Esta es la parte final de una serie de cinco partes que profundiza en la forma en que comienzan a ejecutarse los planes paralelos en modo fila de SQL Server. La parte 1 inicializó el contexto de ejecución cero para la tarea principal y la parte 2 creó el árbol de exploración de consultas. La parte 3 inició el análisis de consultas, realizó algunas fases iniciales y comenzó las primeras tareas paralelas adicionales en la rama C. La parte 4 describía la sincronización de intercambio y la puesta en marcha de las ramas C y D del plan paralelo.
Inicio de tareas paralelas de la rama B
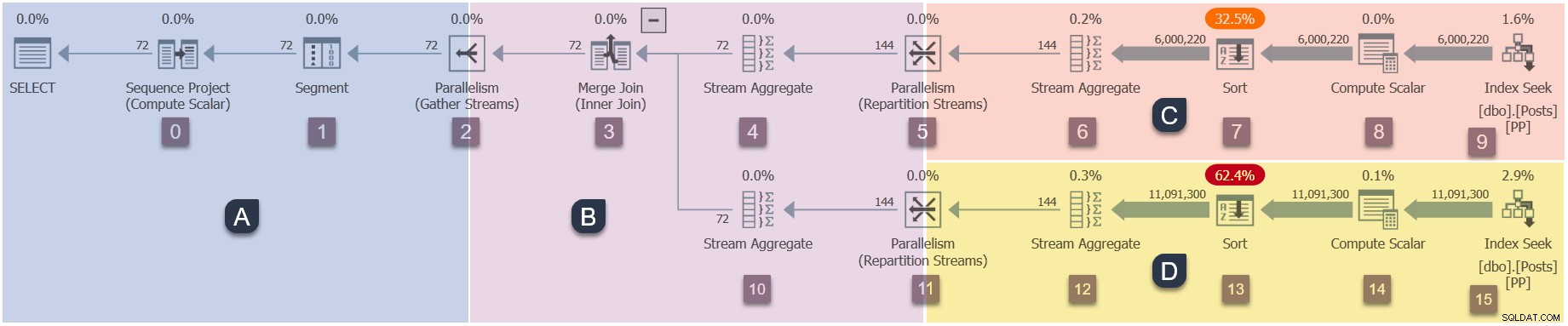
Un recordatorio de las sucursales en este plan paralelo (haga clic para ampliar):
Esta es la cuarta etapa en la secuencia de ejecución:
- Rama A (tarea principal).
- Sucursal C (tareas paralelas adicionales).
- Sucursal D (tareas paralelas adicionales).
- Rama B (tareas paralelas adicionales).
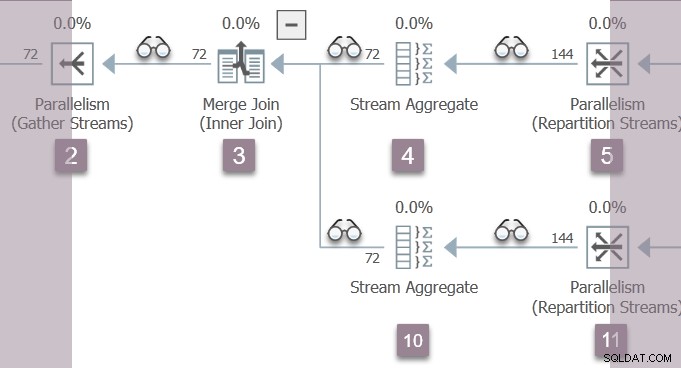
El único hilo activo en este momento (no suspendido en CXPACKET ) es la tarea principal , que está en el lado del consumidor del intercambio de flujos de partición en el nodo 11 en la sucursal B:
La tarea principal ahora regresa de las fases iniciales anidadas llamadas, configurando los tiempos transcurridos y de CPU en los generadores de perfiles a medida que avanza. Las primeras y últimas horas activas son no actualizado durante la fase inicial de procesamiento. Recuerde que estos números se registran en el contexto de ejecución cero:las tareas paralelas de la Rama B aún no existen.
La tarea principal asciende el árbol desde el nodo 11, a través del agregado de flujo en el nodo 10 y la combinación de combinación en el nodo 3, de vuelta al intercambio de flujos de recopilación en el nodo 2.
El procesamiento de la fase inicial ahora está completo .
Con las EarlyPhases originales llamar al nodo 2 reunir flujos intercambiar finalmente completado, la tarea principal vuelve a abrir ese intercambio (puede recordar esa llamada desde el comienzo de esta serie). El método abierto en el nodo 2 ahora llama a CQScanExchangeNew::StartAllProducers para crear las tareas paralelas para la sucursal B.
La tarea principal ahora espera en CXPACKET en el consumidor lado del nodo 2 reunir corrientes intercambio. Esta espera continuará hasta que las tareas de la Rama B recién creada hayan completado su Open anidado llamadas y volvió a completar la apertura del lado del productor del intercambio de flujos de recopilación.
Tareas paralelas de la rama B abiertas
Las dos nuevas tareas paralelas en la Rama B comienzan en el productor lado del nodo 2 reunir corrientes intercambio. Siguiendo el modelo habitual de ejecución iterativa en modo fila, llaman:
CQScanXProducerNew::Open(lado del productor del nodo 2 abierto).CQScanProfileNew::Open(perfilador para el nodo 3).CQScanMergeJoinNew::Open(nodo 3 combinación de combinación).CQScanProfileNew::Open(perfilador para el nodo 4).CQScanStreamAggregateNew::Open(agregado de flujo del nodo 4).CQScanProfileNew::Open(perfilador para el nodo 5).CQScanExchangeNew::Open(intercambio de flujos de reparto).
Las tareas paralelas siguen la entrada externa (superior) a la combinación de combinación, tal como lo hizo el procesamiento de la fase inicial.
Completando el intercambio
Cuando las tareas de la Rama B llegan al consumidor lado del intercambio de flujos de partición en el nodo 5, cada tarea:
- Registros con el puerto de intercambio (
CXPort). - Crea las tuberías (
CXPipe) que conectan esta tarea con una o más tareas del lado del productor (según el tipo de intercambio). El intercambio actual es un flujo de partición, por lo que cada tarea de consumidor tiene dos conductos (en DOP 2). Cada consumidor puede recibir filas de cualquiera de los dos productores. - Agrega un
CXPipeMergepara fusionar filas de varias tuberías (ya que este es un intercambio que preserva el orden). - Crea paquetes de fila (confusamente llamado
CXPacket) utilizado para el control de flujo y para amortiguar filas a través de las tuberías de intercambio. Estos se asignan desde la memoria de consulta previamente otorgada.
Una vez que ambas tareas paralelas del lado del consumidor hayan completado ese trabajo, el intercambio del nodo 5 está listo para funcionar. Los dos consumidores (en la Rama B) y los dos productores (en la Rama C) han abierto el puerto de intercambio, por lo que el nodo 5 CXPACKET espera el final .
Punto de control
Tal como están las cosas:
- La tarea principal en Branch A está esperando en
CXPACKETen el lado del consumidor del intercambio de flujos de recopilación del nodo 2. Esta espera continuará hasta que ambos productores del nodo 2 regresen y abran el intercambio. - Las dos tareas paralelas en Rama B son ejecutables . Acaban de abrir el lado del consumidor del intercambio de flujos de partición en el nodo 5.
- Las dos tareas paralelas en Sucursal C acaban de salir de su
CXPACKETesperar, y ahora son ejecutables . Los dos agregados de flujo en el nodo 6 (uno por tarea paralela) pueden comenzar a agregar filas de las dos clasificaciones en el nodo 7. Recuerde que las búsquedas de índice en el nodo 9 se cerraron hace algún tiempo, cuando las clasificaciones completaron su fase de entrada. - Las dos tareas paralelas en Rama D están esperando en
CXPACKETen el lado del productor del intercambio de flujos de partición en el nodo 11. Están esperando que el lado del consumidor del nodo 11 sea abierto por las dos tareas paralelas en la Rama B. Las búsquedas de índice se han cerrado y las clasificaciones están listas para la transición a su fase de salida.
Múltiples ramas activas
Esta es la primera vez que tenemos varias sucursales (B y C) activas al mismo tiempo, lo que podría ser un desafío para discutir. Afortunadamente, el diseño de la consulta de demostración es tal que los agregados de flujo en la Rama C producirán solo unas pocas filas. El pequeño número de filas de salida estrechas cabrá fácilmente en los búferes del paquete de filas. en el intercambio de flujos de partición del nodo 5. Por lo tanto, las tareas de la rama C pueden continuar con su trabajo (y eventualmente cerrarse) sin esperar a que el lado del consumidor de flujos de partición del nodo 5 obtenga filas.
Convenientemente, esto significa que podemos dejar que las dos tareas paralelas de Branch C se ejecuten en segundo plano sin preocuparnos por ellas. Solo necesitamos preocuparnos por lo que están haciendo las dos tareas paralelas de la Rama B.
Apertura de sucursal B completa
Un recordatorio de la sucursal B:
Los dos trabajadores paralelos en la Rama B regresan de su Open llamadas en el intercambio de flujos de repartición del nodo 5. Esto los lleva de regreso a través del agregado de flujo en el nodo 4, a la unión de fusión en el nodo 3.
Porque estamos ascendiendo el árbol en el Open método, los generadores de perfiles por encima del nodo 5 y el nodo 4 están registrando último activo tiempo, así como la acumulación de tiempos transcurridos y de CPU (por tarea). No estamos ejecutando las primeras fases en la tarea principal ahora, por lo que los números registrados para el contexto de ejecución cero no se ven afectados.
En la unión de fusión, las dos tareas paralelas de la Rama B comienzan a descender la entrada interna (inferior), llevándolos a través del flujo agregado en el nodo 10 (y un par de perfiladores) hasta el lado del consumidor del intercambio de flujos de partición en el nodo 11.
La rama D reanuda la ejecución
Una repetición de los eventos de la Rama C en el nodo 5 ahora ocurre en los flujos de partición del nodo 11. El lado del consumidor del intercambio del nodo 11 se completa y se abre. Los dos productores de la Rama D finalizan su CXPACKET espera, convirtiéndose en ejecutable otra vez. Dejaremos que las tareas de la Sucursal D se ejecuten en segundo plano, colocando sus resultados en búferes de intercambio.
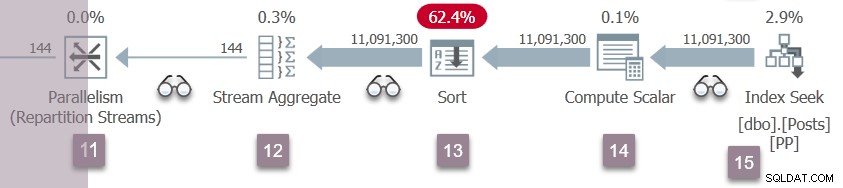
Ahora hay seis tareas paralelas (dos en cada rama B, C y D) compartiendo tiempo de forma cooperativa en los dos programadores asignados a tareas paralelas adicionales en esta consulta.
Inauguración de sucursal A completa
Las dos tareas paralelas en la Rama B regresan de su Open llamadas en el intercambio de flujos de repartición del nodo 11, más allá del agregado de flujo del nodo 10, a través de la combinación de combinación en el nodo 3, y de regreso al lado del productor de los flujos de recopilación en el nodo 2. Perfilador último activo y los tiempos transcurridos y de CPU acumulados se actualizan a medida que ascendemos en el árbol en Open anidado métodos.
En el productor lado del intercambio de flujos de recopilación, las dos tareas paralelas de la Rama B se sincronizan abriendo el puerto de intercambio, luego esperan en CXPACKET para que se abra el lado del consumidor.
La tarea principal la espera en el lado del consumidor de los flujos de recopilación ahora está liberada de su CXPACKET esperar, lo que le permite completar la apertura del puerto de intercambio en el lado del consumidor. Esto, a su vez, libera a los productores de su (breve) CXPACKET Espere. Todos los propietarios han abierto los flujos de recopilación del nodo 2.
Completando el escaneo de consulta
La tarea principal ahora asciende en el árbol de exploración de consultas desde el intercambio de flujos de recopilación, regresando desde Open llamadas en el intercambio, segmento y proyecto de secuencia operadores en la Sucursal A.
Esto completa la apertura el árbol de exploración de consultas, iniciado hace tanto tiempo por la llamada a CQueryScan::StartupQuery . Todas las ramas del plan paralelo ahora han comenzado a ejecutarse.
Filas de retorno
El plan de ejecución está listo para comenzar a devolver filas en respuesta a GetRow llamadas en la raíz del árbol de exploración de consultas, iniciado por una llamada a CQueryScan::GetRow . No voy a entrar en detalles completos, ya que está estrictamente más allá del alcance de un artículo sobre cómo los planes paralelos arrancan .
Aún así, la breve secuencia es:
- La tarea principal llama a
GetRowen el proyecto de secuencia, que llama aGetRowen el segmento, que llama aGetRowsobre el consumidor lado del intercambio de flujos de recolección. - Si aún no hay filas disponibles en el intercambio, la tarea principal espera en
CXCONSUMER. - Mientras tanto, las tareas paralelas de la Rama B que se ejecutan de forma independiente han estado llamando recursivamente a
GetRowempezando por el productor lado del intercambio de flujos de recolección. - Los lados del consumidor de los intercambios de flujos de partición en los nodos 5 y 12 suministran filas a la sucursal B.
- Las ramas C y D todavía están procesando filas de sus clases a través de sus respectivos agregados de flujo. Es posible que las tareas de la rama B tengan que esperar en
CXCONSUMERen los nodos 5 y 12 de los flujos de partición para que esté disponible un paquete completo de filas. - Filas que emergen del
GetRowanidado las llamadas en la rama B se ensamblan en paquetes de filas en el productor lado del intercambio de flujos de recolección. - El
CXCONSUMERde la tarea principal la espera en el lado del consumidor de los flujos de recopilación finaliza cuando un paquete está disponible. - Luego, se procesa una fila a la vez a través de los operadores principales en la Sucursal A y, finalmente, al cliente.
- Eventualmente, las filas se agotan y un
Closeanidado la llamada desciende por el árbol, a través de los intercambios, y la ejecución en paralelo llega a su fin.
Resumen y notas finales
Primero, un resumen de la secuencia de ejecución de este plan de ejecución paralelo en particular:
- La tarea principal abre sucursal A . Fase temprana el procesamiento comienza en el intercambio de flujos de recopilación.
- Las llamadas de la fase inicial de la tarea principal descienden por el árbol de exploración hasta la búsqueda de índice en el nodo 9 y, luego, vuelven a ascender hasta el intercambio de partición en el nodo 5.
- La tarea principal inicia tareas paralelas para Sucursal C , luego espera mientras leen todas las filas disponibles en los operadores de clasificación de bloqueo en el nodo 7.
- Las llamadas de la fase inicial ascienden a la combinación de fusión, luego descienden por la entrada interna al intercambio en el nodo 11.
- Tareas para Sucursal D se inician igual que para la rama C, mientras que la tarea principal espera en el nodo 11.
- Las llamadas de fase temprana regresan desde el nodo 11 hasta los flujos de recopilación. La fase inicial finaliza aquí.
- La tarea principal crea tareas paralelas para Sucursal B y espera hasta que se complete la apertura de la sucursal B.
- Las tareas de la rama B llegan a los flujos de partición del nodo 5, sincronizan, completan el intercambio y liberan las tareas de la rama C para comenzar a agregar filas a partir de las clasificaciones.
- Cuando las tareas de la Rama B llegan a los flujos de partición del nodo 12, se sincronizan, completan el intercambio y liberan las tareas de la Rama D para comenzar a agregar filas desde la ordenación.
- Las tareas de la rama B regresan al intercambio de flujos de recopilación y se sincronizan, lo que libera a la tarea principal de su espera. La tarea principal ya está lista para iniciar el proceso de devolución de filas al cliente.
Es posible que desee ver la ejecución de este plan en Sentry One Plan Explorer. Asegúrese de habilitar la opción "Con perfil de consulta en vivo" de la recopilación del plan real. Lo bueno de ejecutar la consulta directamente dentro de Plan Explorer es que podrá recorrer múltiples capturas a su propio ritmo e incluso rebobinar. También mostrará un resumen gráfico de E/S, CPU y esperas sincronizadas con los datos de generación de perfiles de consultas en vivo.
Notas adicionales
Al ascender en el árbol de exploración de consultas durante el procesamiento de la fase inicial, se establecen los primeros y últimos tiempos activos en cada iterador de generación de perfiles para la tarea principal, pero no se acumula el tiempo transcurrido ni el tiempo de CPU. Ascender el árbol durante Open y GetRow llama a una tarea paralela establece el último tiempo activo y acumula el tiempo transcurrido y el tiempo de CPU en cada iterador de creación de perfiles por tarea.
El procesamiento de fase inicial es específico de los planes paralelos en modo fila. Es necesario asegurarse de que los intercambios se inicialicen en el orden correcto y que toda la maquinaria paralela funcione correctamente.
La tarea principal no siempre realiza todo el procesamiento de la fase inicial. Las primeras fases comienzan en un intercambio raíz, pero la forma en que esas llamadas navegan por el árbol depende de los iteradores encontrados. Elegí una combinación de combinación para esta demostración porque requiere un procesamiento de fase temprana para ambas entradas.
Las primeras fases en (por ejemplo) una unión hash paralela se propagan solo por la entrada de compilación. Cuando la unión hash pasa a su fase de sondeo, abre iteradores en esa entrada, incluidos los intercambios. Se inicia otra ronda de procesamiento de fase temprana, manejada por (exactamente) una de las tareas paralelas, que desempeña el papel de la tarea principal.
Cuando el procesamiento de fase temprana encuentra una rama paralela que contiene un iterador de bloqueo, inicia las tareas paralelas adicionales para esa rama y espera a que esos productores completen su fase de apertura. Esa rama también puede tener ramas secundarias, que se manejan de la misma manera, recursivamente.
Es posible que se requiera que algunas ramas en un plan paralelo de modo de fila se ejecuten en un solo subproceso (por ejemplo, debido a un agregado global o superior). Estas "zonas en serie" también se ejecutan en una tarea "paralela" adicional, con la única diferencia de que solo hay una tarea, un contexto de ejecución y un trabajador para esa rama. El procesamiento de fase inicial funciona igual independientemente del número de tareas asignadas a una sucursal. Por ejemplo, una "zona en serie" informa los tiempos de la tarea principal (o una tarea paralela que desempeña ese papel), así como la tarea adicional única. Esto se manifiesta en el plan de presentación como datos para el "hilo 0" (fases iniciales), así como para el "hilo 1" (la tarea adicional).
Pensamientos de cierre
Todo esto sin duda representa una capa extra de complejidad. El retorno de esa inversión está en el uso de recursos de tiempo de ejecución (principalmente subprocesos y memoria), esperas de sincronización reducidas, mayor rendimiento, métricas de rendimiento potencialmente precisas y una posibilidad minimizada de interbloqueos paralelos entre consultas.
Aunque el paralelismo del modo de fila ha sido eclipsado en gran medida por el motor de ejecución en paralelo del modo por lotes más moderno, el diseño del modo de fila todavía tiene cierta belleza. La mayoría de los iteradores fingen que todavía se ejecutan en un plan en serie, con casi toda la sincronización, el control de flujo y la programación a cargo de los intercambios. El cuidado y la atención evidentes en los detalles de implementación, como el procesamiento de fase inicial, permiten que incluso los planes paralelos más grandes se ejecuten con éxito sin que el diseñador de consultas piense demasiado en las dificultades prácticas.