Uno de los aspectos clave de la alta disponibilidad es la capacidad de reaccionar rápidamente ante fallas. No es raro administrar manualmente las bases de datos y hacer que el software de monitoreo vigile el estado de la base de datos. En caso de falla, el software de monitoreo envía una alerta al personal de guardia. Esto significa que es posible que alguien necesite despertarse, acceder a una computadora e iniciar sesión en los sistemas y ver los registros; es decir, hay bastante tiempo antes de que pueda comenzar la reparación. Idealmente, todo el proceso debería estar automatizado.
En este blog, veremos cómo implementar un sistema totalmente automatizado que detecta cuándo falla la base de datos principal e inicia procedimientos de conmutación por error mediante la promoción de una base de datos secundaria. Usaremos ClusterControl para realizar una conmutación por error automática de la base de datos Moodle PostgreSQL.
Ventaja de la conmutación por error automática
- Menos tiempo para recuperar el servicio de la base de datos
- Mayor tiempo de actividad del sistema
- Menos dependencia del DBA o del administrador que configuran la alta disponibilidad para la base de datos
Arquitectura
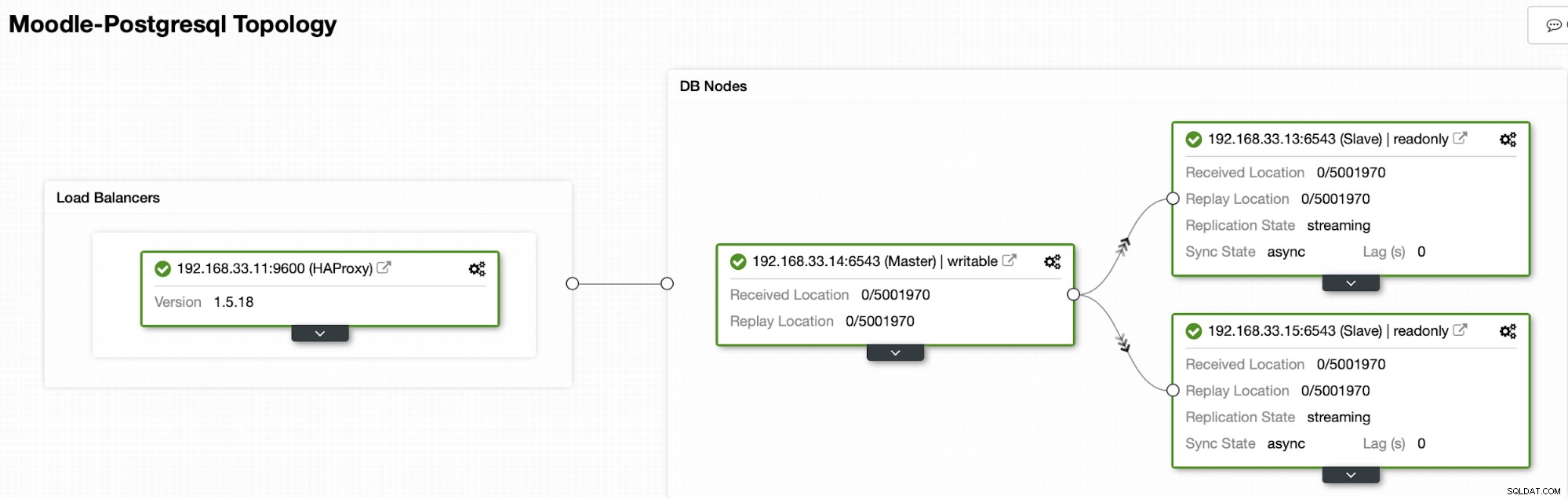
Actualmente tenemos un servidor principal de Postgres y dos servidores secundarios bajo el balanceador de carga HAProxy que envía el tráfico de Moodle al nodo principal de PostgreSQL. La recuperación del clúster y la recuperación automática del nodo en ClusterControl son las configuraciones importantes para realizar el proceso de conmutación por error automático.

Controlar a qué servidor conmutar por error
ClusterControl ofrece listas blancas y negras de un conjunto de servidores que desea que participen en la conmutación por error o que desee excluir como candidatos.
Hay dos variables que puede establecer en la configuración cmon,
- replication_failover_whitelist :contiene una lista de direcciones IP o nombres de host de servidores secundarios que deben usarse como posibles candidatos principales. Si se establece esta variable, solo se considerarán esos hosts.
- replication_failover_blacklist :contiene una lista de hosts que nunca se considerarán como candidatos principales. Puede usarlo para enumerar servidores secundarios que se usan para copias de seguridad o consultas analíticas. Si el hardware varía entre los servidores secundarios, es posible que desee colocar aquí los servidores que utilizan un hardware más lento.
Proceso de conmutación por error automático
Paso 1
Hemos comenzado la carga de datos en el servidor principal (192.168.33.14) usando la herramienta sysbench.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Paso 2
Vamos a detener el servidor principal de Postgres (192.168.33.14). En ClusterControl, el parámetro (enable_cluster_autorecovery) está habilitado, por lo que promoverá el siguiente primario adecuado.
# service postgresql-12 stopPaso 3
ClusterControl detecta fallas en el principal y promueve un secundario con los datos más actuales como un nuevo principal. También funciona en el resto de servidores secundarios para que se repliquen desde el nuevo servidor principal.

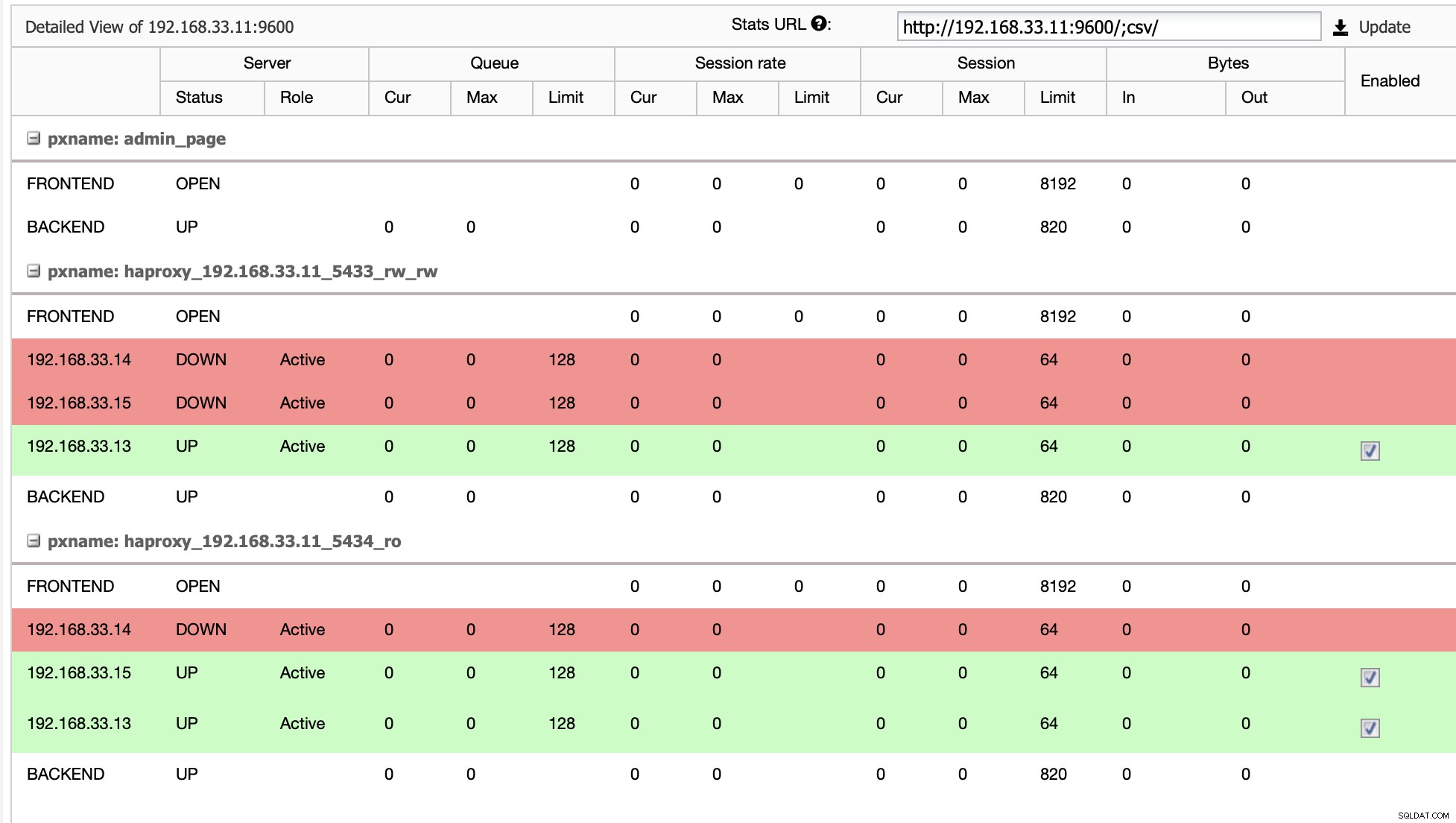
En nuestro caso, el (192.168.33.13) es un nuevo servidor primario y los servidores secundarios ahora se replican desde este nuevo servidor primario. Ahora HAProxy enruta el tráfico de la base de datos desde los servidores de Moodle al último servidor primario.
Desde (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Desde (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Topología actual
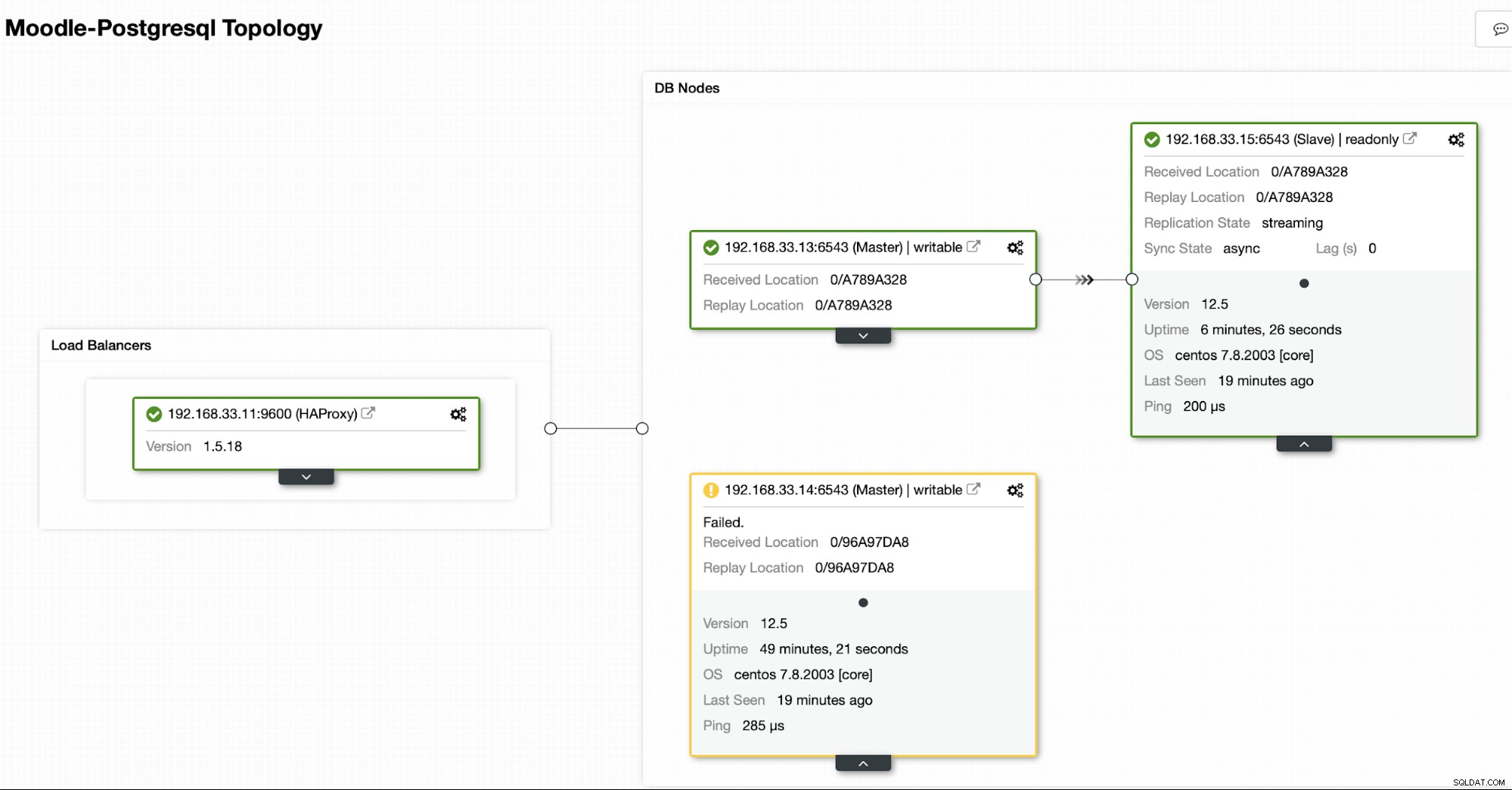
Cuando HAProxy detecta que uno de nuestros nodos, ya sea principal o réplica, está no accesible, lo marca automáticamente como fuera de línea. HAProxy no le enviará ningún tráfico desde la aplicación de Moodle. Esta verificación se realiza mediante scripts de verificación de estado configurados por ClusterControl en el momento de la implementación.
Una vez que ClusterControl promociona un servidor de réplica a principal, nuestro HAProxy marca el servidor principal anterior como fuera de línea y pone el nodo promocionado en línea.
Una vez que el antiguo servidor principal vuelva a estar en línea, no se sincronizará automáticamente con el nuevo servidor principal. Necesitamos dejarlo volver a la topología, y se puede hacer a través de la interfaz ClusterControl. Esto evitará la posibilidad de pérdida de datos o inconsistencias, en caso de que queramos investigar por qué ese servidor falló en primer lugar.
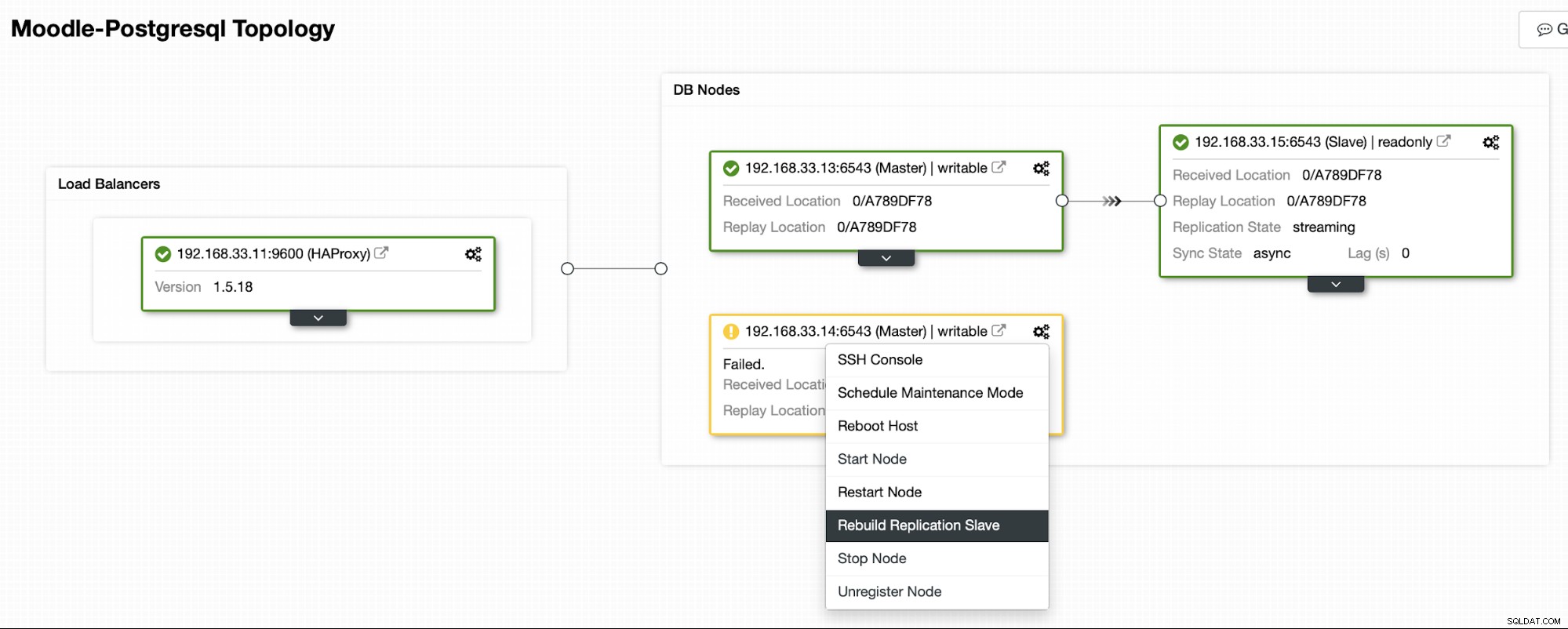
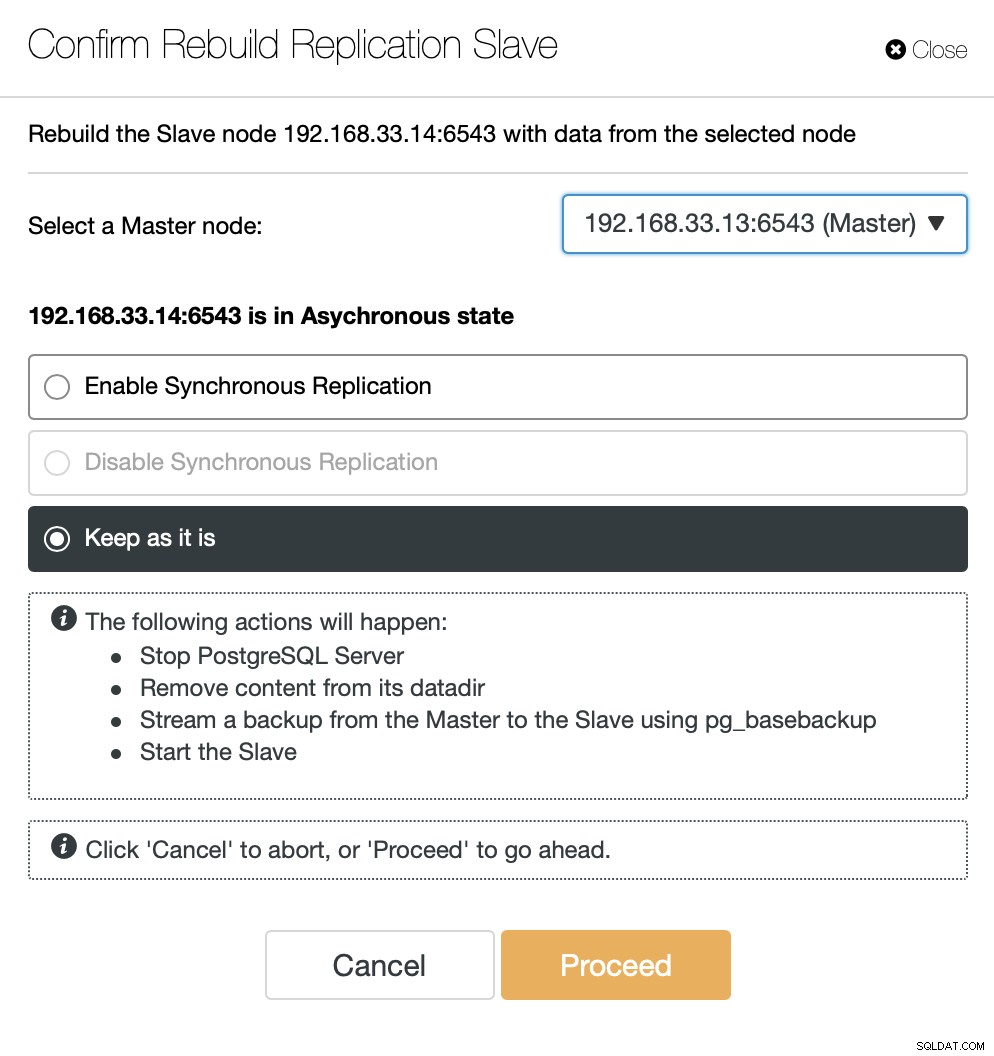
ClusterControl transmitirá la copia de seguridad desde el nuevo servidor principal y configurará la replicación.
Conclusión
La conmutación por error automática es una parte importante de cualquier base de datos de producción de Moodle. Puede reducir el tiempo de inactividad cuando un servidor deja de funcionar, pero también cuando se realizan tareas de mantenimiento o migraciones comunes. Es importante hacerlo bien, ya que es importante que el software de conmutación por error tome las decisiones correctas.