Durante mucho tiempo he sido partidario de elegir el tipo de datos correcto. He hablado sobre algunos ejemplos en una publicación anterior del blog "Bad Habits", pero este fin de semana en SQL Saturday #162 (Cambridge, Reino Unido), el tema del uso de DATETIME apareció por defecto. En una conversación después de mi presentación T-SQL:Malos hábitos y mejores prácticas, un usuario dijo que solo usaba DATETIME incluso si solo necesitan granularidad al minuto o al día, de esta manera las columnas de fecha/hora en toda su empresa son siempre del mismo tipo de datos. Sugerí que esto podría ser un desperdicio y que la consistencia podría no valer la pena, pero hoy decidí probar mi teoría.
Versión TL;DR
Mis pruebas a continuación revelan que ciertamente hay escenarios en los que es posible que desee considerar usar un tipo de datos más delgado en lugar de apegarse a DATETIME En todas partes. Pero es importante ver dónde apuntaron mis pruebas para esto, y también es importante probar estos escenarios contra su esquema, en su entorno, con hardware y datos que sean lo más fieles posible a la producción. Sus resultados pueden variar, y es casi seguro que variarán.
Las tablas de destino
Consideremos el caso en el que la granularidad solo es importante para el día (no nos importan las horas, los minutos y los segundos). Para esto podríamos elegir DATETIME (como lo propuso el usuario), o SMALLDATETIME , o DATE en SQL Server 2008+. También hay dos tipos diferentes de datos que quería considerar:
- Datos que se insertarían aproximadamente de forma secuencial en tiempo real (por ejemplo, eventos que están sucediendo en este momento);
- Datos que se insertarían aleatoriamente (por ejemplo, fechas de nacimiento de nuevos miembros).
Empecé con 2 tablas como las siguientes, luego creé 4 más (2 para SMALLDATETIME, 2 para DATE):
CREATE TABLE dbo.BirthDatesRandom_Datetime ( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL ); CREATE TABLE dbo.EventsSequential_Datetime ( ID INT IDENTITY(1,1) PRIMARY KEY, dt DATETIME NOT NULL ); CREATE INDEX d ON dbo.BirthDatesRandom_Datetime(dt); CREATE INDEX d ON dbo.EventsSequential_Datetime(dt); -- Then repeat for DATE and SMALLDATETIME.
Y mi objetivo era probar el rendimiento de la inserción por lotes de esas dos maneras diferentes, así como el impacto en el tamaño y la fragmentación del almacenamiento general y, finalmente, el rendimiento de las consultas de rango.
Datos de muestra
Para generar algunos datos de muestra, utilicé una de mis prácticas técnicas para generar algo significativo a partir de algo que no lo es:las vistas del catálogo. En mi sistema, esto devolvió 971 valores distintos de fecha/hora (1 000 000 de filas en total) en aproximadamente 12 segundos:
;WITH y AS
(
SELECT TOP (1000000) d = DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20120101'))
FROM
(
SELECT s1.[object_id] % 1000
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS x(x) ORDER BY NEWID()
)
SELECT DISTINCT d FROM y; Puse estos millones de filas en una tabla para poder simular inserciones secuenciales/aleatorias usando diferentes métodos de acceso para exactamente los mismos datos de tres ventanas de sesión diferentes:
CREATE TABLE dbo.Staging
(
ID INT IDENTITY(1,1) PRIMARY KEY,
source_date DATETIME NOT NULL
);
;WITH Staging_Data AS
(
SELECT TOP (1000000) dt = DATEADD(SECOND, x, DATEADD(DAY, DATEDIFF(DAY, x, 0), '20110101'))
FROM
(
SELECT s1.[object_id] % 1000
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
) AS sd(x) ORDER BY NEWID()
)
INSERT dbo.Staging(source_date)
SELECT dt
FROM y
ORDER BY dt; Este proceso tardó un poco más en completarse (20 segundos). Luego creé una segunda tabla para almacenar los mismos datos pero distribuidos aleatoriamente (para poder repetir la misma distribución en todas las inserciones).
CREATE TABLE dbo.Staging_Random ( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATETIME NOT NULL ); INSERT dbo.Staging_Random(source_date) SELECT source_date FROM dbo.Staging ORDER BY NEWID();
Consultas para completar las tablas
Luego, escribí un conjunto de consultas para llenar las otras tablas con estos datos, usando tres ventanas de consulta para simular al menos un poco de simultaneidad:
WAITFOR TIME '13:53';
GO
DECLARE @d DATETIME2 = SYSDATETIME();
INSERT dbo.{table_name}(dt) -- depending on method / data type
SELECT source_date
FROM dbo.Staging[_Random] -- depending on destination
WHERE ID % 3 = <0,1,2> -- depending on query window
ORDER BY ID;
SELECT DATEDIFF(MILLISECOND, @d, SYSDATETIME()); Como en mi última publicación, expandí previamente la base de datos para evitar que cualquier tipo de evento de crecimiento automático de archivos de datos interfiera con los resultados. Me doy cuenta de que no es completamente realista realizar inserciones de un millón de filas en una sola pasada, ya que no puedo evitar que la actividad de registro de una transacción tan grande interfiera, pero debería hacerlo de manera consistente en cada método. Dado que el hardware con el que estoy probando es completamente diferente del hardware que está usando, los resultados absolutos no deberían ser una conclusión clave, solo la comparación relativa.
(En una prueba futura, también probaré esto con lotes reales provenientes de archivos de registro con datos relativamente mixtos, y usando fragmentos de la tabla de origen en bucles; creo que también serían experimentos interesantes. Y, por supuesto, agregar compresión en la mezcla).
Los resultados:
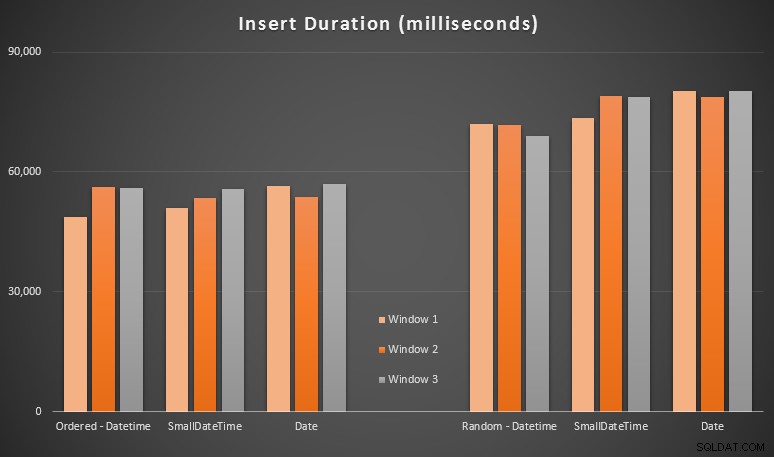
Estos resultados no fueron tan sorprendentes para mí:la inserción en orden aleatorio condujo a tiempos de ejecución más largos que la inserción secuencial, algo que todos podemos llevar a nuestras raíces de comprender cómo funcionan los índices en SQL Server y cómo pueden ocurrir más divisiones de página "malas" en este escenario (no supervisé específicamente las divisiones de página en este ejercicio, pero es algo que consideraré en futuras pruebas).
Me di cuenta de que, en el lado aleatorio, las conversiones implícitas en los datos entrantes podrían haber tenido un impacto en los tiempos, ya que parecían un poco más altos que el DATETIME -> DATETIME nativo. inserciones Así que decidí construir dos nuevas tablas que contengan datos de origen:una usando DATE y otro usando SMALLDATETIME . Esto simularía, hasta cierto punto, convertir su tipo de datos correctamente antes de pasarlo a la declaración de inserción, de modo que no se requiera una conversión implícita durante la inserción. Estas son las nuevas tablas y cómo se completaron:
CREATE TABLE dbo.Staging_Random_SmallDatetime ( ID INT IDENTITY(1,1) PRIMARY KEY, source_date SMALLDATETIME NOT NULL ); CREATE TABLE dbo.Staging_Random_Date ( ID INT IDENTITY(1,1) PRIMARY KEY, source_date DATE NOT NULL ); INSERT dbo.Staging_Random_SmallDatetime(source_date) SELECT CONVERT(SMALLDATETIME, source_date) FROM dbo.Staging_Random ORDER BY ID; INSERT dbo.Staging_Random_Date(source_date) SELECT CONVERT(DATE, source_date) FROM dbo.Staging_Random ORDER BY ID;
Esto no tuvo el efecto que esperaba:los tiempos fueron similares en todos los casos. Así que fue una búsqueda inútil.
Espacio utilizado y fragmentación
Ejecuté la siguiente consulta para determinar cuántas páginas se reservaron para cada tabla:
SELECT name = 'dbo.' + OBJECT_NAME([object_id]), pages = SUM(reserved_page_count) FROM sys.dm_db_partition_stats GROUP BY OBJECT_NAME([object_id]) ORDER BY pages;
Los resultados:
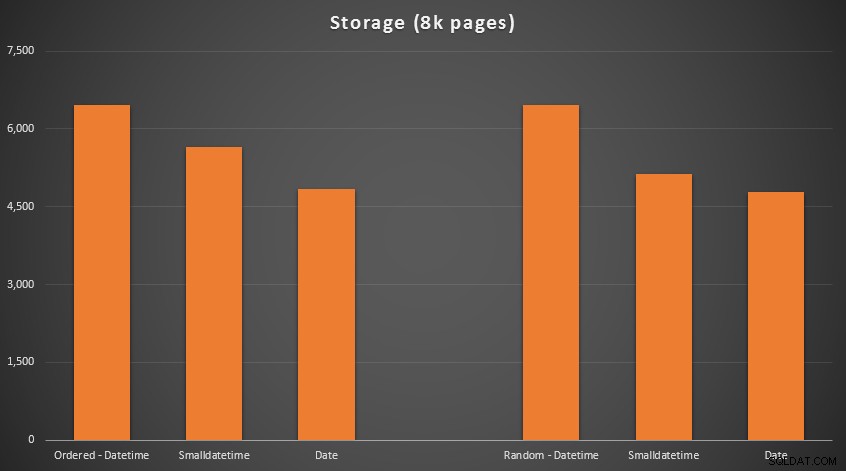
No hay ciencia espacial aquí; use un tipo de datos más pequeño, debe usar menos páginas. Cambiando desde DATETIME al DATE produjo una reducción constante del 25 % en el número de páginas utilizadas, mientras que SMALLDATETIME redujo el requisito en un 13-20%.
Ahora, para la fragmentación y la densidad de páginas en los índices no agrupados (hubo muy poca diferencia para los índices agrupados):
SELECT '{table_name}',
index_id
avg_page_space_used_in_percent,
avg_fragmentation_in_percent
FROM sys.dm_db_index_physical_stats
(
DB_ID(), OBJECT_ID('{table_name}'),
NULL, NULL, 'DETAILED'
)
WHERE index_level = 0 AND index_id = 2; Resultados:
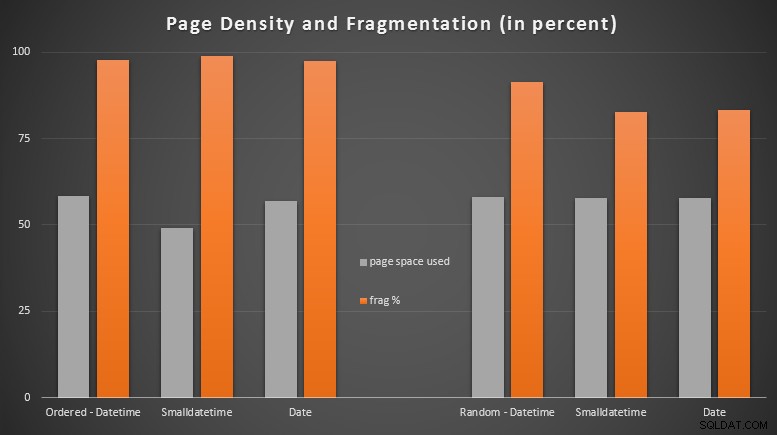
Me sorprendió bastante ver que los datos ordenados se fragmentaron casi por completo, mientras que los datos que se insertaron al azar en realidad terminaron con un uso de la página ligeramente mejor. Tomé nota de que esto justifica una mayor investigación fuera del alcance de estas pruebas específicas, pero puede ser algo que desee verificar si tiene índices no agrupados que dependen en gran medida de inserciones secuenciales.
[Una reconstrucción en línea de los índices no agrupados en las 6 tablas se ejecutó en 7 segundos, volviendo a poner la densidad de página en el rango del 99,5 % y reduciendo la fragmentación a menos del 1 %. Pero no ejecuté eso hasta que realicé las siguientes pruebas de consulta...]
Prueba de consulta de rango
Finalmente, quería ver el impacto en los tiempos de ejecución para consultas de rango de fechas simples en los diferentes índices, tanto con la fragmentación inherente causada por la actividad de escritura de tipo OLTP como en un índice limpio que se reconstruye. La consulta en sí es bastante simple:
SELECT TOP (200000) dt
FROM dbo.{table_name}
WHERE dt >= '20110101'
ORDER BY dt; Estos son los resultados antes de que se reconstruyeran los índices, usando SQL Sentry Plan Explorer:
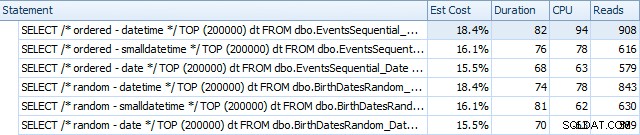
Y difieren ligeramente después de las reconstrucciones:
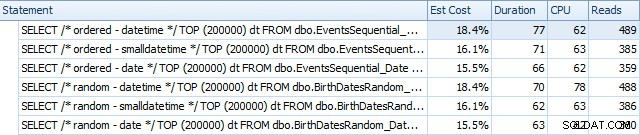
Esencialmente, vemos una duración y lecturas ligeramente más altas para las versiones DATETIME, pero muy poca diferencia en la CPU. Y las diferencias entre SMALLDATETIME y DATE son insignificantes en comparación. Todas las consultas tenían planes de consulta simplistas como este:

(La búsqueda es, por supuesto, un escaneo de rango ordenado).
Conclusión
Si bien es cierto que estas pruebas están bastante fabricadas y podrían haberse beneficiado de más permutaciones, muestran aproximadamente lo que esperaba ver:los mayores impactos en esta elección específica están en el espacio ocupado por el índice no agrupado (donde elegir un tipo de datos más delgado ciertamente beneficio), y en el tiempo requerido para realizar inserciones en orden arbitrario, en lugar de secuencial (donde DATETIME solo tiene un borde marginal).
Me encantaría escuchar sus ideas sobre cómo someter opciones de tipo de datos como estas a pruebas más exhaustivas y exigentes. Planeo entrar en más detalles en publicaciones futuras.