Antecedentes
Una de las primeras cosas que observo cuando estoy solucionando un problema de rendimiento son las estadísticas de espera a través del DMV sys.dm_os_wait_stats. Para ver qué está esperando SQL Server, utilizo la consulta del conjunto actual de consultas de diagnóstico de SQL Server de Glenn Berry. Según el resultado, empiezo a indagar en áreas específicas dentro de SQL Server.
Como ejemplo, si veo esperas altas de CXPACKET, compruebo la cantidad de núcleos en el servidor, la cantidad de nodos NUMA y los valores para el grado máximo de paralelismo y el umbral de costo para el paralelismo. Esta es la información de fondo que utilizo para comprender la configuración. Antes de siquiera considerar hacer cambios, reúno más datos cuantitativos, ya que un sistema con CXPACKET espera no necesariamente tiene una configuración incorrecta para el grado máximo de paralelismo.
De manera similar, un sistema que tiene muchas esperas para tipos de espera relacionados con E/S, como PAGEIOLATCH_XX, WRITELOG y IO_COMPLETION, no necesariamente tiene un subsistema de almacenamiento inferior. Cuando veo los tipos de espera relacionados con E/S como las esperas principales, inmediatamente quiero comprender más sobre el almacenamiento subyacente. ¿Es almacenamiento adjunto directo o una SAN? ¿Cuál es el nivel de RAID, cuántos discos existen en la matriz y cuál es la velocidad de los discos? También quiero saber si otros archivos o bases de datos comparten el almacenamiento. Y si bien es importante comprender la configuración, el siguiente paso lógico es observar las estadísticas de los archivos virtuales a través del DMV sys.dm_io_virtual_file_stats.
Introducido en SQL Server 2005, este DMV es un reemplazo para la función fn_virtualfilestats que aquellos de ustedes que ejecutaron SQL Server 2000 y versiones anteriores probablemente conocen y aman. El DMV contiene información de E/S acumulativa para cada archivo de base de datos, pero los datos se restablecen al reiniciar la instancia, cuando una base de datos se cierra, se desconecta, se desconecta y se vuelve a conectar, etc. Es fundamental comprender que los datos de estadísticas de archivos virtuales no son representativos de rendimiento:es una instantánea que es una agregación de datos de E/S desde el último borrado por uno de los eventos antes mencionados. Aunque los datos no son puntuales, aún pueden ser útiles. Si las esperas más altas para una instancia están relacionadas con E/S, pero el tiempo de espera promedio es inferior a 10 ms, el almacenamiento probablemente no sea un problema, pero vale la pena correlacionar la salida con lo que ve en sys.dm_io_virtual_stats para confirmar que es bajo. latencias. Además, incluso si ve latencias altas en sys.dm_io_virtual_stats, aún no ha demostrado que el almacenamiento sea un problema.
La configuración
Para ver las estadísticas de archivos virtuales, configuré dos copias de la base de datos AdventureWorks2012, que puede descargar desde Codeplex. Para la primera copia, en adelante conocida como EX_AdventureWorks2012, ejecuté el script de Jonathan Kehayias para expandir las tablas Sales.SalesOrderHeader y Sales.SalesOrderDetail a 1,2 millones y 4,9 millones de filas, respectivamente. Para la segunda base de datos, BIG_AdventureWorks2012, utilicé el script de mi anterior publicación de particiones para crear una copia de la tabla Sales.SalesOrderHeader con 123 millones de filas. Ambas bases de datos se almacenaron en una unidad USB externa (Seagate Slim 500GB), con tempdb en mi disco local (SSD).
Antes de la prueba, creé cuatro procedimientos almacenados personalizados en cada base de datos (Create_Custom_SPs.zip), que servirían como mi carga de trabajo "normal". Mi proceso de prueba fue el siguiente para cada base de datos:
- Reiniciar la instancia.
- Capturar estadísticas de archivos virtuales.
- Ejecute la carga de trabajo "normal" durante dos minutos (procedimientos llamados repetidamente a través de un script de PowerShell).
- Capturar estadísticas de archivos virtuales.
- Reconstruya todos los índices para las tablas SalesOrder correspondientes.
- Capturar estadísticas de archivos virtuales.
Los datos
Para capturar estadísticas de archivos virtuales, creé una tabla para contener información histórica y luego usé una variación de la consulta de Jimmy May de su guión DMV All-Stars para la instantánea:
USE [msdb];
GO
CREATE TABLE [dbo].[SQLskills_FileLatency]
(
[RowID] [INT] IDENTITY(1,1) NOT NULL,
[CaptureID] [INT] NOT NULL,
[CaptureDate] [DATETIME2](7) NULL,
[ReadLatency] [BIGINT] NULL,
[WriteLatency] [BIGINT] NULL,
[Latency] [BIGINT] NULL,
[AvgBPerRead] [BIGINT] NULL,
[AvgBPerWrite] [BIGINT] NULL,
[AvgBPerTransfer] [BIGINT] NULL,
[Drive] [NVARCHAR](2) NULL,
[DB] [NVARCHAR](128) NULL,
[database_id] [SMALLINT] NOT NULL,
[file_id] [SMALLINT] NOT NULL,
[sample_ms] [INT] NOT NULL,
[num_of_reads] [BIGINT] NOT NULL,
[num_of_bytes_read] [BIGINT] NOT NULL,
[io_stall_read_ms] [BIGINT] NOT NULL,
[num_of_writes] [BIGINT] NOT NULL,
[num_of_bytes_written] [BIGINT] NOT NULL,
[io_stall_write_ms] [BIGINT] NOT NULL,
[io_stall] [BIGINT] NOT NULL,
[size_on_disk_MB] [NUMERIC](25, 6) NULL,
[file_handle] [VARBINARY](8) NOT NULL,
[physical_name] [NVARCHAR](260) NOT NULL
) ON [PRIMARY];
GO
CREATE CLUSTERED INDEX CI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureDate], [RowID]);
CREATE NONCLUSTERED INDEX NCI_SQLskills_FileLatency ON [dbo].[SQLskills_FileLatency] ([CaptureID]);
DECLARE @CaptureID INT;
SELECT @CaptureID = MAX(CaptureID) FROM [msdb].[dbo].[SQLskills_FileLatency];
PRINT (@CaptureID);
IF @CaptureID IS NULL
BEGIN
SET @CaptureID = 1;
END
ELSE
BEGIN
SET @CaptureID = @CaptureID + 1;
END
INSERT INTO [msdb].[dbo].[SQLskills_FileLatency]
(
[CaptureID],
[CaptureDate],
[ReadLatency],
[WriteLatency],
[Latency],
[AvgBPerRead],
[AvgBPerWrite],
[AvgBPerTransfer],
[Drive],
[DB],
[database_id],
[file_id],
[sample_ms],
[num_of_reads],
[num_of_bytes_read],
[io_stall_read_ms],
[num_of_writes],
[num_of_bytes_written],
[io_stall_write_ms],
[io_stall],
[size_on_disk_MB],
[file_handle],
[physical_name]
)
SELECT
--virtual file latency
@CaptureID,
GETDATE(),
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([io_stall_read_ms]/[num_of_reads])
END [ReadLatency],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([io_stall_write_ms]/[num_of_writes])
END [WriteLatency],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE ([io_stall]/([num_of_reads] + [num_of_writes]))
END [Latency],
--avg bytes per IOP
CASE
WHEN [num_of_reads] = 0
THEN 0
ELSE ([num_of_bytes_read]/[num_of_reads])
END [AvgBPerRead],
CASE
WHEN [io_stall_write_ms] = 0
THEN 0
ELSE ([num_of_bytes_written]/[num_of_writes])
END [AvgBPerWrite],
CASE
WHEN ([num_of_reads] = 0 AND [num_of_writes] = 0)
THEN 0
ELSE (([num_of_bytes_read] + [num_of_bytes_written])/([num_of_reads] + [num_of_writes]))
END [AvgBPerTransfer],
LEFT([mf].[physical_name],2) [Drive],
DB_NAME([vfs].[database_id]) [DB],
[vfs].[database_id],
[vfs].[file_id],
[vfs].[sample_ms],
[vfs].[num_of_reads],
[vfs].[num_of_bytes_read],
[vfs].[io_stall_read_ms],
[vfs].[num_of_writes],
[vfs].[num_of_bytes_written],
[vfs].[io_stall_write_ms],
[vfs].[io_stall],
[vfs].[size_on_disk_bytes]/1024/1024. [size_on_disk_MB],
[vfs].[file_handle],
[mf].[physical_name]
FROM [sys].[dm_io_virtual_file_stats](NULL,NULL) AS vfs
JOIN [sys].[master_files] [mf]
ON [vfs].[database_id] = [mf].[database_id]
AND [vfs].[file_id] = [mf].[file_id]
ORDER BY [Latency] DESC; Reinicié la instancia e inmediatamente capturé las estadísticas del archivo. Cuando filtré la salida para ver solo los archivos de la base de datos EX_AdventureWorks2012 y tempdb, solo se capturaron los datos de tempdb ya que no se habían solicitado datos de la base de datos EX_AdventureWorks2012:

Resultado de la captura inicial de sys.dm_os_virtual_file_stats
Luego ejecuté la carga de trabajo "normal" durante dos minutos (la cantidad de ejecuciones de cada procedimiento almacenado varió levemente) y, después de completar, capturé las estadísticas del archivo nuevamente:

Resultado de sys.dm_os_virtual_file_stats después de la carga de trabajo normal
Vemos una latencia de 57 ms para el archivo de datos EX_AdventureWorks2012. No es lo ideal, pero con el tiempo y con mi carga de trabajo normal, esto probablemente se equilibraría. Hay una latencia mínima para tempdb, lo que se espera ya que la carga de trabajo que ejecuté no genera mucha actividad de tempdb. A continuación, reconstruí todos los índices para las tablas Sales.SalesOrderHeaderEnlarged y Sales.SalesOrderDetailEnlarged:
USE [EX_AdventureWorks2012]; GO ALTER INDEX ALL ON Sales.SalesOrderHeaderEnlarged REBUILD; ALTER INDEX ALL ON Sales.SalesOrderDetailEnlarged REBUILD;
Las reconstrucciones tardaron menos de un minuto y observe el pico en la latencia de lectura para el archivo de datos EX_AdventureWorks2012 y los picos en la latencia de escritura para los datos EX_AdventureWorks2012 y archivos de registro:

Resultado de sys.dm_os_virtual_file_stats después de la reconstrucción del índice
De acuerdo con esa instantánea de las estadísticas del archivo, la latencia es horrible; más de 600ms para escrituras! Si viera este valor para un sistema de producción, sería fácil sospechar de inmediato problemas con el almacenamiento. Sin embargo, también vale la pena señalar que AvgBPerWrite también aumentó, y las escrituras de bloques más grandes tardan más en completarse. Se espera el aumento de AvgBPerWrite para la tarea de reconstrucción del índice.
Comprenda que al mirar estos datos, no obtiene una imagen completa. Una mejor manera de ver las latencias usando estadísticas de archivos virtuales es tomar instantáneas y luego calcular la latencia para el período de tiempo transcurrido. Por ejemplo, el siguiente script usa dos instantáneas (actual y anterior) y luego calcula la cantidad de lecturas y escrituras en ese período de tiempo, la diferencia en los valores io_stall_read_ms y io_stall_write_ms, y luego divide el delta io_stall_read_ms por el número de lecturas, y el delta io_stall_write_ms por número de escrituras. Con este método, calculamos la cantidad de tiempo que SQL Server estuvo esperando en E/S para lecturas o escrituras, y luego lo dividimos por la cantidad de lecturas o escrituras para determinar la latencia.
DECLARE @CurrentID INT, @PreviousID INT; SET @CurrentID = 3; SET @PreviousID = @CurrentID - 1; WITH [p] AS ( SELECT [CaptureDate], [database_id], [file_id], [ReadLatency], [WriteLatency], [num_of_reads], [io_stall_read_ms], [num_of_writes], [io_stall_write_ms] FROM [msdb].[dbo].[SQLskills_FileLatency] WHERE [CaptureID] = @PreviousID ) SELECT [c].[CaptureDate] [CurrentCaptureDate], [p].[CaptureDate] [PreviousCaptureDate], DATEDIFF(MINUTE, [p].[CaptureDate], [c].[CaptureDate]) [MinBetweenCaptures], [c].[DB], [c].[physical_name], [c].[ReadLatency] [CurrentReadLatency], [p].[ReadLatency] [PreviousReadLatency], [c].[WriteLatency] [CurrentWriteLatency], [p].[WriteLatency] [PreviousWriteLatency], [c].[io_stall_read_ms]- [p].[io_stall_read_ms] [delta_io_stall_read], [c].[num_of_reads] - [p].[num_of_reads] [delta_num_of_reads], [c].[io_stall_write_ms] - [p].[io_stall_write_ms] [delta_io_stall_write], [c].[num_of_writes] - [p].[num_of_writes] [delta_num_of_writes], CASE WHEN ([c].[num_of_reads] - [p].[num_of_reads]) = 0 THEN NULL ELSE ([c].[io_stall_read_ms] - [p].[io_stall_read_ms])/([c].[num_of_reads] - [p].[num_of_reads]) END [IntervalReadLatency], CASE WHEN ([c].[num_of_writes] - [p].[num_of_writes]) = 0 THEN NULL ELSE ([c].[io_stall_write_ms] - [p].[io_stall_write_ms])/([c].[num_of_writes] - [p].[num_of_writes]) END [IntervalWriteLatency] FROM [msdb].[dbo].[SQLskills_FileLatency] [c] JOIN [p] ON [c].[database_id] = [p].[database_id] AND [c].[file_id] = [p].[file_id] WHERE [c].[CaptureID] = @CurrentID AND [c].[database_id] IN (2, 11);
Cuando ejecutamos esto para calcular la latencia durante la reconstrucción del índice, obtenemos lo siguiente:

Latencia calculada a partir de sys.dm_io_virtual_file_stats durante la reconstrucción del índice para EX_AdventureWorks2012
Ahora podemos ver que la latencia real durante ese tiempo fue alta, lo que cabría esperar. Y si luego volviéramos a nuestra carga de trabajo normal y la ejecutáramos durante algunas horas, los valores promedio calculados a partir de las estadísticas de archivos virtuales disminuirían con el tiempo. De hecho, si observamos los datos de PerfMon que se capturaron durante la prueba (y luego se procesaron a través de PAL), vemos picos significativos en el Promedio. Disco segundos/Lectura y Promedio. Disk sec/Write, que se correlaciona con la hora en que se ejecutó la reconstrucción del índice. Pero en otros momentos, los valores de latencia están muy por debajo de los valores aceptables:
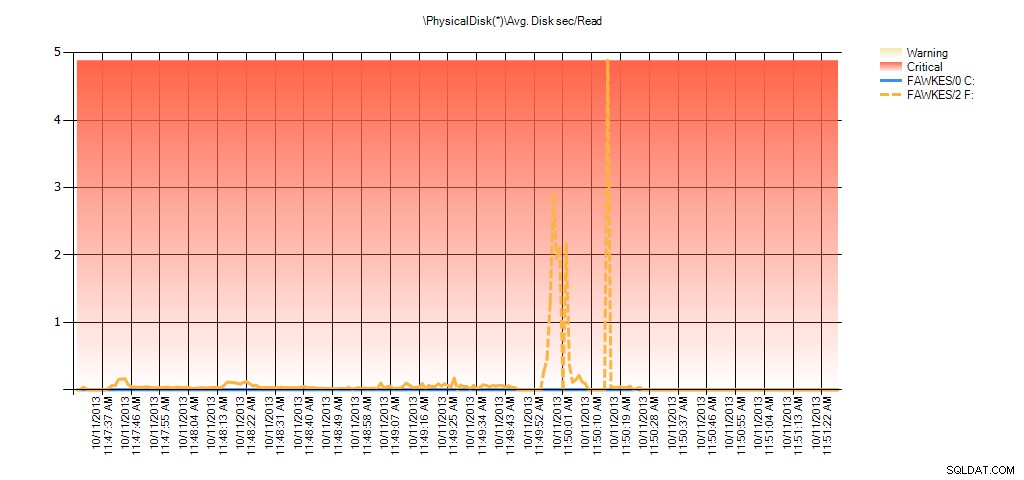
Resumen del promedio de segundos de disco/lectura de PAL para EX_AdventureWorks2012 durante la prueba
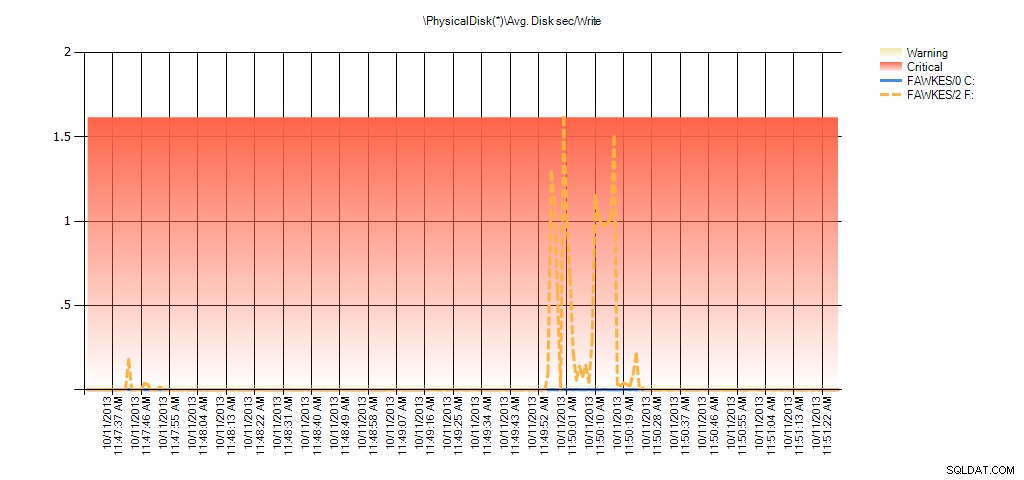
Resumen de Avg Disk Seg/Write de PAL para EX_AdventureWorks2012 durante la prueba
Puede ver el mismo comportamiento para la base de datos BIG_AdventureWorks 2012. Aquí está la información de latencia basada en la instantánea de estadísticas del archivo virtual antes de la reconstrucción del índice y después:

Latencia calculada a partir de sys.dm_io_virtual_file_stats durante la reconstrucción del índice para BIG_AdventureWorks2012
Y los datos del Monitor de rendimiento muestran los mismos picos durante la reconstrucción:
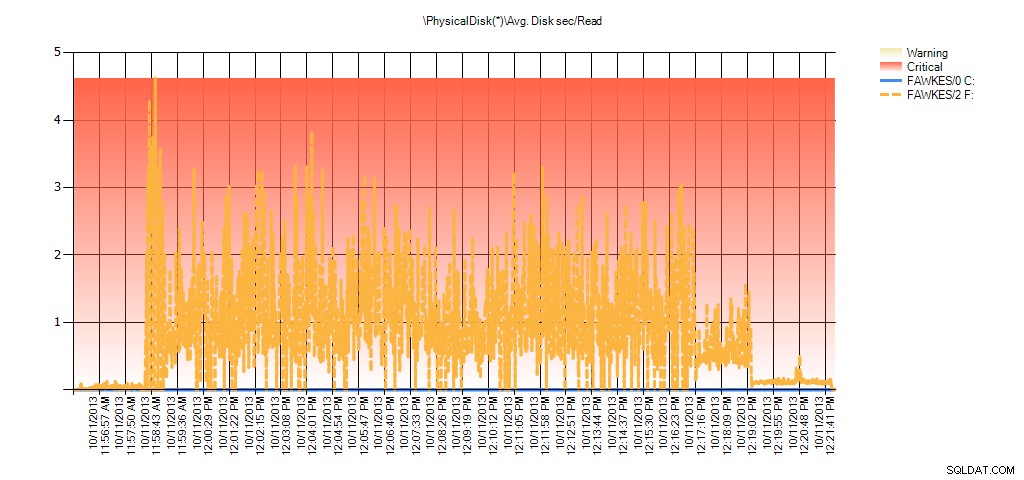
Resumen del promedio de segundos de disco/lectura de PAL para BIG_AdventureWorks2012 durante la prueba
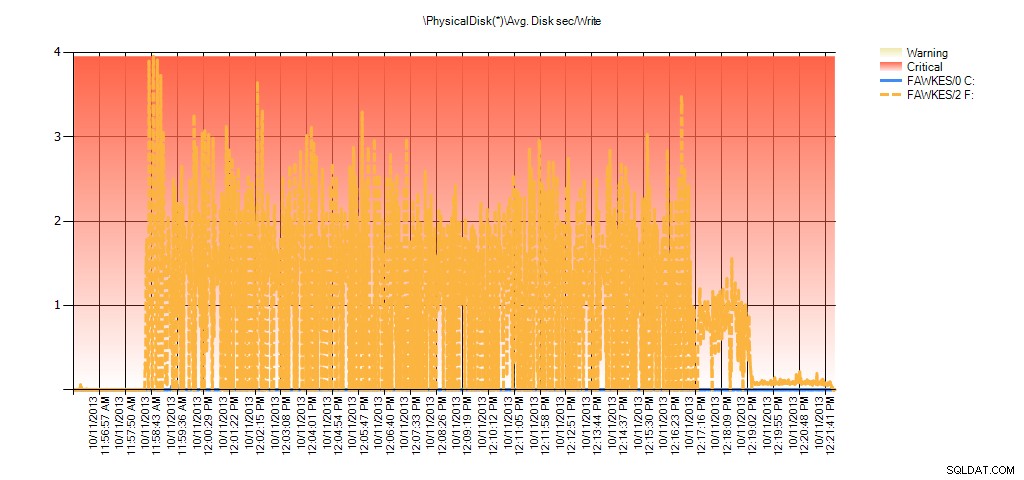
Resumen de Avg Disk Seg/Write de PAL para BIG_AdventureWorks2012 durante la prueba
Conclusión
Las estadísticas de archivos virtuales son un excelente punto de partida cuando desea comprender el rendimiento de E/S para una instancia de SQL Server. Si ve esperas relacionadas con E/S cuando mira las estadísticas de espera, mirar sys.dm_io_virtual_file_stats es el siguiente paso lógico. Sin embargo, comprenda que los datos que está viendo son un agregado desde la última vez que se borraron las estadísticas por uno de los eventos asociados (reinicio de instancia, fuera de línea de la base de datos, etc.). Si observa latencias bajas, el subsistema de E/S se mantiene al día con la carga de rendimiento. Sin embargo, si ve latencias altas, no es una conclusión inevitable que el almacenamiento sea un problema. Para saber realmente qué está pasando, puede comenzar a tomar una instantánea de las estadísticas del archivo, como se muestra aquí, o simplemente puede usar el Monitor de rendimiento para ver la latencia en tiempo real. Es muy fácil crear un conjunto de recopiladores de datos en PerfMon que capture los contadores de disco físico Promedio. Disco segundos/lectura y promedio. Disk Sec/Read para todos los discos que alojan archivos de bases de datos. Programe el recopilador de datos para que se inicie y se detenga de forma regular, y muestree cada n segundos (por ejemplo, 15), y una vez que haya capturado los datos de PerfMon durante un tiempo adecuado, ejecútelos a través de PAL para examinar la latencia a lo largo del tiempo.
Si encuentra que la latencia de E/S ocurre durante su carga de trabajo normal, y no solo durante las tareas de mantenimiento que impulsan las E/S, todavía no puede apuntar al almacenamiento como el problema subyacente. La latencia de almacenamiento puede existir por una variedad de razones, como:
- SQL Server tiene que leer demasiados datos como resultado de planes de consulta ineficientes o falta de índices
- Se asigna muy poca memoria a la instancia y se leen los mismos datos del disco una y otra vez porque no pueden permanecer en la memoria
- Las conversiones implícitas provocan exploraciones de índices o tablas
- Las consultas realizan SELECT * cuando no se requieren todas las columnas
- Los problemas de registros reenviados en montones causan E/S adicionales
- Las densidades de página bajas debido a la fragmentación del índice, las divisiones de página o la configuración incorrecta del factor de relleno provocan E/S adicionales
Cualquiera que sea la causa raíz, lo que es esencial comprender sobre el rendimiento, particularmente en lo que se refiere a E/S, es que rara vez hay un punto de datos que pueda usar para identificar el problema. Encontrar el verdadero problema requiere múltiples hechos que, cuando se juntan, lo ayudan a descubrir el problema.
Finalmente, tenga en cuenta que en algunos casos la latencia de almacenamiento puede ser completamente aceptable. Antes de exigir un almacenamiento más rápido o cambios en el código, revise los patrones de carga de trabajo y el Acuerdo de nivel de servicio (SLA) para la base de datos. En el caso de un almacén de datos que proporciona informes a los usuarios, el SLA para las consultas probablemente no sea el mismo valor de una fracción de segundo que esperaría para un sistema OLTP de gran volumen. En la solución DW, las latencias de E/S superiores a un segundo pueden ser perfectamente aceptables y esperadas. Comprenda las expectativas de la empresa y sus usuarios, y luego determine qué acción, si corresponde, tomar. Y si se requieren cambios, recopile los datos cuantitativos que necesita para respaldar su argumento, a saber, estadísticas de espera, estadísticas de archivos virtuales y latencias del Monitor de rendimiento.