Una de las mejores formas de conocer los errores de SQL Server es leer las notas de la versión de las actualizaciones acumulativas y los Service Packs cuando se publiquen. Sin embargo, ocasionalmente, esta también es una excelente manera de conocer las mejoras de SQL Server.
Actualización acumulativa 6 para SQL Server 2014 Service Pack 1 introdujo un nuevo indicador de seguimiento, 7471, que cambia el comportamiento de bloqueo de las tareas de ACTUALIZAR ESTADÍSTICAS en SQL Server (consulte KB n.º 3156157). En esta publicación, veremos la diferencia en el comportamiento de bloqueo y dónde podría ser útil esta marca de rastreo.
Para configurar un entorno de demostración adecuado para esta publicación, utilicé la base de datos AdventureWorks2014 y creé una versión ampliada de la tabla SalesOrderDetail basada en el script disponible en mi blog. La tabla SalesOrderDetailEnlarged se amplió a 2 GB de tamaño para que las operaciones de ACTUALIZAR ESTADÍSTICAS CON EXPLORACIÓN COMPLETA pudieran ejecutarse con diferentes estadísticas en la tabla al mismo tiempo. Luego usé sp_whoisactive para examinar los bloqueos que tenían ambas sesiones.
Comportamiento sin TF 7471
El comportamiento predeterminado de SQL Server requiere un bloqueo exclusivo (X) en el recurso OBJECT.UPDSTATS para la tabla cada vez que se ejecuta un comando UPDATE STATISTICS en una tabla. Puede ver esto en el resultado de sp_whoisactive para dos ejecuciones simultáneas de UPDATE STATISTICS WITH FULLSCAN en la tabla Sales.SalesOrderDetailEnlarged, usando diferentes nombres de índice para actualizar las estadísticas. Esto da como resultado el bloqueo de la segunda ejecución de ACTUALIZAR ESTADÍSTICAS hasta que se complete la primera ejecución.
UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="OBJECT.UPDSTATS" request_mode="X" request_status="GRANT" request_count="1" />
</Locks>
</Object> UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([IX_SalesOrderDetailEnlarged_ProductID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT.UPDSTATS" request_mode="X" request_status="WAIT" request_count="1" />
</Locks>
</Object> La granularidad del recurso de bloqueo en OBJECT.UPDSTATS evita actualizaciones simultáneas de varias estadísticas en la misma tabla. Las mejoras de hardware en los últimos años realmente han cambiado los cuellos de botella potenciales que son comunes a las implementaciones de SQL Server, y al igual que se han realizado cambios en DBCC CHECKDB para que se ejecute más rápido, se cambió el comportamiento de bloqueo de UPDATE STATISTICS para permitir actualizaciones simultáneas de estadísticas en el misma tabla puede reducir significativamente las ventanas de mantenimiento para los VLDB, especialmente donde hay suficiente capacidad de subsistema de E/S y CPU para permitir que se realicen actualizaciones simultáneas sin afectar la experiencia del usuario final.
Comportamiento con TF 7471
El comportamiento de bloqueo con el indicador de seguimiento 7471 habilitó cambios de requerir un bloqueo exclusivo (X) en el recurso OBJECT.UPDSTATS a requerir un bloqueo de actualización (U) en el recurso METADATA.STATS para la estadística específica que se está actualizando, lo que permite ejecuciones simultáneas de ACTUALIZAR ESTADÍSTICAS en la misma tabla. La salida de sp_whoisactive para los mismos comandos ACTUALIZAR ESTADÍSTICAS CON FULLCAN con el indicador de seguimiento habilitado se muestra a continuación:
UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) WITH FULLSCAN; <Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="U" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
</Locks>
</Object> UPDATE STATISTICS [Sales].[SalesOrderDetailEnlarged]
([IX_SalesOrderDetailEnlarged_ProductID]) WITH FULLSCAN; <Objects>
<Object name="SalesOrderDetailEnlarged" schema_name="Sales">
<Locks>
<Lock resource_type="METADATA.INDEXSTATS"
index_name="IX_SalesOrderDetailEnlarged_ProductID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.INDEXSTATS"
index_name="PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID"
request_mode="Sch-S" request_status="GRANT" request_count="2" />
<Lock resource_type="METADATA.STATS" request_mode="U" request_status="GRANT" request_count="1" />
<Lock resource_type="OBJECT" request_mode="Sch-S" request_status="GRANT" request_count="2" />
</Locks>
</Object> Para los VLDB, que se están volviendo mucho más comunes, esto puede marcar una gran diferencia en el tiempo que lleva realizar actualizaciones de estadísticas en un servidor.
Recientemente escribí en un blog sobre una solución de mantenimiento en paralelo para SQL Server utilizando Service Broker y los scripts de mantenimiento de Ola Hallengren como una forma de optimizar las tareas de mantenimiento nocturno y reducir el tiempo necesario para reconstruir índices y actualizar estadísticas en servidores que tienen mucha capacidad de CPU y E/S. disponible. Como parte de esa solución, forcé una orden de tareas en cola a Service Broker para intentar evitar tener ejecuciones simultáneas en la misma tabla para las tareas de reconstrucción/reorganización de índices y ACTUALIZAR ESTADÍSTICAS. El objetivo de esto era mantener a los trabajadores lo más ocupados posible hasta el final de las tareas de mantenimiento, donde las cosas se serializarían en ejecución en función del bloqueo de tareas concurrentes.
Hice algunas modificaciones al procesamiento en esa publicación solo para probar los efectos de este indicador de seguimiento solo con actualizaciones de estadísticas simultáneas, y los resultados están a continuación.
Prueba del rendimiento de la actualización de estadísticas simultáneas
Para probar el rendimiento de solo actualizar estadísticas en paralelo usando la configuración de Service Broker, comencé creando una columna estadística en cada columna en la base de datos AdventureWorks2014 usando el siguiente script para generar los comandos DDL que se ejecutarán.
USE [AdventureWorks2014]
GO
SELECT *, 'DROP STATISTICS ' + QUOTENAME(c.TABLE_SCHEMA) + '.'
+ QUOTENAME(c.TABLE_NAME) + '.' + QUOTENAME(c.TABLE_NAME
+ '_' + c.COLUMN_NAME) + ';
GO
CREATE STATISTICS ' +QUOTENAME(c.TABLE_NAME + '_' + c.COLUMN_NAME)
+ ' ON ' + QUOTENAME(c.TABLE_SCHEMA) + '.' + QUOTENAME(c.TABLE_NAME)
+ ' (' +QUOTENAME(c.COLUMN_NAME) + ');' + '
GO'
FROM INFORMATION_SCHEMA.COLUMNS AS c
INNER JOIN INFORMATION_SCHEMA.TABLES AS t
ON c.TABLE_CATALOG = t.TABLE_CATALOG AND
c.TABLE_SCHEMA = t.TABLE_SCHEMA AND
c.TABLE_NAME = t.TABLE_NAME
WHERE t.TABLE_TYPE = 'BASE TABLE'
AND c.DATA_TYPE <> N'xml'; Esto no es algo que normalmente querría hacer, pero me brinda muchas estadísticas para probar en paralelo el impacto de la marca de seguimiento en la actualización de estadísticas al mismo tiempo. En lugar de aleatorizar el orden en el que coloco las tareas en la cola de Service Broker, simplemente pongo en cola las tareas tal como existen en la tabla CommandLog en función del ID de la tabla, simplemente incrementando el ID en uno hasta que todos los comandos se hayan puesto en cola. para su procesamiento.
USE [master]; -- Clear the Command Log TRUNCATE TABLE [master].[dbo].[CommandLog]; DECLARE @MaxID INT; SELECT @MaxID = MAX(ID) FROM master.dbo.CommandLog; SELECT @MaxID = ISNULL(@MaxID, 1) ---- Load new tasks into the Command Log EXEC master.dbo.IndexOptimize @Databases = N'AdventureWorks2014', @FragmentationLow = NULL, @FragmentationMedium = NULL, @FragmentationHigh = NULL, @UpdateStatistics = 'ALL', @StatisticsSample = 100, @LogToTable = 'Y', @Execute = 'N'; DECLARE @NewMaxID INT SELECT @NewMaxID = MAX(ID) FROM master.dbo.CommandLog; USE msdb; DECLARE @CurrentID INT = @MaxID WHILE (@CurrentID <= @NewMaxID) BEGIN -- Begin a conversation and send a request message DECLARE @conversation_handle UNIQUEIDENTIFIER; DECLARE @message_body XML; BEGIN TRANSACTION; BEGIN DIALOG @conversation_handle FROM SERVICE [OlaHallengrenMaintenanceTaskService] TO SERVICE N'OlaHallengrenMaintenanceTaskService' ON CONTRACT [OlaHallengrenMaintenanceTaskContract] WITH ENCRYPTION = OFF; SELECT @message_body = N'<CommandLogID>'+CAST(@CurrentID AS NVARCHAR)+N'</CommandLogID>'; SEND ON CONVERSATION @conversation_handle MESSAGE TYPE [OlaHallengrenMaintenanceTaskMessage] (@message_body); COMMIT TRANSACTION; SET @CurrentID = @CurrentID + 1; END WHILE EXISTS (SELECT 1 FROM OlaHallengrenMaintenanceTaskQueue WITH(NOLOCK)) BEGIN WAITFOR DELAY '00:00:01.000' END WAITFOR DELAY '00:00:06.000' SELECT DATEDIFF(ms, MIN(StartTime), MAX(EndTime)) FROM master.dbo.CommandLog; GO 10
Luego esperé a que se completaran todas las tareas, medí el delta en la hora de inicio y la hora de finalización de las ejecuciones de tareas, y tomé el promedio de diez pruebas para determinar las mejoras solo para actualizar las estadísticas al mismo tiempo usando el muestreo predeterminado y las actualizaciones de escaneo completo.
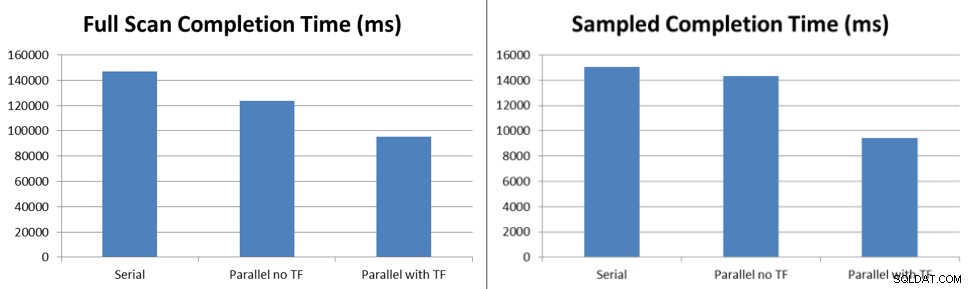
Los resultados de la prueba muestran que, incluso con el bloqueo que se produce con el comportamiento predeterminado sin el indicador de seguimiento, las actualizaciones de muestra de estadísticas se ejecutan un 6 % más rápido y las actualizaciones de análisis completo se ejecutan un 16 % más rápido con cinco subprocesos que procesan las tareas en cola para Service Broker. Con la marca de rastreo 7471 habilitada, las mismas actualizaciones de estadísticas de muestra se ejecutan un 38 % más rápido y las actualizaciones de análisis completo se ejecutan un 45 % más rápido con cinco subprocesos que procesan las tareas en cola para Service Broker.
Desafíos potenciales con TF 7471
A pesar de lo convincentes que son los resultados de la prueba, nada en este mundo es gratis y en mi prueba inicial de esto encontré algunos problemas con el tamaño de la VM que estaba usando en mi computadora portátil que creó problemas de carga de trabajo.
Originalmente estaba probando el mantenimiento en paralelo usando una VM de 4vCPU con 4GB de RAM que configuré específicamente para este propósito. Cuando comencé a aumentar la cantidad de MAX_QUEUE_READERS para el procedimiento de activación en Service Broker, comencé a encontrar problemas con las esperas de RESOURCE_SEMAPHORE cuando se habilitaba el indicador de seguimiento, lo que permitía actualizaciones paralelas de estadísticas en las tablas ampliadas en mi base de datos AdventureWorks2014 debido a los requisitos de concesión de memoria. para cada uno de los comandos UPDATE STATISTICS que se estaban ejecutando. Esto se alivió cambiando la configuración de la VM a 16 GB de RAM, pero esto es algo que se debe monitorear y observar cuando se realizan tareas paralelas en tablas más grandes, para incluir el mantenimiento de índices, ya que la inanición de la concesión de memoria también afectará las solicitudes de los usuarios finales que pueden estar intentando ejecutar y también necesita una concesión de memoria más grande.
El equipo del producto también escribió en su blog sobre este indicador de rastreo y en su publicación advierten que pueden ocurrir escenarios de interbloqueo durante la actualización simultánea de estadísticas mientras también se crean estadísticas. Esto no es algo con lo que me haya topado todavía durante mis pruebas, pero definitivamente es algo a tener en cuenta (Kendra Little también advierte al respecto). Como resultado, su recomendación es que este indicador de seguimiento solo se habilite durante la ejecución de tareas de mantenimiento en paralelo y luego se debe deshabilitar durante los períodos de carga de trabajo normales.
¡Disfrútalo!