La creciente demanda de sistemas de alta disponibilidad y SLA estrictos nos empuja a reemplazar los procedimientos manuales con soluciones automatizadas. Pero, ¿tiene el tiempo y los recursos necesarios para abordar la complejidad de las operaciones de conmutación por error por sí mismo? ¿Sacrificará el tiempo de inactividad de la base de datos de producción para aprenderlo de la manera difícil?
ClusterControl proporciona soporte avanzado para la detección y el manejo de fallas. Es utilizado por muchas organizaciones empresariales, manteniendo los sistemas de producción más críticos en funcionamiento las 24 horas del día, los 7 días de la semana.
Esta solución de administración de bases de datos también lo respalda con la implementación de diferentes proxies de carga. Estos proxies desempeñan un papel clave en la pila HA, por lo que no es necesario ajustar la cadena de conexión de la aplicación o la entrada de DNS para redirigir las conexiones de la aplicación al nuevo nodo maestro.
Cuando se detecta una falla, ClusterControl hace todo el trabajo en segundo plano para elegir un nuevo maestro, implementar servidores esclavos de conmutación por error y configurar balanceadores de carga. En este blog, aprenderá cómo lograr la conmutación por error automática de TimescaleDB en sus sistemas de producción.
Implementación de topologías de replicación completas
A partir de ClusterControl 1.7.2, puede implementar una configuración de replicación completa de TimescaleDB de la misma manera que implementaría PostgreSQL:puede usar el menú "Implementar clúster" para implementar un servidor principal y uno o más servidores de reserva de TimescaleDB. Veamos qué aspecto tiene.
Primero, debe definir los detalles de acceso al implementar nuevos clústeres mediante ClusterControl. Requiere acceso de contraseña raíz o sudo a todos los nodos en los que se implementará su nuevo clúster.
 ClusterControl:implementar un nuevo clúster
ClusterControl:implementar un nuevo clúster A continuación, debemos definir el usuario y la contraseña para el usuario de TimescaleDB.
 ClusterControl:implementar clúster de base de datos
ClusterControl:implementar clúster de base de datos Finalmente, desea definir la topología:qué host debe ser el principal y qué hosts deben configurarse como en espera. Mientras define los hosts en la topología, ClusterControl verificará si el acceso ssh funciona como se espera; esto le permite detectar cualquier problema de conectividad desde el principio. En la última pantalla, se le preguntará sobre el tipo de replicación síncrona o asíncrona.
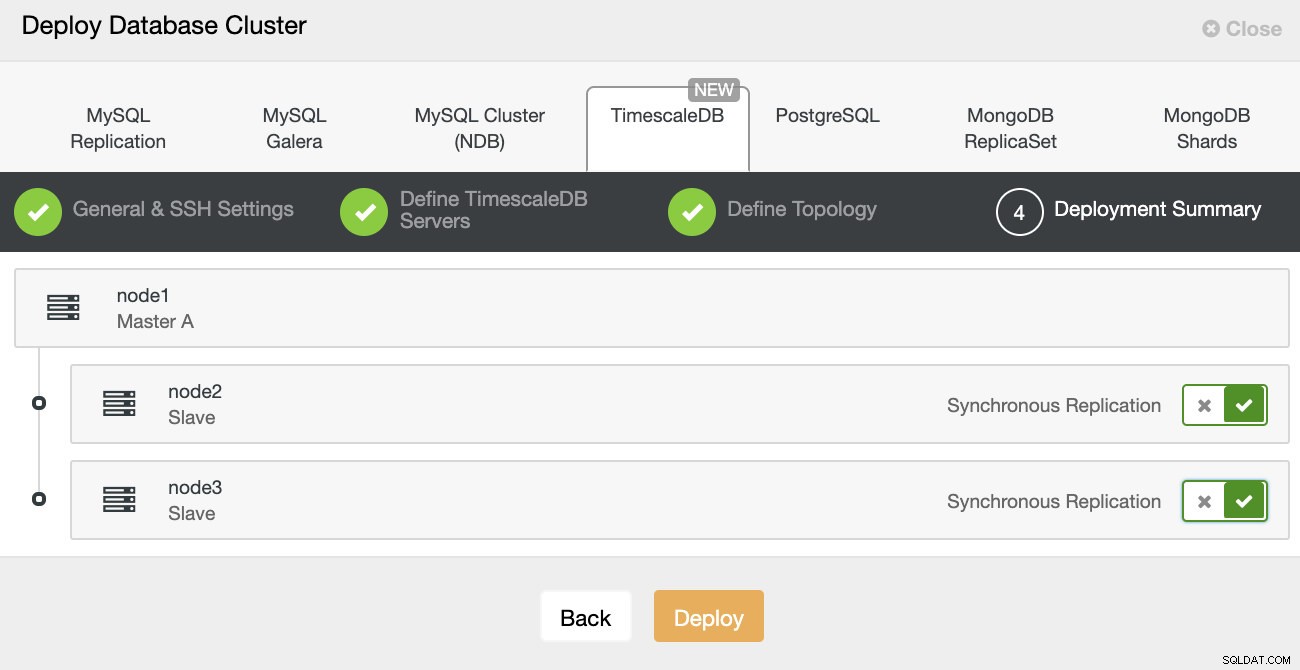 Despliegue de ClusterControl
Despliegue de ClusterControl Eso es todo, es cuestión de comenzar el despliegue. Se crea un trabajo en ClusterControl y podrá seguir el progreso.
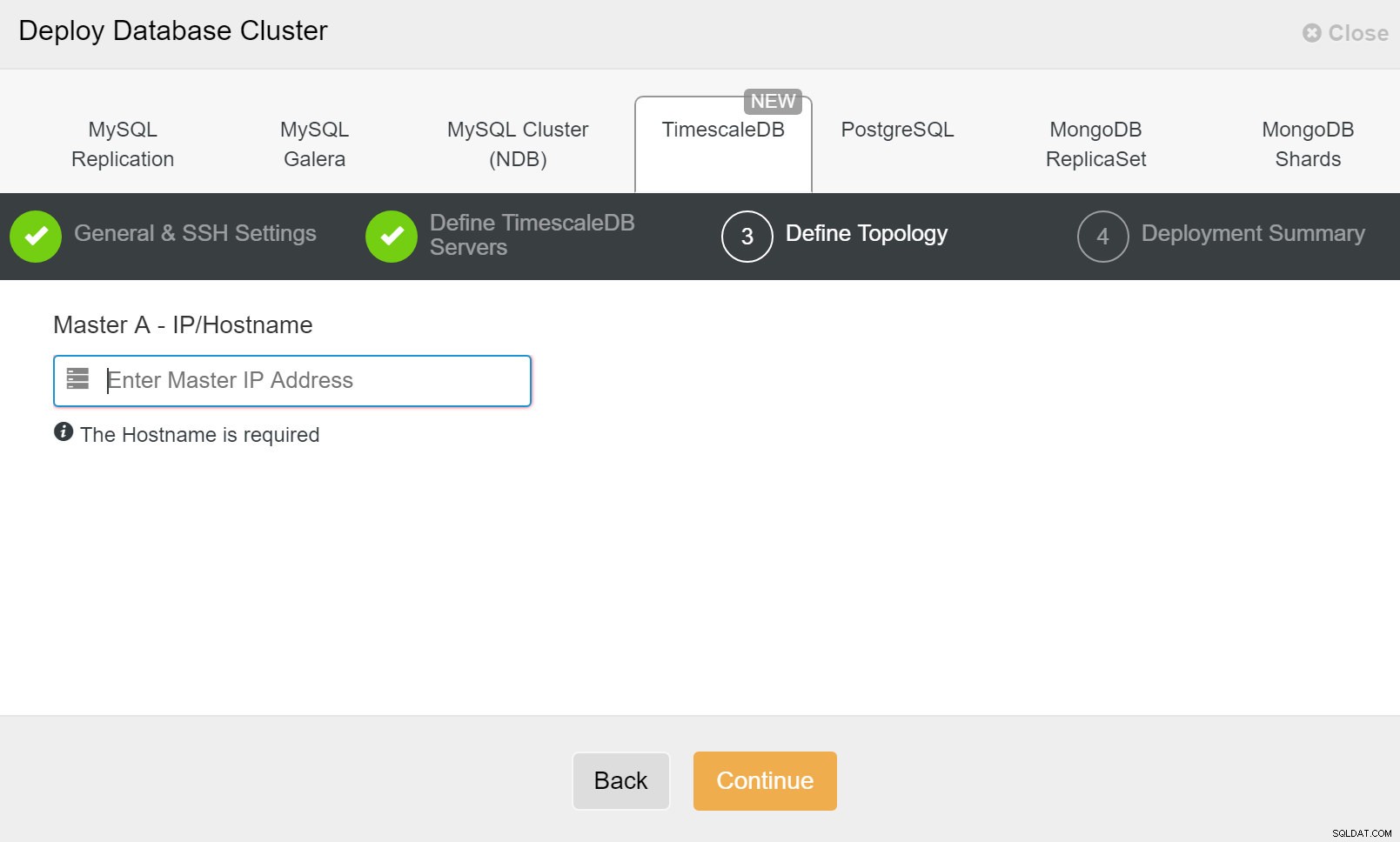 ClusterControl:definir la topología para el clúster de TimescleDb
ClusterControl:definir la topología para el clúster de TimescleDb Una vez que termine, verá la configuración de topología con roles en el clúster. Tenga en cuenta que también agregamos un balanceador de carga (HAProxy) delante de las instancias de la base de datos para que la conmutación por error automática no requiera cambios en la configuración de conexión de la base de datos.
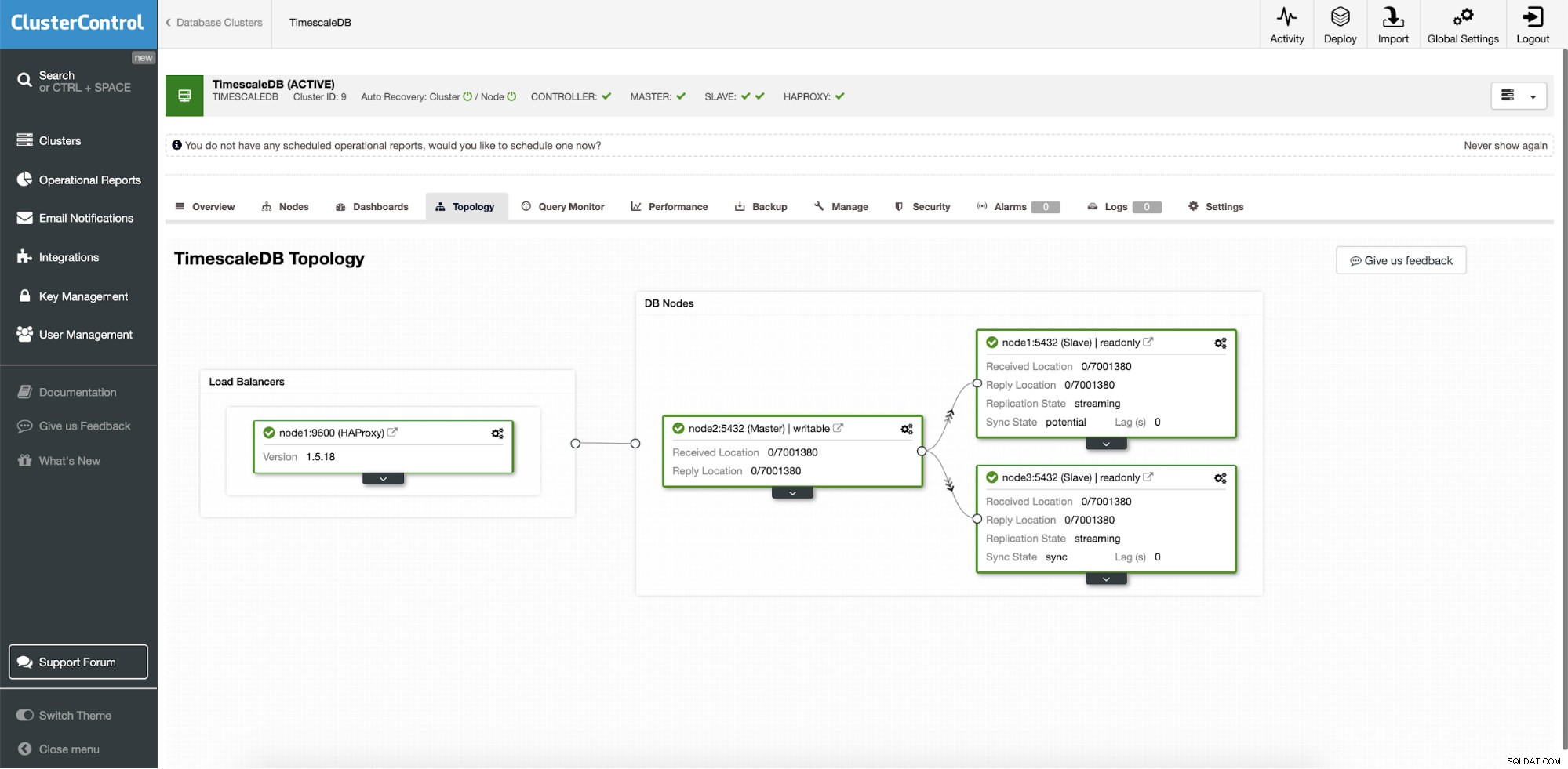 ClusterControl:Topología
ClusterControl:Topología Cuando ClusterControl implementa Timescale, la recuperación automática está habilitada de forma predeterminada. El estado se puede comprobar en la barra de herramientas.
 ClusterControl:clúster de recuperación automática y estado del nodo
ClusterControl:clúster de recuperación automática y estado del nodo Configuración de conmutación por error
Una vez que se implementa la configuración de replicación, ClusterControl puede monitorear la configuración y recuperar automáticamente cualquier servidor fallido. También puede orquestar cambios en la topología.
La conmutación por error automática de ClusterControl se diseñó con los siguientes principios:
- Asegúrese de que el maestro esté realmente inactivo antes de realizar la conmutación por error
- Conmutación por error solo una vez
- No realice la conmutación por error a un esclavo inconsistente
- Solo escribe al maestro
- No recupere automáticamente el maestro fallido
Con los algoritmos incorporados, la conmutación por error a menudo se puede realizar con bastante rapidez para que pueda garantizar los SLA más altos para su entorno de base de datos.
El proceso es configurable. Viene con múltiples parámetros que puede usar para adaptar la recuperación a las especificaciones de su entorno.
| max_replication_lag | Retraso de replicación máximo permitido en segundos antes |
| detención_de_replicación_en_error | Los procedimientos de conmutación por error/conmutación fallarán si se encuentran errores que pueden causar la pérdida de datos. Habilitado por defecto. 0 significa deshabilitar, |
| replicación_auto_reconstrucción_esclavo | Si se detiene SQL THREAD y el código de error no es cero, el esclavo se reconstruirá automáticamente. 1 significa habilitar, 0 significa deshabilitar (predeterminado). |
| replication_failover_blacklist | Lista separada por comas de pares de nombre de host:puerto. Los servidores incluidos en la lista negra no se considerarán candidatos durante la conmutación por error. replication_failover_blacklist se ignora si se establece replication_failover_whitelist. |
| replication_failover_whitelist | Lista separada por comas de pares de nombre de host:puerto. Solo los servidores incluidos en la lista blanca se considerarán candidatos durante la conmutación por error. Si ningún servidor en la lista blanca está disponible (activo/conectado), la conmutación por error fallará. replication_failover_blacklist se ignora si se establece replication_failover_whitelist. |
Manejo de conmutación por error
Cuando se detecta un fallo de maestro, se crea una lista de candidatos a maestro y se elige uno de ellos para que sea el nuevo maestro. Es posible tener una lista blanca de servidores para promocionar a principal, así como una lista negra de servidores que no pueden promocionarse a principal. Los esclavos restantes ahora son esclavos del nuevo primario y el antiguo primario no se reinicia.
A continuación podemos ver una simulación de falla de nodo.
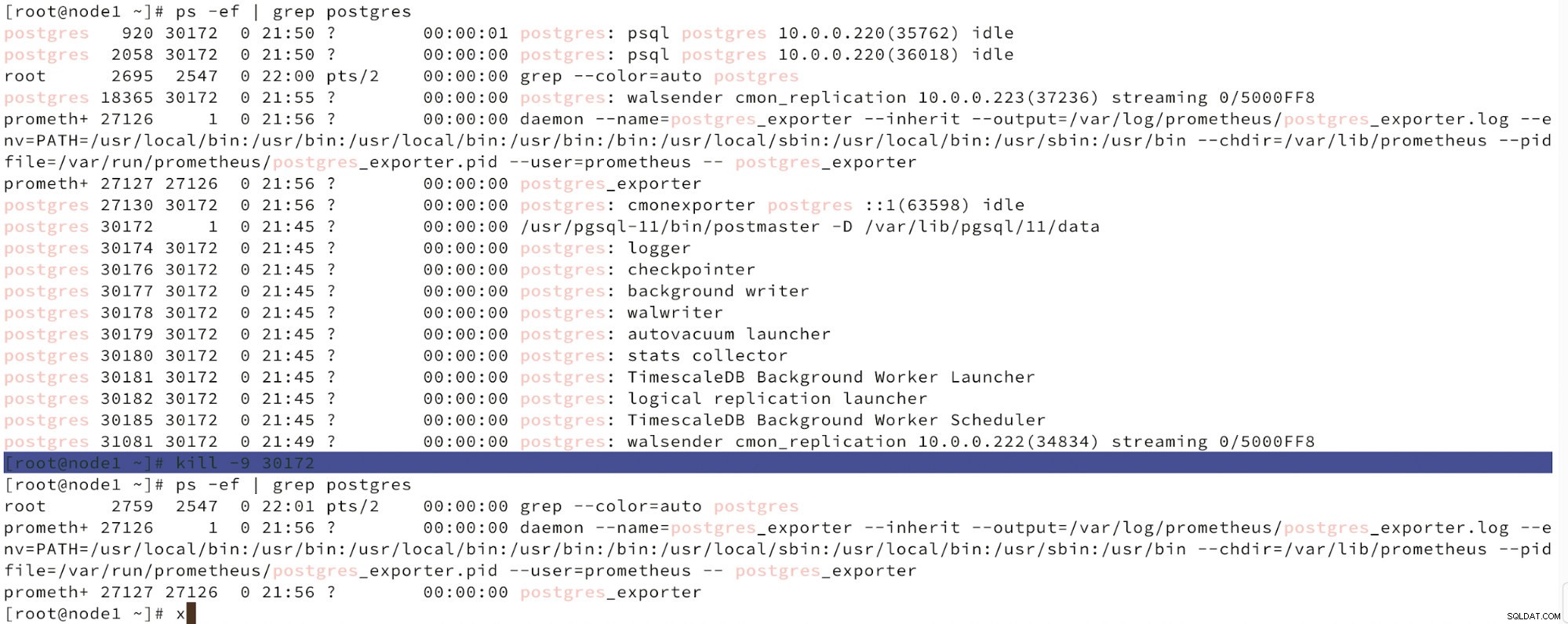 Simule la falla del nodo maestro con kill
Simule la falla del nodo maestro con kill Cuando se detecta un mal funcionamiento de los nodos y se detecta la recuperación automática, ClusterControl activa el trabajo para realizar la conmutación por error. A continuación podemos ver las acciones realizadas para recuperar el clúster.
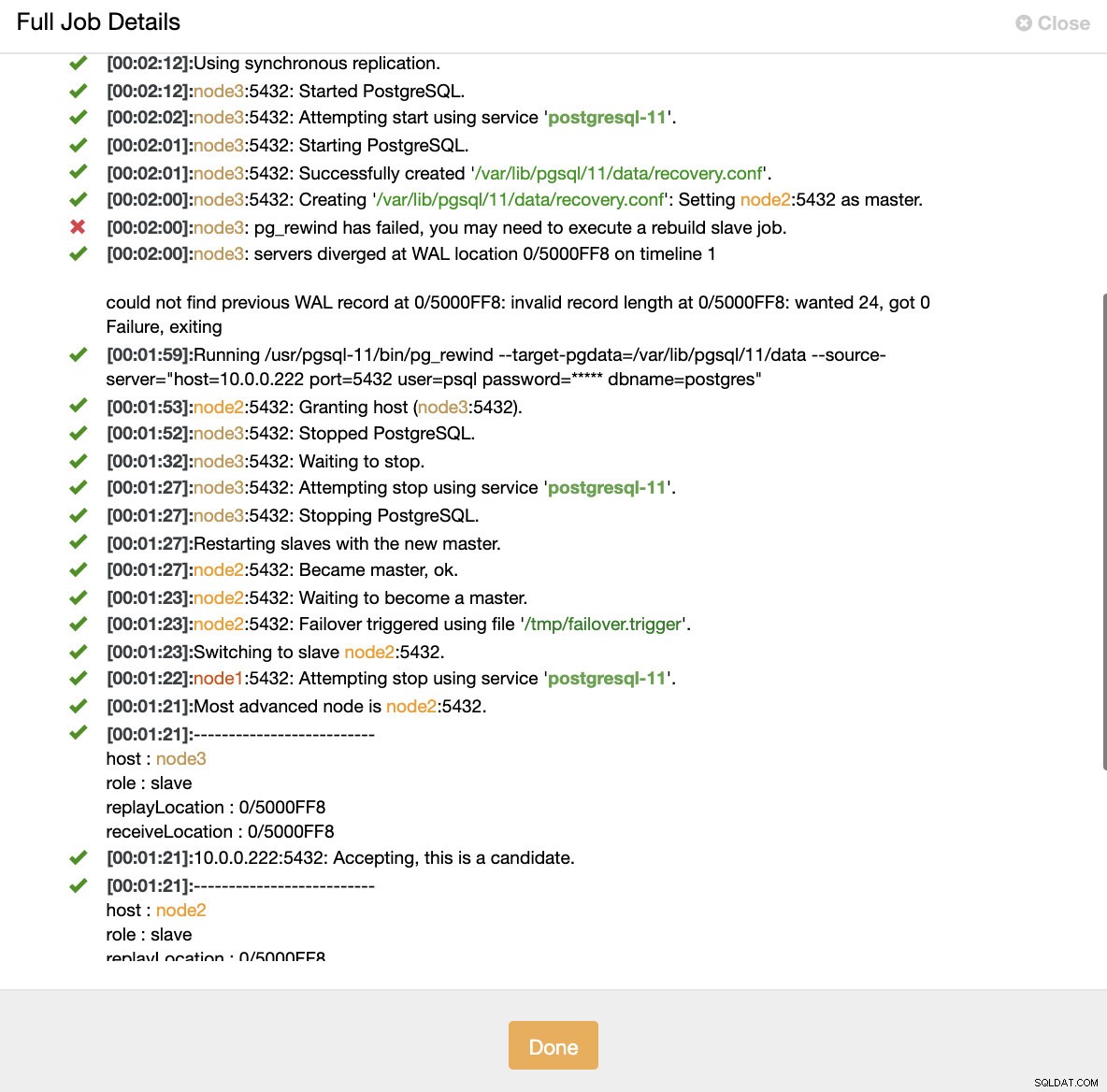 ClusterControl:trabajo activado para reconstruir el clúster
ClusterControl:trabajo activado para reconstruir el clúster ClusterControl mantiene intencionalmente fuera de línea el principal antiguo porque puede ocurrir que algunos de los datos no se hayan transferido a los servidores de reserva. En tal caso, el principal es el único host que contiene estos datos y es posible que desee recuperar los datos que faltan manualmente. Para aquellos que deseen que se reconstruya automáticamente el servidor principal fallido, hay una opción en el archivo de configuración de cmon:replication_auto_rebuild_slave. De manera predeterminada, está deshabilitado, pero cuando el usuario lo habilita, el principal fallido se reconstruirá como esclavo del nuevo principal. Por supuesto, si faltan datos que solo existen en el primario fallido, esos datos se perderán.
Reconstrucción de servidores en espera
La característica diferente es el trabajo "Reconstruir esclavo de replicación" que está disponible para todos los esclavos (o servidores en espera) en la configuración de replicación. Esto se debe usar, por ejemplo, cuando desee borrar los datos en el modo de espera y reconstruirlo nuevamente con una copia nueva de los datos del primario. Puede ser beneficioso si un servidor en espera no puede conectarse y replicarse desde el principal por algún motivo.
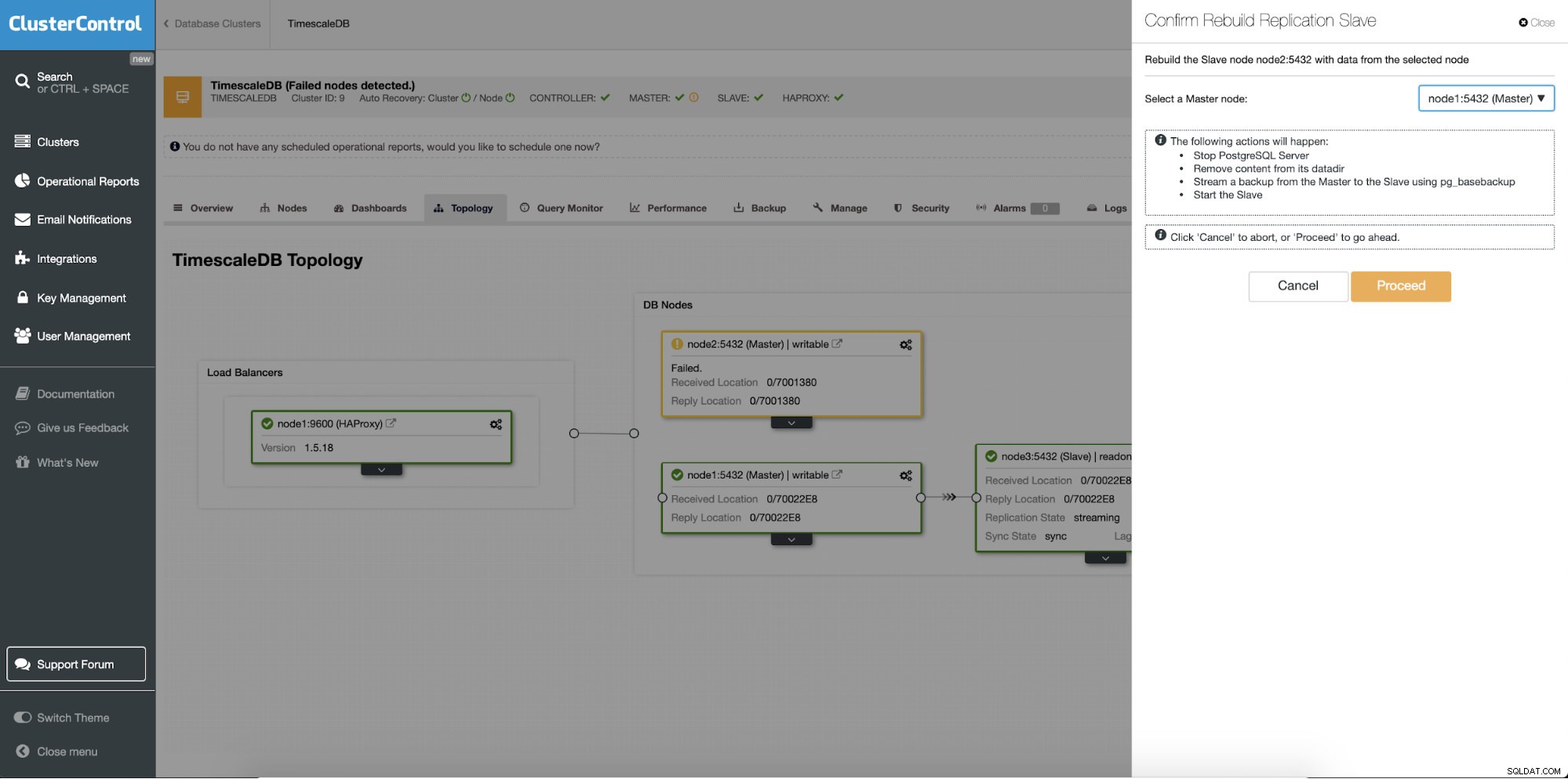 ClusterControl:reconstruir esclavo de replicación
ClusterControl:reconstruir esclavo de replicación 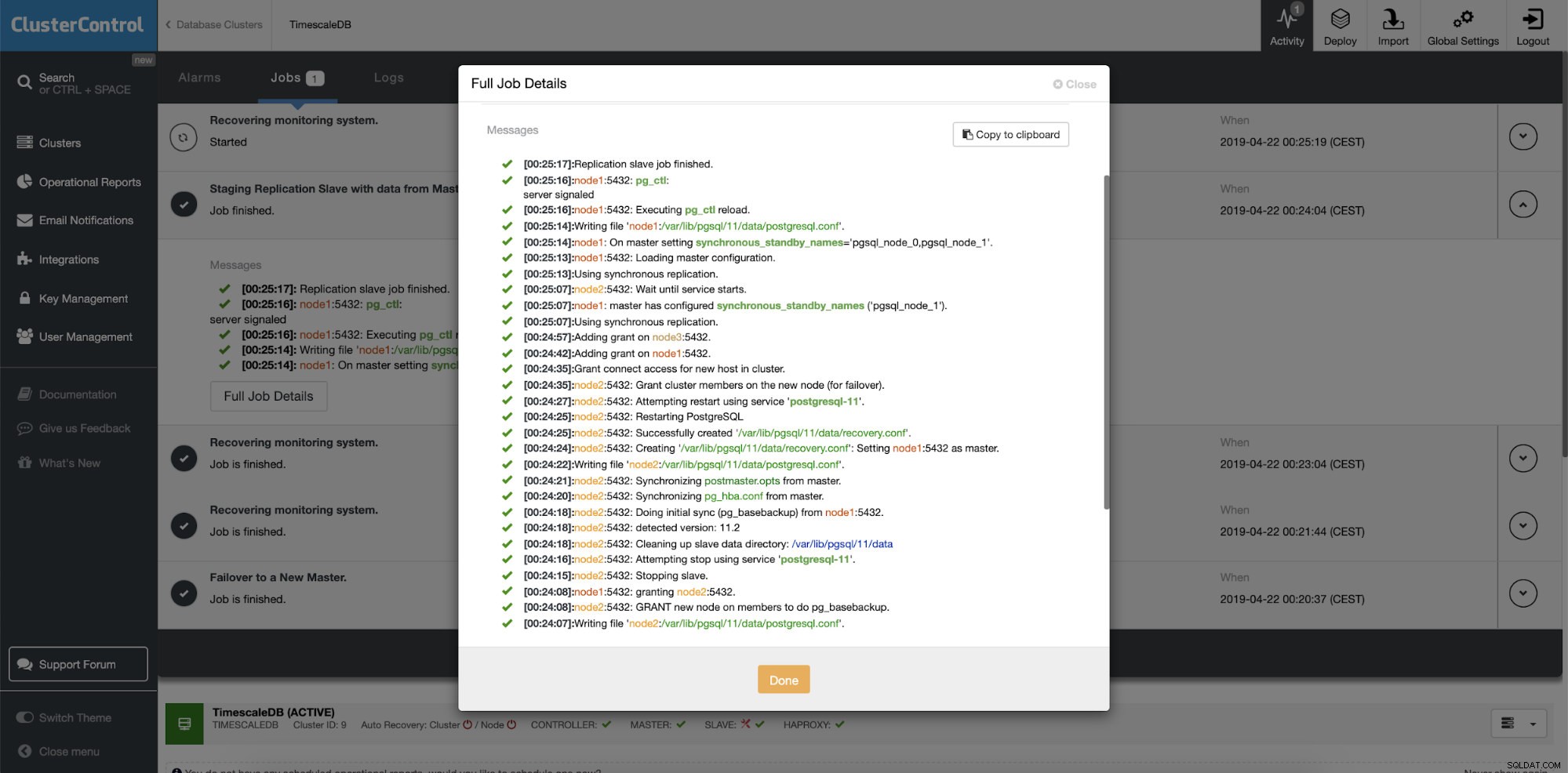 ClusterControl:reconstruir esclavo
ClusterControl:reconstruir esclavo