Anteriormente escribí sobre los beneficios de usar NOEXPAND sugerencias, incluso en Enterprise Edition. Todos los detalles están en el artículo vinculado, pero para resumir brevemente:
- SQL Server solo creará automáticamente estadísticas en una vista indexada cuando
NOEXPANDse utiliza la sugerencia de tabla. Omitir esta sugerencia puede generar advertencias en el plan de ejecución sobre estadísticas faltantes que no se pueden resolver creando estadísticas manualmente. - SQL Server solo usará estadísticas de vista creadas automática o manualmente en los cálculos de estimación de cardinalidad cuando la consulta hace referencia a la vista directamente y
NOEXPANDse utiliza la sugerencia. Para todas las definiciones de vista, excepto las más triviales, esto significa que es probable que la calidad de las estimaciones de cardinalidad sea menor cuando no se usa esta sugerencia, lo que a menudo da como resultado planes de ejecución menos óptimos. - La falta de, o la imposibilidad de usar, ver estadísticas puede hacer que el optimizador adivine las estimaciones de cardinalidad, incluso cuando las estadísticas de la tabla base están disponibles. Esto puede suceder cuando parte del plan de consulta se reemplaza con una referencia de vista indexada mediante la función de coincidencia de vista automática, pero las estadísticas de vista no están disponibles, como se describe anteriormente.
Hay otra consecuencia de no usar NOEXPAND sugerencia, que mencioné de pasada hace un par de años en mi artículo, Limitaciones del optimizador con índices filtrados:
El NOEXPAND se necesitan sugerencias incluso en Enterprise Edition para garantizar que el optimizador utilice la garantía de unicidad proporcionada por los índices de vista.
Este artículo examina esa declaración y sus implicaciones con más detalle.
Configuración de demostración
El siguiente script crea una tabla simple y una vista indexada:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Eso crea una tabla de montón de una sola columna y una vista sin restricciones de la misma tabla con un índice agrupado único. Esto no pretende ser un caso de uso realista para una vista indexada; pero ayudará a ilustrar los puntos clave con el mínimo de distracciones. El punto importante es que la tabla base aquí no tiene ningún índice (ni siquiera un índice agrupado), pero la vista sí, y ese índice es único.
La consulta de ejemplo
Considere la siguiente consulta simple contra la tabla base:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; El plan de ejecución que verá para esta consulta depende de la edición de SQL Server en uso. Si no es Enterprise Edition (o equivalente), verá un plan como este:

El optimizador de consultas de SQL Server ha optado por escanear la tabla base y aplicar la distinción especificada mediante un operador Distinct Sort. Esta forma de plan es totalmente esperada, ya que la coincidencia de vista indexada automática no está disponible fuera de Enterprise Edition. Voy a dejar de decir "Enterprise Edition o equivalente" de ahora en adelante, pero continúe infiriendo que me refiero a cualquier edición que admita la coincidencia de vista automática cuando digo "Enterprise Edition" de ahora en adelante.
La sugerencia EXPANDIR VISTAS
Esto es un poco aparte, pero para obtener el mismo plan en Enterprise Edition, necesitamos usar un EXPAND VIEWS sugerencia de consulta:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Puede parecer un poco extraño usar esta sugerencia cuando no hay referencias de vista en la consulta, pero así es como funciona. El EXPAND VIEWS La sugerencia especifica efectivamente que la coincidencia de vista indexada debe deshabilitarse mientras se compila y optimiza la consulta. Para que quede claro:sin esta sugerencia, Enterprise Edition puede hacer coincidir (partes de) la consulta con una o más vistas indexadas.
Con coincidencia de vista automática habilitada
Sin EXPAND VIEWS sugerencia, compilar la misma consulta en Developer Edition (por ejemplo) produce un plan diferente:
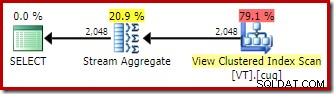
La aplicación de coincidencia de vista indexada significa que el plan de ejecución presenta un escaneo del índice agrupado de vista en lugar de un escaneo de tabla base.
El mismo plan se produce en este caso si la consulta hace referencia a la vista directamente (en lugar de la tabla base):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; En todas las ediciones, la referencia de vista se expande antes de que comience la optimización de consultas. En las ediciones equivalentes a Enterprise, el formulario expandido puede coincidir con la vista más adelante. Este es un concepto clave para entender cuando se piensa en cómo el compilador de consultas y el optimizador usan vistas indexadas en SQL Server.
El agregado de flujo
La diferencia más interesante entre los dos planes que hemos visto hasta ahora es Stream Aggregate en el plan de coincidencia de vistas. Si observa los costos estimados de los operadores Table Scan y View Scan, verá que son exactamente iguales. El optimizador no decidió usar la vista indexada porque abarataba el acceso a los datos. Más bien, escanear el índice de vista permite que DISTINCT requisito para implementarse como Stream Aggregate, en lugar de Hash Aggregate o Distinct Sort (como en el primer plan).
Un Stream Aggregate requiere entrada ordenada por la(s) columna(s) de agrupación. En este caso, el distintivo es equivalente a agrupar por una sola columna, y el índice agrupado único de la vista proporciona la garantía de orden necesaria. El modelo de costos del optimizador identifica Stream Aggregate como una opción más económica que Distinct Sort o Hash Aggregate para esta consulta. Esta es la base para que el optimizador elija acceder a la vista indexada cuando la coincidencia de vista automática está disponible.
Con todo lo dicho y entendido, Stream Aggregate sigue siendo inesperado:Dada la garantía de unicidad proporcionada por el índice de vista, no es necesario realizar esta operación de agrupación en absoluto. El único el índice agrupado ya garantiza que la columna no contenga duplicados.
Este, en pocas palabras, es el problema. Cuando se utiliza la coincidencia automática de vistas, el optimizador reconoce la garantía de pedido proporcionada por el índice de vistas, pero no la garantía de unicidad.
Usando una sugerencia NOEXPAND
Para obtener el plan de ejecución ideal para esta consulta, debemos hacer referencia a la vista directamente y usar un NOEXPAND sugerencia de tabla:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Esto nos da el plan que esperaría una persona con experiencia en bases de datos; uno que reconoce correctamente que la operación distinta es redundante y se puede eliminar:
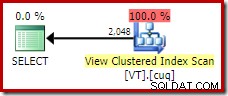
Un segundo ejemplo
No aprovechar la garantía de unicidad proporcionada por un índice de vista puede tener otros efectos en el plan de ejecución final. Considere ahora una unión automática de la vista indexada (nuevamente, solo para ilustrar un concepto; no pretende ser una consulta realista):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Al usar Developer Edition, el plan de ejecución elegido no accede a la vista indexada y presenta una unión hash (a veces indica que falta un índice útil):
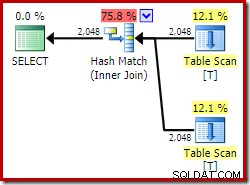
Ahora intentemos exactamente la misma consulta, pero con un NOEXPAND sugerencia sobre cada referencia de vista:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; El plan de ejecución ahora presenta dos accesos de vista indexados y una combinación de combinación:
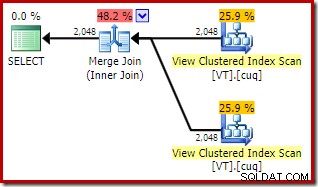
Este nuevo plan tiene un costo estimado mucho más bajo que el plan hash join, entonces, ¿por qué el optimizador no eligió esta opción antes? Podemos ver por qué agregando una sugerencia de combinación de combinación a la consulta original:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Esto le da un aspecto similar plan que elige acceder a la vista aunque NOEXPAND no se especificó:
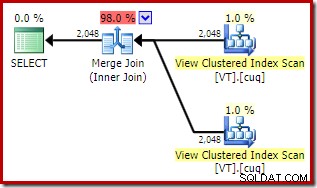
El costo total estimado de este plan es más alto que los dos ejemplos anteriores. Merge Join en este plan también representa una mayor proporción del costo total estimado que antes (98% versus 48.2%).
La razón de esto se puede ver observando las propiedades de la unión de fusión. En el NOEXPAND plan, era una unión de combinación de uno a muchos. En el plan directamente arriba, es una combinación de combinación de muchos a muchos. El modelo de costos del optimizador asigna un costo más alto a las uniones de combinación de muchos a muchos porque se necesita una mesa de trabajo de tempdb para manejar cualquier duplicado.
Conclusiones
Las garantías proporcionadas por un índice único pueden ser una poderosa herramienta de optimización, por lo que es una pena que la coincidencia automática de índices no pueda aprovecharla actualmente. Los beneficios potenciales van más allá de la eliminación de agregaciones innecesarias o la habilitación de una combinación de combinación de uno a varios, como se ve en los ejemplos simples anteriores. En general, puede ser difícil detectar que un plan de ejecución no es óptimo porque el optimizador no aprovechó una garantía de unicidad.
Esta limitación del optimizador no solo se aplica al índice agrupado único que debe tener una vista para materializarse. En escenarios más complejos, también pueden estar presentes índices no agrupados adicionales en la vista; tal vez para reflejar relaciones cruzadas que son difíciles de hacer cumplir o representar de otra manera. Si estos índices no agrupados se definen como únicos, el optimizador también pasará por alto estas garantías, si se utiliza la coincidencia automática de índices.
Agregando esto a las limitaciones en torno a la creación y el uso de información estadística, parece que confiar en la comparación automática de vistas puede resultar en planes de ejecución inferiores. La opción más segura es probablemente hacer referencia explícita a las vistas indexadas y usar un NOEXPAND sugerencia siempre, al menos hasta que estos problemas se aborden en el producto.
Factores atenuantes
Debo enfatizar que el problema descrito en este artículo solo se aplica a la garantía de unicidad proporcionada por un índice de vista único. Si el optimizador puede obtener la información de unicidad requerida otra manera , hay muchas posibilidades de que se eviten los problemas de optimización.
Por ejemplo, puede haber un índice único adecuado en una tabla base a la que hace referencia la vista. O, en el caso de una vista que contiene agregación, el optimizador ya puede inferir una garantía de unicidad útil a partir del GROUP BY de la vista. cláusula. La práctica común de agregar un índice agrupado de vista a las claves de agrupación no agrega información de exclusividad adicional en ese caso.
Sin embargo, hay momentos en los que esta "supervisión de unicidad" puede significar que obtendrá planes de ejecución de mejor calidad al usar una referencia de vista explícita y NOEXPAND sugerencias, incluso en Enterprise Edition.