Hubo muchos comentarios después de mi publicación la semana pasada sobre la división de cadenas. Creo que el punto del artículo no era tan obvio como podría haber sido:gastar mucho tiempo y esfuerzo tratando de "perfeccionar" una función de división inherentemente lenta basada en T-SQL no sería beneficioso. Desde entonces, he recopilado la versión más reciente de la función de división de cadenas de Jeff Moden y la he comparado con las demás:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO (Los únicos cambios que hice:lo formateé para que se muestre y eliminé los comentarios. Puede recuperar la fuente original aquí).
Tuve que hacer un par de ajustes a mis pruebas para representar fielmente la función de Jeff. Lo más importante:tuve que descartar todas las muestras que involucraban cadenas de más de 4000 caracteres. Así que cambié las cadenas de 5000 caracteres en la tabla dbo.strings para que tengan 4000 caracteres y me concentré solo en los tres primeros escenarios no MAX (manteniendo los resultados anteriores para los dos primeros y ejecutando la tercera prueba nuevamente para el nuevo longitudes de cadena de 4.000 caracteres). También eliminé la tabla de Números de todas las pruebas menos una, porque estaba claro que el desempeño siempre era peor por un factor de al menos 10. El siguiente gráfico muestra el desempeño de las funciones en cada una de las cuatro pruebas, nuevamente con un promedio de más de 10 ejecuciones y siempre con un caché frío y búferes limpios.
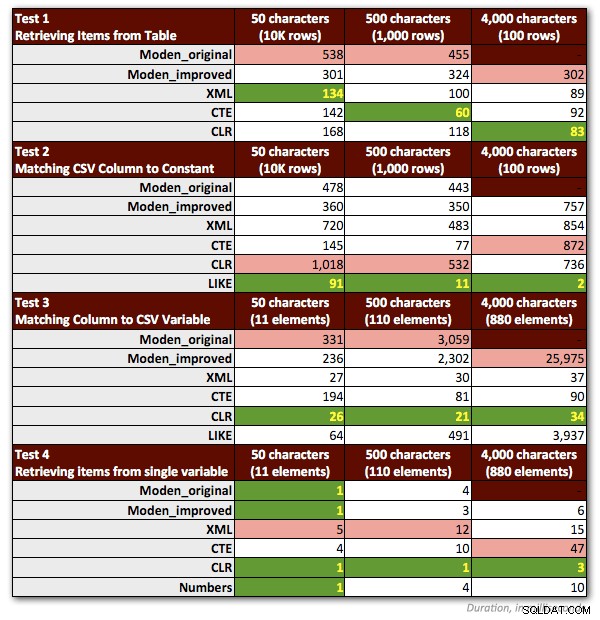
Aquí están mis métodos preferidos ligeramente revisados, para cada tipo de tarea:
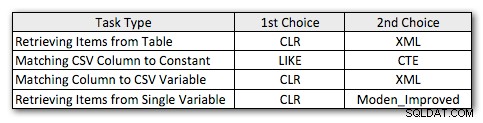
Notarás que CLR sigue siendo mi método de elección, excepto en el único caso en que la división no tiene sentido. Y en los casos en que CLR no es una opción, los métodos XML y CTE son generalmente más eficientes, excepto en el caso de la división de una sola variable, donde la función de Jeff puede ser la mejor opción. Pero dado que es posible que deba admitir más de 4000 caracteres, la solución de la tabla de números podría volver a aparecer en mi lista en situaciones específicas en las que no se me permite usar CLR.
Prometo que mi próxima publicación sobre listas no hablará sobre la división en absoluto, a través de T-SQL o CLR, y demostraré cómo simplificar este problema independientemente del tipo de datos.
Aparte, noté este comentario en una de las versiones de las funciones de Jeff que se publicó en los comentarios:También agradezco a quien haya escrito el primer artículo que vi sobre "tablas de números" que se encuentra en la siguiente URL y a Adam Machanic. por llevarme a ella hace muchos años.https://web.archive.org/web/20150411042510/https://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an -auxiliary-numbers-table.html
Ese artículo fue escrito por mí en 2004. Así que quienquiera que haya agregado el comentario a la función, es bienvenido. :-)



