La necesidad más común de eliminar el tiempo de un valor de fecha y hora es obtener todas las filas que representan pedidos (o visitas o accidentes) que ocurrieron en un día determinado. Sin embargo, no todas las técnicas que se utilizan para hacerlo son eficientes o incluso seguras.
Versión TL;DR
Si desea una consulta de rango seguro que funcione bien, use un rango abierto o, para consultas de un solo día en SQL Server 2008 y superior, use CONVERT(DATE) :
DECLARE @today DATETIME; -- only on <= 2005: SET @today = DATEADD(DAY, DATEDIFF(DAY, '20000101', CURRENT_TIMESTAMP), '20000101'); -- or on 2008 and above: SET @today = CONVERT(DATE, CURRENT_TIMESTAMP); -- and then use an open-ended range in the query: ... WHERE OrderDate >= @today AND OrderDate < DATEADD(DAY, 1, @today); -- you can also do this (again, in SQL Server 2008 and above): ... WHERE CONVERT(DATE, OrderDate) = @today;
Algunas advertencias:
- Ten cuidado con el
DATEDIFFenfoque, ya que pueden ocurrir algunas anomalías de estimación de cardinalidad (consulte esta publicación de blog y la pregunta de desbordamiento de pila que lo impulsó para obtener más información). - Si bien la última todavía usará potencialmente una búsqueda de índice (a diferencia de cualquier otra expresión no sargable que haya encontrado), debe tener cuidado al convertir la columna a una fecha antes de comparar. Este enfoque también puede producir estimaciones de cardinalidad fundamentalmente erróneas. Consulte esta respuesta de Martin Smith para obtener más detalles.
En cualquier caso, siga leyendo para comprender por qué estos son los dos únicos enfoques que recomiendo.
No todos los enfoques son seguros
Como ejemplo inseguro, veo que este se usa mucho:
WHERE OrderDate BETWEEN DATEDIFF(DAY, 0, GETDATE()) AND DATEADD(MILLISECOND, -3, DATEDIFF(DAY, 0, GETDATE()) + 1);
Hay algunos problemas con este enfoque, pero el más notable es el cálculo del "final" de hoy, si el tipo de datos subyacente es SMALLDATETIME , ese rango final se va a redondear; si es DATETIME2 , teóricamente podría perder datos al final del día. Si elige minutos o nanosegundos o cualquier otra brecha para acomodar el tipo de datos actual, su consulta comenzará a tener un comportamiento extraño si el tipo de datos cambia más tarde (y seamos honestos, si alguien cambia el tipo de esa columna para que sea más o menos granular, no están corriendo revisando cada consulta que accede a él). Tener que codificar de esta manera según el tipo de datos de fecha/hora en la columna subyacente está fragmentado y es propenso a errores. Es mucho mejor usar intervalos de fechas abiertos para esto:
Hablo mucho más sobre esto en un par de entradas de blog antiguas:
- ¿Qué tienen en común BETWEEN y el diablo?
- Malos hábitos para eliminar:mal manejo de consultas de fechas/rango
Pero quería comparar el rendimiento de algunos de los enfoques más comunes que veo por ahí. Siempre he usado rangos abiertos, y desde SQL Server 2008 hemos podido usar CONVERT(DATE) y seguir utilizando un índice en esa columna, que es bastante potente.
SELECT CONVERT(CHAR(8), CURRENT_TIMESTAMP, 112); SELECT CONVERT(CHAR(10), CURRENT_TIMESTAMP, 120); SELECT CONVERT(DATE, CURRENT_TIMESTAMP); SELECT DATEADD(DAY, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP), '19000101'); SELECT CONVERT(DATETIME, DATEDIFF(DAY, '19000101', CURRENT_TIMESTAMP)); SELECT CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, CURRENT_TIMESTAMP))); SELECT CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, CURRENT_TIMESTAMP)));
Una prueba de rendimiento simple
Para realizar una prueba de rendimiento inicial muy simple, hice lo siguiente para cada una de las declaraciones anteriores, configurando una variable en la salida del cálculo 100 000 veces:
SELECT SYSDATETIME(); GO DECLARE @d DATETIME = [conversion method]; GO 100000 SELECT SYSDATETIME(); GO
Hice esto tres veces para cada método, y todos se ejecutaron en el rango de 34 a 38 segundos. Hablando estrictamente, existen diferencias muy insignificantes en estos métodos al realizar las operaciones en la memoria:
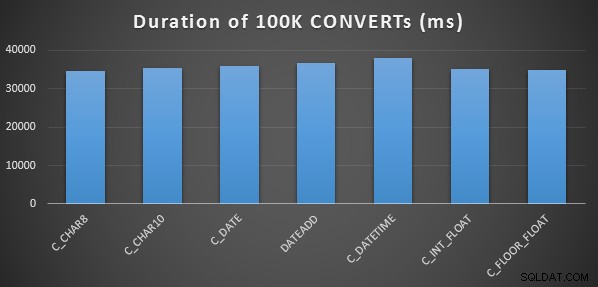
Una prueba de rendimiento más elaborada
También quería comparar estos métodos con diferentes tipos de datos (DATETIME , SMALLDATETIME y DATETIME2 ), contra un índice agrupado y un montón, y con y sin compresión de datos. Así que primero creé una base de datos simple. A través de la experimentación, determiné que el tamaño óptimo para manejar 120 millones de filas y toda la actividad de registro que podría incurrir (y para evitar que los eventos de crecimiento automático interfirieran con las pruebas) era un archivo de datos de 20 GB y un registro de 3 GB:
CREATE DATABASE [Datetime_Testing] ON PRIMARY ( NAME = N'Datetime_Testing_Data', FILENAME = N'D:\DATA\Datetime_Testing.mdf', SIZE = 20480000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 102400KB ) LOG ON ( NAME = N'Datetime_Testing_Log', FILENAME = N'E:\LOGS\Datetime_Testing_log.ldf', SIZE = 3000000KB , MAXSIZE = UNLIMITED, FILEGROWTH = 20480KB );
A continuación, creé 12 tablas:
-- clustered index with no compression: CREATE TABLE dbo.smalldatetime_nocompression_clustered(dt SMALLDATETIME); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_nocompression_clustered(dt); -- heap with no compression: CREATE TABLE dbo.smalldatetime_nocompression_heap(dt SMALLDATETIME); -- clustered index with page compression: CREATE TABLE dbo.smalldatetime_compression_clustered(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE); CREATE CLUSTERED INDEX x ON dbo.smalldatetime_compression_clustered(dt) WITH (DATA_COMPRESSION = PAGE); -- heap with page compression: CREATE TABLE dbo.smalldatetime_compression_heap(dt SMALLDATETIME) WITH (DATA_COMPRESSION = PAGE);
[Luego repita nuevamente para DATETIME y DATETIME2.]
A continuación, inserté 10 000 000 filas en cada tabla. Hice esto creando una vista que generaría las mismas 10 000 000 fechas cada vez:
CREATE VIEW dbo.TenMillionDates AS SELECT TOP (10000000) d = DATEADD(MINUTE, ROW_NUMBER() OVER (ORDER BY s1.[object_id]), '19700101') FROM sys.all_columns AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id];
Esto me permitió llenar las tablas de esta manera:
INSERT /* dt_comp_clus */ dbo.datetime_compression_clustered(dt) SELECT CONVERT(DATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* dt2_comp_clus */ dbo.datetime2_compression_clustered(dt) SELECT CONVERT(DATETIME2, d) FROM dbo.TenMillionDates; CHECKPOINT; INSERT /* sdt_comp_clus */ dbo.smalldatetime_compression_clustered(dt) SELECT CONVERT(SMALLDATETIME, d) FROM dbo.TenMillionDates; CHECKPOINT;
[Luego repita nuevamente para los montones y el índice agrupado no comprimido. Pongo un CHECKPOINT entre cada inserción para asegurar la reutilización del registro (el modelo de recuperación es simple).]
INSERTAR tiempos y espacio utilizados
Estos son los tiempos para cada inserción (según lo capturado con Plan Explorer):
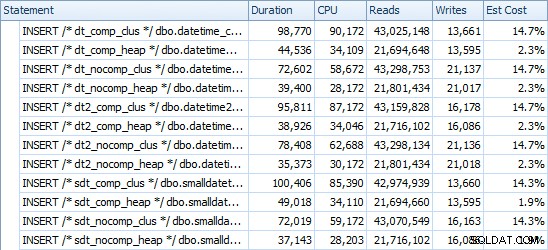
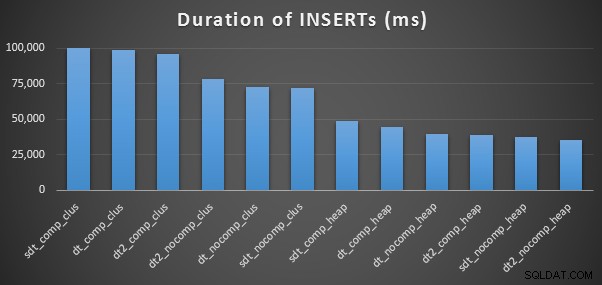
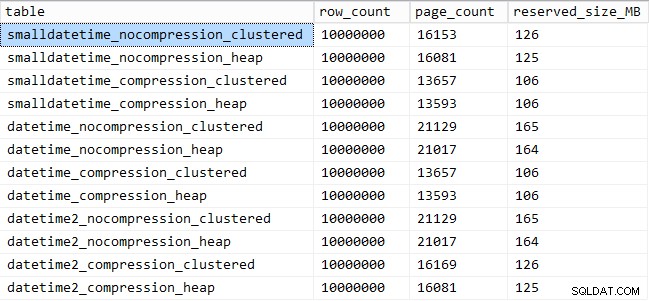
Y aquí está la cantidad de espacio ocupado por cada tabla:
SELECT [table] = OBJECT_NAME([object_id]), row_count, page_count = reserved_page_count, reserved_size_MB = reserved_page_count * 8/1024 FROM sys.dm_db_partition_stats WHERE OBJECT_NAME([object_id]) LIKE '%datetime%';
Rendimiento del patrón de consulta
A continuación, me dispuse a probar el rendimiento de dos patrones de consulta diferentes:
- Contar las filas para un día específico, usando los siete enfoques anteriores, así como el intervalo de fechas abierto.
- Convertir las 10 000 000 filas usando los siete enfoques anteriores, así como solo devolver los datos sin procesar (ya que el formato en el lado del cliente puede ser mejor)
[Con la excepción del FLOAT métodos y el DATETIME2 columna, ya que esta conversión no es legal.]
Para la primera pregunta, las consultas se ven así (repetidas para cada tipo de tabla):
SELECT /* C_CHAR10 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(10), dt, 120) = '19860301';
SELECT /* C_CHAR8 - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(CHAR(8), dt, 112) = '19860301';
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt))) = '19860301';
SELECT /* C_DATETIME - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt)) = '19860301';
SELECT /* C_DATE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATE, dt) = '19860301';
SELECT /* C_INT_FLOAT - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt))) = '19860301';
SELECT /* DATEADD - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101') = '19860301';
SELECT /* RANGE - dt_comp_clus */ COUNT(*)
FROM dbo.datetime_compression_clustered
WHERE dt >= '19860301' AND dt < '19860302'; Los resultados contra un índice agrupado se ven así (haga clic para ampliar):
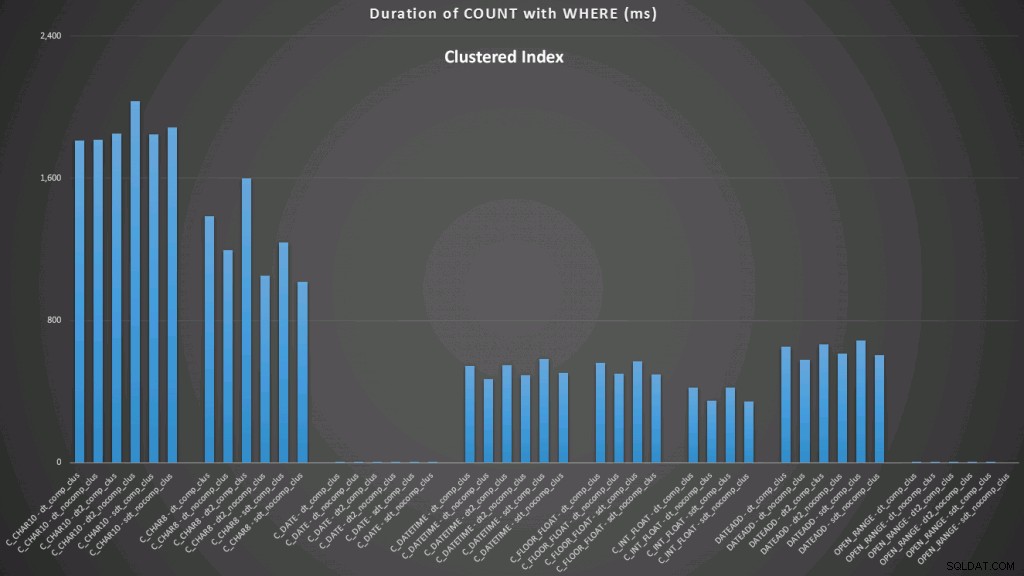
Aquí vemos que la conversión a la fecha y el rango abierto usando un índice son los de mejor desempeño. Sin embargo, contra un montón, la conversión a la fecha en realidad lleva algo de tiempo, lo que hace que el rango abierto sea la opción óptima (haga clic para ampliar):
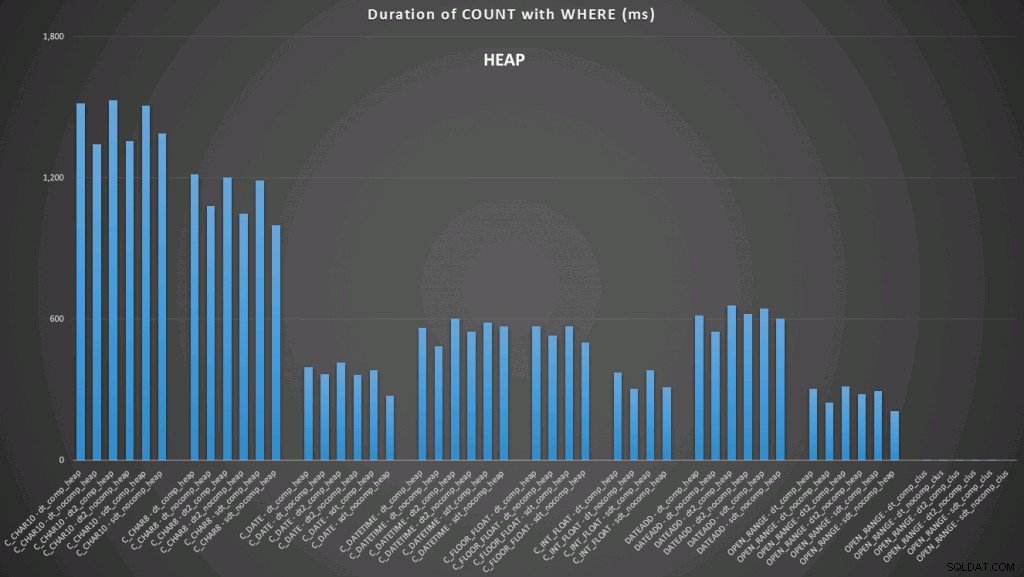
Y aquí está el segundo conjunto de consultas (nuevamente, repitiéndose para cada tipo de tabla):
SELECT /* C_CHAR10 - dt_comp_clus */ dt = CONVERT(CHAR(10), dt, 120)
FROM dbo.datetime_compression_clustered;
SELECT /* C_CHAR8 - dt_comp_clus */ dt = CONVERT(CHAR(8), dt, 112)
FROM dbo.datetime_compression_clustered;
SELECT /* C_FLOOR_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, FLOOR(CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATETIME - dt_comp_clus */ dt = CONVERT(DATETIME, DATEDIFF(DAY, '19000101', dt))
FROM dbo.datetime_compression_clustered;
SELECT /* C_DATE - dt_comp_clus */ dt = CONVERT(DATE, dt)
FROM dbo.datetime_compression_clustered;
SELECT /* C_INT_FLOAT - dt_comp_clus */ dt = CONVERT(DATETIME, CONVERT(INT, CONVERT(FLOAT, dt)))
FROM dbo.datetime_compression_clustered;
SELECT /* DATEADD - dt_comp_clus */ dt = DATEADD(DAY, DATEDIFF(DAY, '19000101', dt), '19000101')
FROM dbo.datetime_compression_clustered;
SELECT /* RAW - dt_comp_clus */ dt
FROM dbo.datetime_compression_clustered; Centrándonos en los resultados de las tablas con un índice agrupado, está claro que la conversión a la fecha tuvo un desempeño muy cercano a la simple selección de datos sin procesar (haga clic para ampliar):
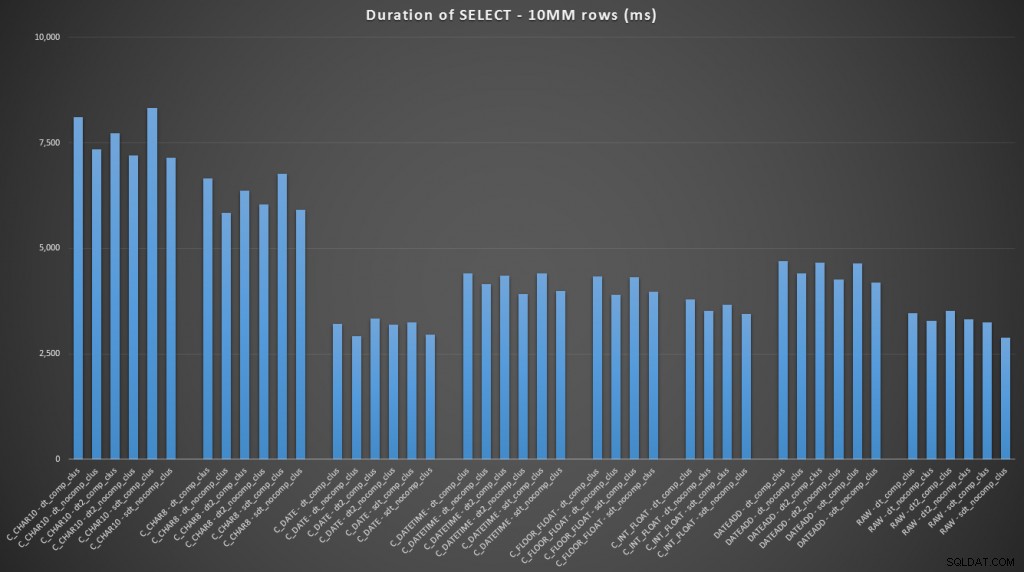
(Para este conjunto de consultas, el montón mostró resultados muy similares, prácticamente indistinguibles).
Conclusión
En caso de que quisiera pasar al remate final, estos resultados muestran que las conversiones en la memoria no son importantes, pero si está convirtiendo datos al salir de una tabla (o como parte de un predicado de búsqueda), el método que elija puede tener un impacto dramático en el rendimiento. Convirtiendo a una DATE (para un solo día) o usar un rango de fechas abierto en cualquier caso producirá el mejor rendimiento, mientras que el método más popular que existe, la conversión a una cadena, es absolutamente pésimo.
También vemos que la compresión puede tener un efecto decente en el espacio de almacenamiento, con un impacto muy pequeño en el rendimiento de las consultas. El efecto sobre el rendimiento de la inserción parece depender tanto de si la tabla tiene un índice agrupado como si no, en lugar de si la compresión está habilitada o no. Sin embargo, con un índice agrupado en su lugar, hubo un aumento notable en la duración que se tardó en insertar 10 millones de filas. Algo a tener en cuenta y equilibrar con el ahorro de espacio en disco.
Claramente, podría haber muchas más pruebas involucradas, con cargas de trabajo más sustanciales y variadas, que puedo explorar más a fondo en una publicación futura.