Introducción
En este artículo, vamos a hablar sobre el uso de nvarchar tipo de datos. Exploraremos cómo SQL Server almacena este tipo de datos en el disco y cómo se procesa en la RAM. También examinaremos cómo el tamaño de nvarchar puede afectar el rendimiento.
Tamaño real de datos:nchar vs nvarchar
Usamos nvarchar cuando el tamaño de las entradas de datos de la columna probablemente va a variar considerablemente. El tamaño de almacenamiento (en bytes) es el doble de la longitud real de los datos ingresados + 2 bytes. Esto nos permite ahorrar almacenamiento en disco en comparación con el uso de nchar tipo de datos. Consideremos el siguiente ejemplo. Estamos creando dos tablas. Una tabla contiene la columna nvarchar, otra tabla contiene columnas nchar. El tamaño de la columna es de 2000 caracteres (4000 bytes).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
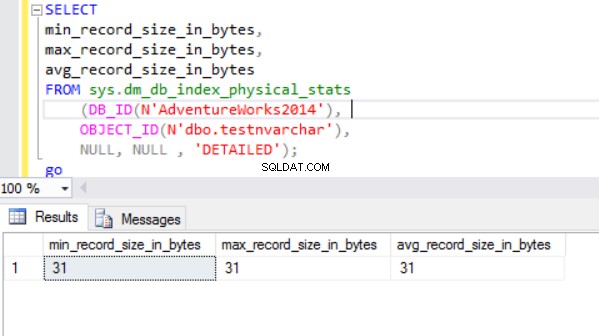
El tamaño real de la fila es:
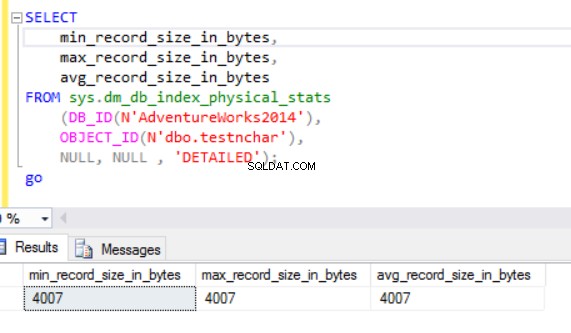
Como podemos ver, el tamaño de fila real del tipo de datos nvarchar es mucho más pequeño que el tipo de datos nchar. En el caso del tipo de datos nchar, usamos ~4000 bytes para almacenar una cadena de caracteres de 10 símbolos. Usamos ~20 bytes para almacenar la misma cadena de caracteres en el caso del tipo de datos nvarchar.
El motor de SQL Server procesa los datos en RAM (grupo de búfer). ¿Qué pasa con el tamaño de fila en la memoria?
Tamaño de datos real:HDD vs RAM
Ejecutemos la siguiente consulta:
SELECT col1 FROM dbo.testnchar;

No hay diferencia entre la utilización del disco y la RAM en el caso de la cadena de caracteres de longitud fija.
SELECT col1 FROM dbo.testnvarchar;

Podemos ver que el motor de SQL Server solicitó la memoria solo para la mitad del tamaño de fila declarado (2000 bytes en lugar de los 20 bytes reales) y varios bytes para obtener información adicional. Por un lado disminuimos el uso de espacio en disco pero por otro podemos inflar la memoria RAM solicitada. Este es un efecto secundario del uso de los diferentes tipos de datos de caracteres. Este efecto secundario puede tener un gran impacto en los recursos en algunos casos.
FORMAT():RAM solicitada vs RAM utilizada
Usamos la función FORMATO, que devuelve un valor formateado con el formato especificado y la referencia cultural opcional. El valor devuelto es nvarchar o nulo. La longitud del valor devuelto está determinada por el formato . FORMAT(getdate(), 'yyyyMMdd','en-US') dará como resultado '20170412'. Necesitamos 16 bytes para almacenar este resultado en la columna del disco (el resultado será nvarchar(8)). ¿Cuál es el tamaño de los datos en la RAM para los datos en particular?
Ejecutemos la siguiente consulta. Utilizamos el siguiente entorno:
- AdventureWorks2014
- Edición de desarrollo de MS SQL 2016
- dbo.Customer (19'820'000 registros) contiene datos de Sales.Customer (19'820 registros se han cargado 1000 veces)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
El plan de ejecución de Query es bastante simple:

La primera operación es "Escaneo de índice agrupado" en la tabla dbo.Customer. Se han leído ~19 000 000 registros. El tamaño estimado de los datos es de 435 Mb.
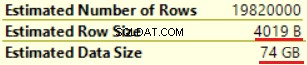
La siguiente operación es "Compute Scalar" (cálculo de la función FORMAT()). El resultado es bastante inesperado ya que formateamos una cadena de caracteres de 16 bytes. El tamaño de fila aumentó drásticamente de 23 bytes a 4019 bytes. Lo mismo con el Tamaño de datos estimado:de 435 MB a 74 GB. Podemos ver que FORMAT() devuelve NVARCHAR(4000).
MS SQL Server 2016 tiene la gran capacidad de mostrar una concesión de memoria excesiva. Podemos ver la advertencia en la última operación (T-SQL SELECT INTO):
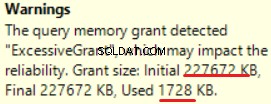
Esto es "sobre concedido" de la memoria:más del 90% de la memoria concedida no se utiliza.
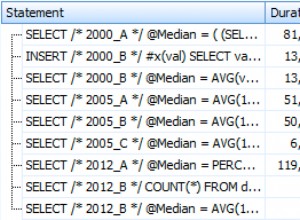
Las estadísticas de tiempo de consulta son:
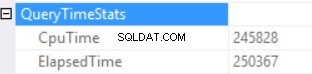
El largo tiempo de ejecución depende de una ejecución de función escalar no efectiva y del efecto secundario de una concesión de memoria excesiva:coincidencia de hash (unión externa derecha). Tenemos un efecto acumulativo de dos causas diferentes:la ejecución de múltiples funciones escalares y la concesión excesiva de memoria.
El motor de SQL Server no puede otorgar más del 25 % de la memoria permitida por consulta. Podemos cambiar esta cantidad en la edición empresarial de MS SQL Server usando el regulador de recursos. La memoria concedida consta de dos partes:obligatoria y adicional. Se utiliza una memoria requerida para las necesidades internas:para operaciones de clasificación y combinación hash. La memoria adicional se basa en el tamaño de datos estimado. Si tanto la memoria requerida como la adicional exceden el límite del 25 %, el motor de SQL Server otorga otro 25 % de la memoria disponible. Lea la publicación de concesión de memoria de SQL Server para obtener más detalles.
Ejecutemos la misma consulta sin la función FORMAT().
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
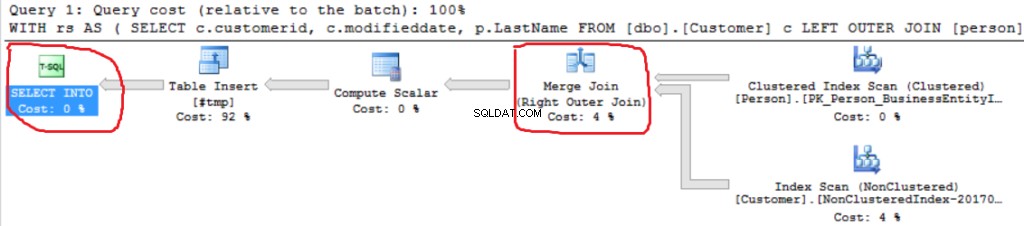
Podemos ver otra implementación de Right Outer Join (Merge Join en lugar de Hash Join).
La información de concesión de memoria es (si no hay clasificación y Hash Join SQL Server no puede conceder memoria):
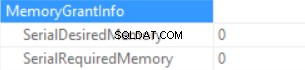
Las estadísticas de tiempo de consulta son (el tiempo se reduce de forma predecible:no se ejecuta la función escalar, el tamaño de datos estimado es menor que en la muestra anterior):

Así que estamos inflando la "memoria otorgada" hasta 222 MB (y estamos usando menos de 2 MB) usando la función FORMAT(). El volumen de datos en el ejemplo es pequeño.
Consulta de ejecución de larga duración
Considere la consulta SQL real de un entorno de producción. Esta consulta se ha ejecutado durante un proceso de carga por lotes (no un escenario transaccional clásico). Usamos MS SQL Server iniciado en Amazon Web Services (AWS, Amazon Relational Database Service). Las características de la instancia de base de datos son 160 GB de RAM (no se pueden otorgar más de ~30 GB de RAM por consulta) y 40 vCPU. La consulta SQL fue casi la misma que en el ejemplo anterior (la diferencia está en la cantidad de tablas y el tamaño de los datos):CTE incluyó la unión entre 6 tablas. La "tabla maestra" (una tabla en la cláusula FROM) contiene ~175 000 000 registros y el tamaño de los datos es de 20 GB. Las tablas de búsqueda (tabla de la derecha en la cláusula JOIN) son pequeñas (en comparación con la tabla principal). La consulta SQL contiene dos llamadas de la función FORMAT() (dos columnas de la tabla "tabla maestra" son el parámetro de esta función).
La consulta de producción se ve así:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
La "imagen" del plan de ejecución se encuentra a continuación (el plan de ejecución es simple:uniones secuenciales y clasificación (palabras clave DISTINTAS) en la parte superior):

Exploremos la información en detalle.
La primera operación es "Exploración de la tabla" (todo es correcto, sin sorpresas):

La operación de "cálculo escalar" aumenta drásticamente el tamaño de fila estimado, así como el tamaño de fila estimado (desde 19 GB hasta 1,3 TB). Dos llamadas de la función FORMAT() agregaron alrededor de 8000 bytes al tamaño de fila estimado (pero el tamaño de datos real es más pequeño).

Una de las operaciones JOIN (Hash Match, Right Outer Join) utiliza columnas no exclusivas de la tabla de la derecha. No importa en el caso de unos pocos registros. Este no es nuestro caso. Como resultado, el tamaño de datos estimado está aumentando hasta ~2,4 TB.

También hay una advertencia (no hay suficiente RAM para procesar esta operación):
La consulta SQL contiene una operación de "Ordenación distinta" en la parte superior, que parece la cereza en la parte superior de un pastel. Podemos ver la misma advertencia allí.
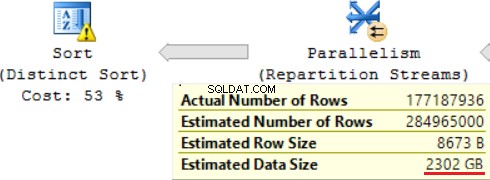
Un resultado del uso de una función escalar es mucho tiempo para la ejecución de consultas:24 horas. Una de las causas de este problema es una estimación incorrecta del tamaño de datos solicitado en función del "Tamaño de datos estimado". Sin usar la función FORMAT(), MS SQL Server ejecuta esta consulta en 2 horas.
Conclusión
Los desarrolladores deben tener cuidado al usar los tipos de datos nvarchar y varchar. La selección de tipos de datos redundantes para las columnas puede dar lugar a un aumento de la memoria necesaria. Como resultado, se desperdiciará RAM y se degradará el rendimiento de la base de datos.