Este artículo es la octava parte de una serie sobre expresiones de tablas. Hasta ahora proporcioné información básica sobre las expresiones de tabla, cubrí los aspectos lógicos y de optimización de las tablas derivadas, los aspectos lógicos de CTE y algunos de los aspectos de optimización de CTE. Este mes continúo con la cobertura de los aspectos de optimización de CTE, abordando específicamente cómo se manejan múltiples referencias de CTE.
Este artículo es la octava parte de una serie sobre expresiones de tablas. Hasta ahora proporcioné información básica sobre las expresiones de tabla, cubrí los aspectos lógicos y de optimización de las tablas derivadas, los aspectos lógicos de CTE y algunos de los aspectos de optimización de CTE. Este mes continúo con la cobertura de los aspectos de optimización de CTE, abordando específicamente cómo se manejan múltiples referencias de CTE.
En mis ejemplos continuaré usando la base de datos de muestra TSQLV5. Puede encontrar el script que crea y completa TSQLV5 aquí, y su diagrama ER aquí.
Referencias múltiples y no determinismo
El mes pasado expliqué y demostré que los CTE se anidan, mientras que las tablas temporales y las variables de tabla en realidad conservan los datos. Proporcioné recomendaciones en términos de cuándo tiene sentido usar CTE versus cuándo tiene sentido usar objetos temporales desde el punto de vista del rendimiento de la consulta. Pero hay otro aspecto importante de la optimización de CTE, o procesamiento físico, a considerar más allá del rendimiento de la solución:cómo se manejan las múltiples referencias a CTE desde una consulta externa. Es importante darse cuenta de que si tiene una consulta externa con varias referencias a la misma CTE, cada una se anida por separado. Si tiene cálculos no deterministas en la consulta interna del CTE, esos cálculos pueden tener resultados diferentes en las diferentes referencias.
Digamos, por ejemplo, que invoca la función SYSDATETIME en una consulta interna de CTE, creando una columna de resultado llamada dt. Generalmente, suponiendo que no haya cambios en las entradas, una función integrada se evalúa una vez por consulta y referencia, independientemente del número de filas involucradas. Si hace referencia al CTE solo una vez desde una consulta externa, pero interactúa con la columna dt varias veces, se supone que todas las referencias representan la misma evaluación de función y devuelven los mismos valores. Sin embargo, si hace referencia a la CTE varias veces en la consulta externa, ya sea con varias subconsultas que se refieren a la CTE o una unión entre varias instancias de la misma CTE (por ejemplo, con alias C1 y C2), las referencias a C1.dt y C2.dt representa diferentes evaluaciones de la expresión subyacente y podría generar diferentes valores.
Para demostrar esto, considere los siguientes tres lotes:
-- Batch 1
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
SELECT @i += 1 WHERE SYSDATETIME() = SYSDATETIME();
PRINT @i;
GO
-- Batch 2
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 FROM C WHERE dt = dt;
PRINT @i;
GO
-- Batch 3
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 WHERE (SELECT dt FROM C) = (SELECT dt FROM C);
PRINT @i;
GO Con base en lo que acabo de explicar, ¿puede identificar cuál de los lotes tiene un bucle infinito y cuál se detendrá en algún punto debido a que los dos comparandos del predicado se evalúan con valores diferentes?
Recuerde que dije que una llamada a una función no determinista incorporada como SYSDATETIME se evalúa una vez por consulta y referencia. Esto significa que en el Lote 1 tiene dos evaluaciones diferentes y, después de suficientes iteraciones del ciclo, darán como resultado valores diferentes. Intentalo. ¿Cuántas iteraciones informó el código?
En cuanto al Lote 2, el código tiene dos referencias a la columna dt de la misma instancia de CTE, lo que significa que ambas representan la misma evaluación de función y deben representar el mismo valor. En consecuencia, el Lote 2 tiene un bucle infinito. Ejecútelo durante el tiempo que desee, pero eventualmente deberá detener la ejecución del código.
En cuanto al Lote 3, la consulta externa tiene dos subconsultas diferentes que interactúan con el CTE C, cada una de las cuales representa una instancia diferente que pasa por un proceso de anidamiento por separado. El código no asigna explícitamente alias diferentes a las diferentes instancias de la CTE porque las dos subconsultas aparecen en ámbitos independientes, pero para que sea más fácil de entender, podría pensar que las dos usan alias diferentes como C1 en una subconsulta y C2 en el otro. Entonces es como si una subconsulta interactuara con C1.dt y la otra con C2.dt. Las diferentes referencias representan diferentes evaluaciones de la expresión subyacente y, por lo tanto, pueden dar como resultado diferentes valores. Intente ejecutar el código y vea que se detiene en algún punto. ¿Cuántas iteraciones tomó hasta que se detuvo?
Es interesante tratar de identificar los casos en los que tiene una sola evaluación frente a múltiples evaluaciones de la expresión subyacente en el plan de ejecución de la consulta. La figura 1 tiene los planes de ejecución gráficos para los tres lotes (haga clic para ampliar).
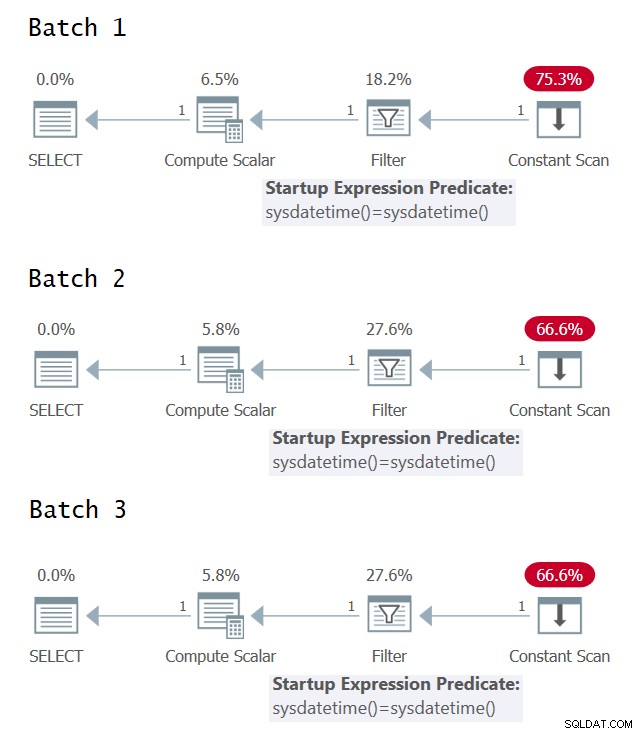 Figura 1:Planes gráficos de ejecución para Lote 1, Lote 2 y Lote 3
Figura 1:Planes gráficos de ejecución para Lote 1, Lote 2 y Lote 3
Desafortunadamente, no hay alegría de los planes de ejecución gráfica; todos parecen idénticos aunque, semánticamente, los tres lotes no tienen significados idénticos. Gracias a @CodeRecce y Forrest (@tsqladdict), como comunidad logramos llegar al fondo de esto por otros medios.
Como descubrió @CodeRecce, los planes XML tienen la respuesta. Estas son las partes relevantes del XML para los tres lotes:
−− Lote 1
…
…
−− Lote 2
…
…
−− Lote 3
…
…
Puede ver claramente en el plan XML para el Lote 1 que el predicado de filtro compara los resultados de dos invocaciones directas separadas de la función intrínseca SYSDATETIME.
En el plan XML para el lote 2, el predicado de filtro compara la expresión constante ConstExpr1002 que representa una invocación de la función SYSDATETIME consigo mismo.
En el plan XML para el lote 3, el predicado de filtro compara dos expresiones constantes diferentes denominadas ConstExpr1005 y ConstExpr1006, cada una de las cuales representa una invocación independiente de la función SYSDATETIME.
Como otra opción, Forrest (@tsqladdict) sugirió usar el indicador de seguimiento 8605, que muestra la representación del árbol de consulta inicial creado por SQL Server, después de habilitar el indicador de seguimiento 3604, lo que hace que la salida de TF 8605 se dirija al cliente SSMS. Use el siguiente código para habilitar ambas marcas de rastreo:
DBCC TRACEON(3604); -- direct output to client GO DBCC TRACEON(8605); -- show initial query tree GO
A continuación, ejecuta el código para el que desea obtener el árbol de consulta. Aquí están las partes relevantes de la salida que obtuve de TF 8605 para los tres lotes:
−− Lote 1
*** Árbol convertido:***
LogOp_Proyecto COL:Expr1000
LogOp_Select
LogOp_ConstTableGet (1) [vacío]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identificador COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,No propiedad,Valor=1)
−− Lote 2
*** Árbol convertido:***
LogOp_Proyecto COL:Expr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Proyecto
LogOp_ConstTableGet (1) [vacío]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identificador COL:Expr1000
ScaOp_Identificador COL:Expr1000
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identificador COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,No propiedad,Valor=1)
−− Lote 3
*** Árbol convertido:***
LogOp_Proyecto COL:Expr1004
LogOp_Select
LogOp_ConstTableGet (1) [vacío]
ScaOp_Comp x_cmpEq
ScaOp_Subconsulta COL:Expr1001
LogOp_Proyecto
LogOp_ViewAnchor
LogOp_Proyecto
LogOp_ConstTableGet (1) [vacío]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Identificador COL:Expr1000
ScaOp_Subquery COL:Expr1003
LogOp_Proyecto
LogOp_ViewAnchor
LogOp_Proyecto
LogOp_ConstTableGet (1) [vacío]
AncOp_PrjList
AncOp_PrjEl COL:Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1003
ScaOp_Identificador COL:Expr1002
AncOp_PrjList
AncOp_PrjEl COL:Expr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identificador COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,No propiedad,Valor=1)
En el Lote 1, puede ver una comparación entre los resultados de dos evaluaciones separadas de la función intrínseca SYSDATETIME.
En el Lote 2, verá una evaluación de la función que da como resultado una columna llamada Expr1000 y luego una comparación entre esta columna y ella misma.
En el Lote 3, verá dos evaluaciones separadas de la función. Uno en la columna llamada Expr1000 (luego proyectado por la columna de subconsulta llamada Expr1001). Otro en columna llamado Expr1002 (luego proyectado por la columna de subconsulta llamada Expr1003). Luego tiene una comparación entre Expr1001 y Expr1003.
Por lo tanto, con un poco más de investigación más allá de lo que expone el plan de ejecución gráfico, puede averiguar cuándo una expresión subyacente se evalúa solo una vez o varias veces. Ahora que comprende los diferentes casos, puede desarrollar sus soluciones en función del comportamiento deseado que está buscando.
Funciones de ventana con orden no determinista
Hay otra clase de cálculos que pueden causarle problemas cuando se utilizan en soluciones con múltiples referencias al mismo CTE. Esas son funciones de ventana que se basan en un orden no determinista. Tome la función de ventana ROW_NUMBER como ejemplo. Cuando se usa con pedido parcial (ordenar por elementos que no identifican de forma única la fila), cada evaluación de la consulta subyacente podría resultar en una asignación diferente de los números de fila incluso si los datos subyacentes no cambiaron. Con varias referencias de CTE, recuerde que cada una se anida por separado y podría obtener diferentes conjuntos de resultados. Dependiendo de lo que haga la consulta externa con cada referencia, p. con qué columnas de cada referencia interactúa y cómo, el optimizador puede decidir acceder a los datos para cada una de las instancias utilizando diferentes índices con diferentes requisitos de ordenación.
Considere el siguiente código como ejemplo:
USE TSQLV5;
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; ¿Puede esta consulta devolver un conjunto de resultados que no esté vacío? Quizás su reacción inicial es que no puede. Pero piense en lo que acabo de explicar un poco más detenidamente y se dará cuenta de que, al menos en teoría, debido a los dos procesos separados de anidamiento de CTE que tendrán lugar aquí, uno de C1 y otro de C2, es posible. Sin embargo, una cosa es teorizar que algo puede pasar y otra demostrarlo. Por ejemplo, cuando ejecuté este código sin crear ningún índice nuevo, seguí obteniendo un conjunto de resultados vacío:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
Obtuve el plan que se muestra en la Figura 23 para esta consulta.
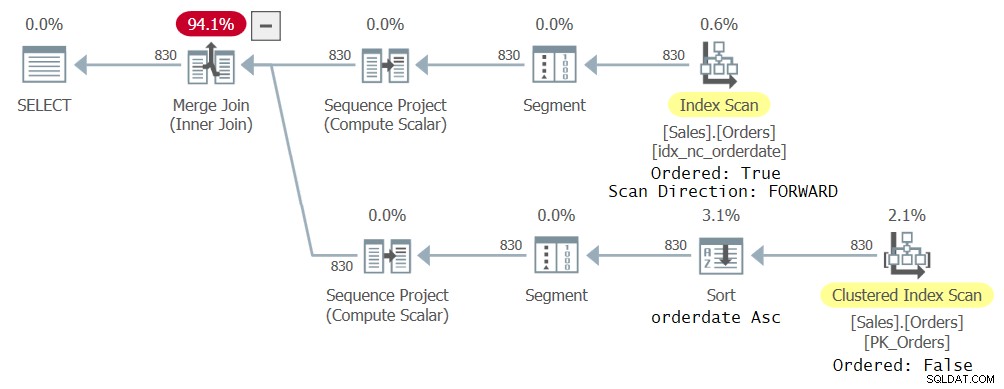 Figura 2:Primer plan para consulta con dos referencias CTE
Figura 2:Primer plan para consulta con dos referencias CTE
Lo que es interesante notar aquí es que el optimizador eligió usar diferentes índices para manejar las diferentes referencias de CTE porque eso es lo que consideró óptimo. Después de todo, cada referencia en la consulta externa se relaciona con un subconjunto diferente de las columnas CTE. Una referencia resultó en un escaneo hacia adelante ordenado del índice idx_nc_orderedate, y la otra en un escaneo desordenado del índice agrupado seguido de una operación de clasificación por orden de fecha ascendente. Aunque el índice idx_nc_orderedate se define explícitamente solo en la columna orderdate como clave, en la práctica se define en (orderdate, orderid) como sus claves, ya que orderid es la clave del índice agrupado y se incluye como la última clave en todos los índices no agrupados. Entonces, un escaneo ordenado del índice en realidad emite las filas ordenadas por orderdate, orderid. En cuanto al escaneo desordenado del índice agrupado, a nivel del motor de almacenamiento, los datos se escanean en orden de clave de índice (según orderid) para abordar las expectativas mínimas de coherencia del nivel de aislamiento predeterminado de lectura confirmada. El operador Sort, por lo tanto, ingiere los datos ordenados por orderid, ordena las filas por orderdate y, en la práctica, termina emitiendo las filas ordenadas por orderdate, orderid.
Nuevamente, en teoría, no hay garantía de que las dos referencias siempre representen el mismo conjunto de resultados, incluso si los datos subyacentes no cambian. Una forma simple de demostrar esto es organizar dos índices óptimos diferentes para las dos referencias, pero hacer que uno ordene los datos por orderdate ASC, orderid ASC, y el otro ordene los datos por orderdate DESC, orderid ASC (o exactamente lo contrario). Ya tenemos el índice anterior en su lugar. Aquí está el código para crear este último:
CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);
Ejecute el código por segunda vez después de crear el índice:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Obtuve el siguiente resultado al ejecutar este código después de crear el nuevo índice:
orderid shipcountry orderid ----------- --------------- ----------- 10251 France 10250 10250 Brazil 10251 10261 Brazil 10260 10260 Germany 10261 10271 USA 10270 ... 11070 Germany 11073 11077 USA 11074 11076 France 11075 11075 Switzerland 11076 11074 Denmark 11077 (546 rows affected)
Ups.
Examine el plan de consulta para esta ejecución como se muestra en la Figura 3:
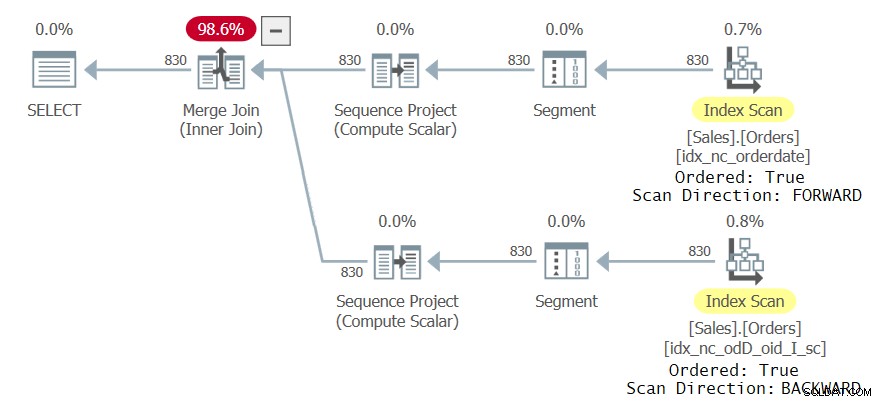 Figura 3:Segundo plan para consulta con dos referencias CTE
Figura 3:Segundo plan para consulta con dos referencias CTE
Observe que la rama superior del plan escanea el índice idx_nc_orderdate de forma ordenada hacia adelante, lo que hace que el operador Sequence Project que calcula los números de fila ingiera los datos en la práctica ordenados por orderdate ASC, orderid ASC. La rama inferior del plan escanea el nuevo índice idx_nc_odD_oid_I_sc de forma ordenada hacia atrás, lo que hace que el operador del Proyecto de secuencia ingiera los datos en la práctica ordenados por fecha de pedido ASC, ID de pedido DESC. Esto da como resultado una disposición diferente de los números de fila para las dos referencias CTE siempre que haya más de una aparición del mismo valor de fecha de pedido. En consecuencia, la consulta genera un conjunto de resultados no vacío.
Si desea evitar tales errores, una opción obvia es conservar el resultado de la consulta interna en un objeto temporal como una tabla temporal o una variable de tabla. Sin embargo, si tiene una situación en la que prefiere ceñirse al uso de CTE, una solución simple es usar el orden total en la función de ventana agregando un desempate. En otras palabras, asegúrese de ordenar por una combinación de expresiones que identifique de forma única una fila. En nuestro caso, simplemente puede agregar orderid explícitamente como desempate, así:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; Obtiene un conjunto de resultados vacío como se esperaba:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
Sin agregar más índices, obtiene el plan que se muestra en la Figura 4:
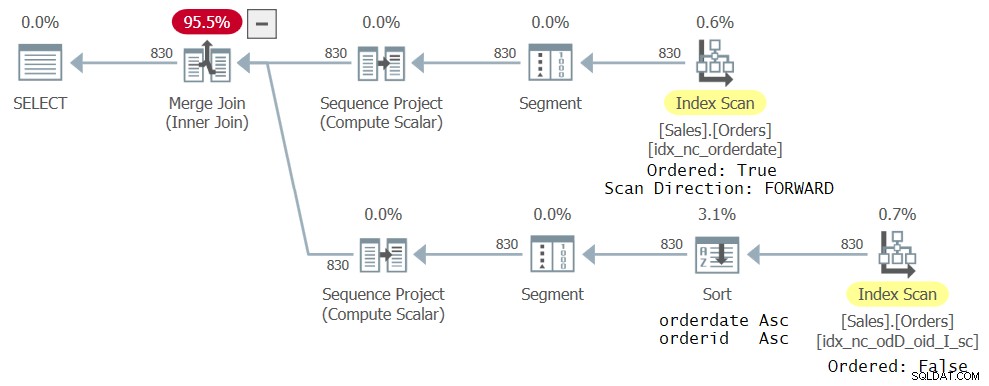 Figura 4:Tercer plan para consulta con dos referencias CTE
Figura 4:Tercer plan para consulta con dos referencias CTE
La rama superior del plano es la misma que la del plano anterior que se muestra en la Figura 3. Sin embargo, la rama inferior es un poco diferente. El nuevo índice creado anteriormente no es realmente ideal para la nueva consulta en el sentido de que no tiene los datos ordenados como necesita la función ROW_NUMBER (orderdate, orderid). Sigue siendo el índice de cobertura más estrecho que el optimizador pudo encontrar para su respectiva referencia CTE, por lo que se selecciona; sin embargo, se escanea de manera ordenada:falsa. Un operador Ordenar explícito luego ordena los datos por fecha de pedido, orderid como las necesidades de cálculo ROW_NUMBER. Por supuesto, puede modificar la definición del índice para que tanto orderdate como orderid usen la misma dirección y, de esta manera, la clasificación explícita se eliminará del plan. Sin embargo, el punto principal es que al usar el pedido total, evita meterse en problemas debido a este error específico.
Cuando haya terminado, ejecute el siguiente código para la limpieza:
DROP INDEX IF EXISTS idx_nc_odD_oid_I_sc ON Sales.Orders;
Conclusión
Es importante comprender que múltiples referencias a la misma CTE desde una consulta externa dan como resultado evaluaciones separadas de la consulta interna de la CTE. Tenga especial cuidado con los cálculos no deterministas, ya que las diferentes evaluaciones pueden dar como resultado valores diferentes.
Cuando use funciones de ventana como ROW_NUMBER y agregados con un marco, asegúrese de usar el orden total para evitar obtener resultados diferentes para la misma fila en las diferentes referencias de CTE.