En la Parte 1 y la Parte 2 de esta serie, cubrí los aspectos lógicos o conceptuales de las expresiones de tabla con nombre en general y las tablas derivadas en particular. Este mes y el próximo cubriré los aspectos de procesamiento físico de las tablas derivadas. Recuerde de la Parte 1 la independencia de los datos físicos principio de la teoría relacional. Se supone que el modelo relacional y el lenguaje de consulta estándar que se basa en él tratan solo los aspectos conceptuales de los datos y dejan los detalles de implementación física como el almacenamiento, la optimización, el acceso y el procesamiento de los datos a la plataforma de la base de datos (el implementación ). A diferencia del tratamiento conceptual de los datos que se basa en un modelo matemático y un lenguaje estándar y, por lo tanto, es muy similar en los diversos sistemas de gestión de bases de datos relacionales que existen, el tratamiento físico de los datos no se basa en ningún estándar y, por lo tanto, tiende a para ser muy específico de la plataforma. En mi cobertura del tratamiento físico de las expresiones de tabla con nombre en la serie, me centro en el tratamiento en Microsoft SQL Server y Azure SQL Database. El tratamiento físico en otras plataformas de bases de datos puede ser bastante diferente.
Recuerde que lo que desencadenó esta serie es cierta confusión que existe en la comunidad de SQL Server en torno a las expresiones de tabla con nombre. Tanto en términos de terminología como en términos de optimización. Abordé algunas consideraciones de terminología en las dos primeras partes de la serie, y abordaré más en futuros artículos cuando hable de CTE, vistas y TVF en línea. En cuanto a la optimización de las expresiones de tabla con nombre, hay confusión en torno a los siguientes elementos (menciono tablas derivadas aquí ya que ese es el enfoque de este artículo):
- Persistencia: ¿Se conserva una tabla derivada en algún lugar? ¿Se conserva en el disco y cómo maneja SQL Server la memoria?
- Proyección de columna: ¿Cómo funciona la coincidencia de índices con tablas derivadas? Por ejemplo, si una tabla derivada proyecta un determinado subconjunto de columnas de alguna tabla subyacente, y la consulta más externa proyecta un subconjunto de las columnas de la tabla derivada, ¿SQL Server es lo suficientemente inteligente como para determinar la indexación óptima basada en el subconjunto final de columnas? eso es realmente necesario? Y qué decir de los permisos; ¿El usuario necesita permisos para todas las columnas a las que se hace referencia en las consultas internas, o solo para las últimas que realmente se necesitan?
- Múltiples referencias a alias de columna: Si la tabla derivada tiene una columna de resultados que se basa en un cálculo no determinista, por ejemplo, una llamada a la función SYSDATETIME, y la consulta externa tiene varias referencias a esa columna, ¿se realizará el cálculo solo una vez o por separado para cada referencia externa? ?
- Anulación/sustitución/inserción: ¿SQL Server anula, o en línea, la consulta de la tabla derivada? Es decir, ¿SQL Server realiza un proceso de sustitución mediante el cual convierte el código anidado original en una consulta que va directamente contra las tablas base? Y si es así, ¿hay alguna forma de indicarle a SQL Server que evite este proceso de anidamiento?
Todas estas son preguntas importantes y las respuestas a estas preguntas tienen implicaciones de rendimiento significativas, por lo que es una buena idea tener una comprensión clara de cómo se manejan estos elementos en SQL Server. Este mes voy a abordar los primeros tres elementos. Hay mucho que decir sobre el cuarto elemento, así que le dedicaré un artículo separado el próximo mes (Parte 4).
En mis ejemplos, usaré una base de datos de muestra llamada TSQLV5. Puede encontrar el script que crea y completa TSQLV5 aquí, y su diagrama ER aquí.
Persistencia
Algunas personas asumen intuitivamente que SQL Server conserva el resultado de la parte de la expresión de la tabla de la tabla derivada (el resultado de la consulta interna) en una tabla de trabajo. A la fecha de este escrito ese no es el caso; sin embargo, dado que las consideraciones de persistencia son una elección del proveedor, Microsoft podría decidir cambiar esto en el futuro. De hecho, SQL Server puede conservar resultados de consultas intermedias en tablas de trabajo (normalmente en tempdb) como parte del procesamiento de consultas. Si decide hacerlo, verá algún tipo de operador de cola de impresión en el plan (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). Sin embargo, la elección de SQL Server de poner en cola algo en una mesa de trabajo o no actualmente no tiene nada que ver con el uso de expresiones de tabla con nombre en la consulta. SQL Server a veces pone en cola los resultados intermedios por razones de rendimiento, como evitar el trabajo repetido (aunque actualmente no está relacionado con el uso de expresiones de tabla con nombre) y, a veces, por otras razones, como la protección de Halloween.
Como mencioné, el próximo mes llegaré a los detalles del anidamiento de tablas derivadas. Por ahora, baste decir que SQL Server normalmente aplica un proceso de anidamiento/inserción a las tablas derivadas, donde sustituye las consultas anidadas con una consulta en las tablas base subyacentes. Bueno, estoy simplificando un poco. No es que SQL Server convierta literalmente la cadena de consulta T-SQL original con las tablas derivadas en una nueva cadena de consulta sin ellas; más bien, SQL Server aplica transformaciones a un árbol lógico interno de operadores, y el resultado es que, de hecho, las tablas derivadas generalmente se anidan. Cuando observa un plan de ejecución para una consulta que involucra tablas derivadas, no ve ninguna mención de ellas porque para la mayoría de los propósitos de optimización no existen. Verá el acceso a las estructuras físicas que contienen los datos para las tablas base subyacentes (montón, índices de almacén de filas de árbol B e índices de almacén de columnas para tablas basadas en disco e índices de árbol y hash para tablas optimizadas para memoria).
Hay casos que impiden que SQL Server anide una tabla derivada, pero incluso en esos casos, SQL Server no conserva el resultado de la expresión de la tabla en una tabla de trabajo. Proporcionaré los detalles junto con ejemplos el próximo mes.
Dado que SQL Server no conserva las tablas derivadas, sino que interactúa directamente con las estructuras físicas que contienen los datos de las tablas base subyacentes, la pregunta sobre cómo se maneja la memoria para las tablas derivadas es discutible. Si las tablas base subyacentes están basadas en disco, sus páginas relevantes deben procesarse en el grupo de búfer. Si las tablas subyacentes son optimizadas para memoria, es necesario procesar sus filas en memoria relevantes. Pero eso no es diferente a cuando consulta las tablas subyacentes directamente sin usar tablas derivadas. Así que no hay nada especial aquí. Cuando usa tablas derivadas, SQL Server no necesita aplicar ninguna consideración de memoria especial para ellas. Para la mayoría de los propósitos de optimización de consultas, no existen.
Si tiene un caso en el que necesita conservar el resultado de algún paso intermedio en una tabla de trabajo, debe usar tablas temporales o variables de tabla, no expresiones de tabla con nombre.
Proyección de columna y una palabra en SELECT *
La proyección es uno de los operadores originales del álgebra relacional. Suponga que tiene una relación R1 con los atributos x, y y z. La proyección de R1 sobre algún subconjunto de sus atributos, por ejemplo, x y z, es una nueva relación R2, cuyo encabezado es el subconjunto de atributos proyectados de R1 (x y z en nuestro caso), y cuyo cuerpo es el conjunto de tuplas formado a partir de la combinación original de valores de atributos proyectados de las tuplas de R1.
Recuerde que el cuerpo de una relación, que es un conjunto de tuplas, por definición no tiene duplicados. Por lo tanto, no hace falta decir que las tuplas de la relación de resultado son la combinación distinta de valores de atributos proyectados desde la relación original. Sin embargo, recuerde que el cuerpo de una tabla en SQL es un conjunto múltiple de filas y no un conjunto y, normalmente, SQL no eliminará las filas duplicadas a menos que se lo indique. Dada una tabla R1 con las columnas x, y y z, la siguiente consulta puede devolver filas duplicadas y, por lo tanto, no sigue la semántica del operador de proyección del álgebra relacional para devolver un conjunto:
SELECT x, z FROM R1;
Al agregar una cláusula DISTINCT, elimina las filas duplicadas y sigue más de cerca la semántica de la proyección relacional:
SELECT DISTINCT x, z FROM R1;
Por supuesto, hay algunos casos en los que sabe que el resultado de su consulta tiene filas distintas sin necesidad de una cláusula DISTINCT, por ejemplo, cuando un subconjunto de las columnas que está devolviendo incluye una clave de la tabla consultada. Por ejemplo, si x es una clave en R1, las dos consultas anteriores son lógicamente equivalentes.
En cualquier caso, recuerde las preguntas que mencioné anteriormente en torno a la optimización de consultas que involucran tablas derivadas y proyección de columnas. ¿Cómo funciona la coincidencia de índices? Si una tabla derivada proyecta un cierto subconjunto de columnas de alguna tabla subyacente, y la consulta más externa proyecta un subconjunto de las columnas de la tabla derivada, ¿es SQL Server lo suficientemente inteligente como para descubrir la indexación óptima basada en el subconjunto final de columnas que en realidad es? ¿necesario? Y qué decir de los permisos; ¿El usuario necesita permisos para todas las columnas a las que se hace referencia en las consultas internas, o solo para las últimas que realmente se necesitan? Además, suponga que la consulta de expresión de tabla define una columna de resultados que se basa en un cálculo, pero la consulta externa no proyecta esa columna. ¿Se evalúa el cálculo en absoluto?
Comenzando con la última pregunta, intentémoslo. Considere la siguiente consulta:
USE TSQLV5; GO SELECT custid, city, 1/0 AS div0error FROM Sales.Customers;
Como era de esperar, esta consulta falla con un error de división por cero:
Mensaje 8134, nivel 16, estado 1Se encontró un error de división por cero.
Luego, defina una tabla derivada llamada D basada en la consulta anterior, y en la consulta externa proyecte D solo en custid y city, así:
SELECT custid, city
FROM ( SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers ) AS D; Como se mencionó, SQL Server normalmente aplica anidación/sustitución, y dado que no hay nada en esta consulta que inhiba la anidación (más sobre el próximo mes), la consulta anterior es equivalente a la siguiente consulta:
SELECT custid, city FROM Sales.Customers;
Una vez más, estoy simplificando un poco aquí. La realidad es un poco más compleja que estas dos consultas que se consideran verdaderamente idénticas, pero abordaré esas complejidades el próximo mes. El punto es que la expresión 1/0 ni siquiera aparece en el plan de ejecución de la consulta y no se evalúa en absoluto, por lo que la consulta anterior se ejecuta correctamente sin errores.
Aún así, la expresión de la tabla debe ser válida. Por ejemplo, considere la siguiente consulta:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Aunque la consulta externa proyecta solo una columna del conjunto de agrupación de la consulta interna, la consulta interna no es válida ya que intenta devolver columnas que no forman parte del conjunto de agrupación ni están contenidas en una función agregada. Esta consulta falla con el siguiente error:
Mensaje 8120, nivel 16, estado 1La columna 'Sales.Customers.custid' no es válida en la lista de selección porque no está incluida en una función agregada ni en la cláusula GROUP BY.
A continuación, abordemos la pregunta de coincidencia de índices. Si la consulta externa proyecta solo un subconjunto de las columnas de la tabla derivada, ¿SQL Server será lo suficientemente inteligente como para hacer una coincidencia de índice basada solo en las columnas devueltas (y, por supuesto, cualquier otra columna que desempeñe un papel significativo, como filtrado, agrupamiento y así sucesivamente)? Pero antes de que abordemos esta pregunta, es posible que se pregunte por qué nos molestamos en hacerlo. ¿Por qué tendría las columnas de retorno de la consulta interna que la consulta externa no necesita?
La respuesta es simple, acortar el código haciendo que la consulta interna use el infame SELECT *. Todos sabemos que usar SELECT * es una mala práctica, pero ese es el caso principalmente cuando se usa en la consulta más externa. ¿Qué sucede si consulta una tabla con un encabezado determinado y luego ese encabezado se modifica? La aplicación podría terminar con errores. Incluso si no termina con errores, podría terminar generando tráfico de red innecesario al devolver columnas que la aplicación realmente no necesita. Además, utiliza la indexación de manera menos óptima en tal caso, ya que reduce las posibilidades de hacer coincidir los índices de cobertura que se basan en las columnas realmente necesarias.
Dicho esto, en realidad me siento bastante cómodo usando SELECT * en una expresión de tabla, sabiendo que de todos modos voy a proyectar solo las columnas realmente necesarias en la consulta más externa. Desde un punto de vista lógico, eso es bastante seguro con algunas advertencias menores a las que llegaré en breve. Eso es siempre que la comparación de índices se realice de manera óptima en tal caso, y la buena noticia es que lo es.
Para demostrar esto, suponga que necesita consultar la tabla Sales.Orders, devolviendo los tres pedidos más recientes para cada cliente. Está planeando definir una tabla derivada llamada D basada en una consulta que calcula los números de fila (columna de resultado número de fila) que están particionados por custid y ordenados por orderdate DESC, orderid DESC. La consulta externa se filtrará desde D (restricción relacional ) solo las filas donde rownum es menor o igual a 3, y proyecto D en custid, orderdate, orderid y rownum. Ahora, Sales.Orders tiene más columnas que las que necesita proyectar, pero por razones de brevedad, desea que la consulta interna use SELECT *, más el cálculo del número de fila. Eso es seguro y se manejará de manera óptima en términos de coincidencia de índices.
Use el siguiente código para crear el índice de cobertura óptimo para respaldar su consulta:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Esta es la consulta que archiva la tarea en cuestión (la llamaremos Consulta 1):
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Observe el SELECCIONAR * de la consulta interna y la lista de columnas explícitas de la consulta externa.
El plan para esta consulta, tal como lo representa SentryOne Plan Explorer, se muestra en la Figura 1.
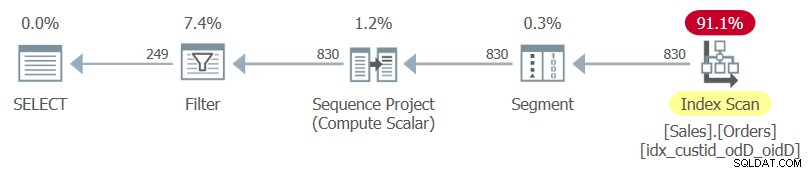 Figura 1:Plan para Consulta 1
Figura 1:Plan para Consulta 1
Observe que el único índice utilizado en este plan es el índice de cobertura óptimo que acaba de crear.
Si resalta solo la consulta interna y examina su plan de ejecución, verá que se usa el índice agrupado de la tabla seguido de una operación de clasificación.
Esas son buenas noticias.
En cuanto a los permisos, esa es una historia diferente. A diferencia de la coincidencia de índices, donde no necesita que el índice incluya columnas a las que hacen referencia las consultas internas siempre que no sean necesarias, debe tener permisos para todas las columnas a las que se hace referencia.
Para demostrar esto, use el siguiente código para crear un usuario llamado usuario1 y asigne algunos permisos (SELECCIONE permisos en todas las columnas de Ventas.Clientes, y solo en las tres columnas de Ventas.Pedidos que son finalmente relevantes en la consulta anterior):
CREATE USER user1 WITHOUT LOGIN; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;
Ejecute el siguiente código para suplantar al usuario1:
EXECUTE AS USER = 'user1';
Intente seleccionar todas las columnas de Ventas.Pedidos:
SELECT * FROM Sales.Orders;
Como era de esperar, obtiene los siguientes errores debido a la falta de permisos en algunas de las columnas:
Mensaje 230, Nivel 14, Estado 1Se denegó el permiso SELECT en la columna 'empid' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Mensaje 230 , Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'fecha requerida' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Mensaje 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'fecha de envío' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Mensaje 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'shipperid' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msj 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'flete' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msj 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'shipname' del objeto 'Orders', base de datos 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
Se denegó el permiso SELECT en la columna 'dirección de envío' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msj 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'shipcity' del objeto 'Orders', base de datos 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
El SELECT se denegó el permiso en la columna 'shipregion' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msg 230, Level 14, State 1
El permiso SELECT fue denegado en la columna 'shippostalcode' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msg 230, Nivel 14, Estado 1
El permiso SELECT fue denegado el la columna 'país de envío' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Pruebe la siguiente consulta, proyectando e interactuando solo con columnas para las que el usuario1 tiene permisos:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Aún así, obtiene errores de permisos de columna debido a la falta de permisos en algunas de las columnas a las que hace referencia la consulta interna a través de su SELECT *:
Mensaje 230, Nivel 14, Estado 1Se denegó el permiso SELECT en la columna 'empid' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Mensaje 230 , Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'fecha requerida' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Mensaje 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'fecha de envío' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Mensaje 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'shipperid' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msj 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'flete' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msj 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'shipname' del objeto 'Orders', base de datos 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
Se denegó el permiso SELECT en la columna 'dirección de envío' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msj 230, Nivel 14, Estado 1
Se denegó el permiso SELECT en la columna 'shipcity' del objeto 'Orders', base de datos 'TSQLV5', esquema 'Sales'.
Msg 230, Level 14, State 1
El SELECT se denegó el permiso en la columna 'shipregion' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msg 230, Level 14, State 1
El permiso SELECT fue denegado en la columna 'shippostalcode' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Msg 230, Nivel 14, Estado 1
El permiso SELECT fue denegado el la columna 'país de envío' del objeto 'Pedidos', base de datos 'TSQLV5', esquema 'Ventas'.
Si en su empresa es una práctica asignar permisos a los usuarios solo en las columnas relevantes con las que necesitan interactuar, tendría sentido usar un código un poco más largo y ser explícito acerca de la lista de columnas tanto en las consultas internas como externas. así:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Esta vez, la consulta se ejecuta sin errores.
Otra variación que requiere que el usuario tenga permisos solo en las columnas relevantes es ser explícito sobre los nombres de las columnas en la lista SELECT de la consulta interna y usar SELECT * en la consulta externa, así:
SELECT *
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Esta consulta también se ejecuta sin errores. Sin embargo, veo esta versión como una que es propensa a errores en caso de que más adelante se realicen algunos cambios en algún nivel interno de anidamiento. Como se mencionó anteriormente, para mí, la mejor práctica es ser explícito acerca de la lista de columnas en la consulta más externa. Entonces, siempre que no tenga preocupaciones sobre la falta de permiso en algunas de las columnas, me siento cómodo con SELECT * en las consultas internas, pero con una lista de columnas explícita en la consulta más externa. Si aplicar permisos de columna específicos es una práctica común en la empresa, lo mejor es ser explícito acerca de los nombres de las columnas en todos los niveles de anidamiento. Eso sí, ser explícito acerca de los nombres de las columnas en todos los niveles de anidamiento es realmente obligatorio si su consulta se usa en un objeto vinculado al esquema, ya que el enlace del esquema no permite el uso de SELECT * en ninguna parte de la consulta.
En este punto, ejecute el siguiente código para eliminar el índice que creó anteriormente en Sales.Orders:
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;
Hay otro caso con un dilema similar con respecto a la legitimidad de usar SELECT *; en la consulta interna del predicado EXISTS.
Considere la siguiente consulta (la llamaremos Consulta 2):
SELECT custid
FROM Sales.Customers AS C
WHERE EXISTS (SELECT * FROM Sales.Orders AS O
WHERE O.custid = C.custid); El plan para esta consulta se muestra en la Figura 2.
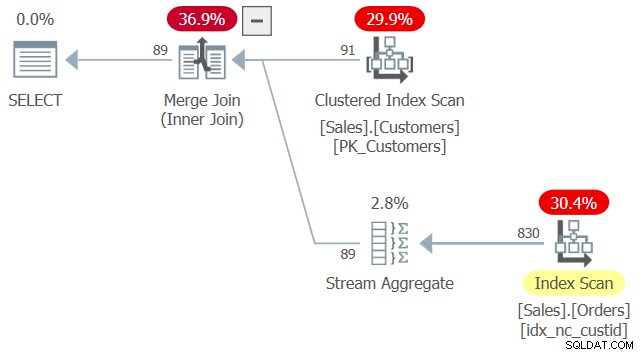 Figura 2:Plan para la consulta 2
Figura 2:Plan para la consulta 2
Al aplicar la coincidencia de índices, el optimizador calculó que el índice idx_nc_custid es un índice de cobertura en Sales.Orders, ya que contiene la columna custid, la única columna verdaderamente relevante en esta consulta. Eso es a pesar del hecho de que este índice no contiene ninguna otra columna además de custid, y que la consulta interna en el predicado EXISTS dice SELECCIONAR *. Hasta ahora, el comportamiento parece similar al uso de SELECT * en tablas derivadas.
La diferencia con esta consulta es que se ejecuta sin errores, a pesar de que el usuario 1 no tiene permisos en algunas de las columnas de Ventas.Pedidos. Hay un argumento para justificar no requerir permisos en todas las columnas aquí. Después de todo, el predicado EXISTS solo necesita verificar la existencia de filas coincidentes, por lo que la lista SELECT de la consulta interna realmente no tiene sentido. Probablemente hubiera sido mejor si SQL no requiriera una lista SELECT en tal caso, pero ese barco ya zarpó. La buena noticia es que la lista SELECT se ignora en la práctica, tanto en términos de coincidencia de índices como en términos de permisos necesarios.
También parecería que hay otra diferencia entre las tablas derivadas y EXISTE cuando se usa SELECCIONAR * en la consulta interna. Recuerde esta consulta anterior en el artículo:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Si recuerda, este código generó un error ya que la consulta interna no es válida.
Pruebe la misma consulta interna, solo que esta vez en el predicado EXISTS (llamaremos a esta Declaración 3):
IF EXISTS ( SELECT *
FROM Sales.Customers
GROUP BY country )
PRINT 'This works! Thanks Dmitri Korotkevitch for the tip!'; Curiosamente, SQL Server considera que este código es válido y se ejecuta correctamente. El plan para este código se muestra en la Figura 3.
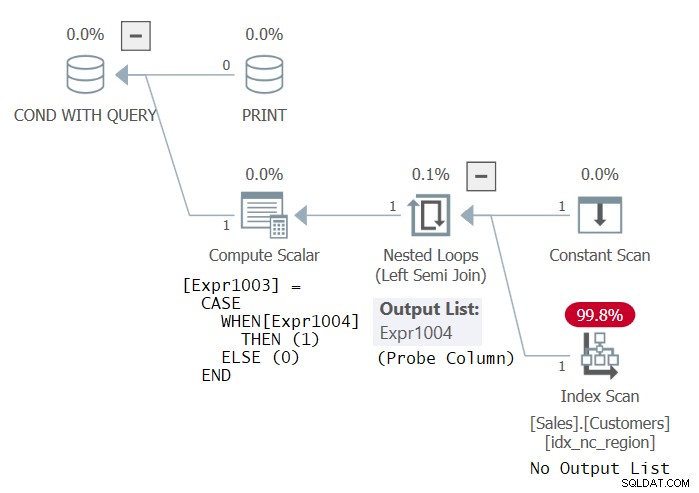 Figura 3:Plan para la Declaración 3
Figura 3:Plan para la Declaración 3
Este plan es idéntico al plan que obtendría si la consulta interna fuera simplemente SELECT * FROM Sales.Customers (sin GROUP BY). Después de todo, está comprobando la existencia de grupos y, si hay filas, naturalmente hay grupos. De todos modos, creo que el hecho de que SQL Server considere esta consulta como válida es un error. ¡Seguramente, el código SQL debería ser válido! Pero puedo ver por qué algunos podrían argumentar que se supone que la lista SELECT en la consulta EXISTS debe ignorarse. En cualquier caso, el plan utiliza una semiunión izquierda probada, que no necesita devolver ninguna columna, sino simplemente sondear una tabla para verificar la existencia de filas. El índice de Clientes podría ser cualquier índice.
En este punto, puede ejecutar el siguiente código para dejar de hacerse pasar por usuario1 y eliminarlo:
REVERT; DROP USER IF EXISTS user1;
Volviendo al hecho de que encuentro que es una práctica conveniente usar SELECT * en niveles internos de anidamiento, cuantos más niveles tenga, más esta práctica acorta y simplifica su código. Aquí hay un ejemplo con dos niveles de anidamiento:
SELECT orderid, orderyear, custid, empid, shipperid
FROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear
FROM ( SELECT *, YEAR(orderdate) AS orderyear
FROM Sales.Orders ) AS D1 ) AS D2
WHERE orderdate = endofyear; Hay casos en los que no se puede utilizar esta práctica. Por ejemplo, cuando la consulta interna une tablas con nombres de columnas comunes, como en el siguiente ejemplo:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Tanto Sales.Customers como Sales.Orders tienen una columna llamada custid. Está utilizando una expresión de tabla que se basa en una unión entre las dos tablas para definir la tabla derivada D. Recuerde que el encabezado de una tabla es un conjunto de columnas y, como conjunto, no puede tener nombres de columna duplicados. Por lo tanto, esta consulta falla con el siguiente error:
Mensaje 8156, Nivel 16, Estado 1La columna 'custid' se especificó varias veces para 'D'.
Aquí, debe ser explícito acerca de los nombres de las columnas en la consulta interna y asegurarse de devolver custid de solo una de las tablas o asignar nombres de columna únicos a las columnas de resultados en caso de que desee devolver ambas. Más a menudo usaría el primer enfoque, así:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Nuevamente, podría ser explícito con los nombres de las columnas en la consulta interna y usar SELECT * en la consulta externa, así:
SELECT *
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Pero como mencioné anteriormente, considero una mala práctica no ser explícito sobre los nombres de las columnas en la consulta más externa.
Múltiples referencias a alias de columna
Pasemos al siguiente elemento:múltiples referencias a columnas de tablas derivadas. Si la tabla derivada tiene una columna de resultados que se basa en un cálculo no determinista y la consulta externa tiene varias referencias a esa columna, ¿se evaluará el cálculo solo una vez o por separado para cada referencia?
Comencemos con el hecho de que se supone que varias referencias a la misma función no determinista en una consulta se evalúan de forma independiente. Considere la siguiente consulta como ejemplo:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;
Este código genera el siguiente resultado que muestra dos GUID diferentes:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
Por el contrario, si tiene una tabla derivada con una columna que se basa en un cálculo no determinista y la consulta externa tiene varias referencias a esa columna, se supone que el cálculo se evalúa solo una vez. Considere la siguiente consulta (la llamaremos Consulta 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2 FROM ( SELECT NEWID() AS mynewid ) AS D;
El plan para esta consulta se muestra en la Figura 4.
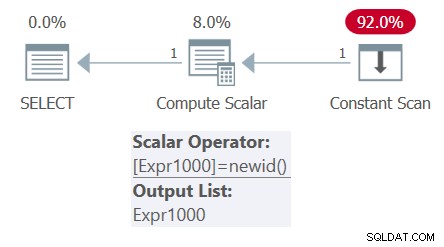 Figura 4:Plan para Consulta 4
Figura 4:Plan para Consulta 4
Observe que solo hay una invocación de la función NEWID en el plan. En consecuencia, la salida muestra el mismo GUID dos veces:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
Por lo tanto, las dos consultas anteriores no son lógicamente equivalentes, y hay casos en los que no se realiza la inserción/sustitución.
Con algunas funciones no deterministas, es un poco más complicado demostrar que varias invocaciones en una consulta se manejan por separado. Tome la función SYSDATETIME como ejemplo. Tiene una precisión de 100 nanosegundos. ¿Cuáles son las posibilidades de que una consulta como la siguiente realmente muestre dos valores diferentes?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;
Si estás aburrido, puedes presionar F5 repetidamente hasta que suceda. Si tiene cosas más importantes que hacer con su tiempo, es posible que prefiera ejecutar un bucle, así:
DECLARE @i AS INT = 1;
WHILE EXISTS( SELECT *
FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; Por ejemplo, cuando ejecuté este código, obtuve 1971.
Si desea asegurarse de que la función no determinista se invoque solo una vez y depender del mismo valor en varias referencias de consulta, asegúrese de definir una expresión de tabla con una columna basada en la invocación de la función y tener varias referencias a esa columna. de la consulta externa, así (la llamaremos Consulta 5):
SELECT mydt AS mydt1, mydt AS mydt1 FROM ( SELECT SYSDATETIME() AS mydt ) AS D;
El plan para esta consulta se muestra en la Figura 5.
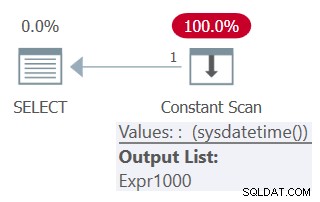 Figura 5:Plan para Consulta 5
Figura 5:Plan para Consulta 5
Observe en el plan que la función se invoca solo una vez.
Now this could be a really interesting exercise in patients to hit F5 repeatedly until you get two different values. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT = 1;
WHILE EXISTS ( SELECT *
FROM (SELECT mydt AS mydt1, mydt AS mydt2
FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT
CASE
WHEN RAND() < 0.5
THEN STR(RAND(), 5, 3) + ' is less than half.'
ELSE STR(RAND(), 5, 3) + ' is at least half.'
END; Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT
CASE
WHEN rnd < 0.5
THEN STR(rnd, 5, 3) + ' is less than half.'
ELSE STR(rnd, 5, 3) + ' is at least half.'
END
FROM ( SELECT RAND() AS rnd ) AS D; Resumen
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.