Hace casi un año, publiqué mi solución para la paginación en SQL Server, que implicaba usar un CTE para ubicar solo los valores clave para el conjunto de filas en cuestión, y luego unirme desde el CTE a la tabla de origen para recuperar las otras columnas solo para esa "página" de filas. Esto resultó más beneficioso cuando había un índice estrecho que admitía el orden solicitado por el usuario, o cuando el orden se basaba en la clave de agrupación, pero incluso funcionaba un poco mejor sin un índice que admitiera el orden requerido.
Desde entonces, me he preguntado si los índices de ColumnStore (tanto agrupados como no agrupados) podrían ayudar en alguno de estos escenarios. TL;RD :Basado en este experimento aislado, la respuesta al título de esta publicación es un rotundo NO . Si no desea ver la configuración de la prueba, el código, los planes de ejecución o los gráficos, no dude en pasar a mi resumen, teniendo en cuenta que mi análisis se basa en un caso de uso muy específico.
Configuración
En una nueva máquina virtual con SQL Server 2016 CTP 3.2 (13.0.900.73) instalado, ejecuté aproximadamente la misma configuración que antes, solo que esta vez con tres tablas. Primero, una tabla tradicional con una clave de agrupamiento estrecha y múltiples índices de soporte:
CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); -- to support "PhoneBook" sorting (order by Last,First) CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
A continuación, una tabla con un índice de ColumnStore agrupado:
CREATE TABLE [dbo].[Customers_CCI] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL UNIQUE, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_CustomersCCI] PRIMARY KEY NONCLUSTERED ([CustomerID]) ); CREATE CLUSTERED COLUMNSTORE INDEX [Customers_CCI] ON [dbo].[Customers_CCI];
Y finalmente, una tabla con un índice ColumnStore no agrupado que cubre todas las columnas:
CREATE TABLE [dbo].[Customers_NCCI]
(
[CustomerID] [int] NOT NULL,
[FirstName] [nvarchar](64) NOT NULL,
[LastName] [nvarchar](64) NOT NULL,
[EMail] [nvarchar](320) NOT NULL UNIQUE,
[Active] [bit] NOT NULL DEFAULT 1,
[Created] [datetime] NOT NULL DEFAULT SYSDATETIME(),
[Updated] [datetime] NULL,
CONSTRAINT [PK_CustomersNCCI] PRIMARY KEY CLUSTERED
([CustomerID])
);
CREATE NONCLUSTERED COLUMNSTORE INDEX [Customers_NCCI]
ON [dbo].[Customers_NCCI]
(
[CustomerID],
[FirstName],
[LastName],
[EMail],
[Active],
[Created],
[Updated]
); Tenga en cuenta que para ambas tablas con índices de ColumnStore, omití el índice que admitiría búsquedas más rápidas en el tipo "Guía telefónica" (apellido, nombre).
Datos de prueba
Luego llené la primera tabla con 1 000 000 de filas aleatorias, según un script que reutilicé de publicaciones anteriores:
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (1000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (2000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name+c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn; Luego usé esa tabla para completar las otras dos con exactamente los mismos datos y reconstruí todos los índices:
INSERT dbo.Customers_CCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; INSERT dbo.Customers_NCCI WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; ALTER INDEX ALL ON dbo.Customers REBUILD; ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
El tamaño total de cada mesa:
| Tabla | Reservado | Datos | Índice |
|---|---|---|---|
| Clientes | 463.200 KB | 154.344 KB | 308.576 KB |
| Clientes_CCI | 117.280 KB | 30.288 KB | 86.536 KB |
| Clientes_NCCI | 349.480 KB | 154.344 KB | 194.976 KB |
Y el recuento de filas/recuento de páginas de los índices relevantes (el índice único en el correo electrónico estaba allí más para cuidar mi propio script de generación de datos que cualquier otra cosa):
| Tabla | Índice | Filas | Páginas |
|---|---|---|---|
| Clientes | PK_Clientes | 1,000,000 | 19.377 |
| Clientes | PhoneBook_Customers | 1,000,000 | 17,209 |
| Clientes | Clientes_activos | 808.012 | 13.977 |
| Clientes_CCI | PK_ClientesCCI | 1,000,000 | 2737 |
| Clientes_CCI | Clientes_CCI | 1,000,000 | 3.826 |
| Clientes_NCCI | PK_ClientesNCCI | 1,000,000 | 19.377 |
| Clientes_NCCI | Clientes_NCCI | 1,000,000 | 16.971 |
Procedimientos
Luego, para ver si los índices de ColumnStore intervendrían y mejorarían cualquiera de los escenarios, ejecuté el mismo conjunto de consultas que antes, pero ahora en las tres tablas. Me volví al menos un poco más inteligente e hice dos procedimientos almacenados con SQL dinámico para aceptar el origen de la tabla y el orden de clasificación. (Soy muy consciente de la inyección de SQL; esto no es lo que haría en producción si estas cadenas provinieran de un usuario final, así que no lo tome como una recomendación para hacerlo. Confío en mí mismo lo suficiente en mi ambiente cerrado que no es una preocupación para estas pruebas).
CREATE PROCEDURE dbo.P_Old
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N'
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
CREATE PROCEDURE dbo.P_CTE
@PageNumber INT = 1,
@PageSize INT = 100,
@Table SYSNAME,
@Sort VARCHAR(32)
AS
BEGIN
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX) = N'
;WITH pg AS
(
SELECT CustomerID
FROM dbo.' + QUOTENAME(@Table) + N'
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.' + QUOTENAME(@Table) + N' AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY ' + CASE @Sort
WHEN 'Key' THEN N'CustomerID'
WHEN 'PhoneBook' THEN N'LastName, FirstName'
WHEN 'Unsupported' THEN N'FirstName DESC, EMail'
END
+ N' OPTION (RECOMPILE);';
EXEC sys.sp_executesql @sql, N'@PageSize INT, @PageNumber INT', @PageSize, @PageNumber;
END
GO
Luego preparé un SQL más dinámico para generar todas las combinaciones de llamadas que necesitaría hacer para llamar tanto a los procedimientos almacenados antiguos como a los nuevos, en los tres órdenes de clasificación deseados y en diferentes números de página (para simular la necesidad de una página cerca del principio, medio y final del orden de clasificación). Para poder copiar PRINT y péguelo en SQL Sentry Plan Explorer para obtener métricas de tiempo de ejecución, ejecuté este lote dos veces, una vez con los procedures CTE usando P_Old , y luego otra vez usando P_CTE .
DECLARE @sql NVARCHAR(MAX) = N''; ;WITH [tables](name) AS ( SELECT N'Customers' UNION ALL SELECT N'Customers_CCI' UNION ALL SELECT N'Customers_NCCI' ), sorts(sort) AS ( SELECT 'Key' UNION ALL SELECT 'PhoneBook' UNION ALL SELECT 'Unsupported' ), pages(pagenumber) AS ( SELECT 1 UNION ALL SELECT 500 UNION ALL SELECT 5000 UNION ALL SELECT 9999 ), procedures(name) AS ( SELECT N'P_CTE' -- N'P_Old' ) SELECT @sql += N' EXEC dbo.' + p.name + N' @Table = N' + CHAR(39) + t.name + CHAR(39) + N', @Sort = N' + CHAR(39) + s.sort + CHAR(39) + N', @PageNumber = ' + CONVERT(NVARCHAR(11), pg.pagenumber) + N';' FROM tables AS t CROSS JOIN sorts AS s CROSS JOIN pages AS pg CROSS JOIN procedures AS p ORDER BY t.name, s.sort, pg.pagenumber; PRINT @sql;
Esto produjo un resultado como este (36 llamadas en total para el método antiguo (P_Old ), y 36 llamadas al nuevo método (P_CTE )):
EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 1; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 500; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 5000; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Key', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'PhoneBook', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_CCI', @Sort = N'Unsupported', @PageNumber = 9999; EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Key', @PageNumber = 1; ... EXEC dbo.P_CTE @Table = N'Customers_NCCI', @Sort = N'Unsupported', @PageNumber = 9999;
Lo sé, todo esto es muy engorroso; pronto llegaremos al remate, lo prometo.
Resultados
Tomé esos dos conjuntos de 36 declaraciones y comencé dos nuevas sesiones en Plan Explorer, ejecutando cada conjunto varias veces para asegurarme de que obtuviéramos datos de un caché tibio y tomando promedios (también podría comparar caché frío y tibio, pero creo que hay suficientes variables aquí).
Puedo decirle de inmediato un par de hechos simples sin siquiera mostrarle gráficos o planos de apoyo:
- En ningún escenario el método "antiguo" venció al nuevo método CTE Promocioné en mi publicación anterior, sin importar qué tipo de índices estuvieran presentes. Eso hace que sea fácil ignorar virtualmente la mitad de los resultados, al menos en términos de duración (que es la métrica que más les importa a los usuarios finales).
- A ningún índice de ColumnStore le fue bien al paginar hacia el final del resultado – solo dieron beneficios al principio, y solo en un par de casos.
- Al ordenar por clave principal (agrupados o no), la presencia de índices de ColumnStore no ayudó – de nuevo, en términos de duración.
Con esos resúmenes fuera del camino, echemos un vistazo a algunas secciones transversales de los datos de duración. Primero, los resultados de la consulta ordenados por nombre de forma descendente, luego por correo electrónico, sin esperanza de utilizar un índice existente para ordenar. Como puede ver en el gráfico, el rendimiento fue inconsistente:en números de página más bajos, ColumnStore no agrupado funcionó mejor; en números de página más altos, el índice tradicional siempre ganó:
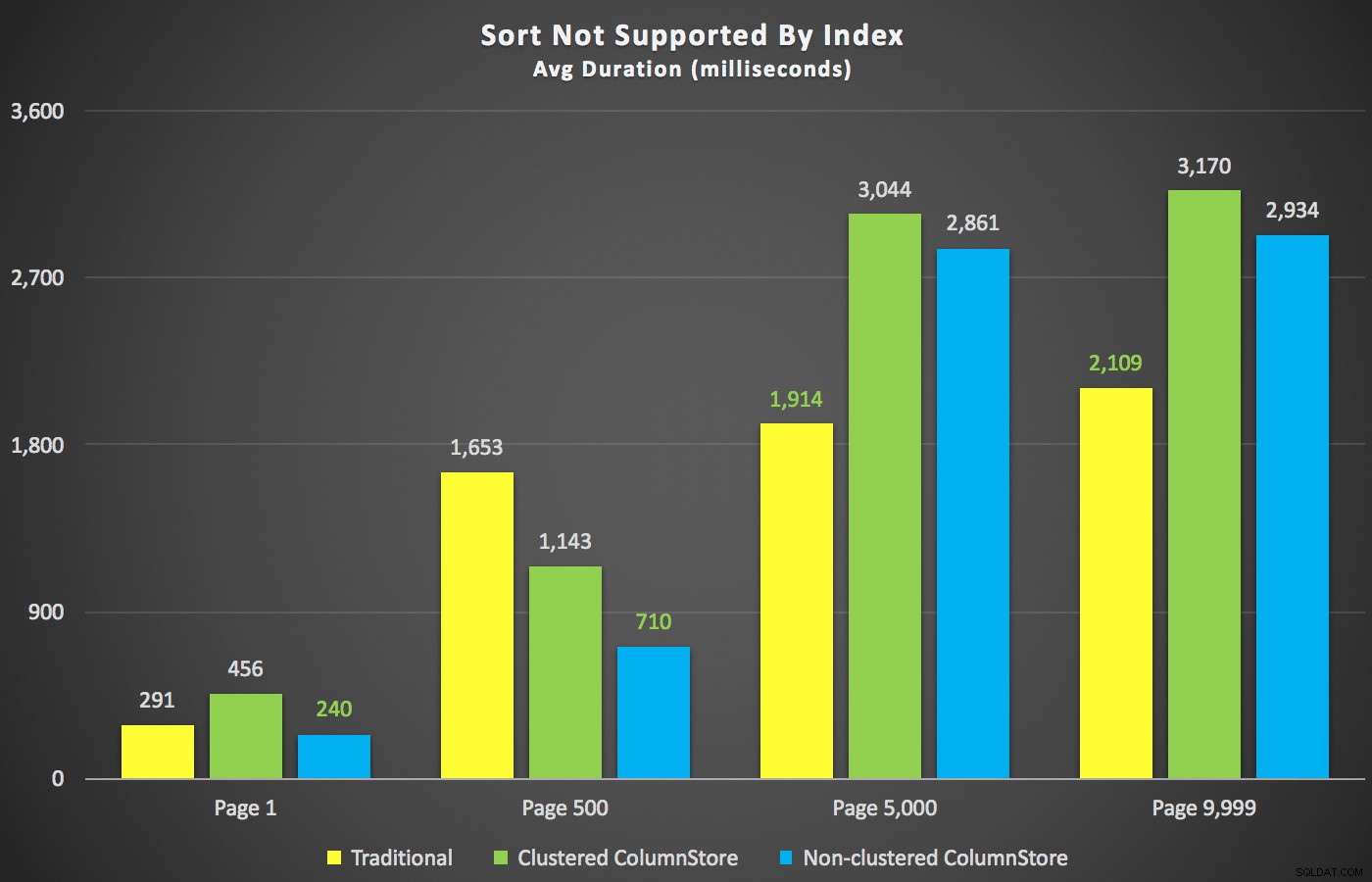 Duración (milisegundos) para diferentes números de página y diferentes tipos de índice
Duración (milisegundos) para diferentes números de página y diferentes tipos de índice
Y luego los tres planos que representan los tres tipos diferentes de índices (con escala de grises añadida por Photoshop para resaltar las principales diferencias entre los planos):
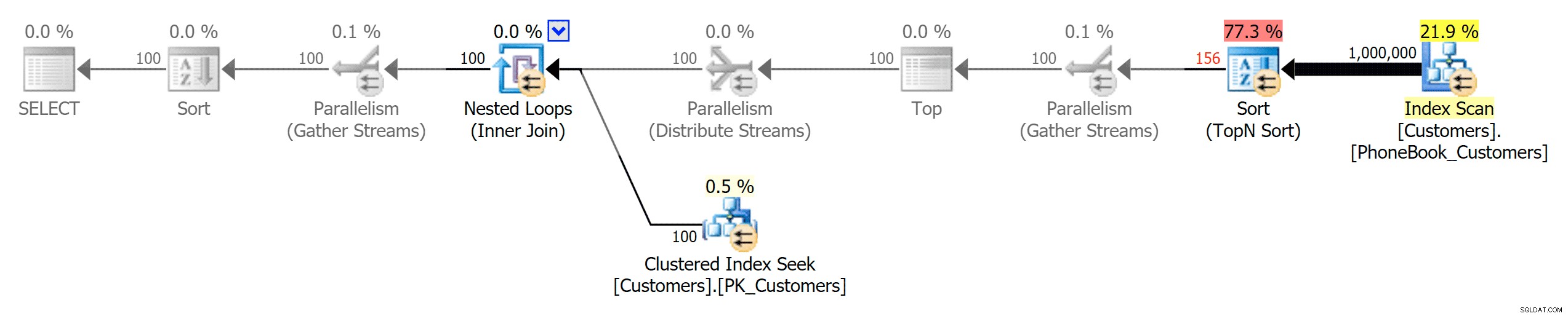 Plan para el índice tradicional
Plan para el índice tradicional
 Plan para el índice ColumnStore agrupado
Plan para el índice ColumnStore agrupado
 Plan para el índice ColumnStore no agrupado
Plan para el índice ColumnStore no agrupado
Un escenario en el que estaba más interesado, incluso antes de comenzar a probar, era el enfoque de clasificación de la guía telefónica (apellido, nombre). En este caso, los índices de ColumnStore fueron bastante perjudiciales para el rendimiento del resultado:
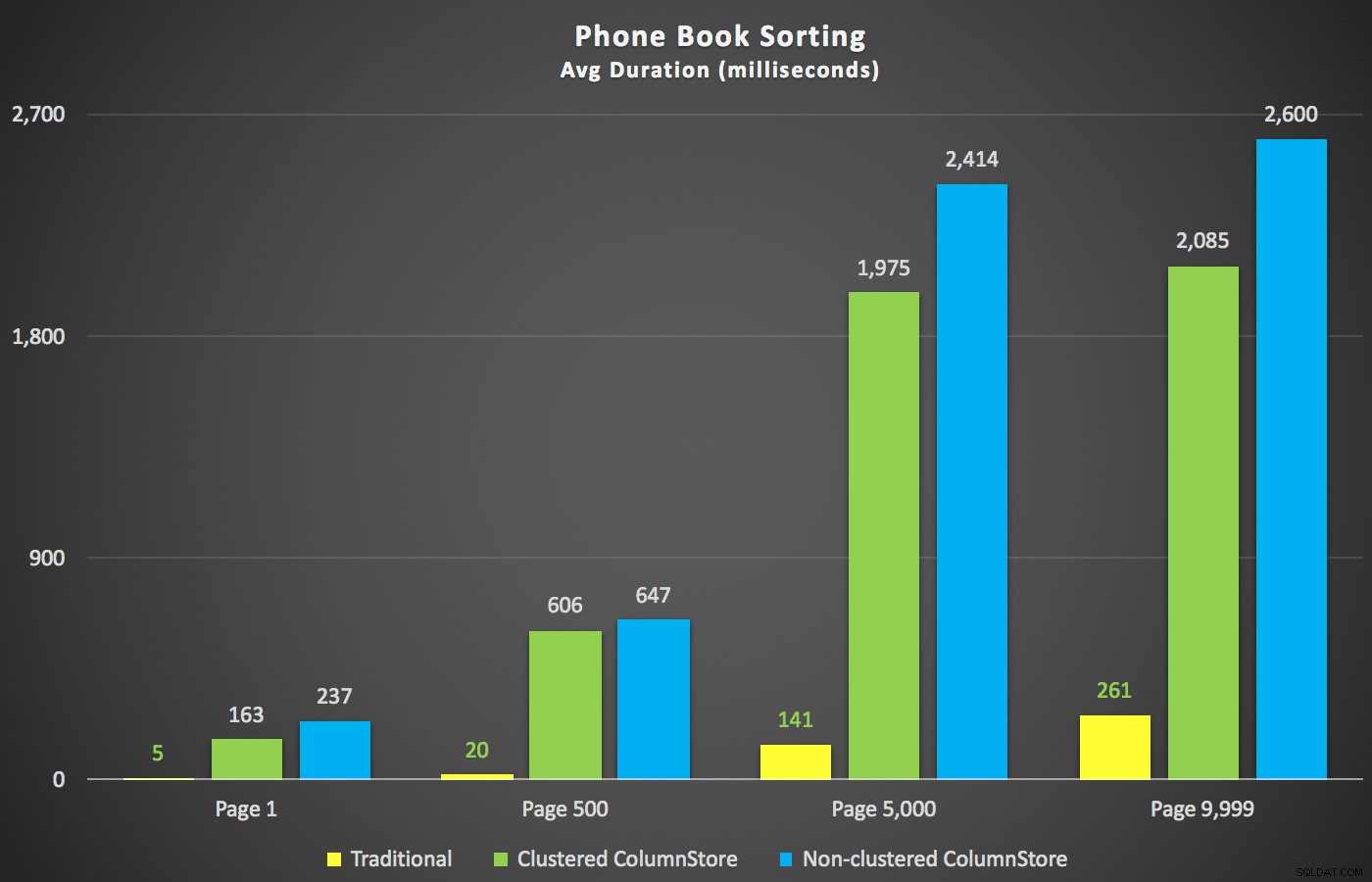
Los planes de ColumnStore aquí son imágenes similares a las de los dos planes de ColumnStore que se muestran arriba para el tipo no admitido. La razón es la misma en ambos casos:escaneos u clasificaciones costosas debido a la falta de un índice de soporte de clasificación.
Entonces, a continuación, creé índices de soporte "PhoneBook" en las tablas con los índices de ColumnStore también, para ver si podía persuadir a un plan diferente y/o tiempos de ejecución más rápidos en cualquiera de esos escenarios. Creé estos dos índices, luego los reconstruí de nuevo:
CREATE NONCLUSTERED INDEX [PhoneBook_CustomersCCI] ON [dbo].[Customers_CCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_CCI REBUILD; CREATE NONCLUSTERED INDEX [PhoneBook_CustomersNCCI] ON [dbo].[Customers_NCCI]([LastName],[FirstName]) INCLUDE ([EMail]); ALTER INDEX ALL ON dbo.Customers_NCCI REBUILD;
Aquí estaban las nuevas duraciones:
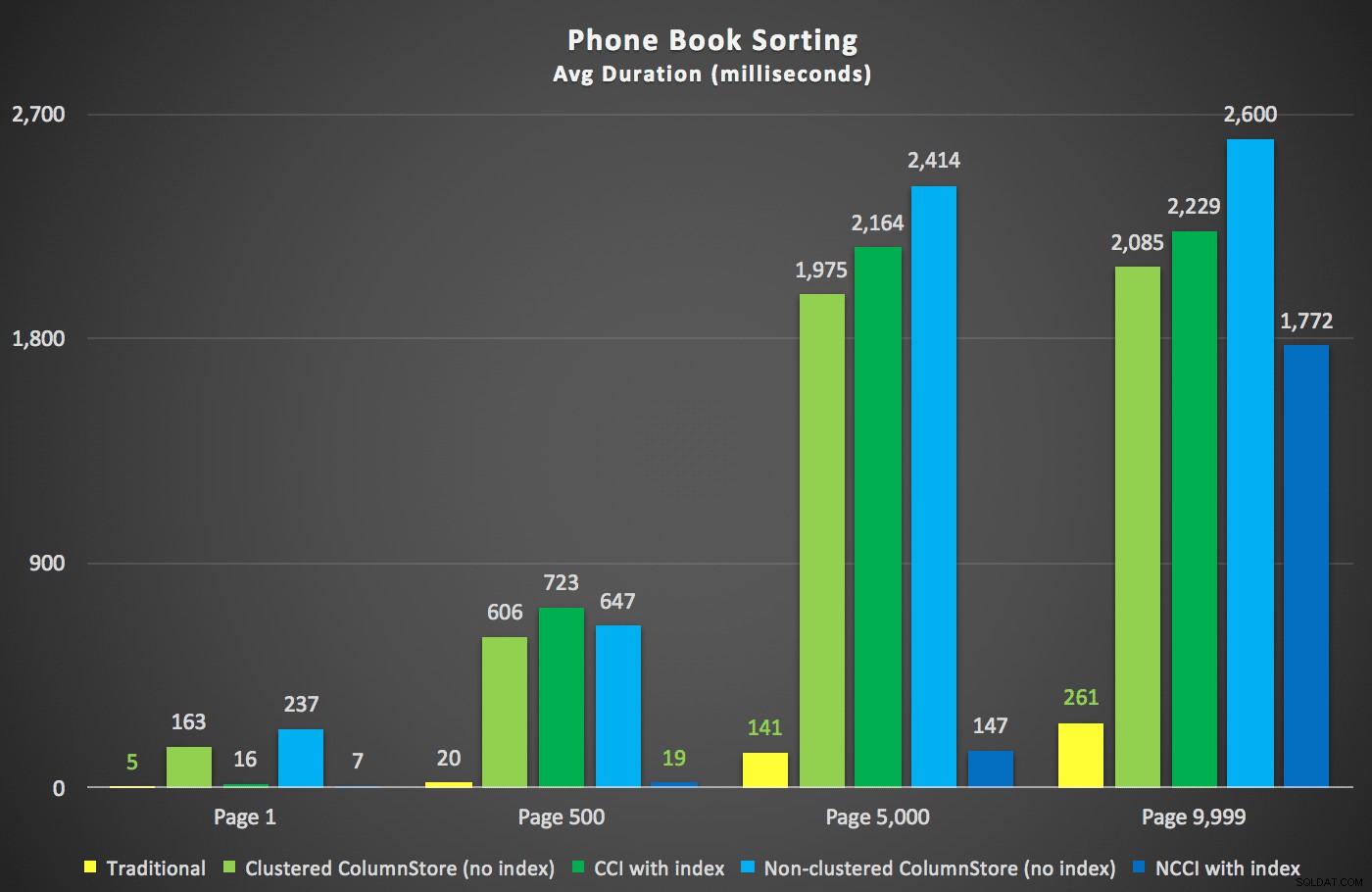
Lo más interesante aquí es que ahora la consulta de paginación en la tabla con el índice ColumnStore no agrupado parece seguir el ritmo del índice tradicional, hasta que superamos la mitad de la tabla. Mirando los planes, podemos ver que en la página 5000, se usa un escaneo de índice tradicional y el índice ColumnStore se ignora por completo:
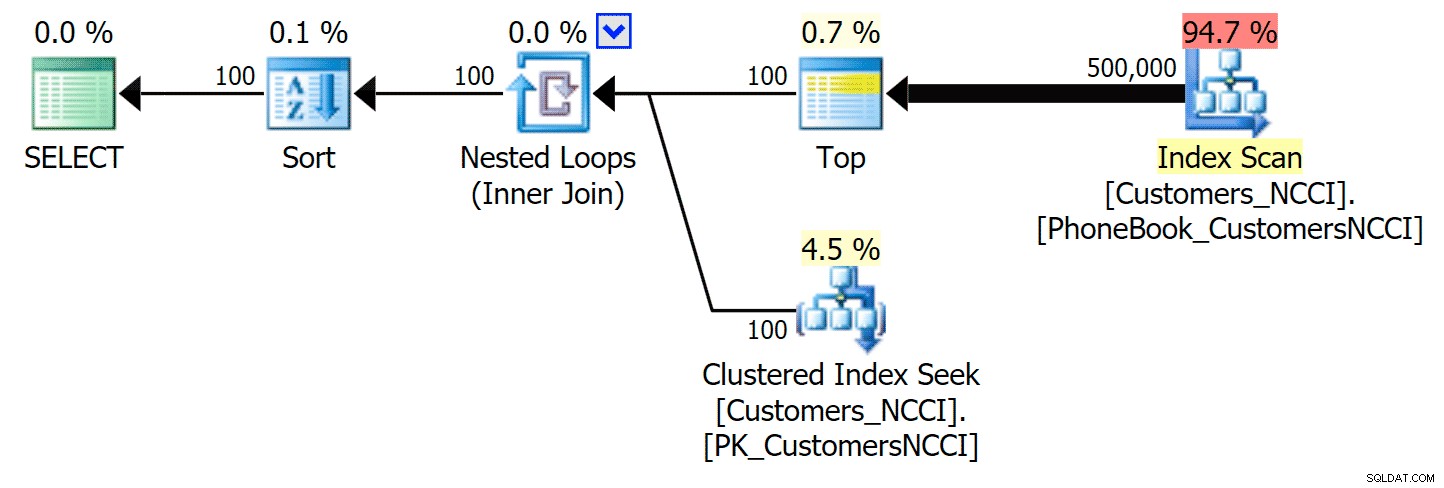 Plan de guía telefónica que ignora el índice ColumnStore no agrupado
Plan de guía telefónica que ignora el índice ColumnStore no agrupado
Pero en algún lugar entre el punto medio de 5000 páginas y el "final" de la tabla en 9999 páginas, el optimizador ha alcanzado una especie de punto de inflexión y, exactamente para la misma consulta, ahora elige escanear el índice ColumnStore no agrupado. :
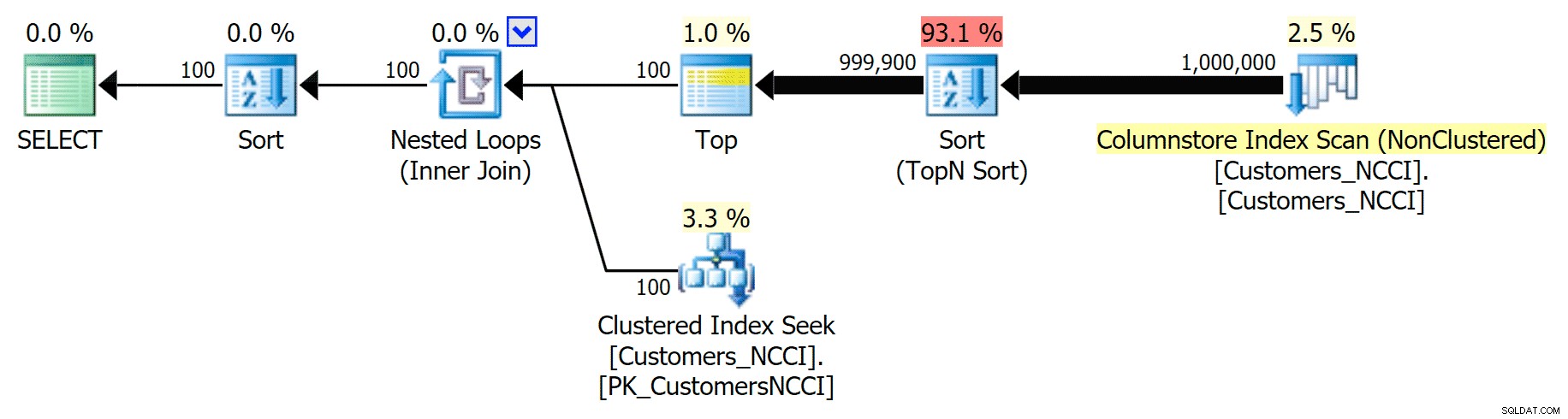 El plan de guía telefónica 'consejos' y utiliza el índice ColumnStore
El plan de guía telefónica 'consejos' y utiliza el índice ColumnStore
Esto resulta ser una decisión no tan buena por parte del optimizador, principalmente debido al costo de la operación de clasificación. Puedes ver cuánto mejora la duración si insinúas el índice regular:
-- ...
;WITH pg AS
(
SELECT CustomerID
FROM dbo.[Customers_NCCI] WITH (INDEX(PhoneBook_CustomersNCCI)) -- hint here
ORDER BY LastName, FirstName OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
-- ... Esto produce el siguiente plan, casi idéntico al primer plan anterior (sin embargo, el costo del escaneo es ligeramente más alto, simplemente porque hay más salida):
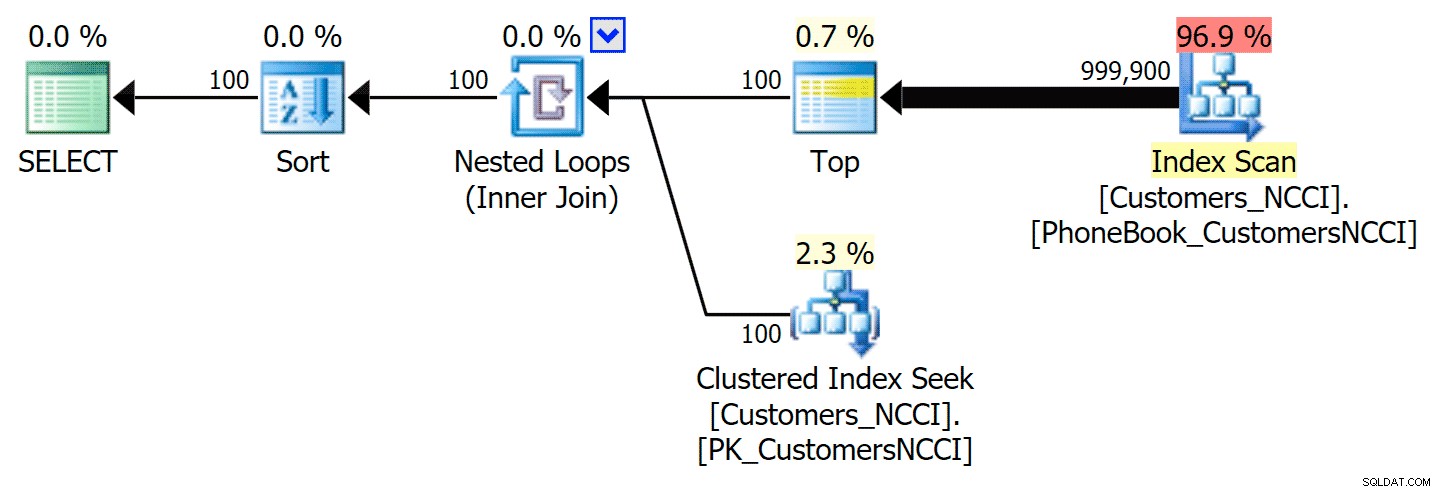 Plan de guía telefónica con índice sugerido
Plan de guía telefónica con índice sugerido
Podría lograr lo mismo usando OPCIÓN (IGNORE_NONCLUSTERED_COLUMNSTORE_INDEX) en lugar de la sugerencia de índice explícita. Solo tenga en cuenta que esto es lo mismo que no tener el índice ColumnStore allí en primer lugar.
Conclusión
Si bien hay un par de casos extremos anteriores en los que un índice de ColumnStore podría (apenas) dar sus frutos, no me parece que sean una buena opción para este escenario de paginación específico. Creo que, lo que es más importante, aunque ColumnStore demuestra un ahorro de espacio significativo debido a la compresión, el rendimiento del tiempo de ejecución no es fantástico debido a los requisitos de clasificación (aunque se estima que estas clasificaciones se ejecutan en modo por lotes, una nueva optimización para SQL Server 2016).
En general, esto podría funcionar con mucho más tiempo dedicado a la investigación y las pruebas; Aprovechando artículos anteriores, quería cambiar lo menos posible. Me encantaría encontrar ese punto de inflexión, por ejemplo, y también me gustaría reconocer que estas no son exactamente pruebas a gran escala (debido al tamaño de la máquina virtual y las limitaciones de memoria), y que los dejé adivinando muchas las métricas de tiempo de ejecución (principalmente por brevedad, pero no sé si un gráfico de lecturas que no siempre son proporcionales a la duración realmente lo diría). Estas pruebas también asumen los lujos de los SSD, suficiente memoria, un caché siempre activo y un entorno de un solo usuario. Realmente me gustaría realizar una batería más grande de pruebas con más datos, en servidores más grandes con discos más lentos e instancias con menos memoria, todo ello con simultaneidad simulada.
Dicho esto, este también podría ser un escenario que ColumnStore no está diseñado para ayudar a resolver en primer lugar, ya que la solución subyacente con índices tradicionales ya es bastante eficiente para extraer un conjunto estrecho de filas, no exactamente la timonera de ColumnStore. Quizás otra variable para agregar a la matriz es el tamaño de la página:todas las pruebas anteriores extraen 100 filas a la vez, pero ¿qué sucede si buscamos 10 000 o 100 000 filas a la vez, independientemente del tamaño de la tabla subyacente?
¿Tiene una situación en la que su carga de trabajo de OLTP mejoró simplemente mediante la adición de índices de ColumnStore? Sé que están diseñados para cargas de trabajo de estilo de almacenamiento de datos, pero si ha visto beneficios en otros lugares, me encantaría conocer su escenario y ver si puedo incorporar algún diferenciador en mi plataforma de prueba.