Este artículo es la cuarta parte de una serie sobre expresiones de tabla. En la Parte 1 y la Parte 2 cubrí el tratamiento conceptual de las tablas derivadas. En la Parte 3, comencé a cubrir las consideraciones de optimización de las tablas derivadas. Este mes cubro más aspectos de optimización de tablas derivadas; específicamente, me enfoco en la sustitución/anulación de tablas derivadas.
En mis ejemplos, usaré bases de datos de muestra llamadas TSQLV5 y PerformanceV5. Puede encontrar el script que crea y completa TSQLV5 aquí, y su diagrama ER aquí. Puede encontrar el script que crea y completa PerformanceV5 aquí.
Desanidación/sustitución
La eliminación/sustitución de expresiones de tabla es un proceso de tomar una consulta que implica el anidamiento de expresiones de tabla y sustituirla por una consulta en la que se elimina la lógica anidada. Debo enfatizar que, en la práctica, no existe un proceso real en el que SQL Server convierta la cadena de consulta original con la lógica anidada en una nueva cadena de consulta sin el anidamiento. Lo que realmente sucede es que el proceso de análisis de consultas produce un árbol inicial de operadores lógicos que reflejan fielmente la consulta original. Luego, SQL Server aplica transformaciones a este árbol de consulta, eliminando algunos de los pasos innecesarios, contrayendo varios pasos en menos pasos y moviendo los operadores. En sus transformaciones, siempre que se cumplan ciertas condiciones, SQL Server puede cambiar las cosas a través de lo que originalmente eran los límites de expresión de la tabla, a veces de manera efectiva como si eliminara las unidades anidadas. Todo esto en un intento de encontrar un plan óptimo.
En este artículo cubro los dos casos en los que se lleva a cabo dicha anulación, así como los inhibidores de anidación. Es decir, cuando usa ciertos elementos de consulta, evita que SQL Server pueda mover operadores lógicos en el árbol de consulta, obligándolo a procesar los operadores en función de los límites de las expresiones de la tabla utilizadas en la consulta original.
Comenzaré demostrando un ejemplo simple en el que las tablas derivadas se anidan. También demostraré un ejemplo de un inhibidor de anidación. Luego hablaré sobre casos inusuales en los que la eliminación del anidamiento puede ser indeseable, lo que puede generar errores o una degradación del rendimiento, y demostraré cómo evitar la eliminación del anidamiento en esos casos mediante el empleo de un inhibidor de eliminación del anidamiento.
La siguiente consulta (la llamaremos Consulta 1) usa varias capas anidadas de tablas derivadas, donde cada una de las expresiones de la tabla aplica una lógica de filtrado básica basada en constantes:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Como puede ver, cada una de las expresiones de la tabla filtra un rango de fechas de pedido que comienzan con una fecha diferente. SQL Server anula esta lógica de consulta de varias capas, lo que le permite fusionar los cuatro predicados de filtrado en uno solo que representa la intersección de los cuatro predicados.
Examine el plan para la Consulta 1 que se muestra en la Figura 1.
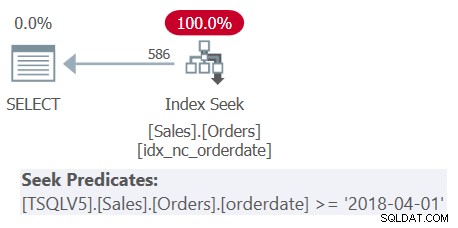 Figura 1:Plan para Consulta 1
Figura 1:Plan para Consulta 1
Observe que los cuatro predicados de filtrado se fusionaron en un solo predicado que representa la intersección de los cuatro. El plan aplica una búsqueda en el índice idx_nc_orderdate en función del predicado combinado único como predicado de búsqueda. Este índice se define en orderdate (explícitamente), orderid (implícitamente debido a la presencia de un índice agrupado en orderid) como claves de índice.
También observe que a pesar de que todas las expresiones de la tabla usan SELECT * y solo la consulta más externa proyecta las dos columnas de interés:orderdate y orderid, el índice antes mencionado se considera que cubre. Como expliqué en la Parte 3, con fines de optimización, como la selección de índices, SQL Server ignora las columnas de las expresiones de la tabla que, en última instancia, no son relevantes. Sin embargo, recuerde que necesita tener permisos para consultar esas columnas.
Como se mencionó, SQL Server intentará anular las expresiones de la tabla, pero evitará la anidación si se topa con un inhibidor de anidamiento. Con una cierta excepción que describiré más adelante, el uso de TOP o OFFSET FETCH inhibirá el anidamiento. El motivo es que intentar anular una expresión de tabla con TOP o OFFSET FETCH podría provocar un cambio en el significado de la consulta original.
Como ejemplo, considere la siguiente consulta (la llamaremos Consulta 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; El número de filas de entrada para el filtro TOP es un valor de tipo BIGINT. En este ejemplo, estoy usando el valor BIGINT máximo (2^63 – 1, cálculo en T-SQL usando SELECT POWER(2., 63) – 1). Aunque usted y yo sabemos que nuestra tabla Pedidos nunca tendrá tantas filas y, por lo tanto, el filtro SUPERIOR realmente no tiene sentido, SQL Server debe tener en cuenta la posibilidad teórica de que el filtro sea significativo. En consecuencia, SQL Server no anula las expresiones de la tabla en esta consulta. El plan para la Consulta 2 se muestra en la Figura 2.
 Figura 2:Plan para la Consulta 2
Figura 2:Plan para la Consulta 2
Los inhibidores de anidamiento impidieron que SQL Server pudiera fusionar los predicados de filtrado, lo que provocó que la forma del plan se pareciera más a la consulta conceptual. Sin embargo, es interesante observar que SQL Server aún ignoró las columnas que finalmente no eran relevantes para la consulta más externa y, por lo tanto, pudo usar el índice de cobertura en orderdate, orderid.
Para ilustrar por qué TOP y OFFSET-FETCH son inhibidores de anidamiento, tomemos una técnica simple de optimización pushdown de predicado. Empuje de predicado significa que el optimizador empuja un predicado de filtro a un punto anterior en comparación con el punto original en el que aparece en el procesamiento de consultas lógicas. Por ejemplo, suponga que tiene una consulta con una combinación interna y un filtro DONDE basado en una columna de uno de los lados de la combinación. En términos de procesamiento de consultas lógicas, se supone que el filtro WHERE se evalúa después de la combinación. Pero, a menudo, el optimizador llevará el predicado del filtro a un paso anterior a la unión, ya que esto deja a la unión con menos filas con las que trabajar, lo que generalmente da como resultado un plan más óptimo. Sin embargo, recuerde que tales transformaciones solo se permiten en los casos en que se conserva el significado de la consulta original, en el sentido de que tiene la garantía de obtener el conjunto de resultados correcto.
Considere el siguiente código, que tiene una consulta externa con un filtro WHERE contra una tabla derivada, que a su vez se basa en una expresión de tabla con un filtro TOP:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders ) AS D
WHERE orderdate >= '20180101'; Por supuesto, esta consulta no es determinista debido a la falta de una cláusula ORDER BY en la expresión de la tabla. Cuando lo ejecuté, SQL Server accedió a las primeras tres filas con fechas de pedido anteriores a 2018, por lo que obtuve un conjunto vacío como resultado:
orderid orderdate ----------- ---------- (0 rows affected)
Como se mencionó, el uso de TOP en la expresión de la tabla evitó el anidamiento/sustitución de la expresión de la tabla aquí. Si SQL Server hubiera anidado la expresión de la tabla, el proceso de sustitución habría dado como resultado el equivalente a la siguiente consulta:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101';
Esta consulta tampoco es determinista debido a la falta de la cláusula ORDER BY, pero claramente tiene un significado diferente al de la consulta original. Si la tabla Sales.Orders tiene al menos tres pedidos realizados en 2018 o después, y los tiene, esta consulta necesariamente devolverá tres filas, a diferencia de la consulta original. Este es el resultado que obtuve cuando ejecuté esta consulta:
orderid orderdate ----------- ---------- 10400 2018-01-01 10401 2018-01-01 10402 2018-01-02 (3 rows affected)
En caso de que la naturaleza no determinista de las dos consultas anteriores lo confunda, aquí hay un ejemplo con una consulta determinista:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderid ) AS D
WHERE orderdate >= '20170708'
ORDER BY orderid; La expresión de la tabla filtra los tres pedidos con los ID de pedido más bajos. La consulta externa luego filtra de esos tres pedidos solo aquellos que se realizaron el 8 de julio de 2017 o después. Resulta que solo hay un pedido que califica. Esta consulta genera el siguiente resultado:
orderid orderdate ----------- ---------- 10250 2017-07-08 (1 row affected)
Suponga que SQL Server anidó la expresión de la tabla en la consulta original, con el proceso de sustitución dando como resultado el siguiente equivalente de consulta:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20170708' ORDER BY orderid;
El significado de esta consulta es diferente a la consulta original. Esta consulta filtra primero los pedidos que se realizaron a partir del 8 de julio de 2017 y, a continuación, filtra los tres primeros entre los que tienen los ID de pedido más bajos. Esta consulta genera el siguiente resultado:
orderid orderdate ----------- ---------- 10250 2017-07-08 10251 2017-07-08 10252 2017-07-09 (3 rows affected)
Para evitar cambiar el significado de la consulta original, SQL Server no aplica anidamiento/sustitución aquí.
Los últimos dos ejemplos involucraron una combinación simple de filtrado WHERE y TOP, pero podría haber elementos conflictivos adicionales como resultado de la anidación. Por ejemplo, qué sucede si tiene diferentes especificaciones de ordenación en la expresión de la tabla y la consulta externa, como en el siguiente ejemplo:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC ) AS D
ORDER BY orderid; Se da cuenta de que si SQL Server desanimó la expresión de la tabla y fusionó las dos especificaciones de orden diferentes en una sola, la consulta resultante habría tenido un significado diferente al de la consulta original. Habría filtrado las filas incorrectas o presentado las filas de resultados en el orden de presentación incorrecto. En resumen, se da cuenta de por qué lo más seguro para SQL Server es evitar el anidamiento/sustitución de expresiones de tabla que se basan en consultas TOP y OFFSET-FETCH.
Mencioné anteriormente que hay una excepción a la regla de que el uso de TOP y OFFSET-FETCH evita el anidamiento. Ahí es cuando usa TOP (100) PERCENT en una expresión de tabla anidada, con o sin una cláusula ORDER BY. SQL Server se da cuenta de que no hay un filtrado real y optimiza la opción. Aquí hay un ejemplo que demuestra esto:
SELECT orderid, orderdate
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Se ignora el filtro TOP, se elimina el anidamiento y se obtiene el mismo plan que se mostró anteriormente para la Consulta 1 en la Figura 1.
Cuando se usa OFFSET 0 ROWS sin la cláusula FETCH en una expresión de tabla anidada, tampoco hay un filtrado real. Por lo tanto, en teoría, SQL Server también podría haber optimizado esta opción y habilitado el anidamiento, pero a la fecha de este escrito no lo hace. Aquí hay un ejemplo que demuestra esto:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1
WHERE orderdate >= '20180201'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2
WHERE orderdate >= '20180301'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3
WHERE orderdate >= '20180401'; Obtiene el mismo plan que el que se muestra anteriormente para la Consulta 2 en la Figura 2, lo que muestra que no se produjo el anidamiento.
Anteriormente expliqué que el proceso de anidamiento/sustitución en realidad no genera una nueva cadena de consulta que luego se optimiza, sino que tiene que ver con las transformaciones que SQL Server aplica al árbol de operadores lógicos. Existe una diferencia entre la forma en que SQL Server optimiza una consulta con expresiones de tablas anidadas frente a una consulta real lógicamente equivalente sin el anidamiento. El uso de expresiones de tabla, como tablas derivadas, así como subconsultas, impide la parametrización simple. Recuerde la Consulta 1 que se mostró anteriormente en el artículo:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Dado que la consulta utiliza tablas derivadas, no se realiza una parametrización simple. Es decir, SQL Server no reemplaza las constantes con parámetros y luego optimiza la consulta, sino que optimiza la consulta con las constantes. Con predicados basados en constantes, SQL Server puede fusionar los períodos que se cruzan, lo que en nuestro caso resultó en un solo predicado en el plan, como se muestra anteriormente en la Figura 1.
A continuación, considere la siguiente consulta (la llamaremos Consulta 3), que es un equivalente lógico de la Consulta 1, pero en la que usted mismo aplica el anidamiento:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401';
El plan para esta consulta se muestra en la Figura 3.
 Figura 3:Plan para la consulta 3
Figura 3:Plan para la consulta 3
Este plan se considera seguro para la parametrización simple, por lo que las constantes se sustituyen por parámetros y, en consecuencia, los predicados no se fusionan. La motivación para la parametrización es, por supuesto, aumentar la probabilidad de reutilización del plan cuando se ejecutan consultas similares que difieren solo en las constantes que utilizan.
Como se mencionó, el uso de tablas derivadas en la consulta 1 impidió la parametrización simple. De manera similar, el uso de subconsultas evitaría una parametrización simple. Por ejemplo, aquí está nuestra consulta anterior 3 con un predicado sin sentido basado en una subconsulta agregada a la cláusula WHERE:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401' AND (SELECT 42) = 42;
Esta vez no se lleva a cabo una parametrización simple, lo que permite que SQL Server fusione los períodos de intersección representados por los predicados con las constantes, lo que da como resultado el mismo plan que se muestra anteriormente en la Figura 1.
Si tienes consultas con expresiones de tabla que usan constantes, y es importante para ti que SQL Server parametrice el código, y por el motivo que sea no puedes parametrizarlo tú mismo, recuerda que tienes la opción de usar parametrización forzada con una guía de plan. Como ejemplo, el siguiente código crea una guía de plan de este tipo para la Consulta 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX);
EXEC sys.sp_get_query_template
@querytext = N'SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= ''20180101'' ) AS D1
WHERE orderdate >= ''20180201'' ) AS D2
WHERE orderdate >= ''20180301'' ) AS D3
WHERE orderdate >= ''20180401'';',
@templatetext = @stmt OUTPUT,
@parameters = @params OUTPUT;
EXEC sys.sp_create_plan_guide
@name = N'TG1',
@stmt = @stmt,
@type = N'TEMPLATE',
@module_or_batch = NULL,
@params = @params,
@hints = N'OPTION(PARAMETERIZATION FORCED)'; Vuelva a ejecutar Query 3 después de crear la guía del plan:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Obtiene el mismo plan que el que se muestra anteriormente en la Figura 3 con los predicados parametrizados.
Cuando haya terminado, ejecute el siguiente código para soltar la guía del plan:
EXEC sys.sp_control_plan_guide @operation = N'DROP', @name = N'TG1';
Evitar el anidamiento
Recuerde que SQL Server anula las expresiones de tablas por motivos de optimización. El objetivo es aumentar la probabilidad de encontrar un plan con un costo menor en comparación con el plan sin anidamiento. Eso es cierto para la mayoría de las reglas de transformación aplicadas por el optimizador. Sin embargo, podría haber algunos casos inusuales en los que desearía evitar el anidamiento. Esto podría ser para evitar errores (sí, en algunos casos inusuales, la eliminación del anidamiento puede generar errores) o por motivos de rendimiento para forzar una determinada forma del plan, similar al uso de otras sugerencias de rendimiento. Recuerde, tiene una manera simple de inhibir el anidamiento usando TOP con un número muy grande.
Ejemplo para evitar errores
Comenzaré con un caso en el que el anidamiento de las expresiones de la tabla puede generar errores.
Considere la siguiente consulta (la llamaremos Consulta 4):
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
Este ejemplo es un poco artificial en el sentido de que es fácil reescribir el predicado del segundo filtro para que nunca resulte en un error (descuento <0.1), pero es un ejemplo conveniente para ilustrar mi punto. Los descuentos no son negativos. Entonces, incluso si hay líneas de pedido con un descuento de cero, se supone que la consulta las filtrará (el primer predicado de filtro dice que el descuento debe ser mayor que el descuento mínimo en la tabla). Sin embargo, no hay seguridad de que SQL Server evalúe los predicados en orden escrito, por lo que no puede contar con un cortocircuito.
Examine el plan para la Consulta 4 que se muestra en la Figura 4.
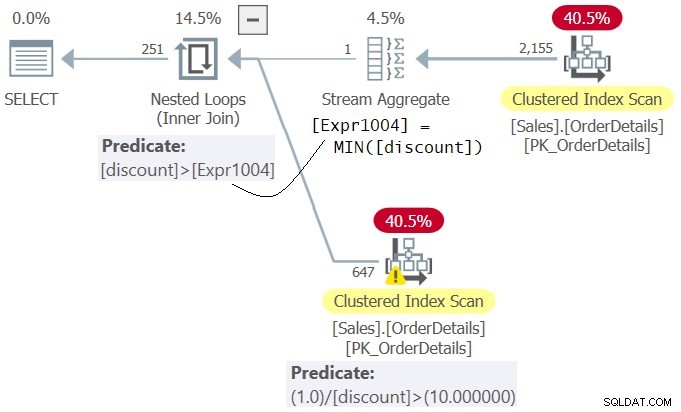 Figura 4:Plan para Consulta 4
Figura 4:Plan para Consulta 4
Observe que en el plan se evalúa el predicado 1.0 / descuento> 10.0 (segundo en la cláusula WHERE) antes que el predicado descuento>
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Tal vez esté pensando que puede evitar el error usando una tabla derivada, separando las tareas de filtrado en una interna y una externa, así:
SELECT orderid, productid, discount
FROM ( SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; Sin embargo, SQL Server aplica el anidamiento de la tabla derivada, lo que da como resultado el mismo plan que se muestra anteriormente en la Figura 4 y, en consecuencia, este código también falla con un error de división por cero:
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Una solución simple aquí es introducir un inhibidor de anidamiento, así (llamaremos a esta solución Consulta 5):
SELECT orderid, productid, discount
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; El plan para la Consulta 5 se muestra en la Figura 5.
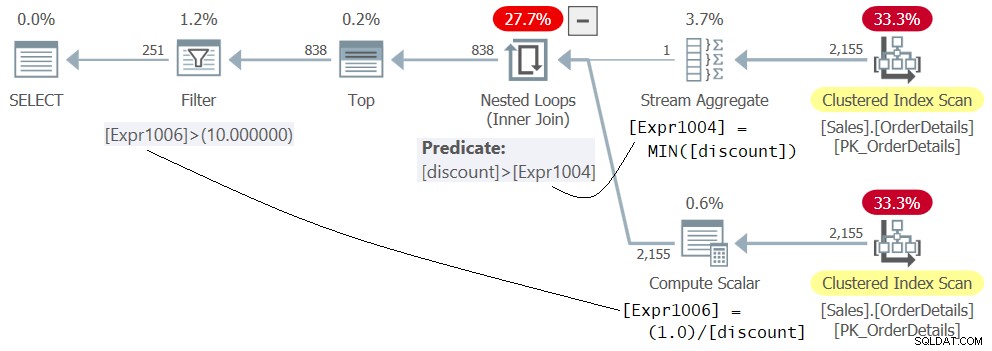 Figura 5:Plan para Consulta 5
Figura 5:Plan para Consulta 5
No se confunda por el hecho de que la expresión 1.0 / descuento aparece en la parte interna del operador Nested Loops, como si se evaluara primero. Esta es solo la definición del miembro Expr1006. El operador Filter aplica la evaluación real del predicado Expr1006> 10.0 como el último paso del plan después de que el operador Nested Loops filtrara las filas con el descuento mínimo anteriormente. Esta solución se ejecuta correctamente sin errores.
Ejemplo por motivos de rendimiento
Continuaré con un caso en el que el anidamiento de las expresiones de la tabla puede perjudicar el rendimiento.
Comience ejecutando el siguiente código para cambiar el contexto a la base de datos PerformanceV5 y habilite STATISTICS IO y TIME:
USE PerformanceV5; SET STATISTICS IO, TIME ON;
Considere la siguiente consulta (la llamaremos Consulta 6):
SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid;
El optimizador identifica un índice de cobertura de apoyo con shipperid y orderdate como claves principales. Por lo tanto, crea un plan con un escaneo ordenado del índice seguido de un operador de Agregado de flujo basado en órdenes, como se muestra en el plan para la Consulta 6 en la Figura 6.
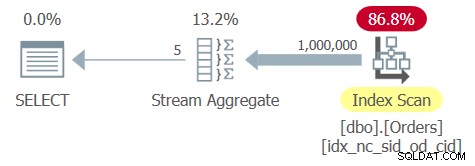 Figura 6:Plan para Consulta 6
Figura 6:Plan para Consulta 6
La tabla Pedidos tiene 1 000 000 filas y la columna de agrupación shipperid es muy densa:solo hay 5 ID de remitente distintos, lo que da como resultado una densidad del 20 % (porcentaje promedio por valor distinto). La aplicación de un escaneo completo de la hoja de índice implica la lectura de unos pocos miles de páginas, lo que resulta en un tiempo de ejecución de aproximadamente un tercio de segundo en mi sistema. Aquí están las estadísticas de rendimiento que obtuve para la ejecución de esta consulta:
CPU time = 344 ms, elapsed time = 346 ms, logical reads = 3854
El árbol de índice tiene actualmente tres niveles de profundidad.
Escalemos el número de pedidos por un factor de 1,000 a 1,000,000,000, pero aún con solo 5 remitentes distintos. El número de páginas en la hoja de índice crecería por un factor de 1000, y el árbol de índice probablemente resultaría en un nivel adicional (cuatro niveles de profundidad). Este plan tiene escala lineal. Terminaría con cerca de 4 000 000 de lecturas lógicas y un tiempo de ejecución de unos pocos minutos.
Cuando necesita calcular un agregado MÍN o MÁX en una tabla grande, con una densidad muy alta en la columna de agrupación (¡importante!) y un índice de árbol B compatible con clave en la columna de agrupación y la columna de agregación, existe una opción mucho más óptima. forma de plan que la de la Figura 6. Imagine una forma de plan que escanea el pequeño conjunto de ID de remitentes de algún índice en la tabla Transportistas y, en un ciclo, aplica para cada remitente una búsqueda contra el índice de soporte en Pedidos para obtener el agregado. Con 1.000.000 de filas en la tabla, 5 búsquedas implicarían 15 lecturas. Con 1 000 000 000 de filas, 5 búsquedas implicarían 20 lecturas. Con un billón de filas, 25 lecturas en total. Claramente, un plan mucho más óptimo. De hecho, puede lograr un plan de este tipo consultando la tabla Transportistas y obteniendo el agregado mediante una subconsulta agregada escalar en Órdenes, así (llamaremos a esta solución Consulta 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid = S.shipperid) AS maxod FROM dbo.Shippers AS S;
El plan para esta consulta se muestra en la Figura 7.
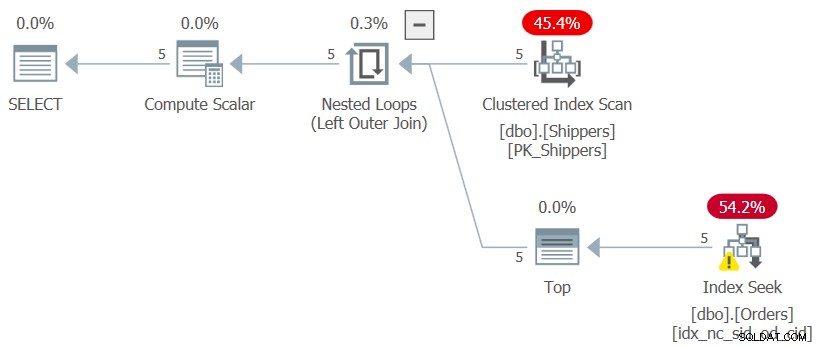 Figura 7:Plan para Consulta 7
Figura 7:Plan para Consulta 7
Se logra la forma deseada del plan y los números de rendimiento para la ejecución de esta consulta son insignificantes como se esperaba:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Siempre que la columna de agrupación sea muy densa, el tamaño de la tabla Pedidos se vuelve prácticamente insignificante.
Pero espera un momento antes de ir a celebrar. Hay un requisito para mantener solo a los remitentes cuya fecha máxima de pedido relacionado en la tabla Pedidos sea a partir de 2018. Suena como una adición bastante simple. Defina una tabla derivada basada en la Consulta 7 y aplique el filtro en la consulta externa, así (llamaremos a esta solución Consulta 8):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Por desgracia, SQL Server anula la consulta de tabla derivada, así como la subconsulta, convirtiendo la lógica de agregación en el equivalente de la lógica de consulta agrupada, con shipperid como columna de agrupación. Y la forma en que SQL Server sabe optimizar una consulta agrupada se basa en un solo paso sobre los datos de entrada, lo que da como resultado un plan muy similar al que se muestra anteriormente en la Figura 6, solo que con el filtro adicional. El plan para la Consulta 8 se muestra en la Figura 8.
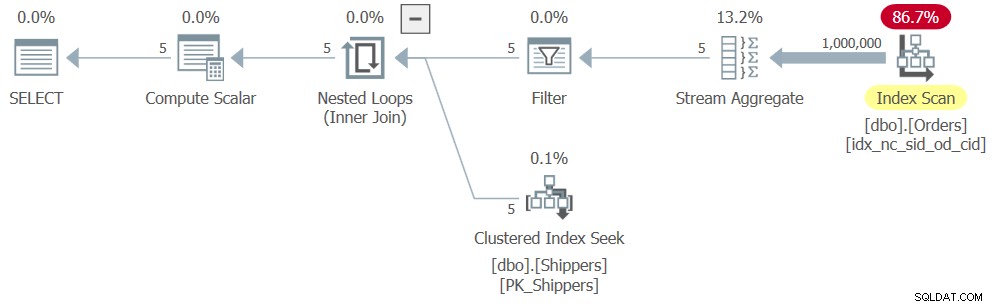 Figura 8:Plan para Consulta 8
Figura 8:Plan para Consulta 8
En consecuencia, la escala es lineal y los números de rendimiento son similares a los de la Consulta 6:
CPU time = 328 ms, elapsed time = 325 ms, logical reads = 3854
La solución es introducir un inhibidor de anidamiento. Esto se puede hacer agregando un filtro TOP a la expresión de la tabla en la que se basa la tabla derivada, así (llamaremos a esta solución Consulta 9):
SELECT shipperid, maxod
FROM ( SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; El plan para esta consulta se muestra en la Figura 9 y tiene la forma de plan deseada con las búsquedas:
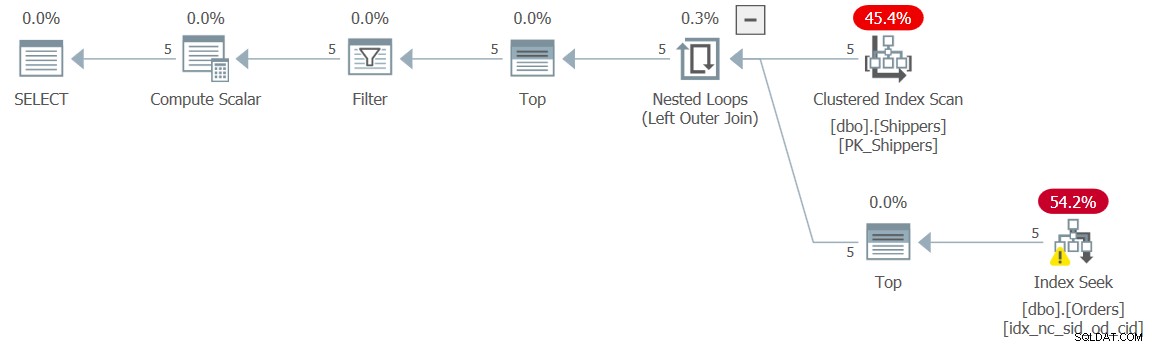 Figura 9:Plan para Consulta 9
Figura 9:Plan para Consulta 9
Los números de rendimiento para esta ejecución son, por supuesto, insignificantes:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Otra opción más es evitar el anidamiento de la subconsulta reemplazando el agregado MAX con un filtro TOP (1) equivalente, así (llamaremos a esta solución Consulta 10):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; El plan para esta consulta se muestra en la Figura 10 y, nuevamente, tiene la forma deseada con las búsquedas.
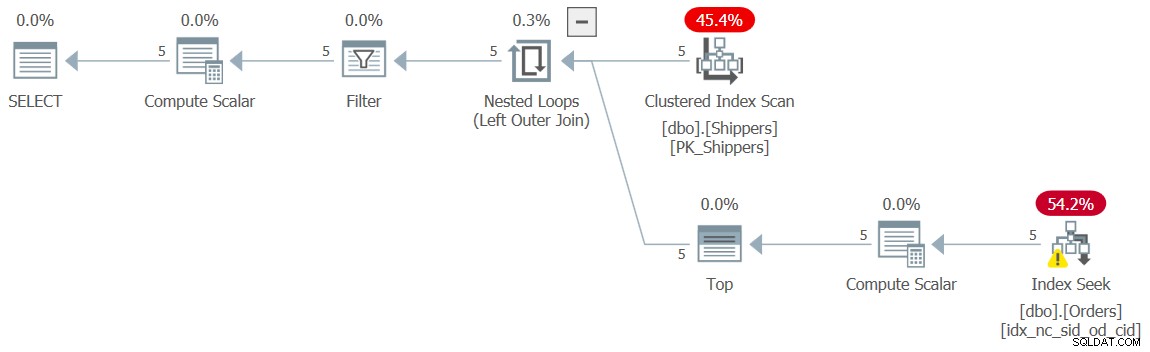 Figura 10:Plan para Consulta 10
Figura 10:Plan para Consulta 10
Obtuve los números de rendimiento insignificantes familiares para esta ejecución:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Cuando haya terminado, ejecute el siguiente código para dejar de generar informes de estadísticas de rendimiento:
SET STATISTICS IO, TIME OFF;
Resumen
En este artículo continué la discusión que comencé el mes pasado sobre la optimización de las tablas derivadas. Este mes me concentré en el anidamiento de tablas derivadas. Expliqué que, por lo general, la anulación da como resultado un plan más óptimo en comparación con la anulación, pero también cubrí ejemplos en los que no es deseable. Mostré un ejemplo en el que el anidamiento resultó en un error, así como un ejemplo que resultó en una degradación del rendimiento. Demostré cómo evitar la anulación mediante la aplicación de un inhibidor de anidación como TOP.
El próximo mes continuaré la exploración de las expresiones de tabla con nombre, cambiando el enfoque a CTE.