Un Sistema de Gestión de Base de Datos es la caja fuerte de la información. Intentaremos diseñar el Sistema de administración de la base de datos para que la base de datos permanezca bien administrada y cumpla con los propósitos.
En este artículo, vamos a discutir el diseño y la administración de sistemas de bases de datos de gran tamaño. Usaremos múltiples constituciones que incluirán tecnologías de base de datos, almacenamiento, distribución de datos, activos de servidor, patrón de arquitectura y algunos otros.
Preferiblemente, debemos buscar una base de datos de gran tamaño en el dominio de telecomunicaciones, plataformas de comercio electrónico, dominio de seguros, sistema bancario, sistema de salud, sistema de energía, etc. Debemos tener en cuenta algunos parámetros antes de elegir la tecnología de base de datos adecuada. es decir, tráfico, TPS (transacciones por segundo), almacenamiento estimado por día, HA y DR.
Diseñando una base de datos de gran tamaño
Mientras construimos nuestra base de datos, debemos prestar atención a varios parámetros porque a menudo es muy problemático cambiar la base de datos con un sustituto. Considerémoslos ahora.
Tecnología de base de datos
La tecnología de base de datos es el factor principal. Si elige el sistema de administración de base de datos correcto, ayudará a que su negocio funcione de manera eficiente y sin esfuerzo.
Hay varias tecnologías de base de datos con muchas características. Sin embargo, mientras trabaja con tecnologías de bases de datos de código abierto, es posible que no obtenga acceso a algunas funciones explícitas de soluciones predefinidas. Las tecnologías de bases de datos empresariales como Microsoft SQL Server, Oracle, etc. las proporcionarían.
Muchas tecnologías de bases de datos empresariales implementan HA (alta disponibilidad), DR (recuperación ante desastres), duplicación, replicación de datos, réplica de lectura secundaria y soluciones comerciales mucho más convenientes y configurables. Pueden o no estar presentes en las bases de datos de código abierto.
Hay muchas muchas razones. Por ejemplo, a veces encontramos que la arquitectura existente se está alterando porque los factores mencionados anteriormente no funcionan como los necesitamos.
Almacenamiento
El almacenamiento afecta drásticamente el rendimiento de la solución empresarial. Las soluciones comerciales requieren almacenamiento de primer nivel o SSD con una cierta cantidad de IOPS. Sin embargo, ¿es así? En las instalaciones o en la nube, el tamaño y el tipo de almacenamiento determinan los costos de infraestructura.
Al considerar el rendimiento del almacenamiento, debemos prestar atención al tipo de datos y al comportamiento del procesamiento de datos. Debemos optar por la selección del almacenamiento de acuerdo con los datos del usuario y el procesamiento de los mismos. Si el usuario va a utilizar varias bases de datos, debemos proporcionar la opción de almacenamiento sobre SAN para diferentes bases de datos para los tipos de datos y el comportamiento de procesamiento de datos.
El ingeniero de la base de datos proporcionará una mejor retrospección de las diversas bases de datos necesarias para el cálculo de IOPS si los usuarios no necesitan almacenamiento premium en absoluto.
Distribución de datos
La mayoría de las tecnologías de bases de datos recientes (SQL o NoSQL) ofrecen funciones de partición o fragmentación.
- La partición redistribuye los datos en el sistema de archivos que se basa en la clave de partición.
- La fragmentación distribuye información a través de los nodos de la base de datos y los datos se almacenarían en la misma máquina o en una diferente.
Fundamentalmente, cada servicio de base de datos o tabla de base de datos no requerirá las funciones de partición/fragmentación de datos. Solo requieren ser aplicados en bases de datos que contienen objetos de mayor tamaño. Eso mejorará el rendimiento.
Activos del servidor
Diferentes máquinas requieren diferentes tipos y tamaños de memoria y CPU. Debe considerar los activos a nivel de hardware, como la memoria, el procesador, etc. Por ejemplo, una máquina que tiene que manejar bases de datos más grandes o varias bases de datos necesitará más memoria y CPU. Por lo tanto, la calidad de la Memoria y el Procesador es significativa. Manejará diferentes tipos de procesadores disponibles en el mercado con diferentes cachés de CPU.
Muchas veces, nos encontramos con problemas de los que quizás no estemos al tanto. No prestamos atención a la utilización y el papel de la memoria caché de la CPU del hardware. Pero es crucial para seleccionar y cumplir con los requisitos de hardware con sistemas de bases de datos más grandes.
Patrón de arquitectura
En el diseño de bases de datos, el patrón de Arquitectura siempre tiene un papel ejemplar. Anteriormente, los sistemas de bases de datos se diseñaban de forma extremadamente monolítica. Ahora, usamos Micro-Servicio basado o Híbrido (Monolítico + Micro).
El rendimiento, la capacidad de expansión y el tiempo de inactividad cero dependen en gran medida del patrón de arquitectura y el diseño de la base de datos. Cada aplicación podría tener una base de datos separada, y todas las bases de datos podrían estar ligeramente acopladas entre sí. En caso de que alguna aplicación o base de datos se caiga, otra parte del producto no se verá afectada. Todos los microservicios serían independientes y se acoplarían libremente.
Microservicio
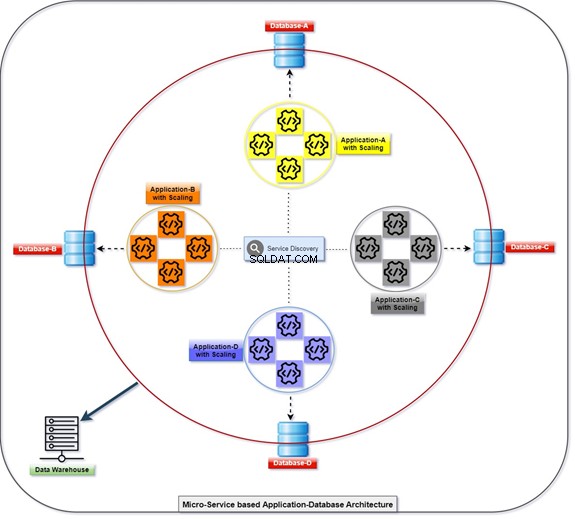
El siguiente diagrama explica cómo se implementan y se comunican todas las aplicaciones con la ayuda de sus bases de datos, que están débilmente acopladas al mismo tiempo. Podemos manipular los datos con T-SQL. La información será recopilada o acumulada por varias aplicaciones, y el cliente podrá acceder a los datos. Consulte el diagrama con el número de aplicaciones escaladas y su base de datos integrada.
Monolítico
¿Qué RDBMS deberíamos usar? Podría ser Oracle, Microsoft SQL Server, Postgres, MySQL, MongoDB o cualquier otra base de datos. La forma convencional de manejar todas las tablas u objetos administrados en una o varias bases de datos en un solo servidor se conoce como Monolítico.
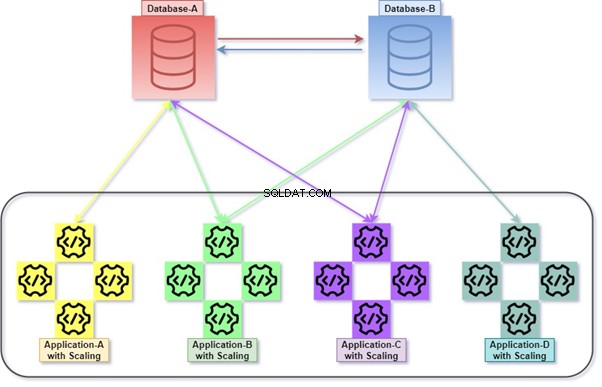
Híbrido
Hybrid es una permutación de Monolithic y Micro Service. Es una práctica bastante común, ya que permite numerosas aplicaciones, numerosas bases de datos y servidores de bases de datos. Numerosas bases de datos y servidores de bases de datos podrían acoplarse estrechamente entre sí.
Por ejemplo, consultar con JOINs entre tablas pertenecientes a dos o más bases de datos en el mismo servidor de base de datos o diferente. Consulta remota utilizada para la recuperación/manipulación de datos con otro servidor de base de datos.
Todo se trata de la arquitectura de SQL Server. Sin embargo, estamos hablando de la manipulación de datos entre diferentes tablas dentro de la misma base de datos o diferentes bases de datos que podrían residir en el mismo servidor o en diferentes servidores.
Ya sea en arquitectura Híbrida o Monolítica, usamos JOINs entre varias tablas dentro de la misma o diferentes bases de datos. Es bastante complejo cuando seguimos los estándares básicos de microservicios porque la distribución de las tablas puede ser entre los servicios de la base de datos (Dbas).
Bajo las tecnologías de bases de datos empresariales como Microsoft SQL Server, Oracle, etc., el usuario puede consultar las tablas de la base de datos distribuida con la ayuda de Linked Server Joins. Pero no está disponible en todas las tecnologías de bases de datos de código abierto. Se conoce como el enfoque de acoplamiento estrecho que podría no funcionar cuando el servicio de base de datos remota no está disponible.
Ahora, analicemos cómo hacerlo acoplado suelto. ¿Por qué necesitamos la manipulación de datos entre bases de datos remotas?
¿Por qué requerimos la manipulación de datos entre bases de datos remotas?
Los usuarios requerirán que los datos se recuperen de más de un servicio de base de datos cuando el sistema esté diseñado con la ayuda de Servicios Micro o Híbridos. Todo el proceso se ve desde el backend que puede manejar cantidades de datos manipulados por la aplicación.
Cuando observamos las consultas entre bases de datos en tiempo real, siempre unimos las tablas de entidades maestras, no las tablas de metadatos. Las tablas maestras no serán más grandes que las tablas de metadatos. A efectos de elaboración de informes, siempre utilizamos el almacén de datos para reunir toda la información. Pero eso no es fácil de administrar y mantener para cada producto. Si diseñamos la solución empresarial, podemos costear el almacén. Pero no nos lo podemos permitir para productos pequeños o medianos.
Por ejemplo, necesitamos un informe con los datos de varias tablas que residen en diferentes bases de datos. No es una tarea fácil de realizar, ya que recopila los datos utilizando diferentes microservicios y los fusiona para generar el informe. Por lo tanto, los datos necesarios deben sincronizarse.
Qué podemos usar como solución estándar Cómo realizar la sincronización de datos de tabla suelta entre dos bases de datos?
La replicación de tablas se debe utilizar para la sincronización de datos simple entre varias bases de datos. El ejemplo es la replicación de transacciones para la sincronización de datos simplex y la replicación de combinación para la sincronización de datos dúplex proporcionada por SQL Server.
Existen algunas soluciones pagas de terceros y de código abierto que pueden sincronizar los datos entre varias bases de datos. Incluso las soluciones sueltas con la ayuda de colas de mensajes como SQL Server Transaction Replication pueden ser desarrolladas por los usuarios por su cuenta.
Conclusión
Los DBA diseñan bases de datos a su manera. Al diseñar la base de datos y elegir el sistema de administración de la base de datos, deben tener en cuenta muchos aspectos. Presentamos los factores más esenciales para el diseño de la base de datos, especialmente para las bases de datos de mayor tamaño. ¡Estén atentos a los próximos materiales!