Para cualquier nueva base de datos creada en SQL Server, el valor predeterminado para la opción Actualización automática de estadísticas está habilitado. . Sospecho que la mayoría de los DBA dejan la opción habilitada, ya que permite que el optimizador actualice automáticamente las estadísticas cuando se invalidan, y generalmente se recomienda dejarla habilitada. Las estadísticas también se actualizan cuando se reconstruyen los índices, y aunque no es raro que las estadísticas se administren bien a través de la opción de actualización automática de estadísticas y a través de reconstrucciones de índices, de vez en cuando un DBA puede encontrar necesario configurar un trabajo regular para actualizar un estadística o conjunto de estadísticas.
La gestión personalizada de estadísticas a menudo implica el comando ACTUALIZAR ESTADÍSTICAS, que parece bastante benigno. Se puede ejecutar para todas las estadísticas de una tabla o vista indexada, o para una estadística específica. Se puede usar la muestra predeterminada, se puede especificar una tasa de muestra específica o el número de filas para muestrear, o puede usar el mismo valor de muestra que se usó anteriormente. Si las estadísticas se actualizan para una tabla o una vista indexada, puede optar por actualizar todas las estadísticas, solo las estadísticas de índice o solo las estadísticas de columna. Y finalmente, puede deshabilitar la opción de estadísticas de actualización automática para una estadística.
Para la mayoría de los DBA, la mayor consideración puede ser cuándo para ejecutar la instrucción UPDATE STATISTICS. Pero los DBA también deciden, conscientemente o no, el tamaño de la muestra para la actualización. El tamaño de muestra seleccionado puede afectar el rendimiento de la actualización real, así como el rendimiento de las consultas.
Comprender los efectos del tamaño de la muestra
El tamaño de muestra predeterminado para ACTUALIZAR ESTADÍSTICAS proviene de un algoritmo no lineal, y el tamaño de muestra disminuye a medida que aumenta el tamaño de la tabla, como mostró Joe Sack en su publicación, Prueba de muestreo predeterminada de estadísticas de actualización automática. En algunos casos, el tamaño de la muestra puede no ser lo suficientemente grande para capturar suficiente información interesante, o el correcto información, para el histograma de estadísticas, como lo señaló Conor Cunningham en su publicación de Tasas de muestreo de estadísticas. Si la muestra predeterminada no crea un buen histograma, los DBA pueden optar por actualizar las estadísticas con una tasa de muestreo más alta, hasta FULLSCAN (escaneo de todas las filas en la tabla o vista indexada). Pero como mencionó Conor en su publicación, escanear más filas tiene un costo, y el DBA se enfrenta al desafío de decidir si ejecutar un FULLSCAN para intentar crear el "mejor" histograma posible, o muestrear un porcentaje más pequeño para minimizar el impacto en el rendimiento de la actualización.
Para intentar comprender en qué punto una muestra tarda más que un ESCANEO COMPLETO, ejecuté las siguientes declaraciones en copias de la tabla SalesOrderDetail que se ampliaron con el script de Jonathan Kehayias:
| ID de declaración | Declaración de ACTUALIZAR ESTADÍSTICAS |
|---|---|
| 1 | ACTUALIZAR ESTADÍSTICAS [Ventas].[SalesOrderDetailEnlarged] CON FULLSCAN; |
| 2 | ACTUALIZAR ESTADÍSTICAS [Ventas].[SalesOrderDetailEnlarged]; |
| 3 | ACTUALIZAR ESTADÍSTICAS [Ventas].[SalesOrderDetailEnlarged] CON MUESTRA 10 POR CIENTO; |
| 4 | ACTUALIZAR ESTADÍSTICAS [Ventas].[SalesOrderDetailEnlarged] CON MUESTRA 25 POR CIENTO; |
| 5 | ACTUALIZAR ESTADÍSTICAS [Ventas].[SalesOrderDetailEnlarged] CON MUESTRA 50 POR CIENTO; |
| 6 | ACTUALIZAR ESTADÍSTICAS [Ventas].[SalesOrderDetailEnlarged] CON MUESTRA 75 POR CIENTO; |
Tenía tres copias de la tabla SalesOrderDetailEnlarged, con las siguientes características*:
| Recuento de filas | Recuento de páginas | MAXDOP | Memoria máxima | Almacenamiento | Máquina |
|---|---|---|---|---|---|
| 23,899,449 | 363,284 | 4 | 8 GB | SSD_1 | Ordenador portátil |
| 607,312,902 | 7,757,200 | 16 | 54 GB | SSD_2 | Servidor de prueba |
| 607,312,902 | 7,757,200 | 16 | 54 GB | 15K | Servidor de prueba |
*Los detalles adicionales sobre el hardware se encuentran al final de esta publicación.
Todas las copias de la tabla tenían las siguientes estadísticas y ninguna de las tres estadísticas del índice incluía columnas:
| Estadística | Tipo | Columnas en clave |
|---|---|---|
| PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID | Índice | Id. de pedido de venta, Id. de detalle de pedido de venta |
| AK_SalesOrderDetailEnlarged_rowguid | Índice | filaguid |
| IX_SalesOrderDetailEnlarged_ProductID | Índice | ProductId |
| user_CarrierTrackingNumber | Columna | Número de seguimiento del operador |
Ejecuté las instrucciones UPDATE STATISTICS anteriores cuatro veces en la tabla SalesOrderDetailEnlarged de mi computadora portátil y dos veces en la tabla SalesOrderDetailEnlarged del TestServer. Las sentencias se ejecutaban en orden aleatorio cada vez, y la caché de procedimientos y la caché de búfer se borraban antes de cada sentencia de actualización. La duración y el uso de tempdb para cada conjunto de declaraciones (promedio) se encuentran en los gráficos a continuación:
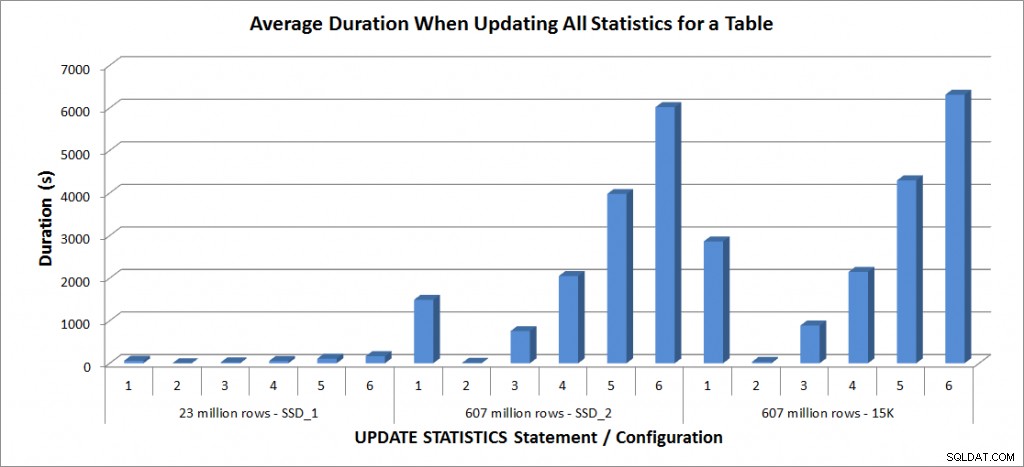
Duración promedio:actualizar todas las estadísticas para SalesOrderDetailEnlarged
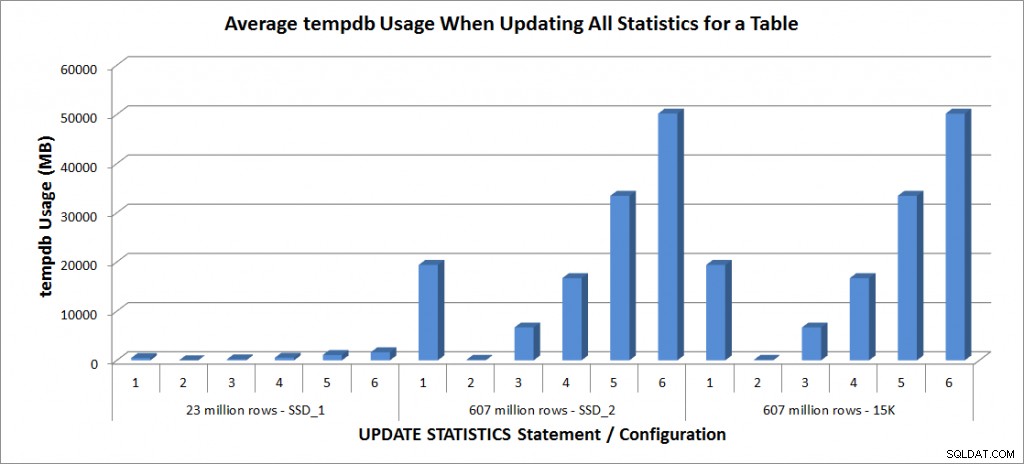
Uso de tempdb:actualizar todas las estadísticas para SalesOrderDetailEnlarged
Las duraciones de la tabla de 23 millones de filas fueron de menos de tres minutos y se describen con más detalle en la siguiente sección. Para la tabla en los discos SSD_2, la declaración FULLSCAN tomó 1492 segundos (casi 25 minutos) y la actualización con una muestra del 25% tomó 2051 segundos (más de 34 minutos). Por el contrario, en los discos de 15K, la instrucción FULLSCAN tomó 2864 segundos (más de 47 minutos) y la actualización con una muestra del 25 % tomó 2147 segundos (casi 36 minutos), menos tiempo que FULLSCAN. Sin embargo, la actualización con una muestra del 50 % tomó 4296 segundos (más de 71 minutos).
El uso de tempdb es mucho más consistente, muestra un aumento constante a medida que aumenta el tamaño de la muestra y usa más espacio de tempdb que FULLSCAN en algún lugar entre 25% y 50%. Lo notable aquí es que UPDATE STATISTICS sí usar tempdb, que es importante recordar cuando se dimensiona tempdb para un entorno de SQL Server. El uso de tempdb se menciona en la entrada UPDATE STATISTICS BOL:
UPDATE STATISTICS puede usar tempdb para ordenar la muestra de filas para crear estadísticas”.
Y el efecto está documentado en la publicación de Linchi Shea, Impacto en el rendimiento:tempdb y estadísticas de actualización. Sin embargo, no es algo que siempre se mencione durante las discusiones sobre el tamaño de tempdb. Si tiene tablas grandes y realiza actualizaciones con FULLSCAN o valores de muestra altos, tenga en cuenta el uso de tempdb.
Rendimiento de actualizaciones selectivas
A continuación, decidí probar las instrucciones UPDATE STATISTICS para las demás estadísticas de la tabla, pero limité mis pruebas a la copia de la tabla con 23 millones de filas. Las seis variaciones anteriores de la instrucción UPDATE STATISTICS se repitieron cuatro veces cada una para las siguientes estadísticas individuales y luego se compararon con la actualización de toda la tabla:
- PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID
- IX_SalesOrderDetailEnlarged_ProductID
- user_CarrierTrackingNumber
Todas las pruebas se realizaron con la configuración antes mencionada en mi computadora portátil y los resultados se muestran en el siguiente gráfico:
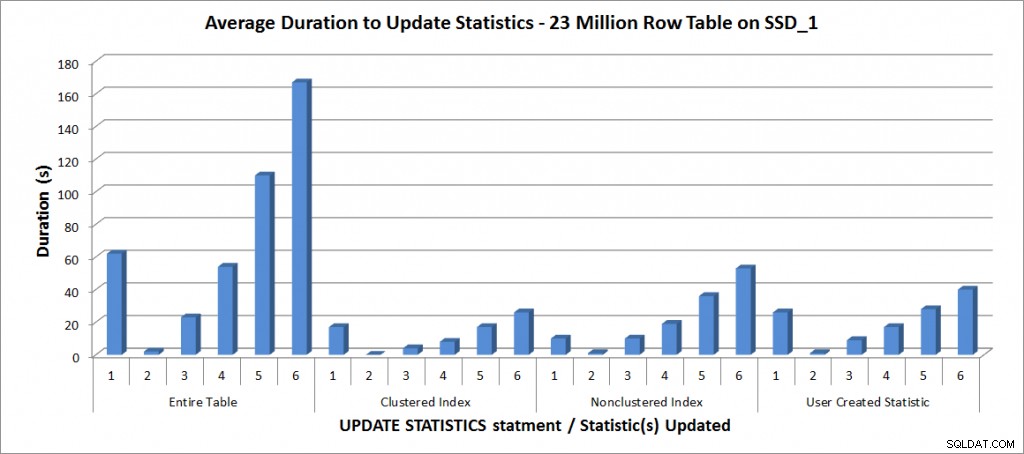
Duración promedio para ACTUALIZAR ESTADÍSTICAS:todas las estadísticas frente a las seleccionadas
Como era de esperar, las actualizaciones de una estadística individual tomaron menos tiempo que cuando se actualizaban todas las estadísticas de la tabla. El valor en el que la muestra actualizada tomó más tiempo que un FULLSCAN varió:
| instrucción ACTUALIZAR | Duración (s) de EXPLORACIÓN COMPLETA | Primera ACTUALIZACIÓN que tomó más tiempo |
|---|---|---|
| Tabla completa | 62 | 50% – 110 segundos |
| Índice agrupado | 17 | 75% – 26 segundos |
| Índice no agrupado | 10 | 25% – 19 segundos |
| Estadística creada por el usuario | 26 | 50% – 28 segundos |
Conclusión
Según estos datos y los datos FULLSCAN de las tablas de 607 millones de filas, no existe una específica. punto de inflexión en el que una actualización de muestra lleva más tiempo que un ESCANEO COMPLETO; ese punto depende del tamaño de la tabla y de los recursos disponibles. Pero los datos aún valen la pena, ya que demuestran que hay un punto en el que un valor muestreado puede tardar más en capturarse que un FULLSCAN. De nuevo se trata de conocer sus datos. Esto es fundamental no solo para comprender si una tabla necesita una gestión personalizada de estadísticas, sino también para comprender el tamaño de muestra ideal para crear un histograma útil y optimizar el uso de recursos.
Especificaciones
Especificaciones de la computadora portátil:Dell M6500, 1 Intel i7 (4 núcleos a 2,13 GHz y HT habilitado para 8 núcleos lógicos), memoria de 32 GB, Windows 7, SQL Server 2012 SP1 (11.0.3128.0 x64), archivos de base de datos almacenados en un SSD Samsung de 265 GB PM810Especificaciones del servidor de prueba:Dell R720, 2 Intel E5-2670 (8 núcleos a 2,6 GHz y HT habilitado, de modo que 16 núcleos lógicos por socket), memoria de 64 GB, Windows 2012, SQL Server 2012 SP1 (11.0.3339.0 x64), archivos de base de datos para una tabla está ubicada en dos tarjetas Fusion-io Duo MLC de 640 GB, los archivos de la base de datos de la otra tabla están en nueve discos de 15 000 RPM en una matriz RAID5