Predicados únicos
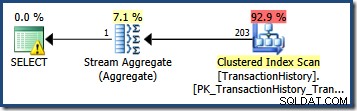
Estimar el número de filas calificadas por un único predicado de consulta suele ser sencillo. Cuando un predicado hace una comparación simple entre una columna y un valor escalar, es muy probable que el estimador de cardinalidad podrá derivar una estimación de buena calidad del histograma estadístico. Por ejemplo, la siguiente consulta de AdventureWorks produce una estimación exactamente correcta de 203 filas (suponiendo que no se hayan realizado cambios en los datos desde que se crearon las estadísticas):
SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.TransactionDate = '20070903';
Mirando el histograma de estadísticas para TransactionDate columna, es claro ver de dónde vino esta estimación:
DBCC SHOW_STATISTICS (
'Production.TransactionHistory',
'TransactionDate')
WITH HISTOGRAM;
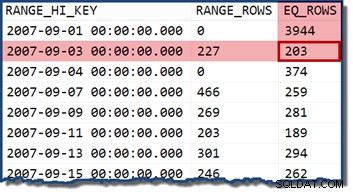
Si cambiamos la consulta para especificar una fecha que se encuentra dentro de un cubo de histograma, el estimador de cardinalidad asume que los valores están distribuidos uniformemente. Usando una fecha de 2007-09-02 produce una estimación de 227 filas (del RANGE_ROWS entrada). Como nota al margen interesante, la estimación permanece en 227 filas, independientemente de cualquier porción de tiempo que podamos agregar al valor de la fecha (la TransactionDate la columna es una datetime tipo de datos).
Si volvemos a intentar la consulta con una fecha de 2007-09-05 o 2007-09-06 (ambos se encuentran entre el 2007-09-04 y 2007-09-07 pasos del histograma), el estimador de cardinalidad asume el 466 RANGE_ROWS se dividen equitativamente entre los dos valores, estimando 233 filas en ambos casos.
Hay muchos otros detalles en la estimación de cardinalidad para predicados simples, pero lo anterior servirá como repaso para nuestros propósitos actuales.
Los problemas de múltiples predicados
Cuando una consulta contiene más de un predicado de columna, la estimación de la cardinalidad se vuelve más difícil. Considere la siguiente consulta con dos predicados simples (cada uno de los cuales es fácil de estimar solo):
SELECT
COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'; Los rangos específicos de valores en la consulta se eligen deliberadamente para que ambos predicados identifiquen exactamente las mismas filas. Podríamos modificar fácilmente los valores de la consulta para dar como resultado cualquier cantidad de superposición, incluso ninguna superposición en absoluto. Imagine ahora que es el estimador de cardinalidad:¿cómo obtendría una estimación de cardinalidad para esta consulta?
El problema es más difícil de lo que podría parecer a primera vista. De forma predeterminada, SQL Server crea automáticamente estadísticas de una sola columna en ambas columnas de predicado. También podemos crear estadísticas de varias columnas manualmente. ¿Nos da esto suficiente información para producir una buena estimación de estos valores específicos? ¿Qué pasa con el caso más general en el que podría haber cualquier grado de superposición?
Usando los dos objetos estadísticos de una sola columna, podemos derivar fácilmente una estimación para cada predicado usando el método de histograma descrito en la sección anterior. Para los valores específicos de la consulta anterior, los histogramas muestran que el TransactionID se espera que el rango coincida con 68412.4 filas y la TransactionDate se espera que el rango coincida con 68,413 filas (Si los histogramas fueran perfectos, estos dos números serían exactamente iguales).
Lo que los histogramas no pueden díganos cuántos de estos dos conjuntos de filas serán las mismas filas . Todo lo que podemos decir basándonos en la información del histograma es que nuestra estimación debe estar en algún lugar entre cero (sin superposición) y 68412,4 filas (superposición completa).
La creación de estadísticas de varias columnas no proporciona ayuda para esta consulta (o para consultas de rango en general). Las estadísticas de varias columnas solo crean un histograma sobre la primera columna nombrada, esencialmente duplicando el histograma asociado con una de las estadísticas creadas automáticamente. La densidad adicional la información proporcionada por la estadística de varias columnas puede ser útil para proporcionar información de casos promedio para consultas que contienen múltiples predicados de igualdad, pero no nos ayudan aquí.
Para producir una estimación con un alto grado de confianza, necesitaríamos SQL Server para proporcionar mejor información sobre la distribución de datos, algo así como un multidimensional histograma de estadísticas. Hasta donde yo sé, ningún motor de base de datos comercial ofrece actualmente una función como esta, aunque se han publicado varios documentos técnicos sobre el tema (incluido uno de Microsoft Research que utilizó un desarrollo interno de SQL Server 2000).
Sin saber nada acerca de las correlaciones y superposiciones de datos para rangos de valores particulares, no está claro cómo debemos proceder para producir una buena estimación para nuestra consulta. Entonces, ¿qué hace SQL Server aquí?
Servidor SQL 7 – 2012
El estimador de cardinalidad en estas versiones de SQL Server generalmente asume que los valores de diferentes atributos en una tabla se distribuyen de forma completamente independiente entre sí. Esta suposición de independencia rara vez es un reflejo preciso de los datos reales, pero tiene la ventaja de hacer cálculos más simples.
Y Selectividad
Usando la suposición de independencia, dos predicados conectados por AND (conocido como conjunción ) con selectividades S1 y S2 , resultan en una selectividad combinada de:
(S1 * S2)
En caso de que el término no le resulte familiar, selectividad es un número entre 0 y 1, que representa la fracción de filas en la tabla que pasan el predicado. Por ejemplo, si un predicado selecciona 12 filas de una tabla de 100 filas, la selectividad es (12/100) =0,12.
En nuestro ejemplo, el TransactionHistory la tabla contiene 113.443 filas en total. El predicado en TransactionID se estima (a partir del histograma) para calificar 68.412,4 filas, por lo que la selectividad es (68.412,4/113.443) o aproximadamente 0,603055 . El predicado en TransactionDate se estima de manera similar que tiene una selectividad de (68 413/113 443) =aproximadamente 0,603061 .
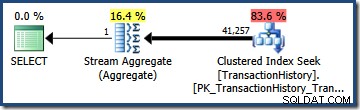
Multiplicar las dos selectividades (usando la fórmula anterior) da una estimación de selectividad combinada de 0.363679 . Multiplicando esta selectividad por la cardinalidad de la tabla (113.443) se obtiene la estimación final de 41.256,8 filas:
O Selectividad
Dos predicados conectados por OR (una disyunción ) con selectividades S1 y S2 , resulta en una selectividad combinada de:
(S1 + S2) – (S1 * S2)
La intuición detrás de la fórmula es sumar las dos selectividades, luego restar la estimación de su conjunción (usando la fórmula anterior). Claramente podríamos tener dos predicados, cada uno de selectividad 0.8, pero simplemente sumarlos produciría una selectividad combinada imposible de 1.6. A pesar de la suposición de independencia, debemos reconocer que los dos predicados pueden superponerse, por lo que para evitar la doble contabilización, se resta la selectividad estimada de la conjunción.
Podemos modificar fácilmente nuestro ejemplo en ejecución para usar OR :
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
OR TH.TransactionDate BETWEEN '20070901' AND '20080313';
Sustituyendo las selectividades de predicado en OR fórmula da una selectividad combinada de:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
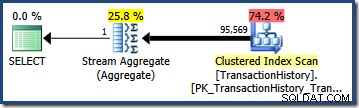
Multiplicada por el número de filas de la tabla, esta selectividad nos da la cardinalidad final estimada de 95.568,6 :
Ninguna estimación (41,257 para el AND consulta; OR consulta) es particularmente bueno porque ambos se basan en una suposición de modelado que no coincide muy bien con la distribución de datos. Ambas consultas devuelven 68 413 filas (porque los predicados identifican exactamente las mismas filas).
Bandera de seguimiento 4137:selectividad mínima
Para SQL Server 2008 (R1) a 2012 inclusive, Microsoft lanzó una solución que cambia la forma en que se calcula la selectividad para AND caso (predicados conjuntivos) solamente. El artículo de Knowledge Base en ese enlace no contiene muchos detalles, pero resulta que la solución cambia la fórmula de selectividad utilizada. En lugar de multiplicar las selectividades individuales, la estimación de cardinalidad para predicados conjuntivos ahora usa solo la selectividad más baja.
Para activar el cambio de comportamiento, se requiere el indicador de seguimiento compatible 4137. Un artículo separado de la base de conocimientos documenta que esta marca de rastreo también es compatible para el uso por consulta a través de QUERYTRACEON pista:
SELECT COUNT_BIG(*)
FROM Production.TransactionHistory AS TH
WHERE
TH.TransactionID BETWEEN 100000 AND 168412
AND TH.TransactionDate BETWEEN '20070901' AND '20080313'
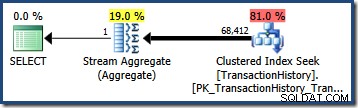
OPTION (QUERYTRACEON 4137); Con esta marca activa, la estimación de cardinalidad utiliza la selectividad mínima de los dos predicados, lo que da como resultado una estimación de 68.412,4 filas:
Esto resulta ser casi perfecto para nuestra consulta porque nuestros predicados de prueba están exactamente correlacionados (y las estimaciones derivadas de los histogramas base también son muy buenas).
Es razonablemente raro que los predicados estén perfectamente correlacionados de esta manera con datos reales, pero la marca de seguimiento puede ayudar en algunos casos. Tenga en cuenta que el comportamiento de selectividad mínima se aplicará a todos los conjuntivos (AND ) predicados en la consulta; no hay forma de especificar el comportamiento a un nivel más granular.
No hay una marca de seguimiento correspondiente para estimar la disyuntiva (OR ) predicados usando selectividad mínima.
Servidor SQL 2014
El cálculo de selectividad en SQL Server 2014 se comporta igual que en las versiones anteriores (y el indicador de seguimiento 4137 funciona como antes) si el nivel de compatibilidad de la base de datos se establece en un valor inferior a 120, o si el indicador de seguimiento 9481 está activo. Establecer el nivel de compatibilidad de la base de datos es el oficial forma de utilizar el estimador de cardinalidad anterior a 2014 en SQL Server 2014. El indicador de seguimiento 9481 es eficaz para hacer lo mismo que en el momento de escribir este artículo y también funciona con QUERYTRACEON , aunque no está documentado para hacerlo. No hay forma de saber cuál será el comportamiento RTM de esta bandera.
Si el nuevo estimador de cardinalidad está activo, SQL Server 2014 usa una fórmula predeterminada diferente para combinar predicados conjuntivos y disyuntivos. Aunque no está documentada, la fórmula de selectividad para las conjunciones se ha descubierto y documentado varias veces. El primero que recuerdo haber visto está en esta publicación de blog en portugués y la segunda parte de seguimiento se publicó un par de semanas después. Para resumir, el enfoque de 2014 para predicados conjuntivos es usar retroceso exponencial: dada una tabla con cardinalidad C y selectividades predicadas S1 , S2 , S3 … Sn , donde S1 es el mas selectivo y Sn lo mínimo:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …
La estimación se calcula multiplicando el predicado más selectivo por la cardinalidad de la tabla, multiplicando por la raíz cuadrada del siguiente predicado más selectivo y así sucesivamente con cada nueva selectividad ganando una raíz cuadrada adicional.
Recordando que la selectividad es un número entre 0 y 1, está claro que aplicar una raíz cuadrada acerca el número a 1. El efecto es tener en cuenta todos los predicados en la estimación final, pero reducir el impacto de los predicados menos selectivos. exponencialmente Podría decirse que esta idea tiene más lógica que la suposición de independencia , pero sigue siendo una fórmula fija:no cambia según el grado real de correlación de datos.
El estimador de cardinalidad de 2014 utiliza una fórmula de retroceso exponencial para ambos predicados conjuntivos y disyuntivos, aunque la fórmula utilizada en los predicados disyuntivos (OR ) el caso aún no ha sido documentado (oficialmente o de otra manera).
Indicadores de seguimiento de selectividad de SQL Server 2014
Trace flag 4137 (para usar selectividad mínima) no funciona en SQL Server 2014, si se utiliza el nuevo estimador de cardinalidad al compilar una consulta. En su lugar, hay una nueva marca de rastreo 9471 . Cuando esta bandera está activa, la selectividad mínima se usa para estimar múltiples conjuntivas y disyuntivas predicados. Este es un cambio con respecto al comportamiento 4137, que solo afectaba a los predicados conjuntivos.
Del mismo modo, trace la marca 9472 se puede especificar para asumir independencia para múltiples predicados, como lo hacían las versiones anteriores. Esta bandera es diferente de 9481 (para usar el estimador de cardinalidad anterior a 2014) porque bajo 9472 se seguirá usando el nuevo estimador de cardinalidad, solo se ve afectada la fórmula de selectividad para múltiples predicados.
Ni 9471 ni 9472 están documentados en el momento de escribir este artículo (aunque pueden estar en RTM).
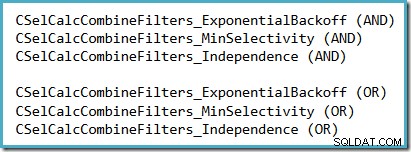
Una manera conveniente de ver qué suposición de selectividad se usa en SQL Server 2014 (con el nuevo estimador de cardinalidad activo) es examinar la salida de depuración del cálculo de selectividad que se produce cuando las marcas de seguimiento 2363 y 3604 están activos. La sección que debe buscar se relaciona con la calculadora de selectividad que combina filtros, donde verá uno de los siguientes, según la suposición que se utilice:
No existe una perspectiva realista de que 2363 sea documentado o respaldado.
Reflexiones finales
No hay nada mágico en el retroceso exponencial, la selectividad mínima o la independencia. Cada enfoque representa una suposición (enormemente) simplificadora que puede o no producir estimaciones aceptables para cualquier consulta o distribución de datos en particular.
En algunos aspectos, retroceso exponencial representa un compromiso entre los dos extremos de la independencia y selectividad mínima . Aun así, es importante no tener expectativas irrazonables de ello. Hasta que se encuentre una forma más precisa de estimar la selectividad para varios predicados (con características de rendimiento razonables), sigue siendo importante ser consciente de las limitaciones del modelo y estar atento a los errores de estimación (potenciales) correspondientes.
Las diversas marcas de seguimiento proporcionan cierto control sobre qué suposición se utiliza, pero la situación está lejos de ser perfecta. Por un lado, la granularidad más fina con la que se puede aplicar un indicador es una sola consulta:el comportamiento de estimación no se puede especificar en el nivel de predicado. Si tiene una consulta en la que algunos predicados están correlacionados y otros son independientes, es posible que las marcas de seguimiento no le ayuden mucho sin refactorizar la consulta de una forma u otra. Del mismo modo, una consulta problemática puede tener correlaciones predicadas que no están bien modeladas por ninguna de las opciones disponibles.
El uso ad-hoc de las marcas de rastreo requiere los mismos permisos que DBCC TRACEON – a saber, sysadmin . Probablemente esté bien para pruebas personales, pero para producción use una guía de plan usando QUERYTRACEON indirecta es una mejor opción. Con una guía del plan, no se requieren permisos adicionales para ejecutar la consulta (aunque, por supuesto, se requieren permisos elevados para crear la guía del plan).