De vez en cuando veo a alguien expresar un requisito para crear un número aleatorio para una clave. Por lo general, esto es para crear algún tipo de ID de cliente o ID de usuario sustituto que es un número único dentro de un rango, pero que no se emite de forma secuencial y, por lo tanto, es mucho menos adivinable que una IDENTITY. valor.
NEWID() resuelve el problema de las conjeturas, pero la penalización del rendimiento suele ser un factor decisivo, especialmente cuando se agrupan:claves mucho más anchas que los números enteros y divisiones de página debido a valores no secuenciales. NEWSEQUENTIALID() resuelve el problema de división de páginas, pero sigue siendo una clave muy amplia y vuelve a introducir el problema de que puede adivinar el siguiente valor (o valores emitidos recientemente) con cierto nivel de precisión.
Como resultado, quieren una técnica para generar un y aleatorio entero único. Generar un número aleatorio por sí solo no es difícil, usando métodos como RAND() o CHECKSUM(NEWID()) . El problema viene cuando hay que detectar colisiones. Echemos un vistazo rápido a un enfoque típico, asumiendo que queremos valores de CustomerID entre 1 y 1,000,000:
DECLARE @rc INT = 0,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
-- or ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1;
-- or CONVERT(INT, RAND() * 1000000) + 1;
WHILE @rc = 0
BEGIN
IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID = @CustomerID)
BEGIN
INSERT dbo.Customers(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT @CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@rc = 0;
END
END A medida que la tabla se hace más grande, no solo se vuelve más costosa la verificación de duplicados, sino que también aumentan las probabilidades de generar un duplicado. Así que este enfoque puede parecer que funciona bien cuando la mesa es pequeña, pero sospecho que debe doler más y más con el tiempo.
Un enfoque diferente
Soy una gran fan de las mesas auxiliares; He estado escribiendo públicamente sobre tablas de calendario y tablas de números durante una década y usándolas durante mucho más tiempo. Y este es un caso en el que creo que una tabla rellenada previamente podría ser muy útil. ¿Por qué confiar en la generación de números aleatorios en tiempo de ejecución y tratar con posibles duplicados, cuando puede completar todos esos valores por adelantado y saber, con 100% de certeza, si protege sus tablas de DML no autorizado, que el próximo valor que seleccione nunca ha sido usado antes?
CREATE TABLE dbo.RandomNumbers1
(
RowID INT,
Value INT, --UNIQUE,
PRIMARY KEY (RowID, Value)
);
;WITH x AS
(
SELECT TOP (1000000) s1.[object_id]
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
ORDER BY s1.[object_id]
)
INSERT dbo.RandomNumbers(RowID, Value)
SELECT
r = ROW_NUMBER() OVER (ORDER BY [object_id]),
n = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM x
ORDER BY r; Esta población tardó 9 segundos en crearse (en una máquina virtual en una computadora portátil) y ocupó alrededor de 17 MB en el disco. Los datos en la tabla se ven así:
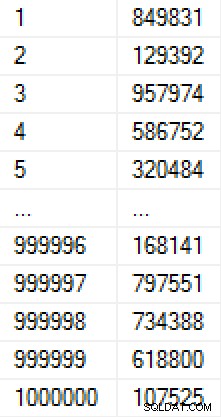
(Si nos preocupaba cómo se completaban los números, podríamos agregar una restricción única en la columna Valor, lo que haría que la tabla tuviera 30 MB. Si hubiéramos aplicado la compresión de página, habría sido de 11 MB o 25 MB, respectivamente). )
Creé otra copia de la tabla y la rellené con los mismos valores, para poder probar dos métodos diferentes para obtener el siguiente valor:
CREATE TABLE dbo.RandomNumbers2 ( RowID INT, Value INT, -- UNIQUE PRIMARY KEY (RowID, Value) ); INSERT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Ahora, cada vez que queramos un nuevo número aleatorio, podemos sacar uno de la pila de números existentes y eliminarlo. Esto evita que tengamos que preocuparnos por los duplicados y nos permite extraer números, utilizando un índice agrupado, que en realidad ya están en orden aleatorio. (Estrictamente hablando, no tenemos que eliminar los números tal como los usamos; podríamos agregar una columna para indicar si se ha utilizado un valor; esto facilitaría restablecer y reutilizar ese valor en el caso de que un Cliente se elimine más tarde o algo salga mal fuera de esta transacción, pero antes de que se creen por completo).
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding;
Usé una variable de tabla para contener la salida intermedia, porque existen varias limitaciones con DML componible que pueden hacer que sea imposible insertar en la tabla Clientes directamente desde DELETE (por ejemplo, la presencia de claves foráneas). Aún así, reconociendo que no siempre será posible, también quería probar este método:
DELETE TOP (1) dbo.RandomNumbers2 OUTPUT deleted.Value, ...other params... INTO dbo.Customers(CustomerID, ...other columns...);
Tenga en cuenta que ninguna de estas soluciones realmente garantiza un orden aleatorio, especialmente si la tabla de números aleatorios tiene otros índices (como un índice único en la columna Valor). No hay forma de definir un pedido para un DELETE usando TOP; de la documentación:
Entonces, si desea garantizar un orden aleatorio, podría hacer algo como esto:
DECLARE @holding TABLE(CustomerID INT);
;WITH x AS
(
SELECT TOP (1) Value
FROM dbo.RandomNumbers2
ORDER BY RowID
)
DELETE x OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers(CustomerID, ...other columns...)
SELECT CustomerID, ...other params...
FROM @holding; Otra consideración aquí es que, para estas pruebas, las tablas Clientes tienen una clave principal agrupada en la columna CustomerID; esto ciertamente conducirá a divisiones de página a medida que inserte valores aleatorios. En el mundo real, si tuviera este requisito, probablemente terminaría agrupando en una columna diferente.
Tenga en cuenta que también he omitido las transacciones y el manejo de errores aquí, pero estos también deben tenerse en cuenta para el código de producción.
Pruebas de rendimiento
Para hacer algunas comparaciones de rendimiento realistas, creé cinco procedimientos almacenados, que representan los siguientes escenarios (velocidad de prueba, distribución y frecuencia de colisión de los diferentes métodos aleatorios, así como la velocidad de uso de una tabla predefinida de números aleatorios):
- Generación de tiempo de ejecución usando
CHECKSUM(NEWID()) - Generación de tiempo de ejecución usando
CRYPT_GEN_RANDOM() - Generación de tiempo de ejecución usando
RAND() - Tabla de números predefinidos con variable de tabla
- Tabla de números predefinidos con inserción directa
Usan una tabla de registro para rastrear la duración y el número de colisiones:
CREATE TABLE dbo.CustomerLog ( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, collisions INT, duration INT -- microseconds );
El código para los procedimientos sigue (haga clic para mostrar/ocultar):
/* Runtime using CHECKSUM(NEWID()) */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Checksum
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CHECKSUM(NEWID())) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;
END
GO
/* runtime using CRYPT_GEN_RANDOM() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_CryptGen
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;
END
GO
/* runtime using RAND() */
CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]
AS
BEGIN
SET NOCOUNT ON;
DECLARE
@start DATETIME2(7) = SYSDATETIME(),
@duration INT,
@CustomerID INT = CONVERT(INT, RAND() * 1000000) + 1,
@collisions INT = 0,
@rc INT = 0;
WHILE @rc = 0
BEGIN
IF NOT EXISTS
(
SELECT 1 FROM dbo.Customers_Runtime_Rand
WHERE CustomerID = @CustomerID
)
BEGIN
INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID;
SET @rc = 1;
END
ELSE
BEGIN
SELECT
@CustomerID = CONVERT(INT, RAND() * 1000000) + 1,
@collisions += 1,
@rc = 0;
END
END
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;
END
GO
/* pre-defined using a table variable */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DECLARE @holding TABLE(CustomerID INT);
DELETE TOP (1) dbo.RandomNumbers1
OUTPUT deleted.Value INTO @holding;
INSERT dbo.Customers_Predefined_TableVariable(CustomerID)
SELECT CustomerID FROM @holding;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;
END
GO
/* pre-defined using a direct insert */
CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]
AS
BEGIN
SET NOCOUNT ON;
DECLARE @start DATETIME2(7) = SYSDATETIME(), @duration INT;
DELETE TOP (1) dbo.RandomNumbers2
OUTPUT deleted.Value INTO dbo.Customers_Predefined_Direct;
SELECT @duration = DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME()));
INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;
END
GO Y para probar esto, ejecutaría cada procedimiento almacenado 1,000,000 veces:
EXEC dbo.AddCustomer_Runtime_Checksum; EXEC dbo.AddCustomer_Runtime_CryptGen; EXEC dbo.AddCustomer_Runtime_Rand; EXEC dbo.AddCustomer_Predefined_TableVariable; EXEC dbo.AddCustomer_Predefined_Direct; GO 1000000
No es de extrañar que los métodos que usaban la tabla predefinida de números aleatorios tardaran un poco más *al comienzo de la prueba*, ya que tenían que realizar E/S tanto de lectura como de escritura cada vez. Teniendo en cuenta que estos números están en microsegundos , estas son las duraciones promedio de cada procedimiento, en diferentes intervalos a lo largo del camino (promedio de las primeras 10 000 ejecuciones, las 10 000 ejecuciones intermedias, las últimas 10 000 ejecuciones y las últimas 1000 ejecuciones):
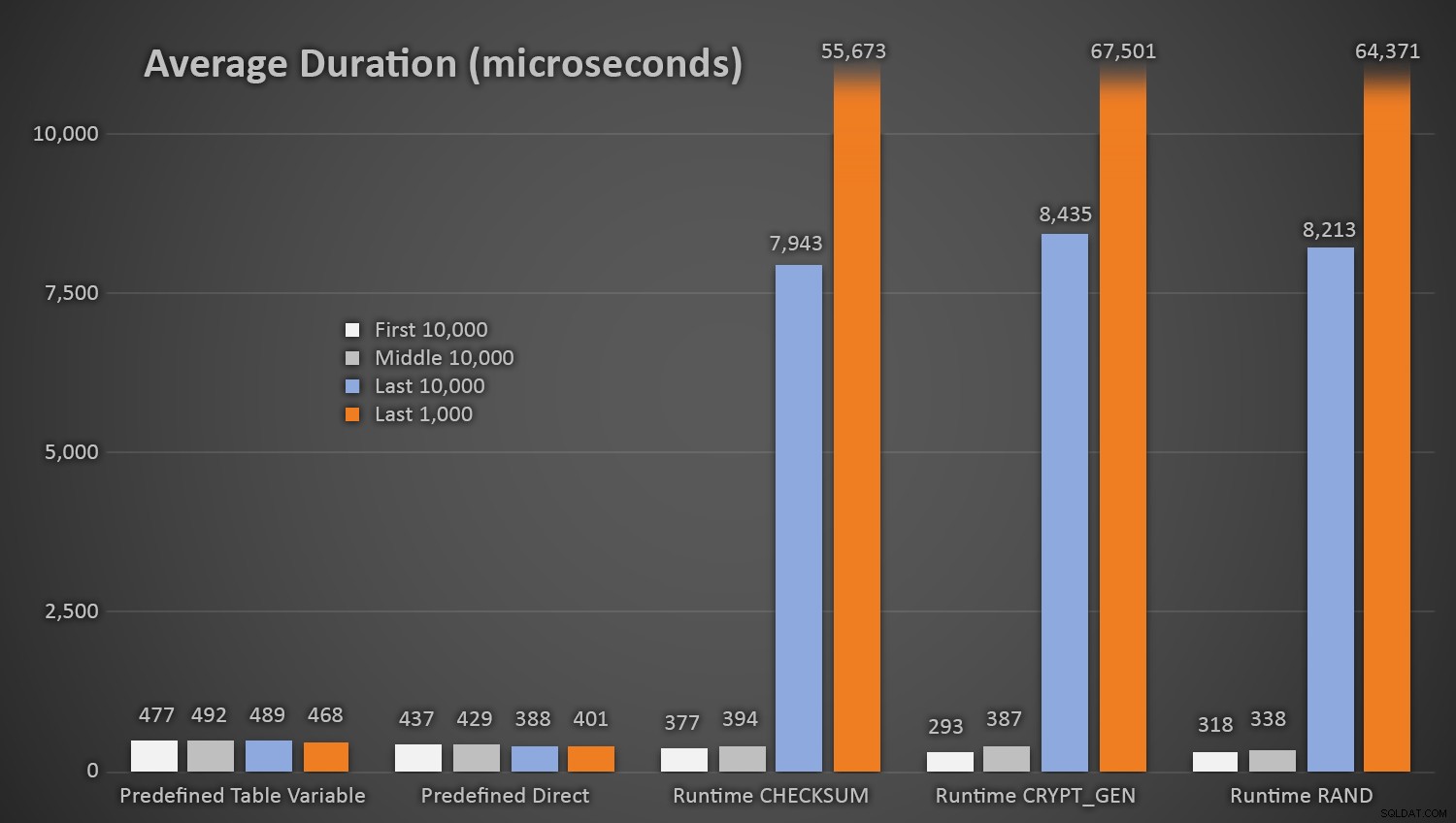
Duración promedio (en microsegundos) de generación aleatoria utilizando diferentes enfoques
Esto funciona bien para todos los métodos cuando hay pocas filas en la tabla Customers, pero a medida que la tabla se hace más y más grande, el costo de comparar el nuevo número aleatorio con los datos existentes usando los métodos de tiempo de ejecución aumenta sustancialmente, tanto por el aumento de I /O y también porque aumenta el número de colisiones (obligándote a intentarlo una y otra vez). Compare la duración promedio cuando se encuentre en los siguientes rangos de recuentos de colisiones (y recuerde que este patrón solo afecta los métodos de tiempo de ejecución):
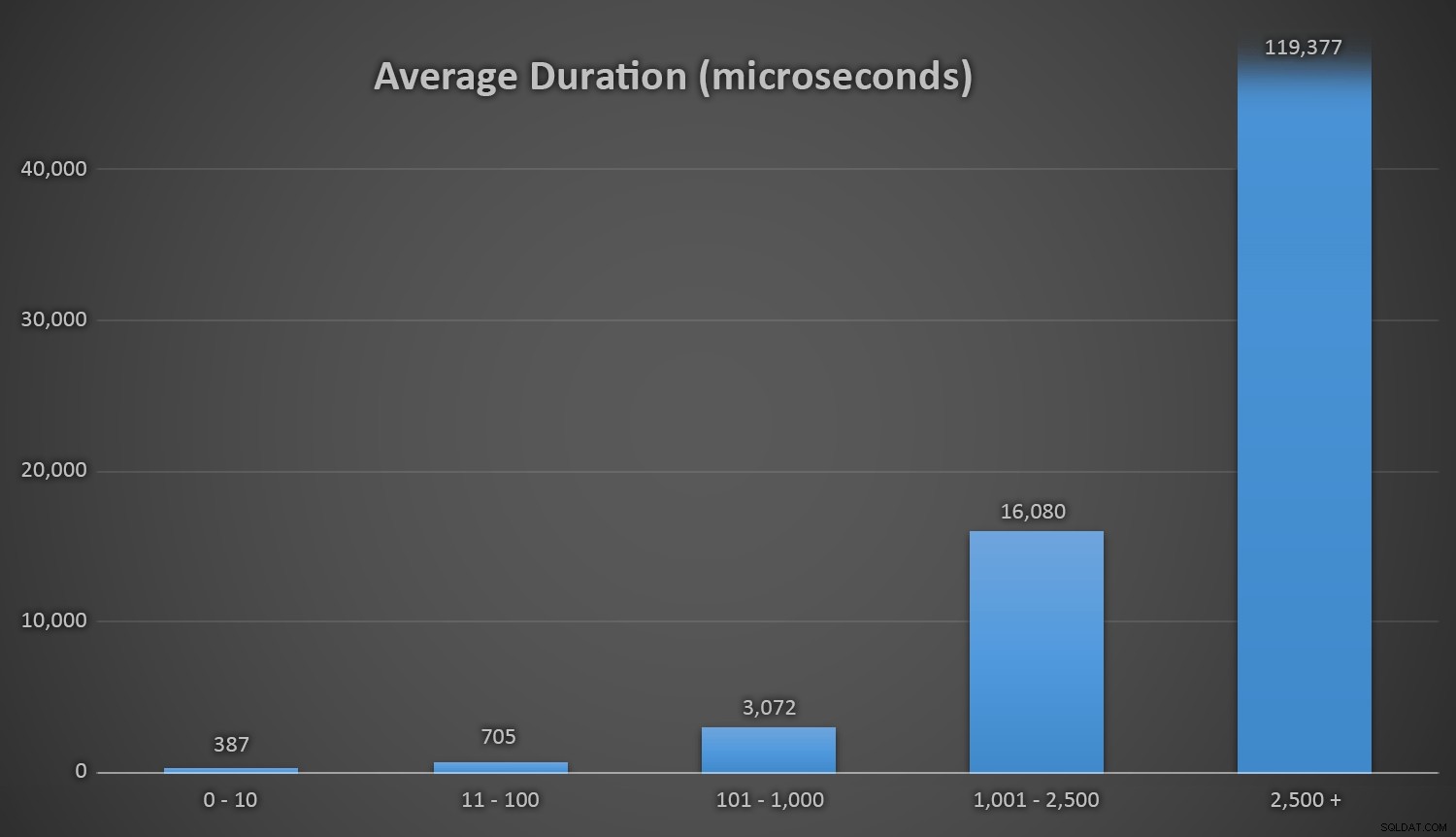
Duración promedio (en microsegundos) durante diferentes rangos de colisiones
Me gustaría que hubiera una forma sencilla de graficar la duración frente a los recuentos de colisiones. Los dejo con este dato:en las últimas tres inserciones, los siguientes métodos de tiempo de ejecución tuvieron que realizar tantos intentos antes de que finalmente tropezaran con la última identificación única que estaban buscando, y este es el tiempo que tomó:
| Número de colisiones | Duración (microsegundos) | ||
|---|---|---|---|
| SUMA DE COMPROBACIÓN(NEWID()) | De la tercera a la última fila | 63.545 | 639.358 |
| Segunda a la última fila | 164.807 | 1,605,695 | |
| Última fila | 30.630 | 296,207 | |
| CRYPT_GEN_RANDOM() | De la tercera a la última fila | 219.766 | 2,229,166 |
| Segunda a la última fila | 255.463 | 2,681,468 | |
| Última fila | 136,342 | 1,434,725 | |
| ALEATORIO() | De la tercera a la última fila | 129.764 | 1,215,994 |
| Segunda a la última fila | 220.195 | 2,088,992 | |
| Última fila | 440.765 | 4.161.925 | |
Duración excesiva y colisiones cerca del final de la línea
Es interesante notar que la última fila no siempre es la que produce la mayor cantidad de colisiones, por lo que esto puede comenzar a ser un problema real mucho antes de que haya utilizado más de 999,000 valores.
Otra consideración
Es posible que desee considerar configurar algún tipo de alerta o notificación cuando la tabla RandomNumbers comience a estar por debajo de una cierta cantidad de filas (momento en el que puede volver a llenar la tabla con un nuevo conjunto de 1,000,001 a 2,000,000, por ejemplo). Tendría que hacer algo similar si estuviera generando números aleatorios sobre la marcha:si mantiene eso dentro de un rango de 1 a 1,000,000, entonces tendría que cambiar el código para generar números de un rango diferente una vez que He usado todos esos valores.
Si está utilizando el método de número aleatorio en tiempo de ejecución, puede evitar esta situación cambiando constantemente el tamaño del grupo del que extrae un número aleatorio (que también debería estabilizarse y reducir drásticamente la cantidad de colisiones). Por ejemplo, en lugar de:
DECLARE @CustomerID INT = ABS(CHECKSUM(NEWID())) % 1000000 + 1;
Puede basar el grupo en la cantidad de filas que ya están en la tabla:
DECLARE @total INT = 1000000 + ISNULL(
(SELECT SUM(row_count) FROM sys.dm_db_partition_stats
WHERE [object_id] = OBJECT_ID('dbo.Customers') AND index_id = 1),0);
Ahora su única preocupación real es cuando se acerca al límite superior de INT …
Nota:Recientemente también escribí un consejo sobre esto en MSSQLTips.com.



