Nota:esta publicación se publicó originalmente solo en nuestro libro electrónico, Técnicas de alto rendimiento para SQL Server, Volumen 4. Puede obtener más información sobre nuestros libros electrónicos aquí.
Regularmente me hacen la pregunta:"¿Por dónde empiezo cuando se trata de intentar ajustar una instancia de SQL Server?" Mi primera respuesta es preguntarles sobre la configuración de su instancia. Si ciertas cosas no están configuradas correctamente, comenzar a buscar consultas de larga duración o de alto costo de inmediato podría ser una pérdida de tiempo.
He escrito en un blog sobre cosas comunes que los administradores pasan por alto, donde comparto muchas de las configuraciones que los administradores deben cambiar desde una instalación predeterminada de SQL Server. Para elementos relacionados con el rendimiento, les digo que deben verificar lo siguiente:
- Configuración de memoria
- Actualización de estadísticas
- Mantenimiento de índice
- MAXDOP y umbral de costo para paralelismo
- mejores prácticas de tempdb
- Optimizar para cargas de trabajo ad hoc
Una vez que paso los elementos de configuración, les pregunto si han mirado las estadísticas de archivo y espera, así como las consultas de alto costo. La mayoría de las veces la respuesta es "no", con una explicación de que no están seguros de cómo encontrar esa información.
Por lo general, el cumplimiento común cuando alguien dice que necesita ajustar un servidor SQL es que se está ejecutando lentamente. ¿Qué significa lento? ¿Es un informe determinado, una aplicación específica o todo? ¿Comenzó a suceder o ha ido empeorando con el tiempo? Comienzo haciendo las preguntas habituales de clasificación de cómo se compara la utilización de la memoria, la CPU y el disco cuando las cosas son normales, si el problema comenzó a ocurrir y qué cambió recientemente. A menos que el cliente esté capturando una línea de base, no tiene métricas con las que comparar para saber si las estadísticas actuales son anormales.
Casi todos los servidores SQL en los que trabajo alojan más de una base de datos de usuario. Cuando un cliente informa que SQL Server se está ejecutando lentamente, la mayoría de las veces está preocupado por una aplicación específica que está causando problemas a sus clientes. Una reacción instintiva es centrarse de inmediato en esa base de datos en particular, sin embargo, muchas veces otro proceso podría estar consumiendo recursos valiosos y la base de datos de la aplicación se ve afectada. Por ejemplo, si tiene una gran base de datos de informes y alguien inició un informe masivo que satura el disco, aumenta la CPU y vacía el caché del plan, puede apostar a que las otras bases de datos de usuarios se ralentizarán mientras se genera ese informe.
Siempre me gusta comenzar mirando las estadísticas del archivo. Para SQL Server 2005 y versiones posteriores, puede consultar el DMV sys.dm_io_virtual_file_stats para obtener estadísticas de E/S para cada archivo de registro y datos. Este DMV reemplazó la función fn_virtualfilestats. Para capturar las estadísticas del archivo, me gusta usar un script que elaboró Paul Randal:capturar las latencias de E/S durante un período de tiempo. Este script capturará una línea de base y, 30 minutos más tarde (a menos que cambie la duración en la sección WAITFOR DELAY), capturará las estadísticas y calculará los deltas entre ellas. El script de Paul también hace un poco de matemática para determinar las latencias de lectura y escritura, lo que nos facilita mucho la lectura y la comprensión.
En mi computadora portátil, restauré una copia de la base de datos AdventureWorks2014 en una unidad USB para tener velocidades de disco más lentas; Luego inicié un proceso para generar una carga en su contra. Puede ver los resultados a continuación, donde mi latencia de escritura para mi archivo de datos es de 240 ms y la latencia de escritura para mi archivo de registro es de 46 ms. Las latencias tan altas son problemáticas.
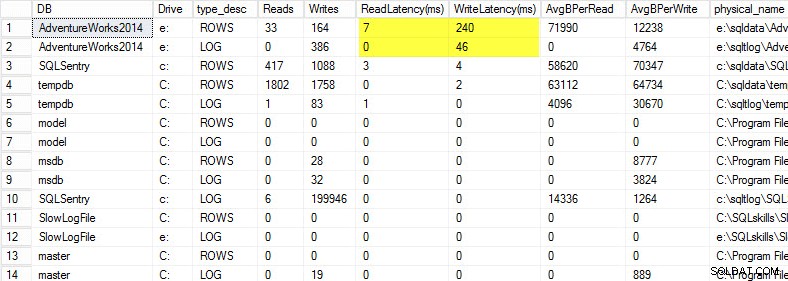
Cualquier cosa por encima de 20 ms debe considerarse mala, como compartí en una publicación anterior:monitorear la latencia de lectura/escritura. Mi latencia de lectura es decente, pero la base de datos AdventureWorks2014 sufre escrituras lentas. En este caso, investigaría qué está generando las escrituras, además de investigar el rendimiento de mi subsistema de E/S. Si esto hubiera sido latencias de lectura excesivamente altas, comenzaría a investigar el rendimiento de las consultas (por qué está haciendo tantas lecturas, por ejemplo, de índices faltantes), así como el rendimiento general del subsistema de E/S.
Es importante conocer el rendimiento general de su subsistema de E/S, y la mejor manera de saber de lo que es capaz es mediante una evaluación comparativa. Glenn Berry habla de esto en su artículo que analiza el rendimiento de E/S para SQL Server. Glenn explica la latencia, las IOPS y el rendimiento y muestra CrystalDiskMark, que es una herramienta gratuita que puede usar para establecer una línea base de su almacenamiento.
Después de averiguar cómo se están desempeñando las estadísticas del archivo, me gusta mirar las estadísticas de espera mediante el DMV sys.dm_os_wait_stats, que devuelve información sobre todas las esperas que ocurrieron. Para esto recurro a otra secuencia de comandos que Paul Randal proporciona en su publicación de blog de captura de estadísticas de espera para un período de tiempo. El guión de Paul vuelve a hacer un poco de matemáticas por nosotros pero, lo que es más importante, excluye muchas de las esperas benignas que normalmente no nos importan. Este script también tiene WAITFOR DELAY y está configurado en 30 minutos. Leer las estadísticas de espera puede ser un poco más complicado:puede tener esperas que parezcan altas según el porcentaje, pero la espera promedio es tan baja que no es motivo de preocupación.
Inicié el mismo proceso de carga y capturé mis estadísticas de espera, que se muestran a continuación. Para obtener explicaciones sobre muchos de estos tipos de espera, puede leer otra de las publicaciones del blog de Paul, estadísticas de espera o, por favor, dígame dónde le duele, además de algunas de sus publicaciones en este blog.
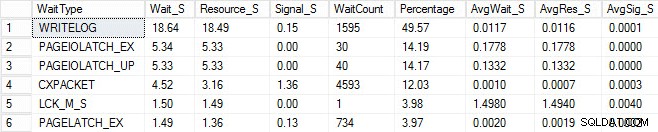
En esta salida artificial, las esperas de PAGEIOLATCH podrían indicar un cuello de botella con mi subsistema de E/S, pero también podrían ser un problema de memoria, búsquedas de escaneos de tablas o una serie de otros problemas. En mi caso, sabemos que es un problema de disco, ya que estoy almacenando la base de datos en una memoria USB. El tiempo de espera de LCK_M_S es muy alto, sin embargo, solo hay una instancia de la espera. Mi WRITELOG también es más alto de lo que me gustaría ver, pero es comprensible conociendo los problemas de latencia con la memoria USB. Esto también muestra las esperas de CXPACKET, y sería fácil tener una reacción instintiva y pensar que tiene un problema de paralelismo/MAXDOP, sin embargo, el contador AvgWait_S es muy bajo. Tenga cuidado al usar las esperas para la resolución de problemas. Deje que sea una guía para decirle cosas que no son el problema, así como para darle una dirección de dónde buscar problemas. La solución adecuada de problemas consiste en correlacionar los comportamientos de múltiples áreas para reducir el problema.
Después de mirar el archivo y las estadísticas de espera, empiezo a profundizar en las consultas de alto costo en función de los problemas que encontré. Para ello recurro a las consultas de información de diagnóstico de Glenn Berry. Estos conjuntos de consultas son los guiones de acceso que utilizan muchos consultores. Glenn y la comunidad constantemente brindan actualizaciones para que sean lo más informativos y sólidos posible. Una de mis consultas favoritas son las principales consultas almacenadas en caché por número de ejecuciones. Me encanta encontrar consultas o procedimientos almacenados que tengan un alto número de ejecuciones junto con un alto total de lecturas lógicas. Si esas consultas tienen oportunidades de ajuste, entonces puede hacer una gran diferencia para el servidor rápidamente. En los scripts también se incluyen los SP principales en caché por lecturas lógicas totales y los SP principales en caché por lecturas físicas totales. Ambos son buenos para buscar lecturas altas con recuentos de ejecución altos para que pueda reducir la cantidad de E/S.
Además de los scripts de Glenn, me gusta usar sp_whoisactive de Adam Machanic para ver lo que se está ejecutando actualmente.
Hay mucho más en el ajuste del rendimiento que solo mirar las estadísticas de archivo y espera y las consultas de alto costo, sin embargo, ahí es donde me gusta comenzar. Es una forma de evaluar rápidamente un entorno para comenzar a determinar qué está causando el problema. No existe una forma completamente infalible de sintonizar:lo que cada DBA de producción necesita es una lista de verificación de las cosas que se deben ejecutar para eliminar y una muy buena colección de scripts para analizar la salud del sistema. Tener una línea de base es clave para descartar rápidamente un comportamiento normal o anormal. Mi buena amiga Erin Stellato tiene un curso completo sobre Pluralsight llamado SQL Server:Benchmarking and Baselining si necesita ayuda para configurar y capturar su línea base.
Mejor aún, obtenga una herramienta de última generación como SQL Sentry Performance Advisor que no solo recopilará y almacenará información histórica para generar perfiles y tendencias, y brindará acceso fácil a todos los detalles mencionados anteriormente y más, sino que también le brinda la capacidad de comparar la actividad con líneas de base integradas o definidas por el usuario, mantener índices de manera eficiente sin mover un dedo y alertar o automatizar respuestas basadas en una arquitectura de condiciones personalizadas muy sólida. La siguiente captura de pantalla muestra la vista histórica del panel de Performance Advisor, con esperas de disco en naranja, E/S de la base de datos en la parte inferior derecha y líneas de base que comparan el período actual y el anterior en cada gráfico (haga clic para ampliar):
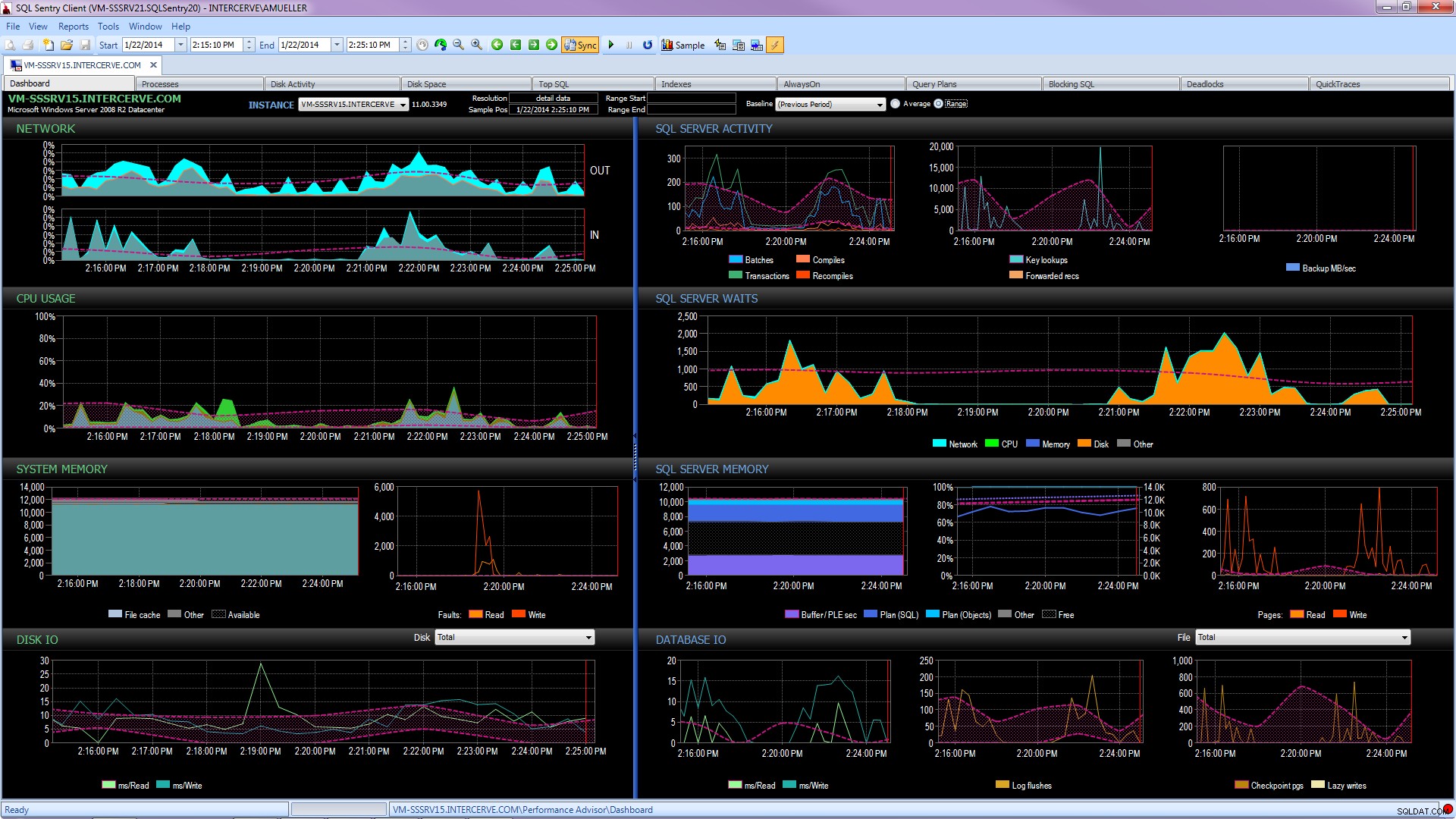
Las herramientas de control de calidad no son gratuitas, pero proporcionan una gran cantidad de funciones y soporte que le permiten centrarse en los problemas de rendimiento de sus servidores, en lugar de centrarse en consultas, trabajos y alertas que pueden le permite concentrarse en sus problemas de rendimiento, pero solo una vez que los haya resuelto correctamente. A menudo, es muy valioso no reinventar la rueda.