La calidad de un plan de ejecución depende en gran medida de la precisión del número estimado de filas generadas por cada operador del plan. Si el número estimado de filas se desvía significativamente del número real de filas, esto puede tener un impacto significativo en la calidad del plan de ejecución de una consulta. La mala calidad del plan puede ser responsable de E/S excesivas, CPU inflada, presión de memoria, rendimiento reducido y simultaneidad general reducida.
Por "calidad del plan":me refiero a que SQL Server genere un plan de ejecución que resulte en opciones de operadores físicos que reflejen el estado actual de los datos. Al tomar tales decisiones basadas en datos precisos, existe una mayor probabilidad de que la consulta se realice correctamente. Los valores estimados de cardinalidad se utilizan como entrada para el costeo del operador, y cuando los valores están demasiado alejados de la realidad, el impacto negativo en el plan de ejecución puede ser pronunciado. Estas estimaciones se alimentan a los diversos modelos de costos asociados a la consulta en sí, y las estimaciones de filas incorrectas pueden afectar una variedad de decisiones, incluida la selección de índices, operaciones de búsqueda frente a escaneo, ejecución paralela frente a serie, selección de algoritmo de unión, unión física interna frente a externa. selección (p. ej., compilación frente a sondeo), generación de colas, búsquedas de marcadores frente a acceso completo a la tabla de almacenamiento dinámico o en clúster, selección de agregación de flujo o hash, y si una modificación de datos utiliza o no un plan amplio o estrecho.
Como ejemplo, supongamos que tiene el siguiente SELECT consulta (utilizando la base de datos de crédito):
SELECT m.member_no, m.lastname, p.payment_no, p.payment_dt, p.payment_amt FROM dbo.member AS m INNER JOIN dbo.payment AS p ON m.member_no = p.member_no;
Según la lógica de la consulta, ¿la siguiente forma del plan es lo que esperaría ver?
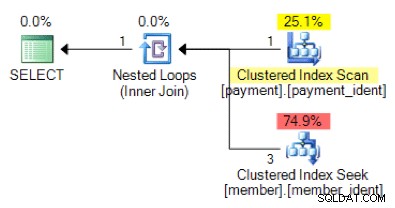
¿Y qué pasa con este plan alternativo, donde en lugar de un bucle anidado tenemos una coincidencia hash?
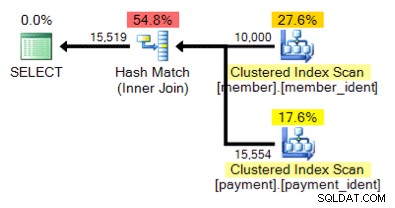
La respuesta "correcta" depende de algunos otros factores, pero un factor importante es el número de filas en cada una de las tablas. En algunos casos, un algoritmo de combinación física es más apropiado que el otro, y si las suposiciones de estimación de cardinalidad inicial no son correctas, es posible que su consulta esté utilizando un enfoque no óptimo.
Identificación problemas de estimación de cardinalidad es relativamente sencillo. Si tiene un plan de ejecución real, puede comparar los valores de recuento de filas estimados con los reales para los operadores y buscar sesgos. SQL Sentry Plan Explorer simplifica esta tarea al permitirle ver filas reales versus filas estimadas para todos los operadores en una sola pestaña de árbol de plan en lugar de tener que pasar el mouse sobre los operadores individuales en el plan gráfico:

Ahora, los sesgos no siempre dan como resultado planes de mala calidad, pero si tiene problemas de rendimiento con una consulta y ve tales sesgos en el plan, esta es un área que merece una mayor investigación.
La identificación de problemas de estimación de cardinalidad es relativamente sencilla, pero la resolución a menudo no lo es. Hay una serie de causas fundamentales por las que pueden ocurrir problemas de estimación de cardinalidad, y cubriré diez de las razones más comunes en esta publicación.
Estadísticas perdidas o obsoletas
De todas las razones de los problemas de estimación de cardinalidad, esta es la que espera para ver, ya que a menudo es más fácil de abordar. En este escenario, sus estadísticas faltan o están desactualizadas. Es posible que tenga deshabilitadas las opciones de la base de datos para la creación y actualizaciones automáticas de estadísticas, "no recalculadas" habilitadas para estadísticas específicas, o que tenga tablas lo suficientemente grandes como para que sus actualizaciones automáticas de estadísticas simplemente no se realicen con la frecuencia suficiente.
Problemas de muestreo
Puede ser que la precisión del histograma de estadísticas sea inadecuada, por ejemplo, si tiene una tabla muy grande con sesgos de datos significativos y/o frecuentes. Es posible que deba cambiar el muestreo predeterminado o, incluso si eso no ayuda, investigue utilizando tablas separadas, estadísticas filtradas o índices filtrados.
Correlaciones de columnas ocultas
El optimizador de consultas asume que las columnas dentro de la misma tabla son independientes. Por ejemplo, si tiene una columna de ciudad y estado, es posible que sepamos intuitivamente que estas dos columnas están correlacionadas, pero SQL Server no entiende esto a menos que lo ayudemos con un índice de varias columnas asociado o con varias columnas creadas manualmente. estadísticas de columna. Sin ayudar al optimizador con la correlación, la selectividad de sus predicados puede ser exagerada.
A continuación se muestra un ejemplo de dos predicados correlacionados:
SELECT lastname, firstname FROM dbo.member WHERE city = 'Minneapolis' AND state_prov - 'MN';
Sé que el 10 % de nuestras 10 000 filas member la tabla califica para esta combinación, pero el optimizador de consultas supone que es el 1 % de las 10 000 filas:
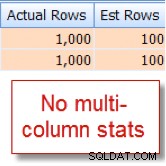
Ahora compare esto con la estimación adecuada que veo después de agregar estadísticas de varias columnas:
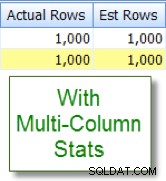
Comparaciones de columnas dentro de la tabla
Pueden ocurrir problemas de estimación de cardinalidad al comparar columnas dentro de la misma tabla. Este es un problema conocido. Si tiene que hacerlo, puede mejorar las estimaciones de cardinalidad de las comparaciones de columnas usando columnas calculadas en su lugar o reescribiendo la consulta para usar autocombinaciones o expresiones de tabla comunes.
Uso de variables de tabla
¿Usas mucho las variables de la tabla? Las variables de la tabla muestran una estimación de cardinalidad de "1", lo que para un pequeño número de filas puede no ser un problema, pero para conjuntos de resultados grandes o volátiles puede afectar significativamente la calidad del plan de consulta. A continuación se muestra una captura de pantalla de la estimación de un operador de 1 fila frente a las 1 600 000 filas reales de @charge variable de tabla:

Si esta es su causa principal, le recomendamos que explore alternativas como tablas temporales o tablas de preparación permanentes cuando sea posible.
UDF escalares y MSTV
De manera similar a las variables de tabla, las funciones escalares y con valores de tabla de múltiples declaraciones son una caja negra desde una perspectiva de estimación de cardinalidad. Si se encuentra con problemas de calidad del plan debido a ellos, considere las funciones de tabla en línea como una alternativa, o incluso extraiga la referencia de la función por completo y solo haga referencia a los objetos directamente.
A continuación, se muestra un plan estimado versus real cuando se utiliza una función con valores de tabla de varios estados:
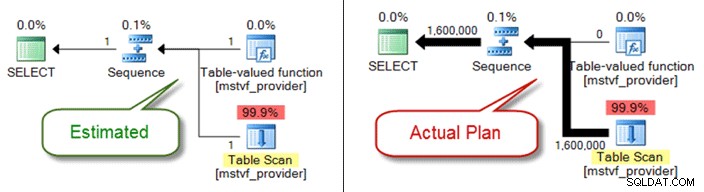
Problemas de tipos de datos
Los problemas de tipo de datos implícitos junto con las condiciones de búsqueda y unión pueden causar problemas de estimación de cardinalidad. También pueden consumir subrepticiamente los recursos a nivel del servidor (CPU, E/S, memoria), por lo que es importante abordarlos siempre que sea posible.
Predicados complejos
Probablemente haya visto este patrón antes:una consulta con WHERE cláusula que tiene cada referencia de columna de la tabla envuelta en varias funciones, operaciones de concatenación, operaciones matemáticas y más. Y aunque no todos los ajustes de funciones impiden estimaciones de cardinalidad adecuadas (como para LOWER , UPPER y GETDATE ) hay muchas maneras de enterrar su predicado hasta el punto de que el optimizador de consultas ya no puede hacer estimaciones precisas.
Complejidad de la consulta
Al igual que los predicados enterrados, ¿sus consultas son extraordinariamente complejas? Me doy cuenta de que "complejo" es un término subjetivo, y su evaluación puede variar, pero la mayoría puede estar de acuerdo en que anidar vistas dentro de vistas dentro de vistas que hacen referencia a tablas superpuestas probablemente no sea óptimo, especialmente cuando se combina con más de 10 uniones de tablas, referencias de funciones y predicados enterrados. Si bien el optimizador de consultas hace un trabajo admirable, no es mágico, y si tiene sesgos significativos, la complejidad de las consultas (consultas de navaja suiza) ciertamente puede hacer que sea casi imposible obtener estimaciones de filas precisas para los operadores.
Consultas distribuidas
¿Está utilizando consultas distribuidas con servidores vinculados y observa importantes problemas de estimación de cardinalidad? Si es así, asegúrese de comprobar los permisos asociados con la entidad principal del servidor vinculado que se utiliza para acceder a los datos. Sin el mínimo db_ddladmin rol de base de datos fijo para la cuenta del servidor vinculado, esta falta de visibilidad de las estadísticas remotas debido a permisos insuficientes puede ser la fuente de sus problemas de estimación de cardinalidad.
Y hay otros...
Hay otras razones por las que las estimaciones de cardinalidad pueden estar sesgadas, pero creo que he cubierto las más comunes. El punto clave es prestar atención a los sesgos en asociación con consultas conocidas y de bajo rendimiento. No suponga que el plan se generó en función de condiciones precisas de recuento de filas. Si estos números están sesgados, primero debe intentar solucionar este problema.