Mi compañero de trabajo Steve Wright (blog | @SQL_Steve) me hizo una pregunta recientemente sobre un resultado extraño que estaba viendo. Para probar alguna funcionalidad en nuestra última herramienta, SQL Sentry Plan Explorer PRO, había fabricado una tabla ancha y grande, y estaba ejecutando una variedad de consultas en ella. En un caso, estaba devolviendo una gran cantidad de datos, pero STATISTICS IO estaba mostrando que se estaban realizando muy pocas lecturas. Hice ping a algunas personas en #sqlhelp y, dado que parecía que nadie había visto este problema, pensé en escribir un blog al respecto.
Versión TL;DR
En resumen, tenga muy en cuenta que hay algunos escenarios en los que no puede confiar en STATISTICS IO para decirte la verdad. En algunos casos (este involucra a TOP y paralelismo), subestimará enormemente las lecturas lógicas. Esto puede llevarlo a creer que tiene una consulta muy compatible con E/S cuando no es así. Hay otros casos más obvios, como cuando tiene un montón de E/S ocultas por el uso de funciones escalares definidas por el usuario. Creemos que Plan Explorer hace que esos casos sean más obvios; este, sin embargo, es un poco más complicado.
La consulta del problema
La tabla tiene 37 millones de filas, hasta 250 bytes por fila, aproximadamente 1 millón de páginas y una fragmentación muy baja (0,42 % en el nivel 0, 15 % en el nivel 1 y 0 más allá). No hay columnas calculadas, UDF en juego ni índices, excepto una clave principal agrupada en el INT inicial. columna. Una consulta simple que devuelve 500 000 filas, todas las columnas, usando TOP y SELECT * :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029');
(Y sí, me doy cuenta de que estoy violando mis propias reglas y usando SELECT * y TOP sin ORDER BY , pero en aras de la simplicidad, estoy haciendo todo lo posible para minimizar mi influencia en el optimizador).
Resultados:
(500000 filas afectadas)Tabla 'OrderHistory'. Recuento de escaneo 1, lecturas lógicas 23, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Devolvemos 500.000 filas y tarda unos 10 segundos. Inmediatamente sé que algo anda mal con el número de lecturas lógicas. Incluso si aún no sabía acerca de los datos subyacentes, puedo decir a partir de los resultados de la cuadrícula en Management Studio que esto está extrayendo más de 23 páginas de datos, ya sean de memoria o caché, y esto debería reflejarse en algún lugar de STATISTICS IO . Mirando el plan...
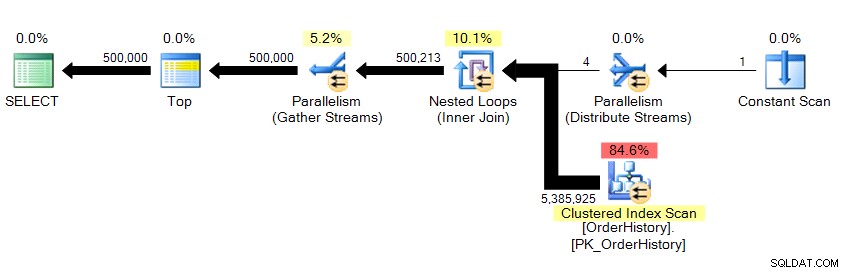
…vemos que hay paralelismo allí, y que hemos escaneado toda la tabla. Entonces, ¿cómo es posible que solo haya 23 lecturas lógicas?
Otra consulta "idéntica"
Una de mis primeras preguntas a Steve fue:"¿Qué pasa si eliminas el paralelismo?" Así que lo probé. Tomé la versión original de la subconsulta y agregué MAXDOP 1 :
SET STATISTICS IO ON; SELECT TOP 500000 * FROM dbo.OrderHistory WHERE OrderDate < (SELECT '19961029') OPTION (MAXDOP 1);
Resultados y plan:
(500000 filas afectadas)Tabla 'OrderHistory'. Recuento de escaneo 1, lecturas lógicas 149589, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
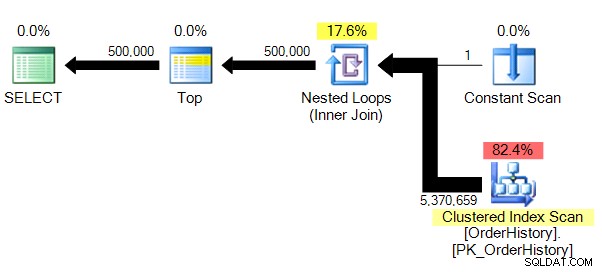
Tenemos un plan un poco menos complejo, y sin el paralelismo (por razones obvias), STATISTICS IO nos muestra números mucho más creíbles para recuentos de lectura lógica.
¿Cuál es la verdad?
No es difícil ver que una de estas consultas no dice toda la verdad. Mientras que STATISTICS IO Puede que no nos cuente toda la historia, tal vez el rastro lo haga. Si recuperamos métricas de tiempo de ejecución generando un plan de ejecución real en Plan Explorer, vemos que la consulta mágica de lectura baja está, de hecho, extrayendo los datos de la memoria o el disco, y no de una nube de polvo mágico. De hecho, tiene *más* lecturas que la otra versión:

Entonces, está claro que se están realizando lecturas, simplemente no aparecen correctamente en STATISTICS IO salida.
¿Cuál es el problema?
Bueno, seré bastante honesto:no lo sé, aparte del hecho de que el paralelismo definitivamente juega un papel, y parece ser algún tipo de condición de carrera. STATISTICS IO (y, dado que ahí es donde obtenemos los datos, nuestra pestaña Table I/O) muestra una cantidad de lecturas muy engañosa. Está claro que la consulta devuelve todos los datos que estamos buscando y, a partir de los resultados del seguimiento, está claro que usa lecturas y no ósmosis para hacerlo. Le pregunté a Paul White (blog | @SQL_Kiwi) al respecto y sugirió que solo algunos de los recuentos de E/S previos al subproceso se incluyen en el total (y acepta que se trata de un error).
Si desea probar esto en casa, todo lo que necesita es AdventureWorks (esto debería reproducirse en las versiones 2008, 2008 R2 y 2012) y la siguiente consulta:
SET STATISTICS IO ON; DBCC SETCPUWEIGHT(1000) WITH NO_INFOMSGS; GO SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101'); SELECT TOP (15000) * FROM Sales.SalesOrderHeader WHERE OrderDate < (SELECT '20080101') OPTION (MAXDOP 1); DBCC SETCPUWEIGHT(1) WITH NO_INFOMSGS;
(Tenga en cuenta que SETCPUWEIGHT sólo se utiliza para convencer al paralelismo. Para obtener más información, consulte la publicación de blog de Paul White sobre Planificación de costos).
Resultados:
Tabla 'Encabezado de pedido de ventas'. Recuento de escaneo 1, lecturas lógicas 4, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.Tabla 'SalesOrderHeader'. Recuento de escaneo 1, lecturas lógicas 333, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Paul señaló una reproducción aún más simple:
SET STATISTICS IO ON; GO SELECT TOP (15000) * FROM Production.TransactionHistory WHERE TransactionDate < (SELECT '20080101') OPTION (QUERYTRACEON 8649, MAXDOP 4); SELECT TOP (15000) * FROM Production.TransactionHistory AS th WHERE TransactionDate < (SELECT '20080101');
Resultados:
Tabla 'Historial de transacciones'. Recuento de escaneo 1, lecturas lógicas 5, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.Tabla 'Historial de transacciones'. Recuento de escaneo 1, lecturas lógicas 110, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Entonces parece que podemos reproducir esto fácilmente a voluntad con un TOP operador y un DOP lo suficientemente bajo. He presentado un error:
- STATISTICS IO no informa lecturas lógicas para planes paralelos
Y Paul ha presentado otros dos errores relacionados con el paralelismo, el primero como resultado de nuestra conversación:
- Error de estimación de cardinalidad con predicado insertado en una búsqueda [entrada de blog relacionada]
- Rendimiento deficiente con paralelismo y Top [entrada de blog relacionada]
(Para los nostálgicos, aquí hay otros seis errores de paralelismo que señalé hace unos años).
¿Cuál es la lección?
Tenga cuidado con confiar en una sola fuente. Si observa únicamente STATISTICS IO después de cambiar una consulta como esta, puede verse tentado a centrarse en la caída milagrosa de las lecturas en lugar del aumento de la duración. En ese momento, puede darse una palmada en la espalda, salir temprano del trabajo y disfrutar de su fin de semana, pensando que acaba de tener un tremendo impacto en el rendimiento de su consulta. Cuando, por supuesto, nada podría estar más lejos de la verdad.