Este artículo es la duodécima parte de una serie sobre expresiones de tabla con nombre. Hasta ahora, cubrí tablas derivadas y CTE, que son expresiones de tabla con nombre con ámbito de declaración, y vistas, que son expresiones de tabla con nombre reutilizables. Este mes presento funciones con valores de tabla en línea, o iTVF, y describo sus beneficios en comparación con las otras expresiones de tabla con nombre. También los comparo con los procedimientos almacenados, centrándome principalmente en las diferencias en términos de la estrategia de optimización predeterminada, y planifico el comportamiento de almacenamiento en caché y reutilización. Hay mucho que cubrir en términos de optimización, así que comenzaré la discusión este mes y continuaré el próximo mes.
En mis ejemplos, usaré una base de datos de muestra llamada TSQLV5. Puede encontrar el script que lo crea y lo completa aquí y su diagrama ER aquí.
¿Qué es una función con valores de tabla en línea?
En comparación con las expresiones de tabla con nombre cubiertas anteriormente, los iTVF se parecen principalmente a las vistas. Al igual que las vistas, los iTVF se crean como un objeto permanente en la base de datos y, por lo tanto, los usuarios que tienen permisos para interactuar con ellos pueden reutilizarlos. La principal ventaja que tienen los iTVF en comparación con las vistas es el hecho de que admiten parámetros de entrada. Por lo tanto, la forma más sencilla de describir un iTVF es como una vista parametrizada, aunque técnicamente se crea con una instrucción CREATE FUNCTION y no con una instrucción CREATE VIEW.
Es importante no confundir las iTVF con las funciones con valores de tabla de múltiples declaraciones (MSTVF). La primera es una expresión de tabla nombrada inlineable basada en una única consulta similar a una vista y es el tema central de este artículo. Este último es un módulo programático que devuelve una variable de tabla como salida, con un flujo de varias declaraciones en su cuerpo cuyo propósito es llenar con datos la variable de tabla devuelta.
Sintaxis
Esta es la sintaxis de T-SQL para crear un iTVF:
CREAR [ O ALTERAR ] FUNCIÓN [
[ (
TABLA DE DEVOLUCIONES
[ CON
COMO
VOLVER
Observe en la sintaxis la posibilidad de definir parámetros de entrada.
El propósito del atributo SCHEMABIDNING es el mismo que el de las vistas y debe evaluarse en función de consideraciones similares. Para obtener más información, consulte la Parte 10 de la serie.
Un ejemplo
Como ejemplo de un iTVF, suponga que necesita crear una expresión de tabla con nombre reutilizable que acepte como entradas un ID de cliente (@custid) y un número (@n) y devuelva el número solicitado de los pedidos más recientes de la tabla Sales.Orders para el cliente de entrada.
No puede implementar esta tarea con una vista, ya que las vistas no son compatibles con los parámetros de entrada. Como se mencionó, puede pensar en un iTVF como una vista parametrizada y, como tal, es la herramienta adecuada para esta tarea.
Antes de implementar la función en sí, aquí hay un código para crear un índice de soporte en la tabla Sales.Orders:
USE TSQLV5; GO CREATE INDEX idx_nc_cid_odD_oidD_i_eid ON Sales.Orders(custid, orderdate DESC, orderid DESC) INCLUDE(empid);
Y aquí está el código para crear la función, llamada Sales.GetTopCustOrders:
CREATE OR ALTER FUNCTION Sales.GetTopCustOrders ( @custid AS INT, @n AS BIGINT ) RETURNS TABLE AS RETURN SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Al igual que con las tablas base y las vistas, cuando busca recuperar datos, especifica iTVF en la cláusula FROM de una instrucción SELECT. Aquí hay un ejemplo solicitando los tres pedidos más recientes para el cliente 1:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
Me referiré a este ejemplo como Consulta 1. El plan para la Consulta 1 se muestra en la Figura 1.
 Figura 1:Plan para Consulta 1
Figura 1:Plan para Consulta 1
¿Qué tienen de integrado los iTVF?
Si se pregunta cuál es el origen del término en línea en las funciones con valores de tabla en línea, tiene que ver con cómo se optimizan. El concepto de inserción es aplicable a los cuatro tipos de expresiones de tabla con nombre que admite T-SQL y, en parte, implica lo que describí en la Parte 4 de la serie como anidamiento/sustitución. Asegúrese de volver a visitar la sección correspondiente en la Parte 4 si necesita un repaso.
Como puede ver en la Figura 1, gracias al hecho de que la función se incorporó, SQL Server pudo crear un plan óptimo que interactúa directamente con los índices de la tabla base subyacente. En nuestro caso, el plan realiza una búsqueda en el índice de soporte que creó anteriormente.
Los iTVF llevan el concepto de inserción un paso más allá al aplicar la optimización de incrustación de parámetros de forma predeterminada. Paul White describe la optimización de incrustación de parámetros en su excelente artículo Parámetros Sniffing, Embedding, and the RECOMPILE Options. Con la optimización de incrustación de parámetros, las referencias de los parámetros de consulta se reemplazan con los valores constantes literales de la ejecución actual y luego se optimiza el código con las constantes.
Observe en el plan de la Figura 1 que tanto el predicado de búsqueda del operador Index Seek como la expresión superior del operador Top muestran los valores constantes literales incrustados 1 y 3 de la ejecución de la consulta actual. No muestran los parámetros @custid y @n, respectivamente.
Con iTVF, la optimización de incrustación de parámetros se utiliza de forma predeterminada. Con los procedimientos almacenados, las consultas parametrizadas se optimizan de forma predeterminada. Debe agregar OPTION(RECOMPILE) a la consulta de un procedimiento almacenado para solicitar la optimización de incrustación de parámetros. Más detalles sobre la optimización de iTVF versus procedimientos almacenados, incluidas las implicaciones, en breve.
Modificación de datos a través de iTVF
Recuerde de la Parte 11 de la serie que, siempre que se cumplan ciertos requisitos, las expresiones de tabla con nombre pueden ser objeto de declaraciones de modificación. Esta capacidad se aplica a los iTVF de forma similar a como se aplica a las visualizaciones. Por ejemplo, aquí hay un código que podría usar para eliminar los tres pedidos más recientes del cliente 1 (en realidad, no ejecute esto):
DELETE FROM Sales.GetTopCustOrders(1, 3);
Específicamente en nuestra base de datos, intentar ejecutar este código fallaría debido a la aplicación de la integridad referencial (los pedidos afectados tienen líneas de pedido relacionadas en la tabla Sales.OrderDetails), pero es un código válido y compatible.
iTVF frente a procedimientos almacenados
Como se mencionó anteriormente, la estrategia de optimización de consultas predeterminada para iTVF es diferente a la de los procedimientos almacenados. Con iTVF, el valor predeterminado es utilizar la optimización de incrustación de parámetros. Con los procedimientos almacenados, el valor predeterminado es optimizar las consultas parametrizadas mientras se aplica la detección de parámetros. Para obtener la incrustación de parámetros para una consulta de procedimiento almacenado, debe agregar OPTION(RECOMPILE).
Al igual que con muchas estrategias y técnicas de optimización, la incorporación de parámetros tiene sus ventajas y desventajas.
La ventaja principal es que permite simplificaciones de consultas que a veces pueden resultar en planes más eficientes. Algunas de esas simplificaciones son verdaderamente fascinantes. Paul demuestra esto con procedimientos almacenados en su artículo, y lo demostraré con iTVF el próximo mes.
El principal inconveniente de la optimización de la incorporación de parámetros es que no obtiene un comportamiento de reutilización y almacenamiento en caché de planes eficiente como lo hace con los planes parametrizados. Con cada combinación distinta de valores de parámetros, obtiene una cadena de consulta distinta y, por lo tanto, una compilación separada que da como resultado un plan en caché separado. Con iTVF con entradas constantes, puede obtener un comportamiento de reutilización del plan, pero solo si se repiten los mismos valores de parámetro. Obviamente, una consulta de procedimiento almacenado con OPCIÓN (RECOMPILAR) no reutilizará un plan, incluso cuando repita los mismos valores de parámetro, por solicitud.
Demostraré tres casos:
- Planes reutilizables con constantes resultantes de la optimización de incrustación de parámetros predeterminados para consultas iTVF con constantes
- Planes parametrizados reutilizables resultantes de la optimización predeterminada de consultas de procedimientos almacenados parametrizados
- Planes no reutilizables con constantes resultantes de la optimización de incrustación de parámetros para consultas de procedimientos almacenados con OPTION(RECOMPILE)
Comencemos con el caso #1.
Utilice el siguiente código para consultar nuestro iTVF con @custid =1 y @n =3:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(1, 3);
Como recordatorio, esta sería la segunda ejecución del mismo código, ya que ya lo ejecutó una vez con los mismos valores de parámetro anteriormente, lo que resultó en el plan que se muestra en la Figura 1.
Use el siguiente código para consultar el iTVF con @custid =2 y @n =3 una vez:
SELECT orderid, orderdate, empid FROM Sales.GetTopCustOrders(2, 3);
Me referiré a este código como Consulta 2. El plan para la Consulta 2 se muestra en la Figura 2.
 Figura 2:Plan para la consulta 2
Figura 2:Plan para la consulta 2
Recuerde que el plan de la Figura 1 para la consulta 1 hacía referencia al ID de cliente constante 1 en el predicado de búsqueda, mientras que este plan hace referencia al ID de cliente constante 2.
Utilice el siguiente código para examinar las estadísticas de ejecución de consultas:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders(%';
Este código genera el siguiente resultado:
plan_handle execution_count text query_plan ------------------- --------------- ---------------------------------------------- ---------------- 0x06000B00FD9A1... 1 SELECT ... FROM Sales.GetTopCustOrders(2, 3); <ShowPlanXML...> 0x06000B00F5C34... 2 SELECT ... FROM Sales.GetTopCustOrders(1, 3); <ShowPlanXML...> (2 rows affected)
Aquí se crearon dos planes separados:uno para la consulta con el ID de cliente 1, que se usó dos veces, y otro para la consulta con el ID de cliente 2, que se usó una vez. Con una gran cantidad de combinaciones distintas de valores de parámetros, terminará con una gran cantidad de compilaciones y planes almacenados en caché.
Procedamos con el caso n.º 2:la estrategia de optimización predeterminada de las consultas de procedimientos almacenados parametrizados. Use el siguiente código para encapsular nuestra consulta en un procedimiento almacenado llamado Sales.GetTopCustOrders2:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC; GO
Use el siguiente código para ejecutar el procedimiento almacenado con @custid =1 y @n =3 dos veces:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
La primera ejecución desencadena la optimización de la consulta, lo que da como resultado el plan parametrizado que se muestra en la Figura 3:
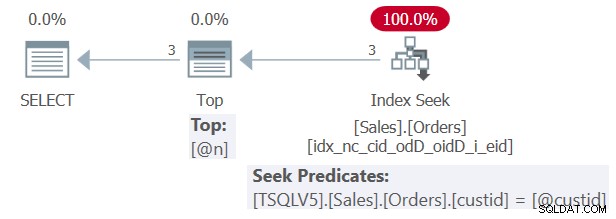 Figura 3:Plan para el proceso Sales.GetTopCustOrders2
Figura 3:Plan para el proceso Sales.GetTopCustOrders2
Observe la referencia al parámetro @custid en el predicado de búsqueda y al parámetro @n en la expresión superior.
Use el siguiente código para ejecutar el procedimiento almacenado con @custid =2 y @n =3 una vez:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
El plan parametrizado almacenado en caché que se muestra en la Figura 3 se vuelve a utilizar.
Utilice el siguiente código para examinar las estadísticas de ejecución de consultas:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Este código genera el siguiente resultado:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 3 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
Solo se creó y almacenó en caché un plan parametrizado, y se usó tres veces, a pesar de los valores de ID de cliente cambiantes.
Procedamos al caso #3. Como se mencionó, con las consultas de procedimientos almacenados puede obtener la optimización de incrustación de parámetros al usar OPTION(RECOMPILE). Utilice el siguiente código para modificar la consulta de procedimiento para incluir esta opción:
CREATE OR ALTER PROC Sales.GetTopCustOrders2 ( @custid AS INT, @n AS BIGINT ) AS SET NOCOUNT ON; SELECT TOP (@n) orderid, orderdate, empid FROM Sales.Orders WHERE custid = @custid ORDER BY orderdate DESC, orderid DESC OPTION(RECOMPILE); GO
Ejecute el proceso con @custid =1 y @n =3 dos veces:
EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3; EXEC Sales.GetTopCustOrders2 @custid = 1, @n = 3;
Obtiene el mismo plan que se muestra anteriormente en la Figura 1 con las constantes incrustadas.
Ejecute el proceso con @custid =2 y @n =3 una vez:
EXEC Sales.GetTopCustOrders2 @custid = 2, @n = 3;
Obtiene el mismo plan que se muestra anteriormente en la Figura 2 con las constantes incrustadas.
Examine las estadísticas de ejecución de consultas:
SELECT Q.plan_handle, Q.execution_count, T.text, P.query_plan FROM sys.dm_exec_query_stats AS Q CROSS APPLY sys.dm_exec_sql_text(Q.plan_handle) AS T CROSS APPLY sys.dm_exec_query_plan(Q.plan_handle) AS P WHERE T.text LIKE '%Sales.' + 'GetTopCustOrders2%';
Este código genera el siguiente resultado:
plan_handle execution_count text query_plan ------------------- --------------- ----------------------------------------------- ---------------- 0x05000B00F1604... 1 ...SELECT TOP (@n)...WHERE custid = @custid...; <ShowPlanXML...> (1 row affected)
El recuento de ejecuciones muestra 1, lo que refleja solo la última ejecución. SQL Server almacena en caché el último plan ejecutado, por lo que puede mostrar estadísticas para esa ejecución, pero a pedido, no reutiliza el plan. Si revisa el plan que se muestra debajo del atributo query_plan, encontrará que es el que se creó para las constantes en la última ejecución, que se muestra anteriormente en la Figura 2.
Si busca menos compilaciones y un comportamiento de reutilización y almacenamiento en caché de planes eficiente, el enfoque de optimización de procedimientos almacenados predeterminado de consultas parametrizadas es el camino a seguir.
Hay una gran ventaja que tiene una implementación basada en iTVF sobre una basada en procedimientos almacenados:cuando necesita aplicar la función a cada fila en una tabla y pasar columnas de la tabla como entradas. Por ejemplo, suponga que necesita devolver los tres pedidos más recientes para cada cliente en la tabla Ventas.Clientes. Ninguna construcción de consulta le permite aplicar un procedimiento almacenado por fila en una tabla. Podría implementar una solución iterativa con un cursor, pero siempre es un buen día cuando puede evitar los cursores. Al combinar el operador APLICAR con una llamada iTVF, puede lograr la tarea de manera agradable y limpia, así:
SELECT C.custid, O.orderid, O.orderdate, O.empid FROM Sales.Customers AS C CROSS APPLY Sales.GetTopCustOrders( C.custid, 3 ) AS O;
Este código genera el siguiente resultado (abreviado):
custid orderid orderdate empid ----------- ----------- ---------- ----------- 1 11011 2019-04-09 3 1 10952 2019-03-16 1 1 10835 2019-01-15 1 2 10926 2019-03-04 4 2 10759 2018-11-28 3 2 10625 2018-08-08 3 ... (263 rows affected)
La llamada a la función se inserta y la referencia al parámetro @custid se reemplaza con la correlación C.custid. Esto da como resultado el plan que se muestra en la Figura 4.
 Figura 4:Plan de consulta con APPLY y Sales.GetTopCustOrders iTVF
Figura 4:Plan de consulta con APPLY y Sales.GetTopCustOrders iTVF
El plan escanea algún índice en la tabla Sales.Customers para obtener el conjunto de ID de clientes y aplica una búsqueda en el índice de soporte que creó anteriormente en Sales.Orders por cliente. Solo hay un plan desde que la función se incorporó en la consulta externa, convirtiéndose en una combinación correlacionada o lateral. Este plan es muy eficiente, especialmente cuando la columna custid en Sales.Orders es muy densa, lo que significa que hay una pequeña cantidad de ID de clientes distintos.
Por supuesto, hay otras formas de implementar esta tarea, como usar un CTE con la función ROW_NUMBER. Esta solución tiende a funcionar mejor que la basada en APPLY cuando la columna custid en la tabla Sales.Orders tiene baja densidad. De cualquier manera, la tarea específica que utilicé en mis ejemplos no es tan importante para los propósitos de nuestra discusión. Mi punto era explicar las diferentes estrategias de optimización que emplea SQL Server con las diferentes herramientas.
Cuando haya terminado, use el siguiente código para la limpieza:
DROP INDEX IF EXISTS idx_nc_cid_odD_oidD_i_eid ON Sales.Orders;
Resumen y lo que sigue
Entonces, ¿qué hemos aprendido de esto?
Un iTVF es una expresión de tabla nombrada parametrizada reutilizable.
SQL Server utiliza una estrategia de optimización de incrustación de parámetros con iTVF de forma predeterminada y una estrategia de optimización de consultas parametrizadas con consultas de procedimientos almacenados. Agregar OPCIÓN (RECOMPILE) a una consulta de procedimiento almacenado puede resultar en la optimización de incrustación de parámetros.
Si desea obtener menos compilaciones y un almacenamiento en caché de planes eficiente y un comportamiento de reutilización, los planes de consulta de procedimientos parametrizados son el camino a seguir.
Los planes para las consultas de iTVF se almacenan en caché y se pueden reutilizar, siempre que se repitan los mismos valores de parámetro.
Puede combinar convenientemente el uso del operador APLICAR y un iTVF para aplicar el iTVF a cada fila de la tabla de la izquierda, pasando columnas de la tabla de la izquierda como entradas al iTVF.
Como se mencionó, hay mucho que cubrir sobre la optimización de iTVF. Este mes comparé los iTVF y los procedimientos almacenados en términos de la estrategia de optimización predeterminada y el comportamiento de reutilización y almacenamiento en caché del plan. El próximo mes profundizaré más en las simplificaciones resultantes de la optimización de la incorporación de parámetros.