Este artículo es la séptima parte de una serie sobre expresiones de tabla con nombre. En las Partes 5 y 6 cubrí los aspectos conceptuales de las expresiones de tabla comunes (CTE). Este mes y el próximo mi atención se centrará en las consideraciones de optimización de CTE.
Comenzaré revisando rápidamente el concepto de anidamiento de las expresiones de tabla con nombre y demostraré su aplicabilidad a CTE. Luego me centraré en las consideraciones de persistencia. Hablaré sobre los aspectos de persistencia de CTE recursivos y no recursivos. Explicaré cuándo tiene sentido ceñirse a CTE frente a cuándo tiene más sentido trabajar con tablas temporales.
En mis ejemplos continuaré usando las bases de datos de muestra TSQLV5 y PerformanceV5. Puede encontrar el script que crea y completa TSQLV5 aquí, y su diagrama ER aquí. Puede encontrar el script que crea y completa PerformanceV5 aquí.
Sustitución/anulación
En la Parte 4 de la serie, que se centró en la optimización de las tablas derivadas, describí un proceso de anidación/sustitución de expresiones de tablas. Expliqué que cuando SQL Server optimiza una consulta que involucra tablas derivadas, aplica reglas de transformación al árbol inicial de operadores lógicos producidos por el analizador, posiblemente cambiando las cosas a lo largo de lo que originalmente eran límites de expresión de tabla. Esto sucede hasta el punto de que cuando compara un plan para una consulta que usa tablas derivadas con un plan para una consulta que va directamente contra las tablas base subyacentes donde usted mismo aplicó la lógica de anidamiento, se ven iguales. También describí una técnica para evitar el anidamiento usando el filtro TOP con una gran cantidad de filas como entrada. Demostré un par de casos en los que esta técnica fue muy útil:uno en el que el objetivo era evitar errores y otro por motivos de optimización.
La versión TL;DR de sustitución/anulación de CTE es que el proceso es el mismo que con las tablas derivadas. Si está satisfecho con esta declaración, puede omitir esta sección y pasar directamente a la siguiente sección sobre Persistencia. No te perderás nada importante que no hayas leído antes. Sin embargo, si eres como yo, probablemente quieras una prueba de que ese es el caso. Luego, probablemente querrá continuar leyendo esta sección y probar el código que uso mientras reviso los ejemplos clave de anidamiento que demostré anteriormente con tablas derivadas y los convierto para usar CTE.
En la Parte 4 demostré la siguiente consulta (la llamaremos Consulta 1):
USE TSQLV5;
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; La consulta implica tres niveles de anidamiento de tablas derivadas, además de una consulta externa. Cada nivel filtra un rango diferente de fechas de pedido. El plan para la Consulta 1 se muestra en la Figura 1.
 Figura 1:Plan de ejecución para la consulta 1
Figura 1:Plan de ejecución para la consulta 1
El plan de la Figura 1 muestra claramente que se deshizo el anidamiento de las tablas derivadas, ya que todos los predicados de filtro se fusionaron en un único predicado de filtro abarcador.
Le expliqué que puede evitar el proceso de anidamiento mediante el uso de un filtro SUPERIOR significativo (a diferencia del 100 POR CIENTO SUPERIOR) con una gran cantidad de filas como entrada, como muestra la siguiente consulta (la llamaremos Consulta 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; El plan para la Consulta 2 se muestra en la Figura 2.
 Figura 2:Plan de ejecución para Consulta 2
Figura 2:Plan de ejecución para Consulta 2
El plan muestra claramente que no se anidó, ya que puede ver efectivamente los límites de la tabla derivada.
Probemos los mismos ejemplos usando CTE. Aquí está la Consulta 1 convertida para usar CTE:
WITH C1 AS
(
SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; Obtiene exactamente el mismo plan que se muestra anteriormente en la Figura 1, donde puede ver que se llevó a cabo el desanidamiento.
Aquí está la Consulta 2 convertida para usar CTE:
WITH C1 AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101'
),
C2 AS
(
SELECT TOP (9223372036854775807) *
FROM C1
WHERE orderdate >= '20180201'
),
C3 AS
(
SELECT TOP (9223372036854775807) *
FROM C2
WHERE orderdate >= '20180301'
)
SELECT orderid, orderdate
FROM C3
WHERE orderdate >= '20180401'; Obtiene el mismo plan que se muestra anteriormente en la Figura 2, donde puede ver que no se desanimó.
A continuación, revisemos los dos ejemplos que usé para demostrar la practicidad de la técnica para evitar el desanidamiento, solo que esta vez usando CTE.
Comencemos con la consulta errónea. La siguiente consulta intenta devolver líneas de pedido con un descuento mayor que el descuento mínimo y donde el recíproco del descuento es mayor que 10:
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
El descuento mínimo no puede ser negativo, sino cero o superior. Entonces, probablemente esté pensando que si una fila tiene un descuento de cero, el primer predicado debería evaluarse como falso y que un cortocircuito debería evitar el intento de evaluar el segundo predicado, evitando así un error. Sin embargo, cuando ejecuta este código, obtiene un error de división por cero:
Msg 8134, Level 16, State 1, Line 99 Divide by zero error encountered.
El problema es que, aunque SQL Server admite un concepto de cortocircuito en el nivel de procesamiento físico, no hay garantía de que evaluará los predicados de filtro en orden escrito de izquierda a derecha. Un intento común de evitar tales errores es usar una expresión de tabla con nombre que controle la parte de la lógica de filtrado que desea que se evalúe en primer lugar y que la consulta externa controle la lógica de filtrado que desea que se evalúe en segundo lugar. Aquí está el intento de solución usando un CTE:
WITH C AS
(
SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0; Sin embargo, desafortunadamente, la anulación de la expresión de la tabla da como resultado un equivalente lógico a la consulta de la solución original, y cuando intenta ejecutar este código, obtiene un error de división por cero nuevamente:
Msg 8134, Level 16, State 1, Line 108 Divide by zero error encountered.
Al usar nuestro truco con el filtro TOP en la consulta interna, evita que se anide la expresión de la tabla, así:
WITH C AS
(
SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails)
)
SELECT orderid, productid, discount
FROM C
WHERE 1.0 / discount > 10.0; Esta vez el código se ejecuta correctamente sin ningún error.
Pasemos al ejemplo en el que utiliza la técnica para evitar el anidamiento por razones de optimización. El siguiente código devuelve solo remitentes con una fecha máxima de pedido a partir del 1 de enero de 2018:
USE PerformanceV5;
WITH C AS
(
SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
WHERE maxod >= '20180101'; Si se pregunta por qué no utilizar una solución mucho más sencilla con una consulta agrupada y un filtro HAVING, tiene que ver con la densidad de la columna shipperid. La tabla Pedidos tiene 1.000.000 de pedidos y los envíos de esos pedidos los manejaron cinco transportistas, lo que significa que, en promedio, cada transportista manejó el 20 % de los pedidos. El plan para una consulta agrupada que calcula la fecha máxima de pedido por remitente escanearía las 1.000.000 de filas, lo que daría como resultado miles de lecturas de páginas. De hecho, si resalta solo la consulta interna de CTE (la llamaremos Consulta 3) que calcula la fecha máxima de pedido por remitente y verifica su plan de ejecución, obtendrá el plan que se muestra en la Figura 3.
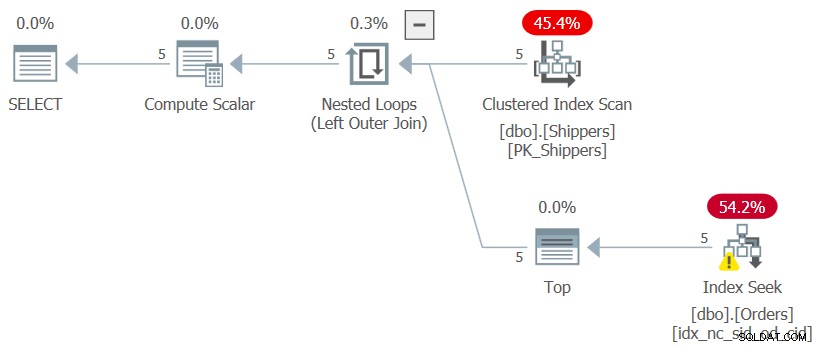 Figura 3:Plan de ejecución para Consulta 3
Figura 3:Plan de ejecución para Consulta 3
El plan escanea cinco filas en el índice agrupado en Transportistas. Por remitente, el plan aplica una búsqueda contra un índice de cobertura en Pedidos, donde (shipperid, orderdate) son las claves principales del índice, yendo directamente a la última fila en cada sección de remitente en el nivel de hoja para extraer la fecha máxima de pedido para el actual expedidor. Dado que solo tenemos cinco cargadores, solo hay cinco operaciones de búsqueda de índice, lo que resulta en un plan muy eficiente. Estas son las medidas de rendimiento que obtuve cuando ejecuté la consulta interna de CTE:
duration: 0 ms, CPU: 0 ms, reads: 15
Sin embargo, cuando ejecuta la solución completa (la llamaremos Consulta 4), obtiene un plan completamente diferente, como se muestra en la Figura 4.
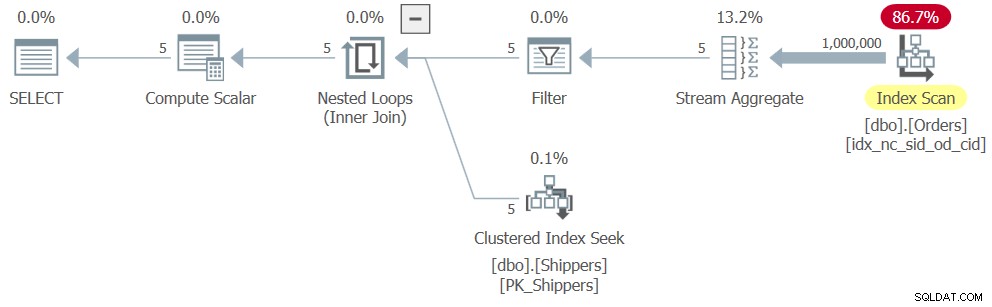 Figura 4:Plan de ejecución para Consulta 4
Figura 4:Plan de ejecución para Consulta 4
Lo que sucedió es que SQL Server anidó la expresión de la tabla, convirtiendo la solución en un equivalente lógico de una consulta agrupada, lo que resultó en un escaneo completo del índice en Pedidos. Estas son las cifras de rendimiento que obtuve para esta solución:
duration: 316 ms, CPU: 281 ms, reads: 3854
Lo que necesitamos aquí es evitar que se produzca el anidamiento de la expresión de la tabla, de modo que la consulta interna se optimice con búsquedas contra el índice en Pedidos, y para que la consulta externa solo resulte en una adición de un operador de filtro en el plan. Esto se logra usando nuestro truco agregando un filtro TOP a la consulta interna, así (llamaremos a esta solución Consulta 5):
WITH C AS
(
SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S
)
SELECT shipperid, maxod
FROM C
WHERE maxod >= '20180101'; El plan para esta solución se muestra en la Figura 5.
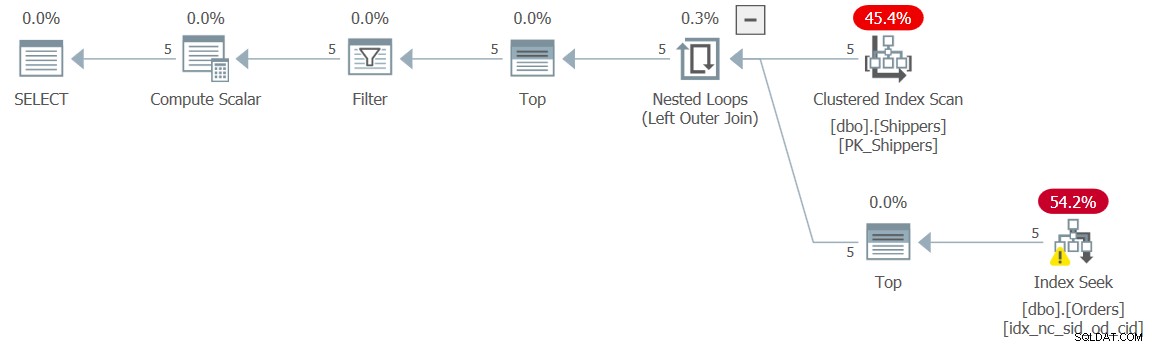 Figura 5:Plan de ejecución para Consulta 5
Figura 5:Plan de ejecución para Consulta 5
El plan muestra que se logró el efecto deseado y, en consecuencia, los números de rendimiento lo confirman:
duration: 0 ms, CPU: 0 ms, reads: 15
Por lo tanto, nuestras pruebas confirman que SQL Server maneja la sustitución/anulación de CTE como lo hace con las tablas derivadas. Esto significa que no debe preferir uno sobre el otro por motivos de optimización, sino por las diferencias conceptuales que le interesan, como se explica en la Parte 5.
Persistencia
Un concepto erróneo común con respecto a las CTE y las expresiones de tabla con nombre en general es que sirven como una especie de vehículo de persistencia. Algunos piensan que SQL Server conserva el conjunto de resultados de la consulta interna en una tabla de trabajo y que la consulta externa en realidad interactúa con esa tabla de trabajo. En la práctica, los CTE regulares no recursivos y las tablas derivadas no se conservan. Describí la lógica de anidamiento que aplica SQL Server al optimizar una consulta que involucra expresiones de tabla, lo que da como resultado un plan que interactúa directamente con las tablas base subyacentes. Tenga en cuenta que el optimizador puede optar por usar tablas de trabajo para conservar conjuntos de resultados intermedios si tiene sentido hacerlo por motivos de rendimiento u otros, como la protección de Halloween. Cuando lo haga, verá los operadores Spool o Index Spool en el plan. Sin embargo, tales opciones no están relacionadas con el uso de expresiones de tabla en la consulta.
CTEs recursivos
Hay un par de excepciones en las que SQL Server conserva los datos de la expresión de la tabla. Uno es el uso de vistas indexadas. Si crea un índice agrupado en una vista, SQL Server conserva el conjunto de resultados de la consulta interna en el índice agrupado de la vista y lo mantiene sincronizado con cualquier cambio en las tablas base subyacentes. La otra excepción es cuando utiliza consultas recursivas. SQL Server necesita conservar los conjuntos de resultados intermedios de las consultas ancla y recursivas en un spool para poder acceder al conjunto de resultados de la última ronda representado por la referencia recursiva al nombre de CTE cada vez que se ejecuta el miembro recursivo.
Para demostrar esto, usaré una de las consultas recursivas de la Parte 6 de la serie.
Use el siguiente código para crear la tabla Empleados en la base de datos tempdb, complétela con datos de muestra y cree un índice de apoyo:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.Employees;
GO
CREATE TABLE dbo.Employees
(
empid INT NOT NULL
CONSTRAINT PK_Employees PRIMARY KEY,
mgrid INT NULL
CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees,
empname VARCHAR(25) NOT NULL,
salary MONEY NOT NULL,
CHECK (empid <> mgrid)
);
INSERT INTO dbo.Employees(empid, mgrid, empname, salary)
VALUES(1, NULL, 'David' , $10000.00),
(2, 1, 'Eitan' , $7000.00),
(3, 1, 'Ina' , $7500.00),
(4, 2, 'Seraph' , $5000.00),
(5, 2, 'Jiru' , $5500.00),
(6, 2, 'Steve' , $4500.00),
(7, 3, 'Aaron' , $5000.00),
(8, 5, 'Lilach' , $3500.00),
(9, 7, 'Rita' , $3000.00),
(10, 5, 'Sean' , $3000.00),
(11, 7, 'Gabriel', $3000.00),
(12, 9, 'Emilia' , $2000.00),
(13, 9, 'Michael', $2000.00),
(14, 9, 'Didi' , $1500.00);
CREATE UNIQUE INDEX idx_unc_mgrid_empid
ON dbo.Employees(mgrid, empid)
INCLUDE(empname, salary);
GO Usé el siguiente CTE recursivo para devolver todos los subordinados de un administrador raíz del subárbol de entrada, usando el empleado 3 como administrador de entrada en este ejemplo:
DECLARE @root AS INT = 3;
WITH C AS
(
SELECT empid, mgrid, empname
FROM dbo.Employees
WHERE empid = @root
UNION ALL
SELECT S.empid, S.mgrid, S.empname
FROM C AS M
INNER JOIN dbo.Employees AS S
ON S.mgrid = M.empid
)
SELECT empid, mgrid, empname
FROM C; El plan para esta consulta (la llamaremos Consulta 6) se muestra en la Figura 6.
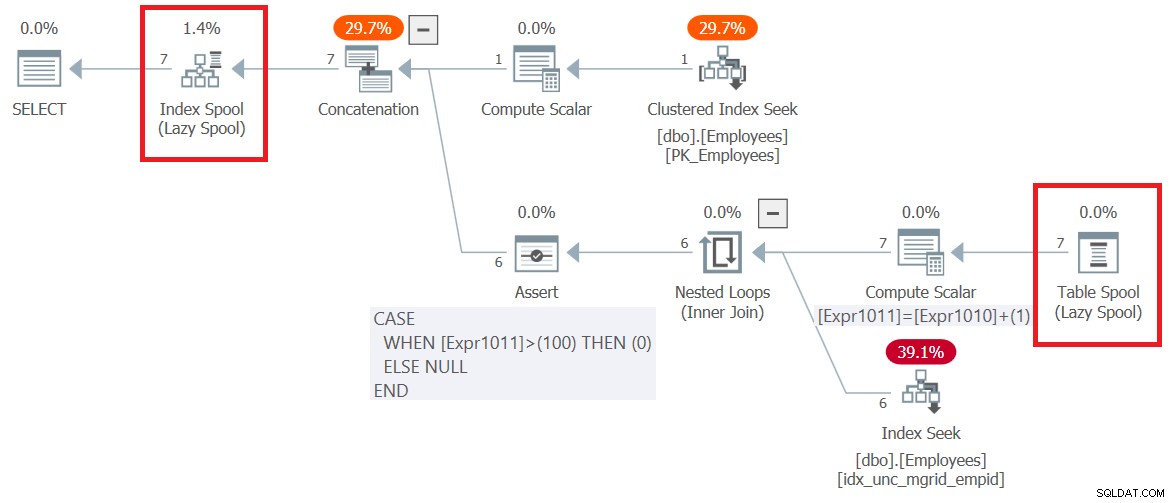 Figura 6:Plan de ejecución para Consulta 6
Figura 6:Plan de ejecución para Consulta 6
Observe que lo primero que sucede en el plan, a la derecha del nodo raíz SELECT, es la creación de una tabla de trabajo basada en un árbol B representada por el operador Index Spool. La parte superior del plan maneja la lógica del miembro ancla. Extrae las filas de empleados de entrada del índice agrupado en Empleados y las escribe en el spool. La parte inferior del plan representa la lógica del miembro recursivo. Se ejecuta repetidamente hasta que devuelve un conjunto de resultados vacío. La entrada exterior al operador Nested Loops obtiene los gestores de la ronda anterior del spool (operador Table Spool). La entrada interna usa un operador de búsqueda de índice contra un índice no agrupado creado en Empleados (mgrid, empid) para obtener los subordinados directos de los gerentes de la ronda anterior. El conjunto de resultados de cada ejecución de la parte inferior del plan también se escribe en el spool de índice. Observe que, en total, se escribieron 7 filas en el carrete. Uno devuelto por el miembro ancla y 6 más devueltos por todas las ejecuciones del miembro recursivo.
Aparte, es interesante notar cómo el plan maneja el límite máximo de recursividad predeterminado, que es 100. Observe que el operador Compute Scalar inferior sigue aumentando un contador interno llamado Expr1011 en 1 con cada ejecución del miembro recursivo. Luego, el operador Assert establece un indicador en cero si este contador excede 100. Si esto sucede, SQL Server detiene la ejecución de la consulta y genera un error.
Cuándo no persistir
Volviendo a los CTE no recursivos, que normalmente no se persisten, depende de usted averiguar desde una perspectiva de optimización cuándo es bueno usarlos en lugar de herramientas de persistencia reales como tablas temporales y variables de tabla. Repasaré un par de ejemplos para demostrar cuándo cada enfoque es más óptimo.
Comencemos con un ejemplo donde los CTE funcionan mejor que las tablas temporales. Ese suele ser el caso cuando no tiene múltiples evaluaciones del mismo CTE, sino quizás solo una solución modular donde cada CTE se evalúa solo una vez. El siguiente código (lo llamaremos consulta 7) consulta la tabla de pedidos en la base de datos de rendimiento, que tiene 1 000 000 de filas, para devolver años de pedidos en los que más de 70 clientes distintos realizaron pedidos:
USE PerformanceV5;
WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM dbo.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70; Esta consulta genera el siguiente resultado:
orderyear numcusts ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000
Ejecuté este código con SQL Server 2019 Developer Edition y obtuve el plan que se muestra en la Figura 7.
 Figura 7:Plan de ejecución para Query 7
Figura 7:Plan de ejecución para Query 7
Tenga en cuenta que la eliminación del anidamiento de la CTE resultó en un plan que extrae los datos de un índice en la tabla Pedidos y no implica ningún almacenamiento en cola del conjunto de resultados de la consulta interna de la CTE. Obtuve los siguientes números de rendimiento al ejecutar esta consulta en mi máquina:
duration: 265 ms, CPU: 828 ms, reads: 3970, writes: 0
Ahora probemos una solución que usa tablas temporales en lugar de CTE (la llamaremos Solución 8), así:
SELECT YEAR(orderdate) AS orderyear, custid INTO #T1 FROM dbo.Orders; SELECT orderyear, COUNT(DISTINCT custid) AS numcusts INTO #T2 FROM #T1 GROUP BY orderyear; SELECT orderyear, numcusts FROM #T2 WHERE numcusts > 70; DROP TABLE #T1, #T2;
Los planes para esta solución se muestran en la Figura 8.
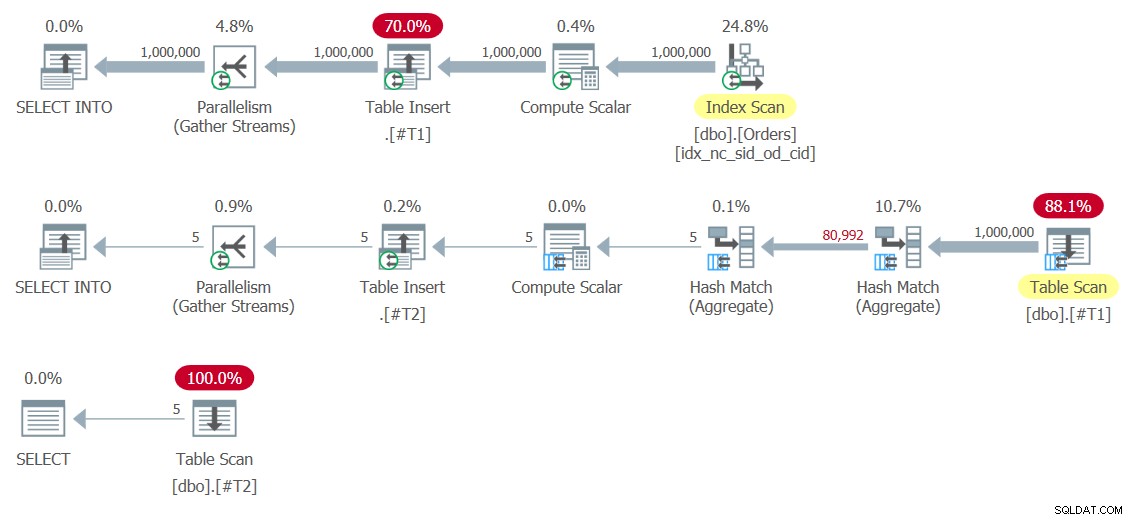 Figura 8:Planes para la Solución 8
Figura 8:Planes para la Solución 8
Observe que los operadores de inserción de tabla escriben los conjuntos de resultados en las tablas temporales #T1 y #T2. El primero es especialmente caro ya que escribe 1.000.000 de filas en #T1. Aquí están los números de rendimiento que obtuve para esta ejecución:
duration: 454 ms, CPU: 1517 ms, reads: 14359, writes: 359
Como ves, la solución con los CTE es mucho más óptima.
Cuándo persistir
Entonces, ¿es siempre preferible una solución modular que implique una sola evaluación de cada CTE al uso de tablas temporales? No necesariamente. En las soluciones basadas en CTE que involucran muchos pasos y dan como resultado planes elaborados donde el optimizador necesita aplicar muchas estimaciones de cardinalidad en muchos puntos diferentes del plan, podría terminar con inexactitudes acumuladas que resultan en elecciones subóptimas. Una de las técnicas para tratar de abordar estos casos es conservar algunos conjuntos de resultados intermedios en tablas temporales e incluso crear índices en ellos si es necesario, lo que le da al optimizador un nuevo comienzo con estadísticas nuevas, lo que aumenta la probabilidad de estimaciones de cardinalidad de mejor calidad que es de esperar que conduzca a opciones más óptimas. Si esto es mejor que una solución que no usa tablas temporales es algo que deberá probar. A veces, valdrá la pena la compensación del costo adicional por la persistencia de conjuntos de resultados intermedios en aras de obtener estimaciones de cardinalidad de mejor calidad.
Otro caso típico donde el uso de tablas temporales es el enfoque preferido es cuando la solución basada en CTE tiene múltiples evaluaciones del mismo CTE, y la consulta interna de CTE es bastante costosa. Considere la siguiente solución basada en CTE (la llamaremos Consulta 9), que hace coincidir cada año y mes de pedido con un año y mes de pedido diferente que tiene el recuento de pedidos más cercano:
WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate)
)
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2; Esta consulta genera el siguiente resultado:
orderyear ordermonth numorders orderyear2 ordermonth2 numorders2 ----------- ----------- ----------- ----------- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 2016 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 rows affected)
El plan para la Consulta 9 se muestra en la Figura 9.
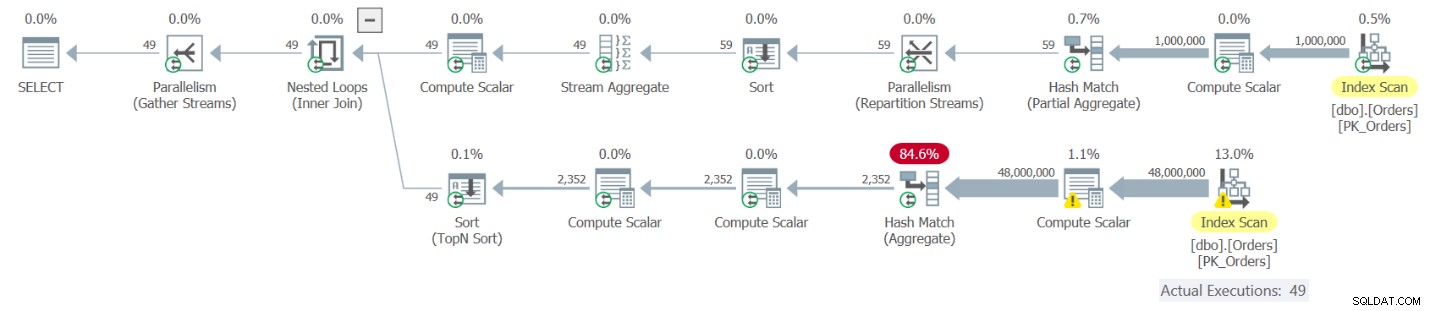 Figura 9:Plan de ejecución para Consulta 9
Figura 9:Plan de ejecución para Consulta 9
La parte superior del plan corresponde a la instancia de OrdCount CTE que tiene el alias O1. Esta referencia da como resultado una evaluación del CTE OrdCount. Esta parte del plan extrae las filas de un índice en la tabla Pedidos, las agrupa por año y mes y agrega el recuento de pedidos por grupo, lo que da como resultado 49 filas. La parte inferior del plan corresponde a la tabla derivada correlacionada O2, que se aplica por fila desde O1, por lo que se ejecuta 49 veces. Cada ejecución consulta el OrdCount CTE y, por lo tanto, da como resultado una evaluación separada de la consulta interna del CTE. Puede ver que la parte inferior del plan escanea todas las filas del índice en Pedidos, los agrupa y los agrega. Básicamente, obtiene un total de 50 evaluaciones del CTE, lo que da como resultado un escaneo de 50 veces de las 1 000 000 filas de Órdenes, agrupándolas y agregándolas. No parece una solución muy eficiente. Estas son las medidas de rendimiento que obtuve al ejecutar esta solución en mi máquina:
duration: 16 seconds, CPU: 56 seconds, reads: 130404, writes: 0
Dado que solo hay unas pocas docenas de meses involucrados, lo que sería mucho más eficiente es usar una tabla temporal para almacenar el resultado de una sola actividad que agrupe y agregue las filas de Pedidos, y luego tenga las entradas externas e internas de el operador APPLY interactúa con la tabla temporal. Aquí está la solución (la llamaremos Solución 10) usando una tabla temporal en lugar del CTE:
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth,
COUNT(*) AS numorders
INTO #OrdCount
FROM dbo.Orders
GROUP BY YEAR(orderdate), MONTH(orderdate);
SELECT O1.orderyear, O1.ordermonth, O1.numorders,
O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2,
O2.numorders AS numorders2
FROM #OrdCount AS O1
CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders
FROM #OrdCount AS O2
WHERE O2.orderyear <> O1.orderyear
OR O2.ordermonth <> O1.ordermonth
ORDER BY ABS(O1.numorders - O2.numorders),
O2.orderyear, O2.ordermonth ) AS O2;
DROP TABLE #OrdCount; Aquí no tiene mucho sentido indexar la tabla temporal, ya que el filtro TOP se basa en un cálculo en su especificación de orden y, por lo tanto, es inevitable ordenar. Sin embargo, es muy posible que en otros casos, con otras soluciones, también sea relevante que considere indexar sus tablas temporales. En cualquier caso, el plan para esta solución se muestra en la Figura 10.
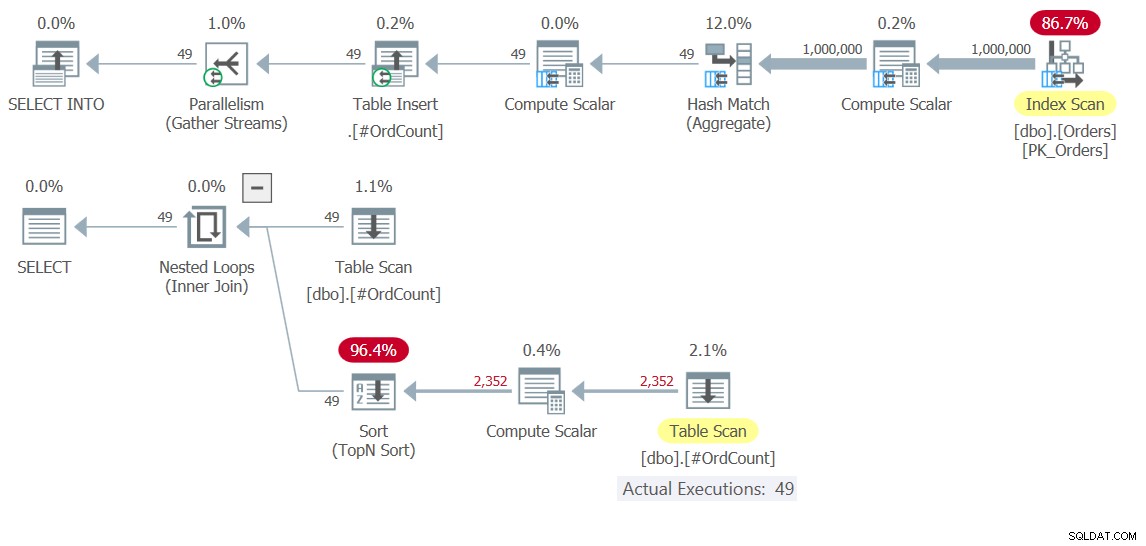 Figura 10:Planes de ejecución para Solution 10
Figura 10:Planes de ejecución para Solution 10
Observe en el plan superior cómo el trabajo pesado que involucra escanear 1,000,000 de filas, agruparlas y agregarlas, ocurre solo una vez. Se escriben 49 filas en la tabla temporal #OrdCount, y luego el plan inferior interactúa con la tabla temporal para las entradas externas e internas del operador Nested Loops, que maneja la lógica del operador APPLY.
Aquí están los números de rendimiento que obtuve para la ejecución de esta solución:
duration: 0.392 seconds, CPU: 0.5 seconds, reads: 3636, writes: 3
Es más rápido en órdenes de magnitud que la solución basada en CTE.
¿Qué sigue?
En este artículo comencé la cobertura de las consideraciones de optimización relacionadas con CTE. Mostré que el proceso de anidamiento/sustitución que tiene lugar con tablas derivadas funciona de la misma manera con CTE. También discutí el hecho de que los CTE no recursivos no se persisten y expliqué que cuando la persistencia es un factor importante para el rendimiento de su solución, debe manejarlo usted mismo mediante el uso de herramientas como tablas temporales y variables de tabla. El próximo mes continuaré la discusión cubriendo aspectos adicionales de la optimización de CTE.