¿Por qué elegir la replicación de MySQL?
Primero algunos conceptos básicos sobre la tecnología de replicación. ¡La replicación de MySQL no es complicada! Es fácil de implementar, monitorear y ajustar, ya que hay varios recursos que puede aprovechar, Google es uno. MySQL Replication no contiene muchas variables de configuración para ajustar. Los errores lógicos de SQL_THREAD y IO_THREAD no son tan difíciles de entender y corregir. MySQL Replication es muy popular hoy en día y ofrece una forma sencilla de implementar la alta disponibilidad de la base de datos. Potentes funciones como GTID (Identificador de transacción global) en lugar de la antigua posición de registro binario, o la replicación semisincrónica sin pérdidas lo hacen más sólido.
Como vimos en una publicación anterior, la latencia de la red es un gran desafío al seleccionar una solución de alta disponibilidad. El uso de MySQL Replication ofrece la ventaja de no ser tan sensible a la latencia. No implementa ninguna replicación basada en certificación, a diferencia de Galera Cluster, que utiliza técnicas de ordenación de transacciones y comunicación grupal para lograr la replicación síncrona. Por lo tanto, no tiene ningún requisito de que todos los nodos tengan que certificar un conjunto de escritura y no es necesario esperar antes de una confirmación en el otro esclavo o réplica.
La elección de la replicación MySQL tradicional con un enfoque asíncrono primario-secundario le brinda velocidad cuando se trata de manejar transacciones desde su maestro; no necesita esperar a que los esclavos se sincronicen o confirmen transacciones. La configuración normalmente tiene un primario (maestro) y uno o más secundarios (esclavos). Por lo tanto, es un sistema de nada compartido, donde todos los servidores tienen una copia completa de los datos por defecto. Por supuesto que hay inconvenientes. La integridad de los datos puede ser un problema si sus esclavos no se replicaron debido a errores de subprocesos de E/S y SQL, o fallas. Como alternativa, para abordar los problemas de integridad de los datos, puede optar por implementar la replicación de MySQL semisincrónica (o denominada replicación semisincrónica sin pérdidas en MySQL 5.7). Cómo funciona esto es que el maestro tiene que esperar hasta que una réplica reconozca todos los eventos de la transacción. Esto significa que tiene que terminar sus escrituras en un registro de retransmisión y vaciarlo en el disco antes de enviarlo de vuelta al maestro con una respuesta ACK. Con la replicación semisíncrona habilitada, los subprocesos o las sesiones en el maestro deben esperar el reconocimiento de una réplica. Una vez que recibe una respuesta ACK de la réplica, puede confirmar la transacción. La siguiente ilustración muestra cómo MySQL maneja la replicación semisincrónica.
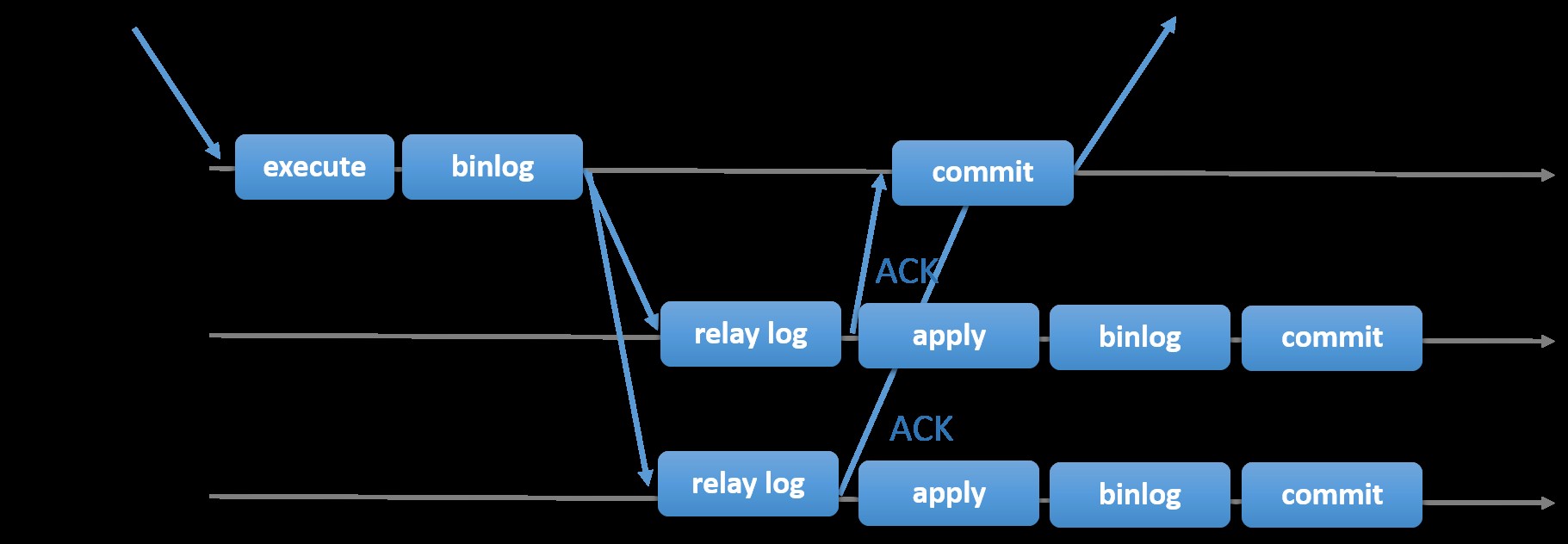 Imagen cortesía de la documentación de MySQL
Imagen cortesía de la documentación de MySQL Con esta implementación, todas las transacciones confirmadas ya se replican en al menos un esclavo en caso de que el maestro se bloquee. Aunque semi-síncrono no representa por sí mismo una solución de alta disponibilidad, pero es un componente para su solución. Lo mejor es que conozca sus necesidades y ajuste su implementación semisincronizada en consecuencia. Por lo tanto, si es aceptable cierta pérdida de datos, puede utilizar la replicación asíncrona tradicional.
La replicación basada en GTID es útil para el DBA, ya que simplifica la tarea de realizar una conmutación por error, especialmente cuando un esclavo apunta a otro maestro o maestro nuevo. Esto significa que con un simple MASTER_AUTO_POSITION=1 después de establecer las credenciales correctas de host y replicación, comenzará a replicar desde el maestro sin necesidad de buscar y especificar las posiciones x e y correctas del registro binario. Agregar compatibilidad con la replicación paralela también aumenta los subprocesos de replicación, ya que agrega velocidad para procesar los eventos del registro de retransmisión.
Por lo tanto, MySQL Replication es un excelente componente de elección sobre otras soluciones HA si se adapta a sus necesidades.
Topologías para la replicación de MySQL
La implementación de la replicación de MySQL en un entorno multinube con GCP (Google Cloud Platform) y AWS sigue siendo el mismo enfoque si tiene que replicar localmente.
Hay varias topologías que puede configurar e implementar.
Maestro con Replicación Esclava (Replicación Única)
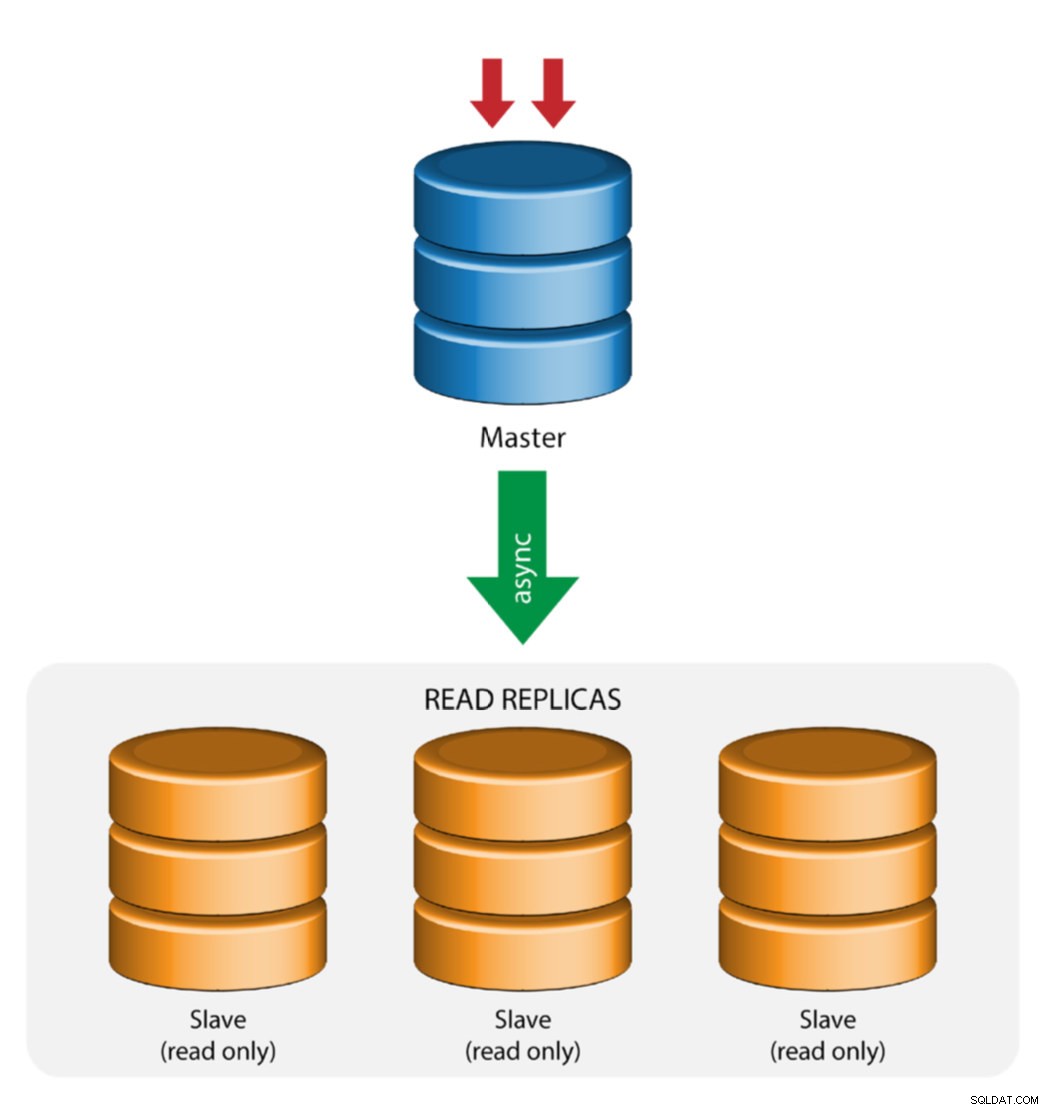
Esta es la topología de replicación de MySQL más sencilla. Un maestro recibe escrituras, uno o más esclavos replican desde el mismo maestro mediante replicación asincrónica o semisíncrona. Si el maestro designado deja de funcionar, el esclavo más actualizado debe promoverse como nuevo maestro. Los esclavos restantes reanudan la replicación desde el nuevo maestro.
Maestro con esclavos de relé (replicación en cadena)
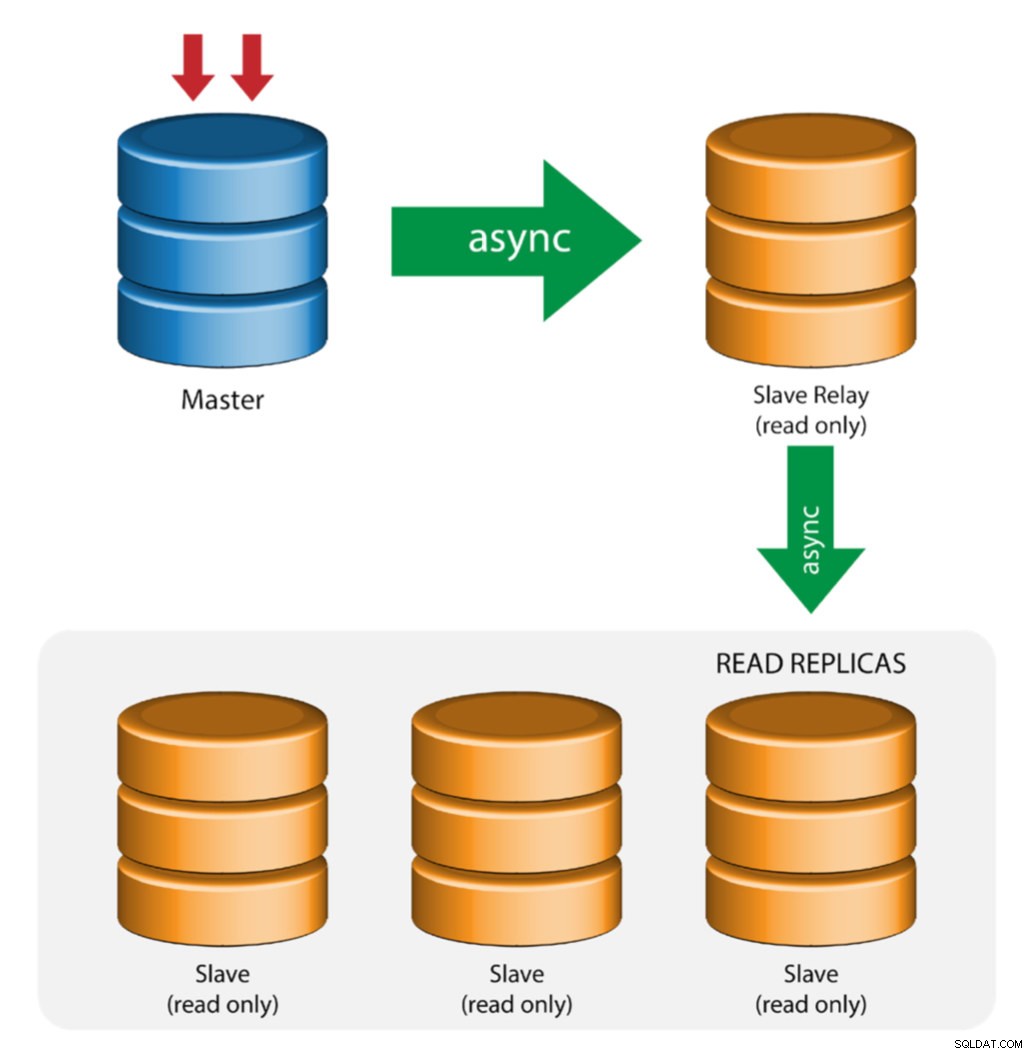
Esta configuración usa un maestro intermedio para actuar como un relé para los otros esclavos en la cadena de replicación. Cuando hay muchos esclavos conectados a un maestro, la interfaz de red del maestro puede sobrecargarse. Esta topología permite que las réplicas de lectura extraigan el flujo de replicación del servidor de retransmisión para descargar el servidor maestro. En el servidor de retransmisión esclavo, el registro binario y log_slave_updates deben estar habilitados, por lo que las actualizaciones recibidas por el servidor esclavo desde el servidor maestro se registran en el propio registro binario del esclavo.
Usar retransmisión esclava tiene sus problemas:
- log_slave_updates tiene alguna penalización de rendimiento.
- El retraso de la replicación en el servidor de retransmisión esclavo generará un retraso en todos sus esclavos.
- Las transacciones no autorizadas en el servidor de retransmisión esclavo infectarán a todos sus esclavos.
- Si un servidor de retransmisión esclavo falla y no está utilizando GTID, todos sus esclavos dejan de replicarse y deben reiniciarse.
Máster con Máster Activo (Replicación Circular)
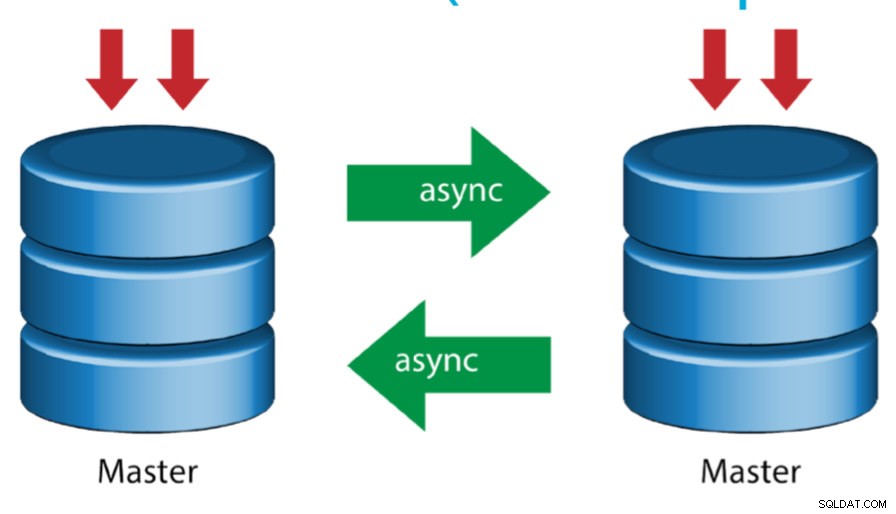
También conocida como topología en anillo, esta configuración requiere dos o más servidores MySQL que actúen como maestros. Todos los maestros reciben escrituras y generan binlogs con algunas advertencias:
- Debe configurar el desplazamiento de incremento automático en cada servidor para evitar colisiones de clave principal.
- No hay resolución de conflictos.
- Actualmente, la replicación de MySQL no admite ningún protocolo de bloqueo entre el maestro y el esclavo para garantizar la atomicidad de una actualización distribuida entre dos servidores diferentes.
- La práctica común es escribir solo en un maestro y el otro maestro actúa como un nodo de reserva activa. Aún así, si tiene esclavos por debajo de ese nivel, debe cambiar al nuevo maestro manualmente si el maestro designado falla.
- ClusterControl admite esta topología (no recomendamos varios escritores en una configuración de replicación). Consulte este blog anterior sobre cómo implementar con ClusterControl.
Maestro con maestro de respaldo (replicación múltiple)
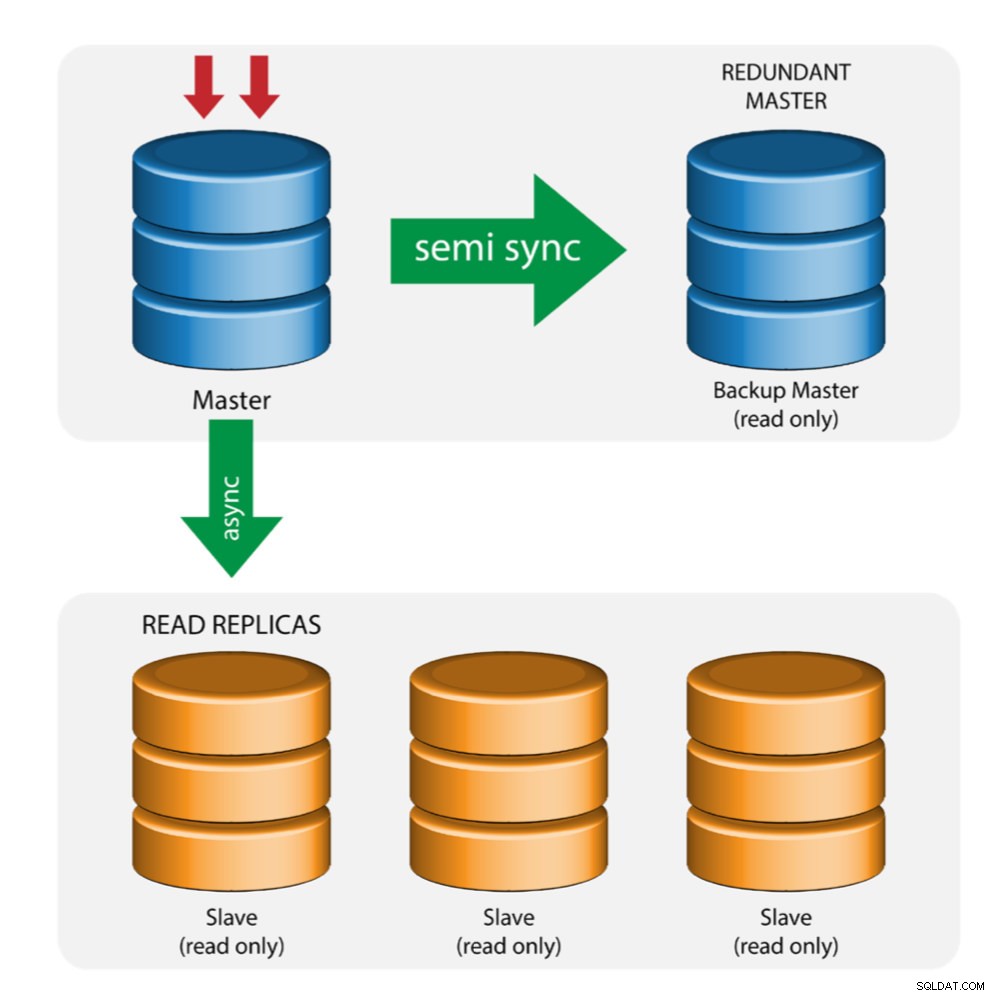
El maestro envía los cambios a un maestro de respaldo ya uno o más esclavos. La replicación semisíncrona se usa entre el maestro y el maestro de respaldo. El maestro envía la actualización al maestro de respaldo y espera con la confirmación de la transacción. El maestro de copia de seguridad obtiene actualizaciones, escribe en su registro de retransmisión y descarga en el disco. El maestro de respaldo acusa recibo de la transacción al maestro y continúa con la confirmación de la transacción. La replicación semisincronizada tiene un impacto en el rendimiento, pero el riesgo de pérdida de datos se minimiza.
Esta topología funciona bien cuando se realiza una conmutación por error del maestro en caso de que el maestro se caiga. El maestro de respaldo actúa como un servidor de espera caliente ya que tiene la mayor probabilidad de tener datos actualizados en comparación con otros esclavos.
Múltiples maestros a un solo esclavo (replicación de múltiples fuentes)
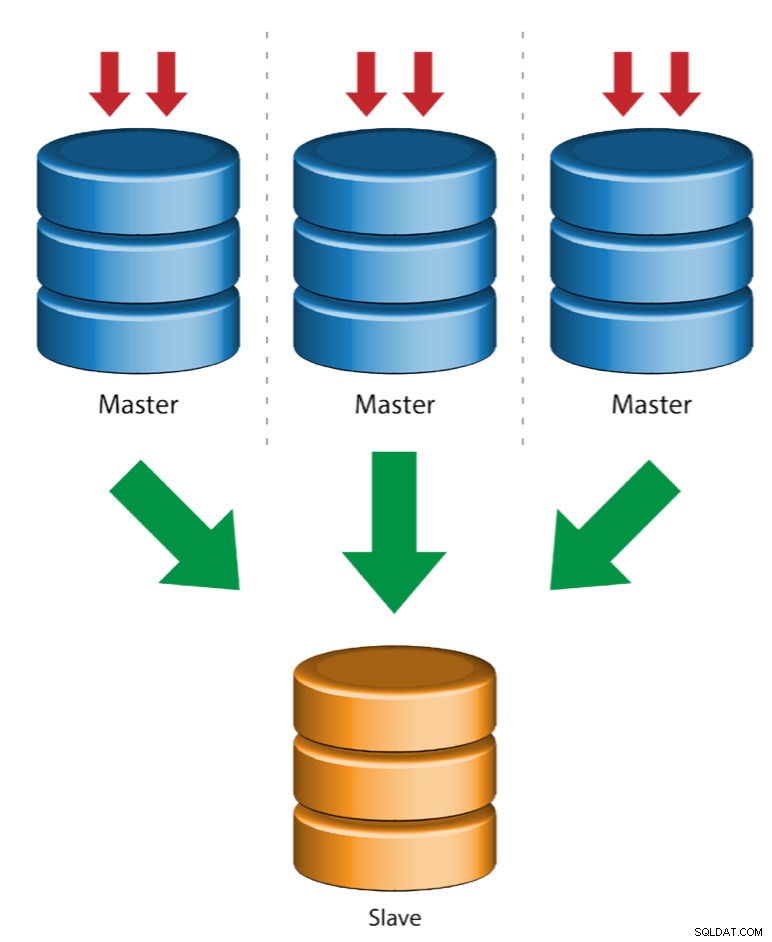
La replicación de múltiples fuentes permite que un esclavo de replicación reciba transacciones de múltiples fuentes simultáneamente. La replicación de varias fuentes se puede utilizar para realizar copias de seguridad de varios servidores en un solo servidor, fusionar fragmentos de tablas y consolidar datos de varios servidores en un solo servidor.
MySQL y MariaDB tienen diferentes implementaciones de replicación de múltiples fuentes, donde MariaDB debe tener GTID con gtid-domain-id configurado para distinguir las transacciones de origen, mientras que MySQL usa un canal de replicación separado para cada maestro desde el que se replica el esclavo. En MySQL, los maestros en una topología de replicación de múltiples fuentes se pueden configurar para usar la replicación basada en el identificador de transacción global (GTID) o la replicación basada en la posición del registro binario.
Puede encontrar más información sobre la replicación de múltiples fuentes de MariaDB en esta publicación de blog. Para MySQL, consulte la documentación de MySQL.
Galera con esclavo de replicación (replicación híbrida)
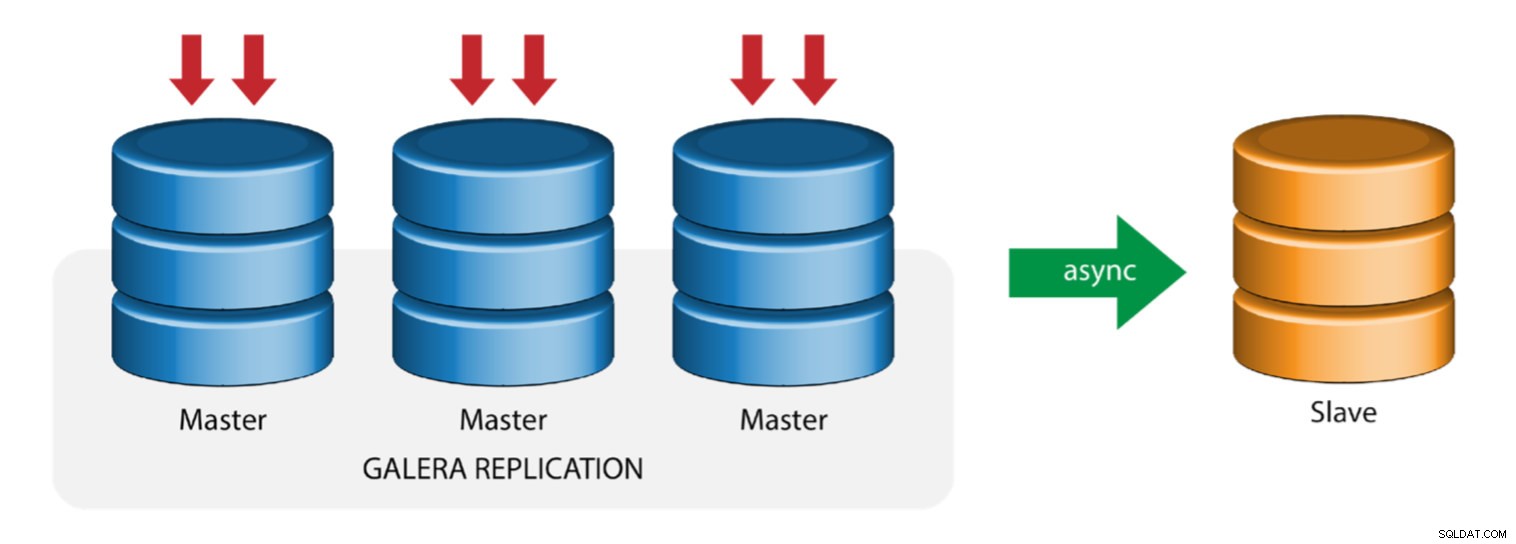
La replicación híbrida es una combinación de replicación asíncrona de MySQL y replicación virtualmente sincrónica proporcionada por Galera. La implementación ahora se simplifica con la implementación de GTID en la replicación de MySQL, donde configurar y realizar la conmutación por error del maestro se ha convertido en un proceso sencillo en el lado del esclavo.
El rendimiento del clúster de Galera es tan rápido como el nodo más lento. Tener un esclavo de replicación asincrónica puede minimizar el impacto en el clúster si envía consultas de tipo informes/OLAP de ejecución prolongada al esclavo, o si realiza trabajos pesados que requieren bloqueos como mysqldump. El esclavo también puede servir como una copia de seguridad en vivo para la recuperación ante desastres en el sitio y fuera del sitio.
ClusterControl admite la replicación híbrida y puede implementarla directamente desde la interfaz de usuario de ClusterControl. Para obtener más información sobre cómo hacerlo, lea las publicaciones del blog:replicación híbrida con MySQL 5.6 y replicación híbrida con MariaDB 10.x.
Preparación de plataformas GCP y AWS
El problema del "mundo real"
En este blog, demostraremos y usaremos la topología de "Replicación múltiple" en la que las instancias en dos plataformas de nube pública diferentes se comunicarán mediante la replicación de MySQL en diferentes regiones y en diferentes zonas de disponibilidad. Este escenario se basa en un problema del mundo real en el que una organización quiere diseñar su infraestructura en múltiples plataformas en la nube para escalabilidad, redundancia, resiliencia/tolerancia a fallas. Se aplicarían conceptos similares para MongoDB o PostgreSQL.
Consideremos una organización estadounidense, con una sucursal en el extranjero en el sureste de Asia. Nuestro tráfico es alto dentro de la región asiática. La latencia debe ser baja cuando se trata de escrituras y lecturas, pero al mismo tiempo, la región basada en EE. UU. también puede extraer registros provenientes del tráfico basado en Asia.
El flujo de la arquitectura en la nube
En esta sección, discutiré el diseño arquitectónico. Primero, queremos ofrecer una capa altamente segura para que nuestros nodos de Google Compute y AWS EC2 puedan comunicarse, actualizar o instalar paquetes desde Internet, segura, altamente disponible en caso de que una AZ (Zona de disponibilidad) se caiga, pueda replicar y comunicarse con otra plataforma en la nube a través de una capa segura. Vea la imagen a continuación como ilustración:

Según la ilustración anterior, en la plataforma de AWS, todos los nodos se ejecutan en diferentes zonas de disponibilidad. Tiene una subred privada y pública para la cual todos los nodos de cómputo están en una subred privada. Por lo tanto, puede salir de Internet para extraer y actualizar sus paquetes de sistema cuando sea necesario. Tiene una puerta de enlace VPN para lo cual tiene que interactuar con GCP en ese canal, saltándose Internet pero a través de un canal seguro y privado. Al igual que GCP, todos los nodos de cómputo están en diferentes zonas de disponibilidad, use NAT Gateway para actualizar los paquetes del sistema cuando sea necesario y use la conexión VPN para interactuar con los nodos de AWS que están alojados en una región diferente, es decir, Asia Pacífico (Singapur). Por otro lado, la región basada en EE. UU. está alojada en us-east1. Para acceder a los nodos, un nodo en la arquitectura sirve como nodo bastión para el cual lo usaremos como host de salto e instalaremos ClusterControl. Esto se abordará más adelante en este blog.
Configurar entornos de GCP y AWS
Al registrar su primera cuenta de GCP, Google proporciona una cuenta de VPC (nube privada virtual) predeterminada. Por lo tanto, es mejor crear una VPC separada de la predeterminada y personalizarla según sus necesidades.
Nuestro objetivo aquí es colocar los nodos de cómputo en subredes privadas o los nodos no se configurarán con IPv4 pública. Por lo tanto, ambas nubes públicas deben poder comunicarse entre sí. Los nodos de cómputo de AWS y GCP operan con diferentes CIDR como se mencionó anteriormente. Por lo tanto, aquí están los siguientes CIDR:
Nodos informáticos de AWS: 172.21.0.0/16
Nodos informáticos de GCP: 10.142.0.0/20
En esta configuración de AWS, asignamos tres subredes que no tienen una puerta de enlace de Internet pero sí una puerta de enlace NAT; y una subred que tiene una puerta de enlace a Internet. Cada una de estas subredes se aloja individualmente en diferentes zonas de disponibilidad (AZ).
ap-sureste-1a =172.21.1.0/24
ap-sureste-1b =172.21.8.0/24
ap-sureste-1c =172.21.24.0/24
Mientras está en GCP, se usa la subred predeterminada creada en una VPC bajo us-east1, que es 10.142.0.0/20 CIDR. Por lo tanto, estos son los pasos que puede seguir para configurar su plataforma de nube pública múltiple.
-
Para este ejercicio, creé una VPC en la región us-east1 con la siguiente subred de 10.142.0.0/20. Ver a continuación:

-
Reserva una IP Estática. Esta es la IP que configuraremos como Customer Gateway en AWS
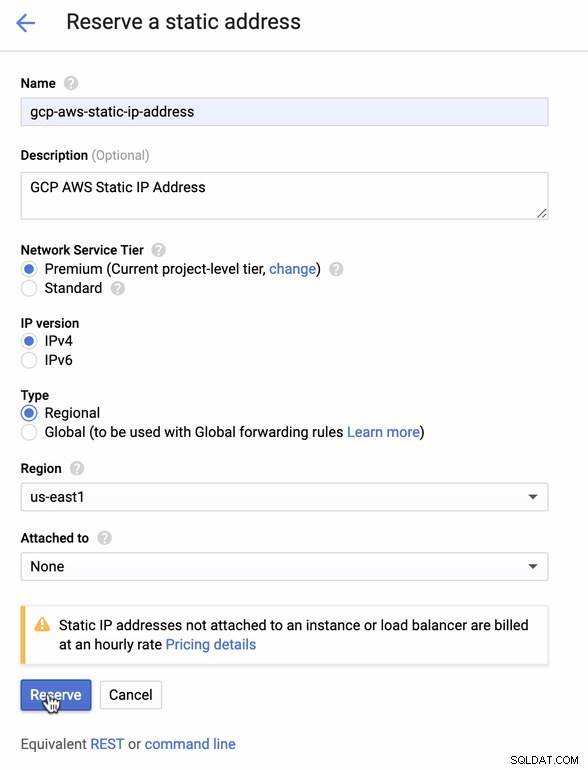
-
Dado que tenemos subredes (aprovisionadas como subnet-us-east1 ), ve a GCP -> Red de VPC -> Redes de VPC y seleccione la VPC que creó y vaya a las Reglas de firewall . En esta sección, agregue las reglas especificando su entrada y salida. Básicamente, estas son las reglas de entrada/salida en AWS o su firewall para las conexiones entrantes y salientes. En esta configuración, abrí todos los protocolos TCP del rango CIDR establecido en mi AWS y GCP VPC para simplificar el propósito de este blog. Por lo tanto, esta no es la forma óptima de seguridad. Ver imagen a continuación:
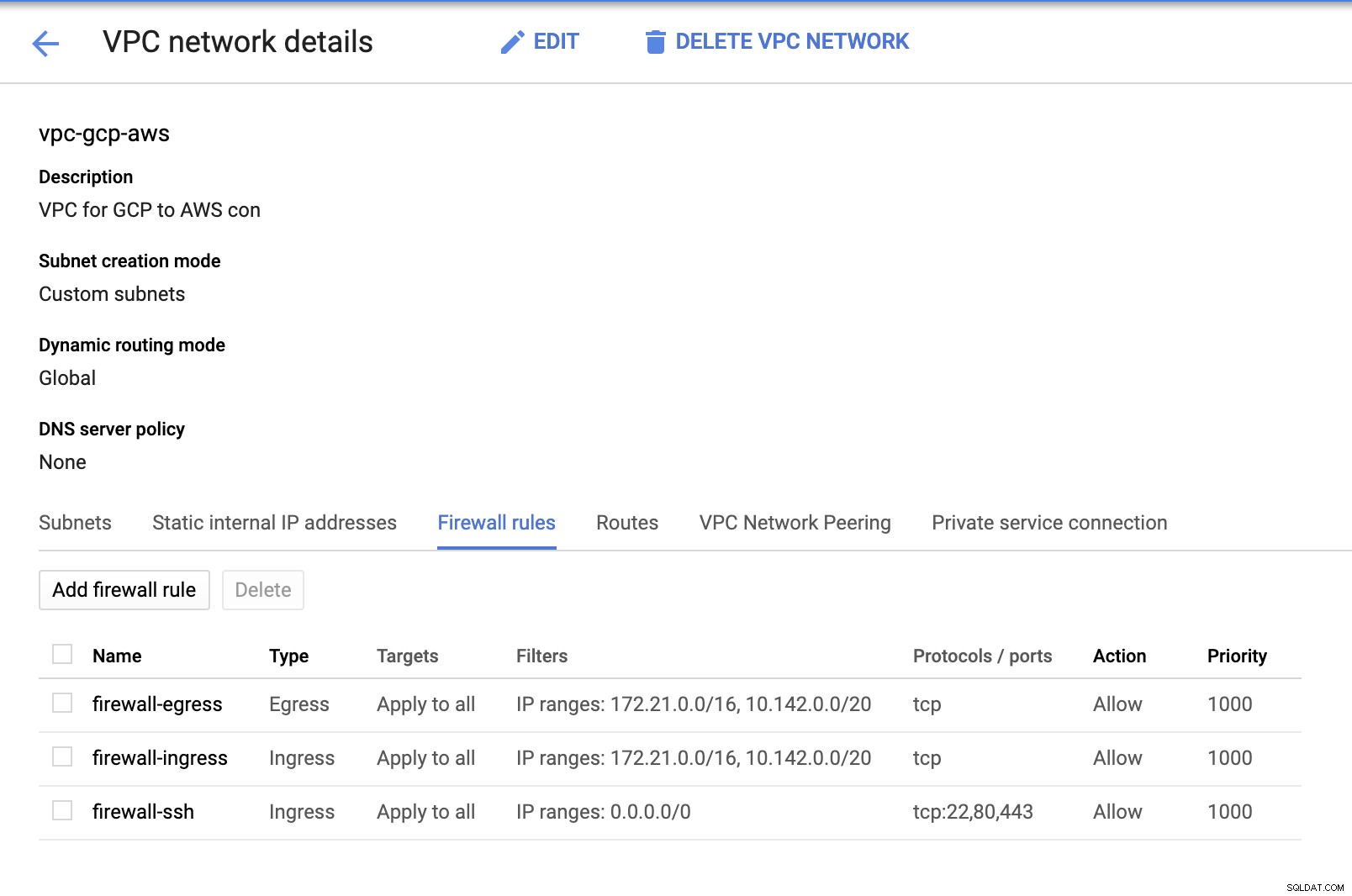
El firewall-ssh aquí se utilizará para permitir conexiones entrantes ssh, HTTP y HTTPS.
-
Ahora cambie a AWS y cree una VPC. Para este blog, utilicé CIDR (Enrutamiento entre dominios sin clases) 172.21.0.0/16
-
Crea las subredes para las que tienes que asignarlas en cada AZ (Availability Zone); y al menos reserve una subred para una subred pública que manejará NAT Gateway, y el resto son para nodos EC2.

-
A continuación, cree su Tabla de rutas y asegúrese de que el "Destino" y los "Objetivos" estén configurados correctamente. Para este blog, creé 2 tablas de rutas. Uno que manejará los 3 AZ que mis nodos de cómputo se asignarán individualmente y se asignarán sin una puerta de enlace de Internet, ya que no tendrá IP pública. Luego, el otro manejará la puerta de enlace NAT y tendrá una puerta de enlace de Internet que estará en la subred pública. Ver imagen a continuación:

y como se mencionó, mi destino de ejemplo para una ruta privada que maneja 3 subredes muestra que tiene un objetivo de puerta de enlace NAT más un objetivo de puerta de enlace virtual que mencionaré más adelante en los pasos entrantes.

-
A continuación, cree una "Puerta de enlace de Internet" y asígnela a la VPC que se creó previamente en la sección AWS VPC. Este Internet Gateway solo se establecerá como destino a la subred pública ya que será el servicio que tendrá que conectarse a Internet. Obviamente, el nombre significa un servicio de puerta de enlace a Internet.
-
A continuación, cree una "Puerta de enlace NAT". Al crear una "Puerta de enlace NAT", asegúrese de haber asignado su NAT a una subred pública. La puerta de enlace NAT es su canal para acceder a Internet desde su subred privada o nodos EC2 que no tienen asignado un IPv4 público. Luego, cree o asigne una EIP (IP elástica) ya que, en AWS, solo los nodos de cómputo que tienen asignado un IPv4 público pueden conectarse a Internet directamente.
-
Ahora, en VPC -> Seguridad -> Grupos de seguridad (SG) , su VPC creada tendrá un SG predeterminado. Para esta configuración, creé "Reglas de entrada" con fuentes asignadas para cada CIDR, es decir, 10.142.0.0/20 en GCP y 172.21.0.0/16 en AWS. Ver a continuación:

Para las "Reglas de salida", puede dejarlo como está, ya que la asignación de reglas a las "Reglas de entrada" es bilateral, lo que significa que también se abrirá para las "Reglas de salida". Tenga en cuenta que esta no es la forma óptima de configurar su grupo de seguridad; pero para facilitar esta configuración, también he ampliado el alcance del rango de puertos y la fuente. También que el protocolo es específico solo para conexiones TCP, ya que no trataremos con UDP para este blog.
Además, puede dejar su VPC -> Seguridad -> ACL de red intacto siempre que no DENIEgue ninguna conexión tcp del CIDR indicado en su fuente. -
A continuación, estableceremos la configuración de VPN que se alojará en la plataforma de AWS. En VPC -> Pasarelas de cliente , cree la puerta de enlace con la dirección IP estática que se creó anteriormente en el paso anterior. Echa un vistazo a la imagen de abajo:
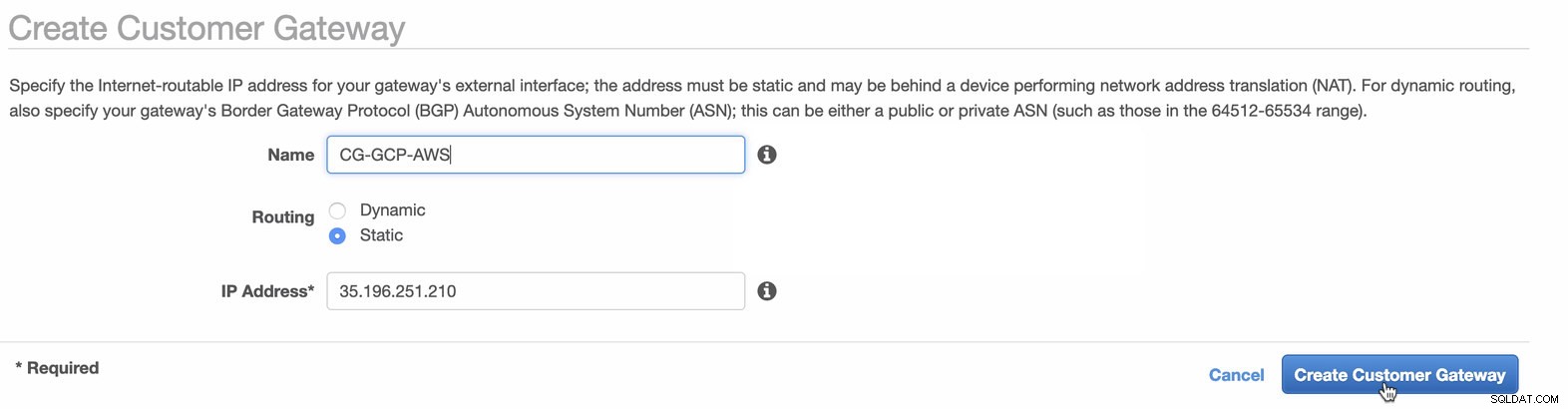
-
A continuación, cree una puerta de enlace privada virtual y adjúntela a la VPC actual que creamos anteriormente en el paso anterior. Ver imagen a continuación:

-
Ahora, cree una conexión VPN que se utilizará para la conexión de sitio a sitio entre AWS y GCP. Al crear una conexión VPN, asegúrese de haber seleccionado la puerta de enlace privada virtual correcta y la puerta de enlace del cliente que creamos en los pasos anteriores. Ver imagen a continuación:
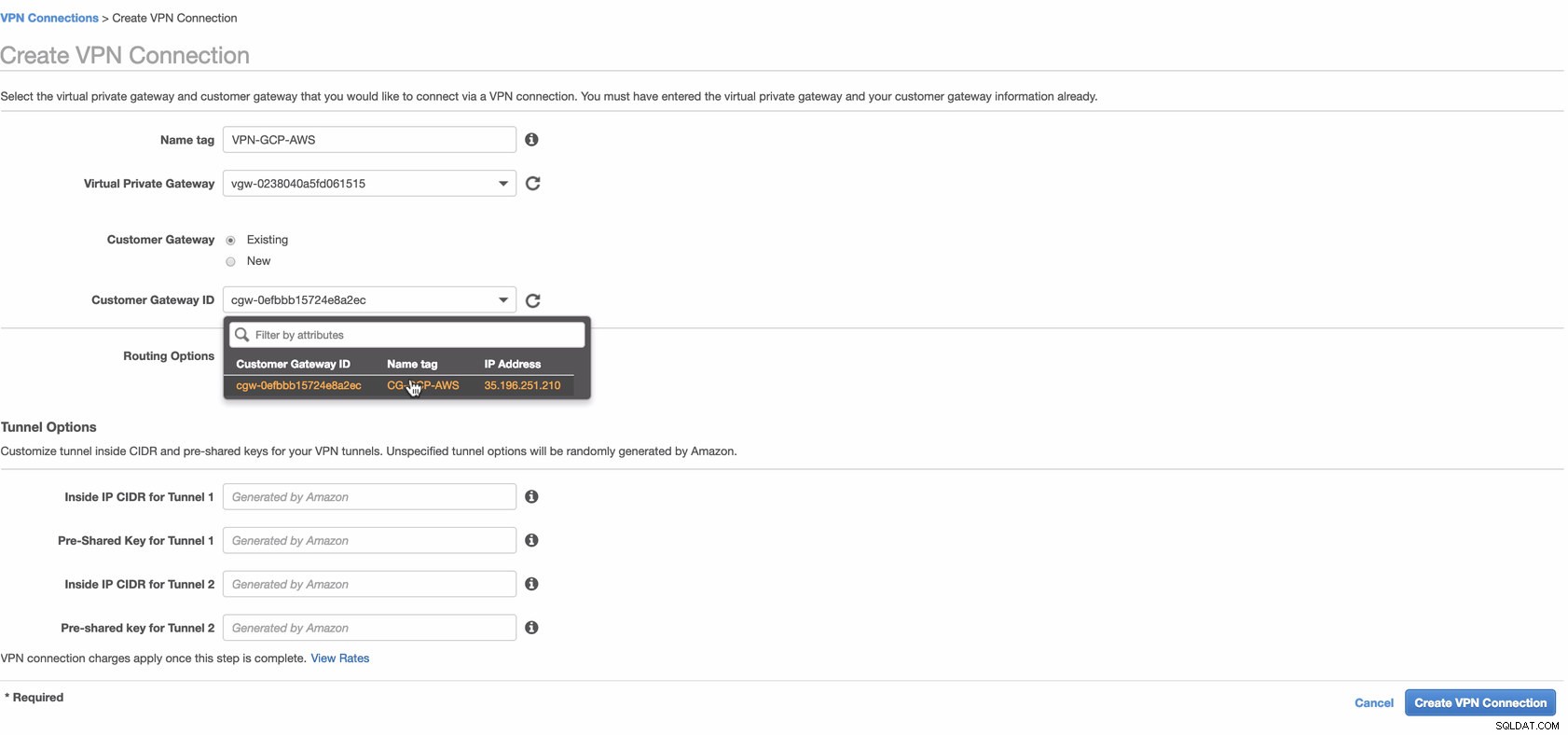
Esto puede llevar algún tiempo mientras AWS crea su conexión VPN. Cuando se aprovisiona su conexión VPN, es posible que se pregunte por qué en la pestaña Túnel (después de seleccionar su conexión VPN), se mostrará que la Dirección IP externa esta abajo. Esto es normal ya que aún no se ha establecido una conexión desde el cliente. Echa un vistazo a la imagen de ejemplo a continuación:

Una vez que la conexión VPN esté lista, seleccione su conexión VPN creada y descargue la configuración. Contiene sus credenciales necesarias para los siguientes pasos para crear una conexión VPN de sitio a sitio con el cliente.
Nota: En caso de que haya configurado su VPN donde IPSEC ESTÁ ACTIVA pero Estado está ABAJO como la imagen de abajo
esto probablemente se deba a valores incorrectos establecidos en los parámetros específicos al configurar su sesión BGP o enrutador en la nube. Compruébelo aquí para solucionar problemas de su VPN.
-
Como tenemos una conexión VPN lista alojada en AWS, creemos una conexión VPN en GCP. Ahora, regresemos a GCP y configuremos la conexión del cliente allí. En GCP, ve a GCP -> Conectividad híbrida -> VPN . Asegúrese de elegir la región correcta, que se encuentra en este blog, estamos usando us-east1 . Luego seleccione la dirección IP estática creada en los pasos anteriores. Ver imagen a continuación:
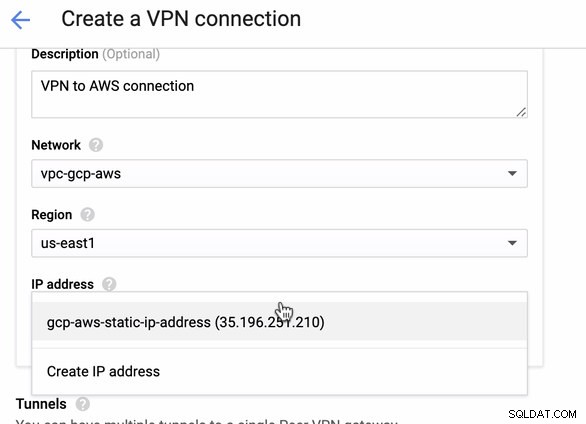
Luego en los Túneles sección, aquí es donde tendrá que configurar en función de las credenciales descargadas de la conexión VPN de AWS que creó anteriormente. Sugiero consultar esta útil guía de Google. Por ejemplo, uno de los túneles que se están instalando se muestra en la siguiente imagen:
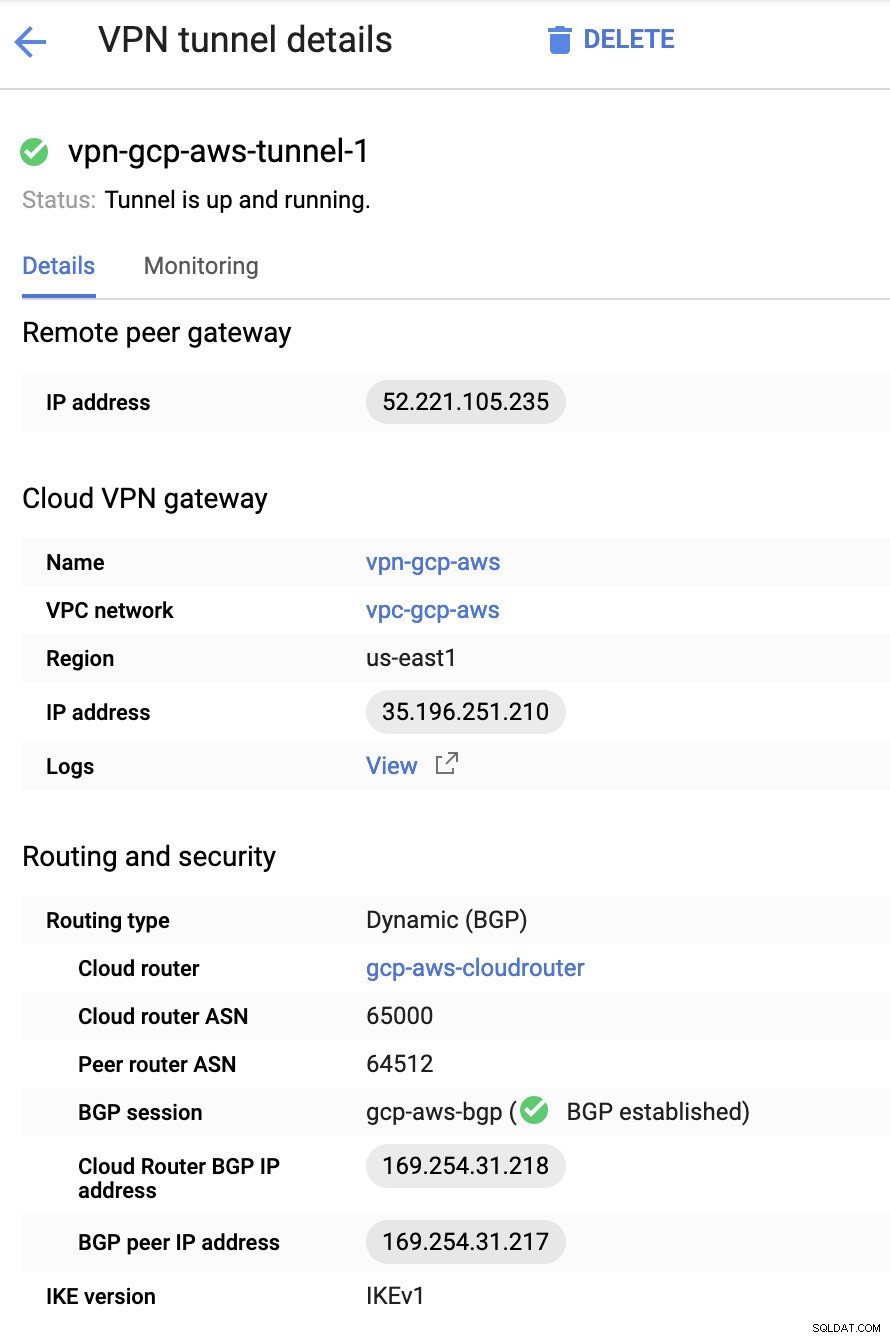
Básicamente, las cosas más importantes aquí son las siguientes:
- Puerta de enlace de pares remotos:Dirección IP:esta es la IP del servidor VPN indicado en Detalles del túnel -> Dirección IP externa . Esto no debe confundirse con la IP estática que creamos bajo GCP. Esa es la puerta de enlace de Cloud VPN -> dirección IP aunque.
- ASN del enrutador en la nube:de forma predeterminada, AWS usa 65000. Pero es probable que obtenga esta información del archivo de configuración descargado.
- ASN del enrutador del mismo nivel:este es el ASN de la puerta de enlace privada virtual que se encuentra en el archivo de configuración descargado.
- Dirección IP BGP de Cloud Router:esta es la Puerta de enlace del cliente encontrado en el archivo de configuración descargado.
- Dirección IP del par BGP:esta es la Puerta de enlace privada virtual encontrado en el archivo de configuración descargado.
-
Eche un vistazo al archivo de configuración de ejemplo que tengo a continuación:
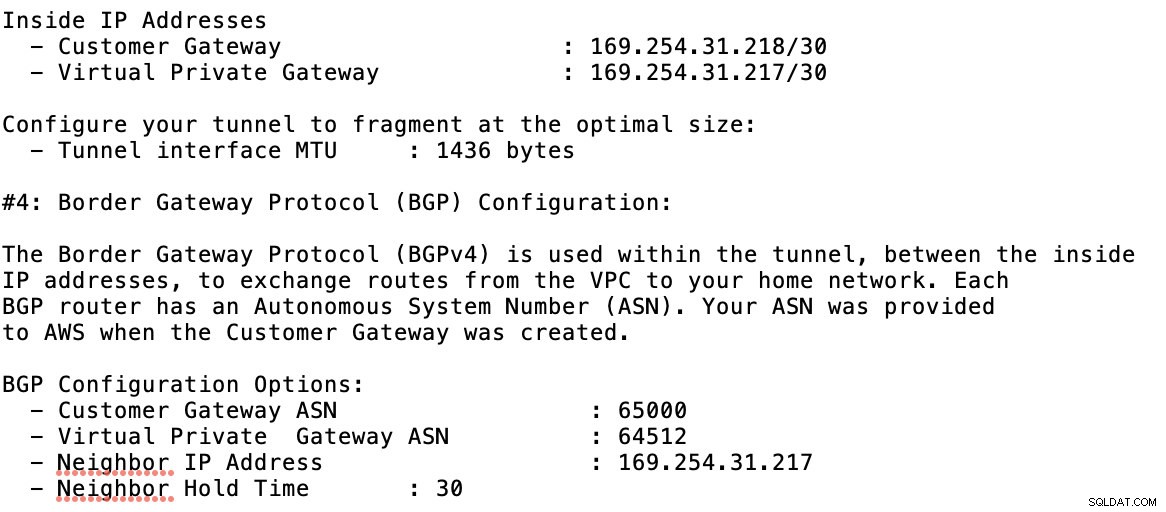
para lo cual debe hacer coincidir esto al agregar su túnel en GCP -> Conectividad híbrida -> VPN configuración de conectividad. Vea la imagen a continuación para la cual creé un enrutador en la nube y una sesión BGP durante la creación de un túnel de muestra:
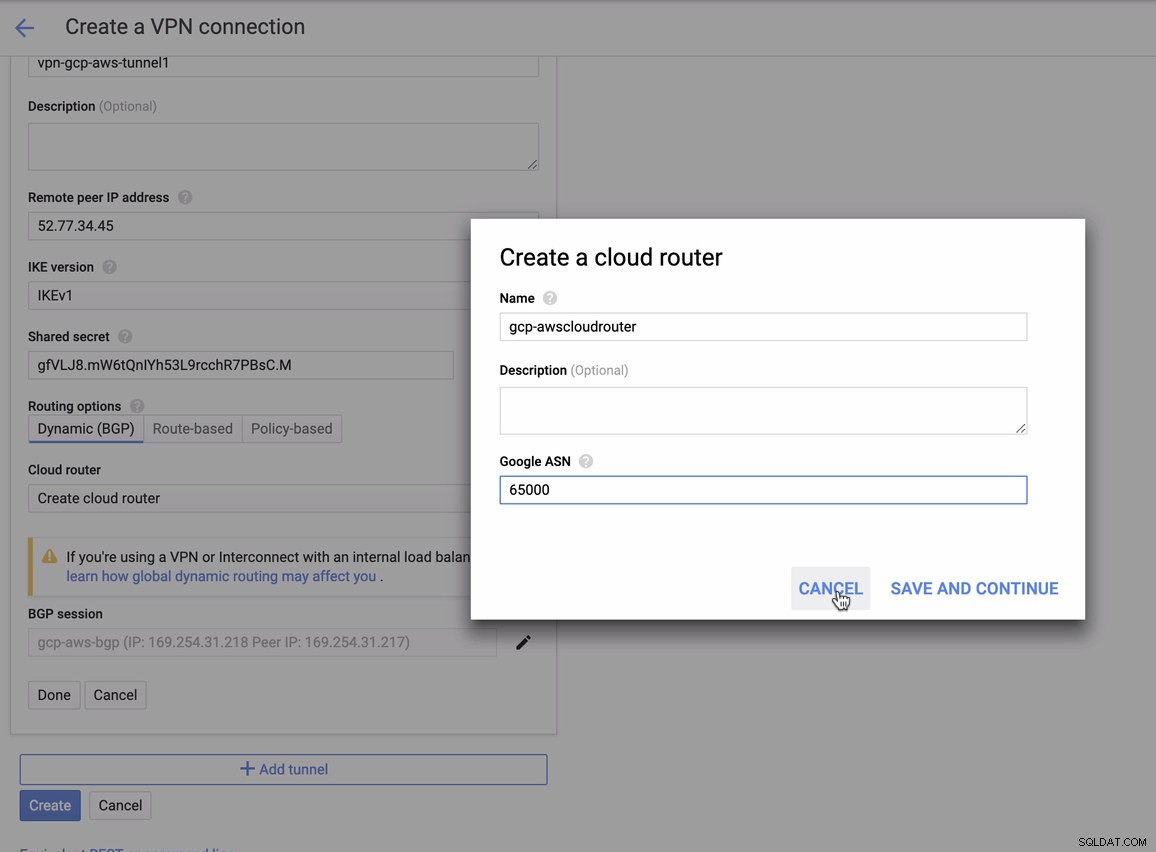
Entonces sesión BGP como,

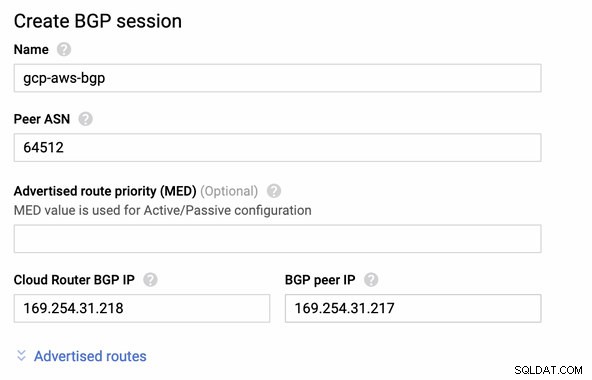
Nota: El archivo de configuración descargado contiene un túnel de configuración IPSec para el cual AWS también contiene dos (2) servidores VPN listos para su conexión. Debe tener que configurar ambos para tener una configuración de alta disponibilidad. Una vez que se haya configurado correctamente para ambos túneles, la conexión VPN de AWS en la pestaña Túneles mostrará que ambas Dirección IP externa están arriba. Ver imagen a continuación:
-
Por último, dado que hemos creado una puerta de enlace de Internet y una puerta de enlace NAT, complete correctamente las subredes públicas y privadas con el Destino correcto. y Objetivo como se observa en la captura de pantalla de los pasos anteriores. Esto se puede configurar yendo a Servicios -> Redes y entrega de contenido -> VPC -> Tablas de rutas y seleccione las tablas de rutas creadas mencionadas en los pasos anteriores. Vea la imagen a continuación:
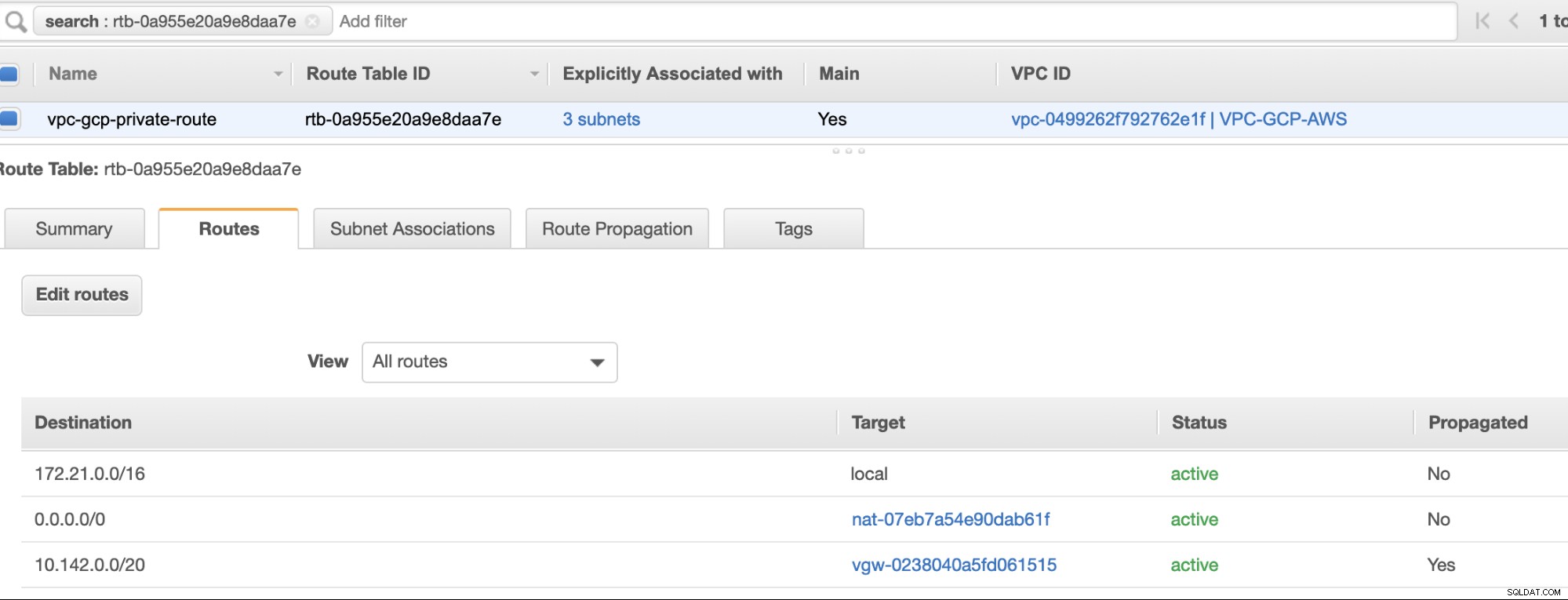
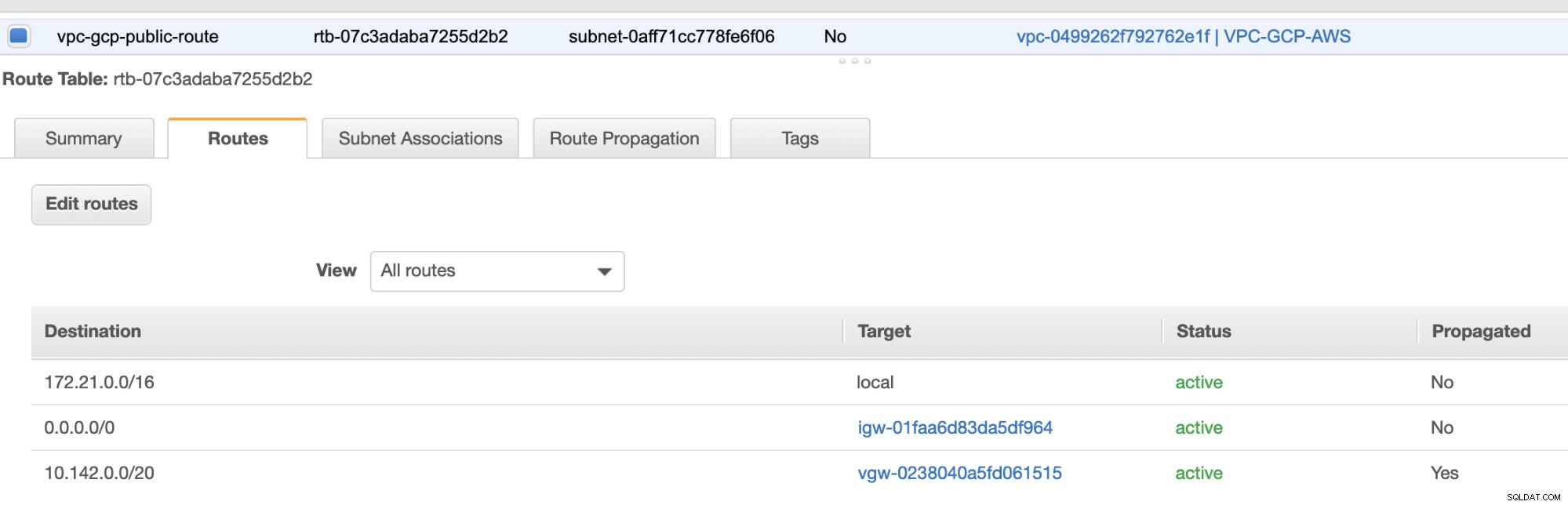
Como habrás notado, el igw-01faa6d83da5df964 es el Internet Gateway que creamos y es utilizado por la vía pública. Mientras que la tabla de rutas privadas tiene un destino y un objetivo establecidos en nat-07eb7a54e90dab61f y ambos tienen Destino establecido en 0.0.0.0/0 ya que permitirá desde diferentes conexiones IPv4. Además, no olvide configurar la propagación de ruta correctamente para Virtual Gateway como se ve en la captura de pantalla que tiene un objetivo vgw-0238040a5fd061515 . Simplemente haga clic en Propagación de ruta y configúrelo en Sí, tal como se muestra en la siguiente captura de pantalla:
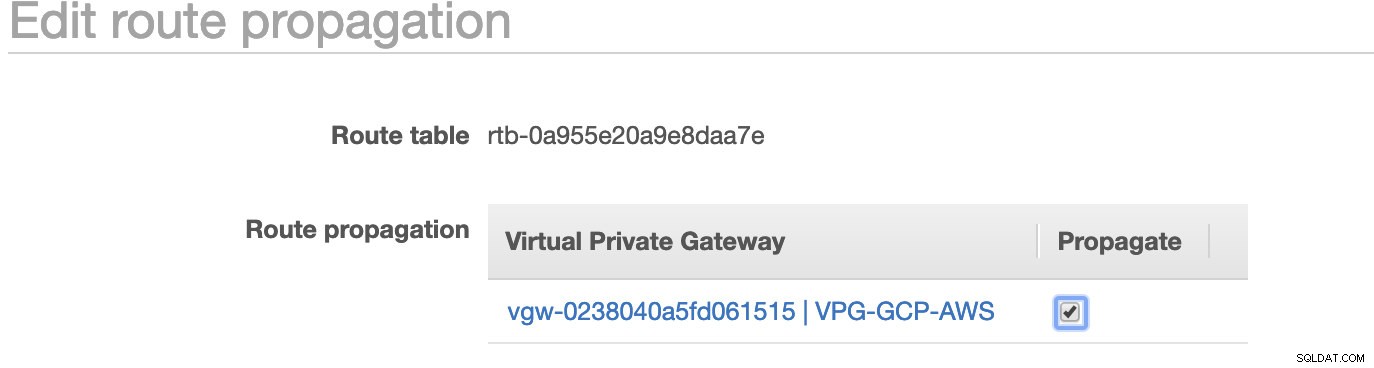
Esto es muy importante para que la conexión de las conexiones GCP externas se enrute a las tablas de rutas en AWS y no se necesite más trabajo manual. De lo contrario, su GCP no puede establecer conexión con AWS.
Ahora que nuestra VPN está activa, continuaremos configurando nuestros nodos privados, incluido el host bastión.
Configurar los nodos de Compute Engine
La configuración de los nodos de Compute Engine/EC2 será rápida y fácil, ya que tenemos toda la configuración en su lugar. No entraré en detalles, pero verifique las capturas de pantalla a continuación, ya que explican la configuración.
Nodos de AWS EC2 :

Nodos informáticos de GCP :
Básicamente, en esta configuración. El host control de clúster será el bastión o host de salto y para el cual se instalará ClusterControl. Obviamente, todos los nodos aquí no son accesibles por Internet. No tienen asignado un IPv4 externo y los nodos se comunican a través de un canal muy seguro mediante VPN.
Por último, todos estos nodos desde AWS hasta GCP están configurados con un usuario de sistema uniforme con acceso sudo, que se necesita en la siguiente sección. Vea cómo ClusterControl puede hacerle la vida más fácil cuando está en varias nubes y en varias regiones.
ClusterControl al rescate!!!
Manejar múltiples nodos y en diferentes plataformas de nube pública, además de en una "Región" diferente, puede ser una tarea "realmente dolorosa y desalentadora". ¿Cómo monitorea eso de manera efectiva? ClusterControl actúa no solo como su navaja suiza, sino también como su DBA virtual. Ahora, veamos cómo ClusterControl puede hacerle la vida más fácil.
Creación de un clúster de replicación múltiple mediante ClusterControl
Ahora intentemos crear un clúster de replicación maestro-esclavo de MariaDB siguiendo la topología "Replicación múltiple".
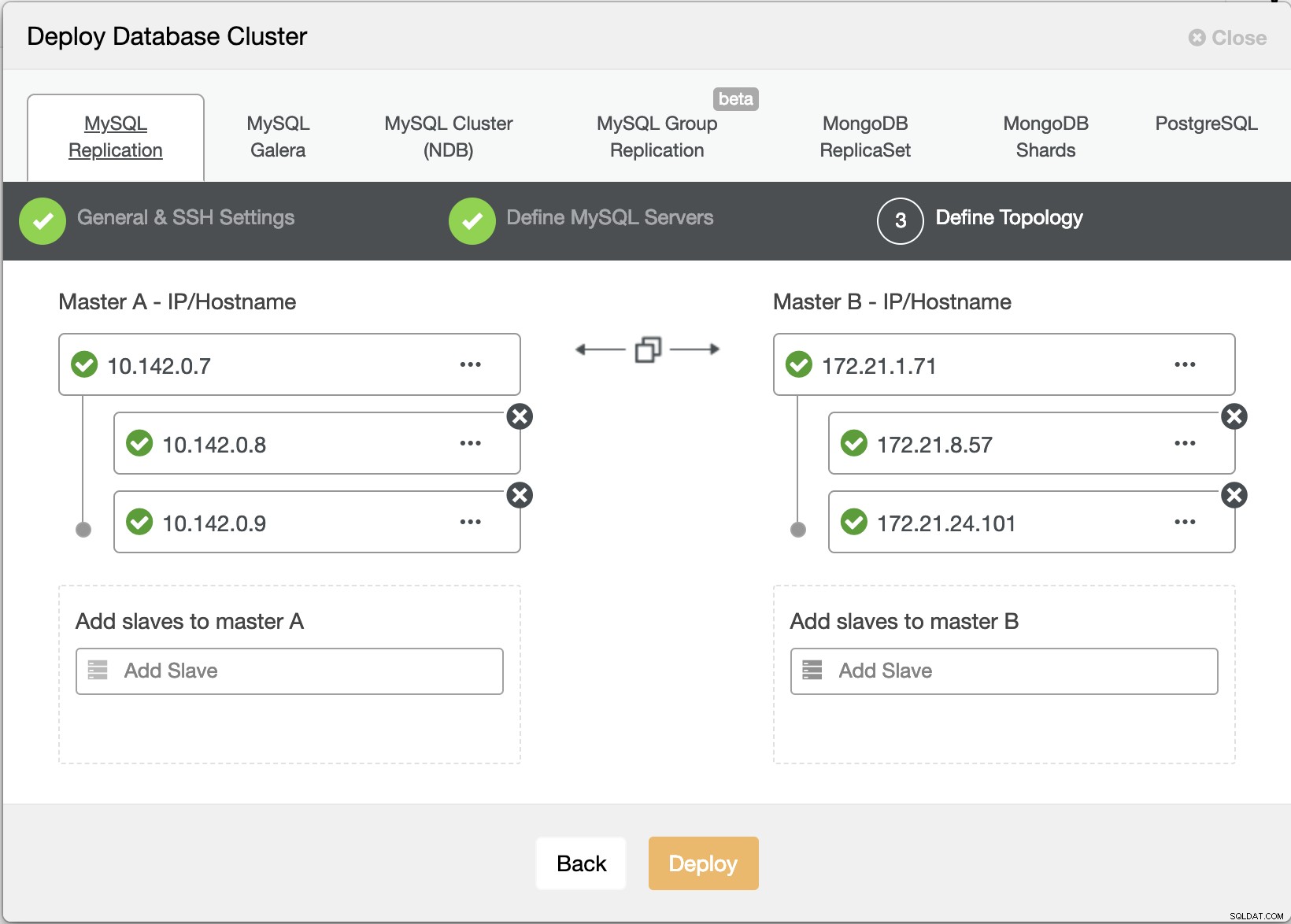 Asistente de implementación de ClusterControl
Asistente de implementación de ClusterControl Presionando Implementar El botón instalará paquetes y configurará los nodos en consecuencia. Por lo tanto, una vista lógica de cómo se vería la topología:
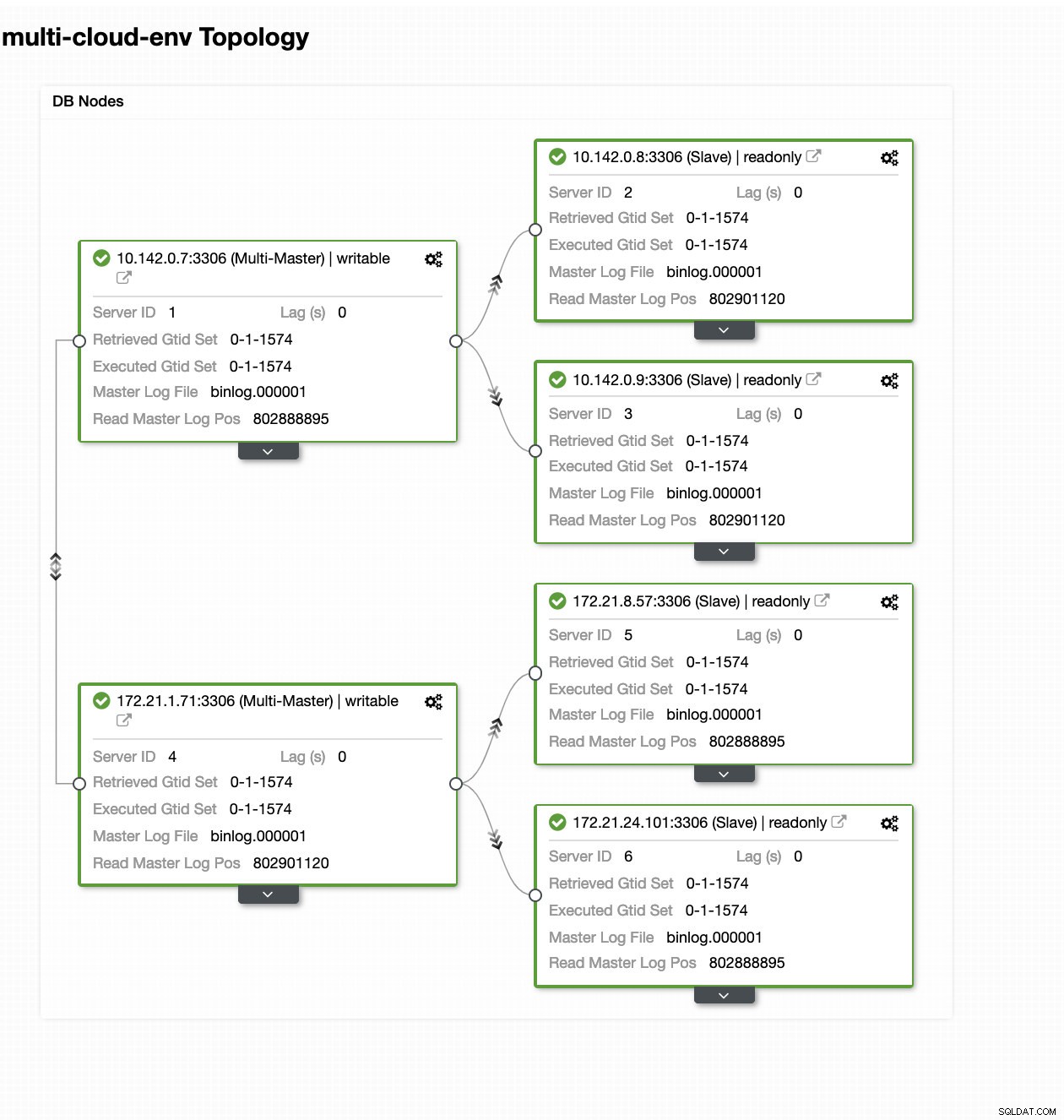 ClusterControl - Vista de topología
ClusterControl - Vista de topología Los nodos 172.21.0.0/16 rango de IP se replican desde su maestro que se ejecuta en GCP.
Ahora, ¿qué tal si intentamos cargar algunas escrituras en el maestro? Cualquier problema con la conectividad o la latencia podría generar un retraso esclavo, podrá detectarlo con ClusterControl. Vea la captura de pantalla a continuación:
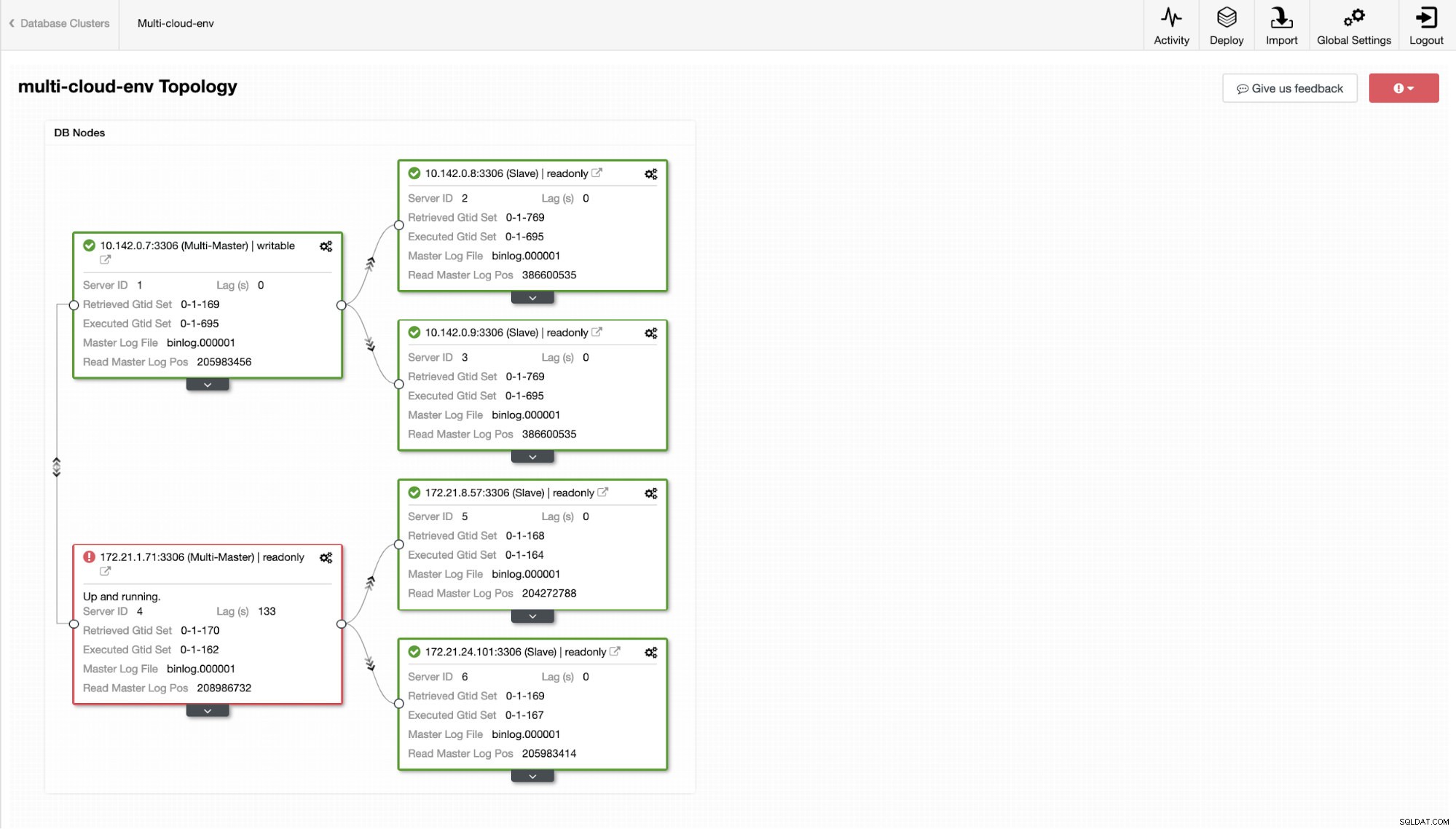
y como puede ver en la esquina superior derecha de la captura de pantalla, se vuelve rojo para indicar que se detectaron problemas. Por lo tanto, se envió una alarma mientras se detectaba este problema. Ver a continuación:
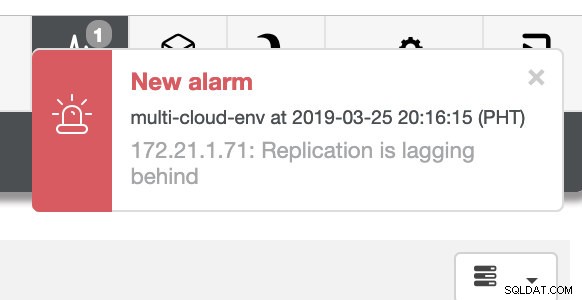
Tenemos que profundizar en esto. Para una supervisión detallada, hemos habilitado agentes en las instancias de la base de datos. Echemos un vistazo al Tablero.
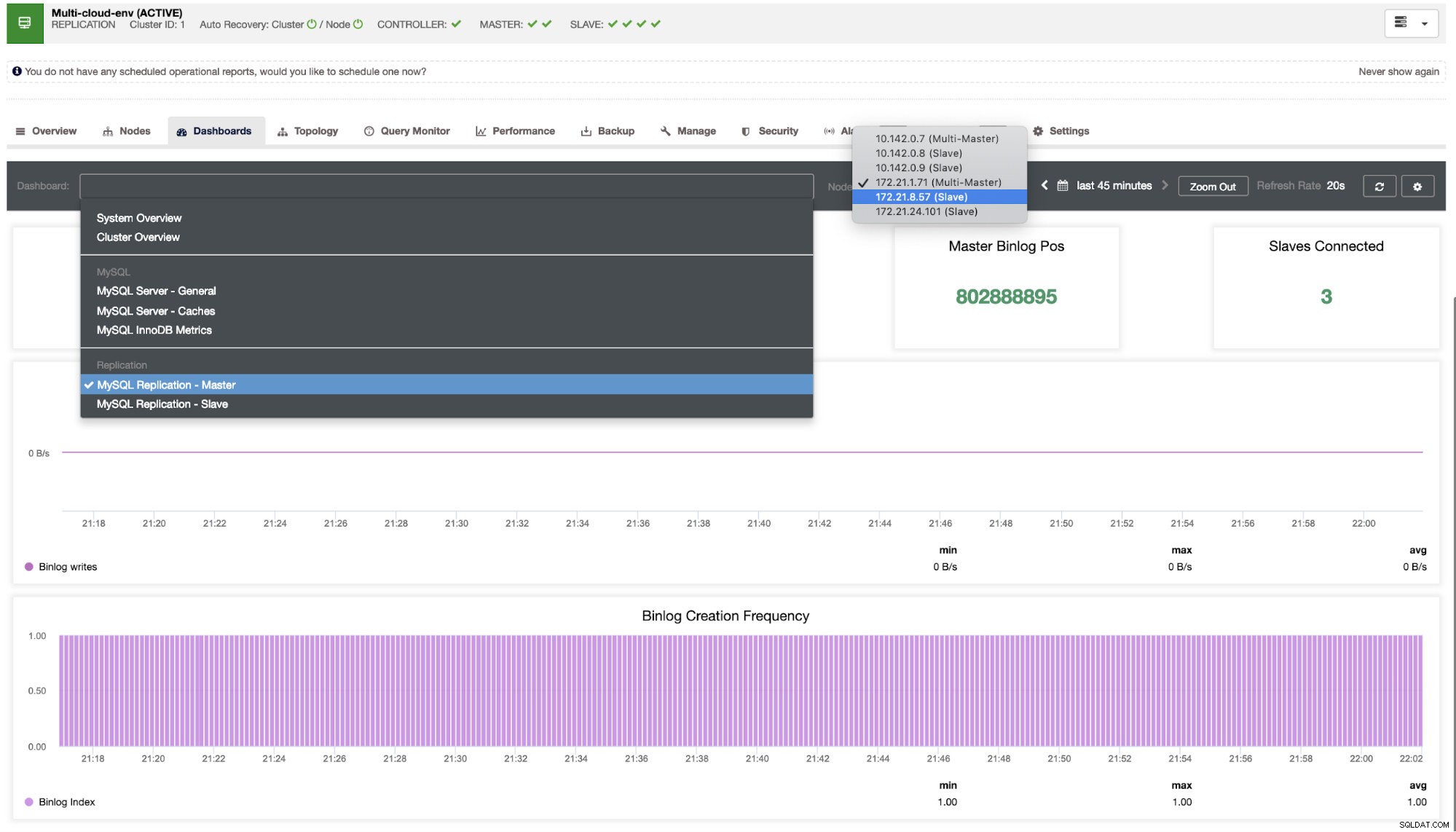
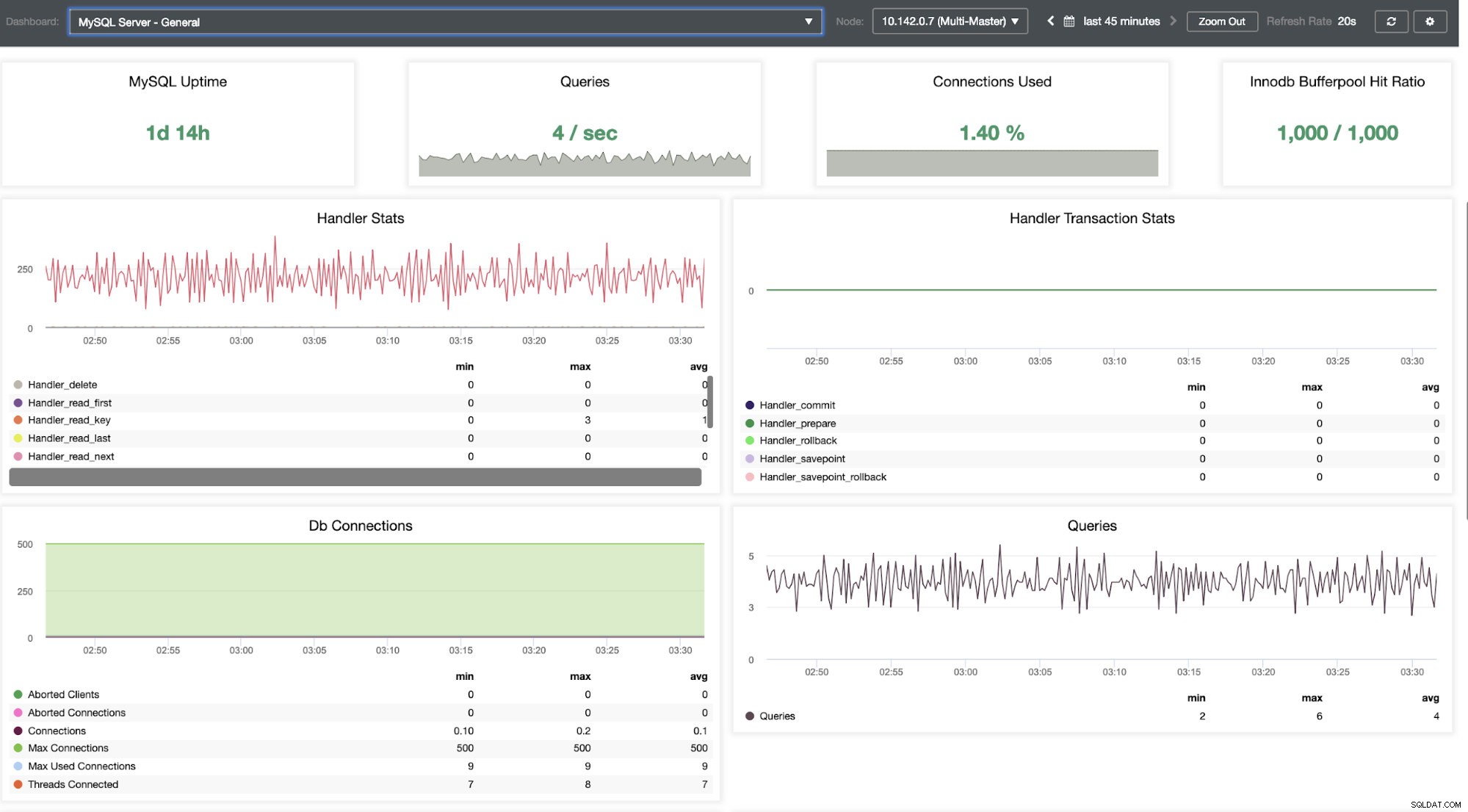
Ofrece una experiencia súper fluida en términos de monitoreo de sus nodos.
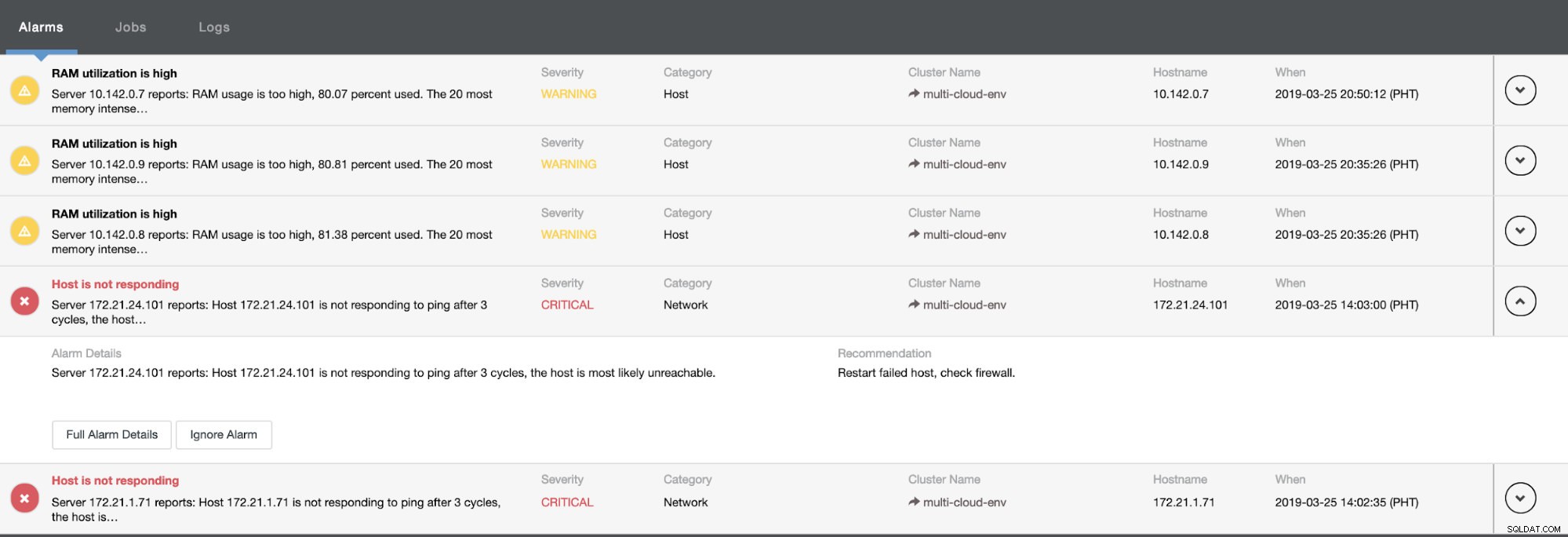
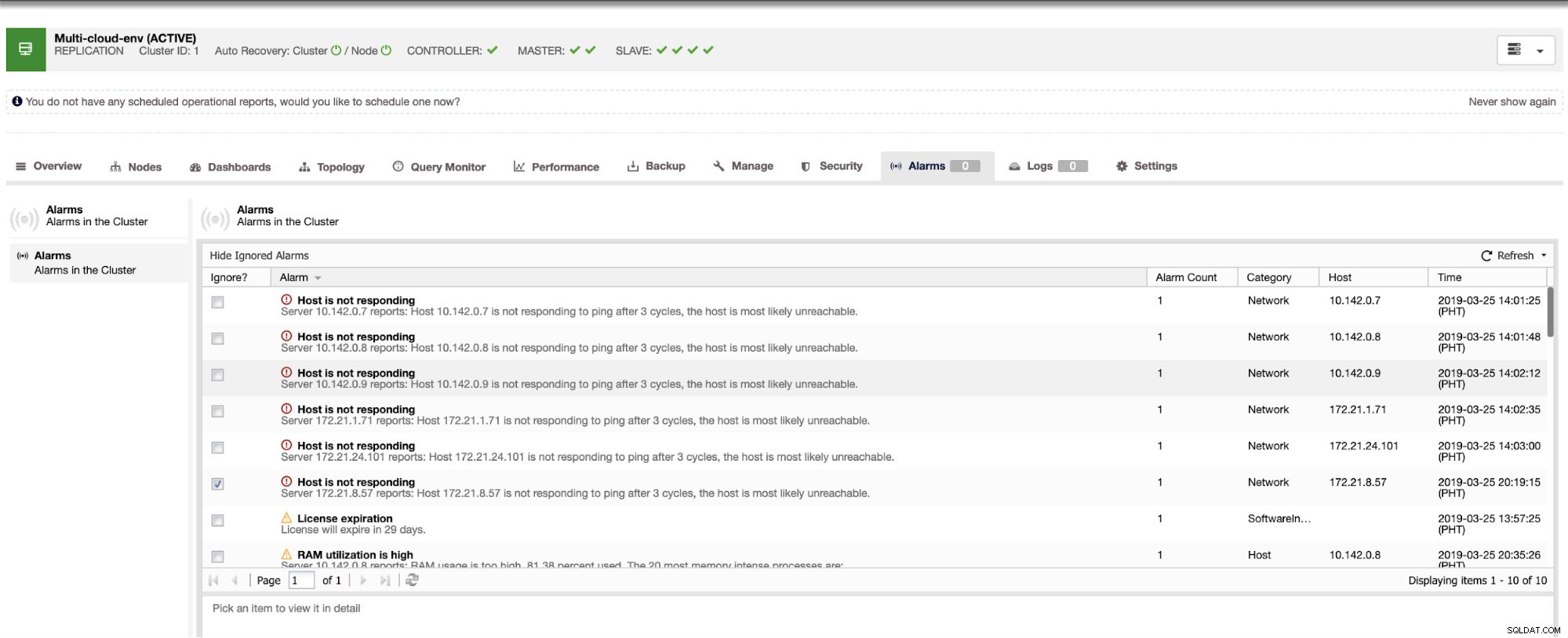
Nos dice que la utilización es alta o que el host no responde. Aunque esto fue solo un ping falla de respuesta, puede ignorar la alerta para evitar que la bombardee. Por lo tanto, puede "dejar de ignorarlo" si es necesario yendo a Clúster -> Alarmas en Clustercontrol. Ver a continuación:
Gestión de fallas y realización de conmutación por error
Digamos que el nodo maestro us-east1 falló o requiere una revisión importante debido a una actualización del sistema o del hardware. Digamos que esta es la topología en este momento (vea la imagen a continuación):
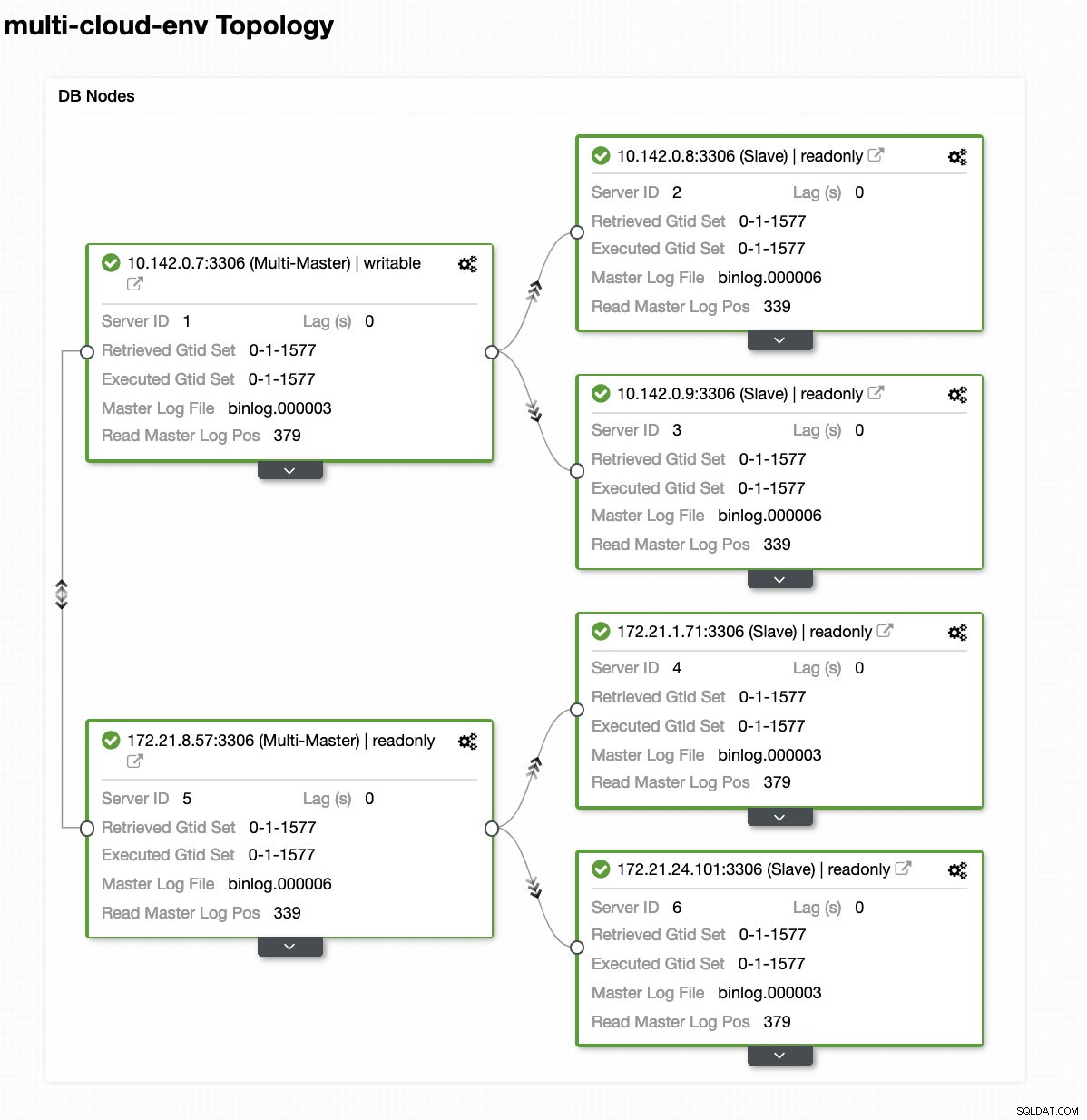
Intentemos apagar el host 10.142.0.7, que es el maestro en la región us-east1. Vea las capturas de pantalla a continuación sobre cómo reacciona ClusterControl ante esto:
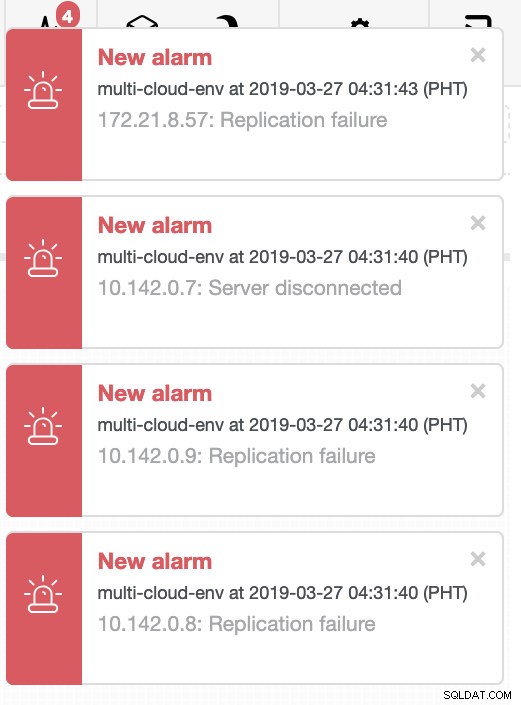
ClusterControl envía alarmas una vez que detecta anomalías en el clúster. Luego intenta hacer una conmutación por error a un nuevo maestro eligiendo el candidato correcto (ver imagen a continuación):

Luego, apartó el maestro fallido que ya se había sacado del clúster (vea la imagen a continuación):
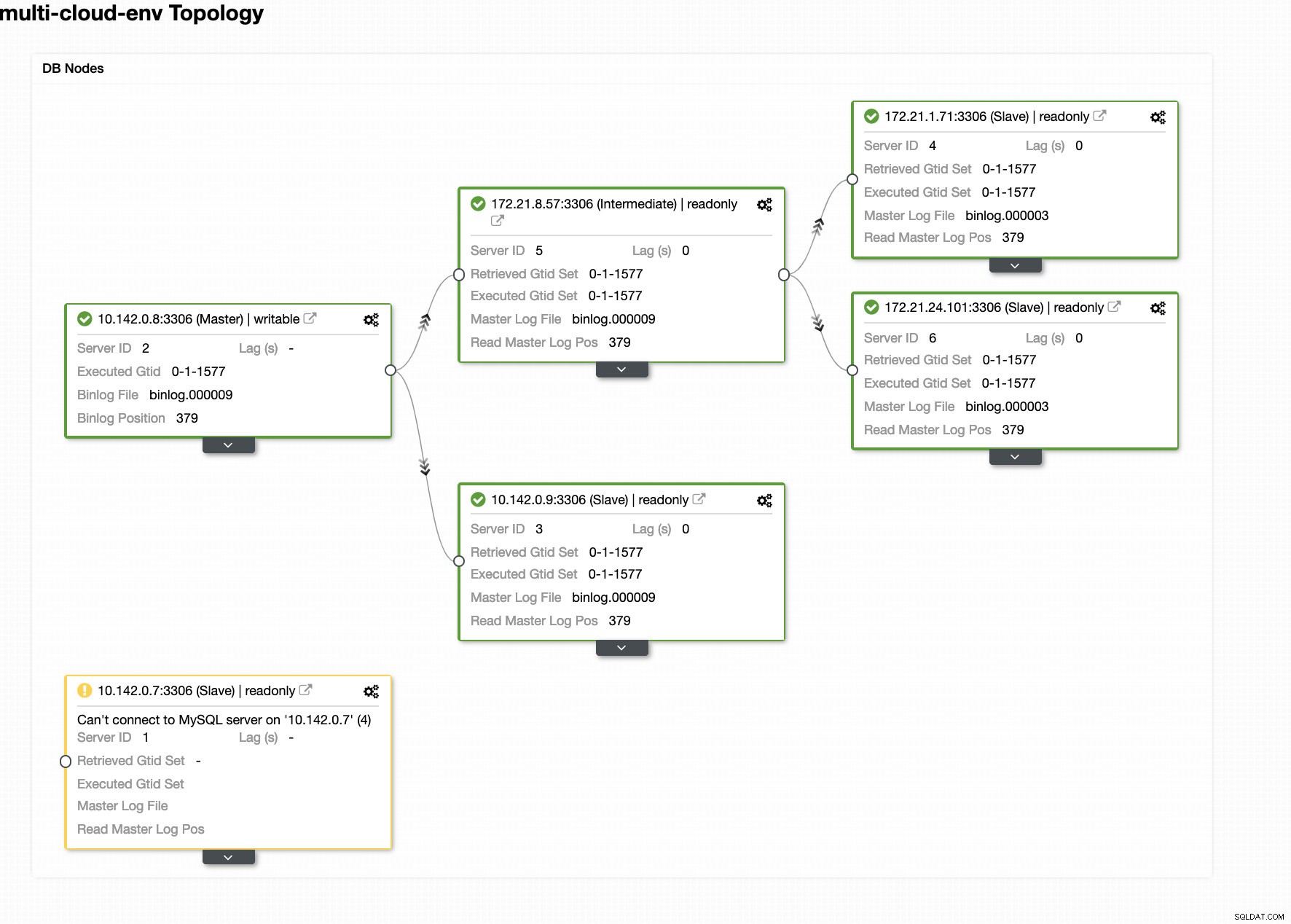
Esto es solo un vistazo de lo que puede hacer ClusterControl, hay otras funciones excelentes, como copias de seguridad, monitoreo de consultas, implementación/administración de balanceadores de carga, ¡y muchas más!
Conclusión
Administrar su configuración de replicación de MySQL en una nube múltiple puede ser complicado. Se debe tener mucho cuidado para asegurar nuestra configuración, por lo que esperamos que este blog brinde una idea sobre cómo definir subredes y proteger los nodos de la base de datos. Después de la seguridad, hay varias cosas que administrar y aquí es donde ClusterControl puede ser muy útil.
Pruébelo ahora y háganos saber cómo va. Puede ponerse en contacto con nosotros aquí en cualquier momento.