Una definición simple de la mediana es:
La mediana es el valor medio en una lista ordenada de númerosPara desarrollarlo un poco, podemos encontrar la mediana de una lista de números usando el siguiente procedimiento:
- Ordena los números (en orden ascendente o descendente, no importa cuál).
- El número del medio (por posición) en la lista ordenada es la mediana.
- Si hay dos números "igualmente medios", la mediana es el promedio de los dos valores medios.
Aaron Bertrand ha probado previamente el rendimiento de varias formas de calcular la mediana en SQL Server:
- ¿Cuál es la forma más rápida de calcular la mediana?
- Mejores enfoques para la mediana agrupada
Rob Farley agregó recientemente otro enfoque dirigido a las instalaciones anteriores a 2012:
- Medianas pre-SQL 2012
Este artículo presenta un nuevo método que utiliza un cursor dinámico.
El método OFFSET-FETCH de 2012
Comenzaremos analizando la implementación de mejor rendimiento, creada por Peter Larsson. Utiliza SQL Server 2012 OFFSET extensión al ORDER BY cláusula para ubicar eficientemente una o dos filas intermedias necesarias para calcular la mediana.
MEDIANA ÚNICA DE COMPENSACIÓN
El primer artículo de Aaron probó el cálculo de una única mediana en una tabla de diez millones de filas:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
La solución de Peter Larsson usando el OFFSET la extensión es:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); El código anterior codifica el resultado de contar las filas en la tabla. Todos los métodos probados para calcular la mediana necesitan este recuento para calcular los números de fila de la mediana, por lo que es un costo constante. Dejar la operación de conteo de filas fuera del tiempo evita una posible fuente de variación.
El plan de ejecución para el OFFSET la solución se muestra a continuación:

El operador Top salta rápidamente las filas innecesarias y pasa solo una o dos filas necesarias para calcular la mediana al agregado de flujo. Cuando se ejecuta con una recopilación de planes de ejecución y caché tibios desactivada, esta consulta se ejecuta durante 910 ms en promedio en mi computadora portátil. Esta es una máquina con un procesador Intel i7 740QM que funciona a 1,73 GHz con Turbo desactivado (para mantener la coherencia).
OFFSET Mediana agrupada
El segundo artículo de Aaron probó el rendimiento del cálculo de una mediana por grupo, utilizando una tabla Ventas de un millón de filas con diez mil entradas para cada uno de los cien vendedores:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Una vez más, la solución de mejor rendimiento utiliza OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); La parte importante del plan de ejecución se muestra a continuación:

La fila superior del plan se ocupa de encontrar el recuento de filas de grupo para cada vendedor. La fila inferior usa los mismos elementos del plan vistos para la solución de la mediana de un solo grupo para calcular la mediana de cada vendedor. Cuando se ejecuta con una caché tibia y planes de ejecución desactivados, esta consulta se ejecuta en 320 ms en promedio en mi computadora portátil.
Uso de un cursor dinámico
Puede parecer una locura siquiera pensar en usar un cursor para calcular la mediana. Los cursores de Transact SQL tienen una reputación (en su mayoría bien merecida) de ser lentos e ineficientes. También se suele pensar que los cursores dinámicos son el peor tipo de cursor. Estos puntos son válidos en algunas circunstancias, pero no siempre.
Los cursores de Transact SQL se limitan a procesar una sola fila a la vez, por lo que pueden ser lentos si es necesario recuperar y procesar muchas filas. Sin embargo, ese no es el caso para el cálculo de la mediana:todo lo que tenemos que hacer es ubicar y obtener uno o dos valores medios eficientemente . Un cursor dinámico es muy adecuado para esta tarea como veremos.
Cursor dinámico de mediana única
La solución de cursor dinámico para el cálculo de una única mediana consta de los siguientes pasos:
- Cree un cursor desplazable dinámico sobre la lista ordenada de elementos.
- Calcule la posición de la primera fila mediana.
- Cambie la posición del cursor usando
FETCH RELATIVE. - Decide si se necesita una segunda fila para calcular la mediana.
- Si no es así, devuelva el valor de la mediana única de inmediato.
- De lo contrario, busca el segundo valor usando
FETCH NEXT. - Calcule el promedio de los dos valores y devuélvalo.
Observe qué tan fielmente refleja esa lista el procedimiento simple para encontrar la mediana dado al comienzo de este artículo. A continuación se muestra una implementación completa del código Transact SQL:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
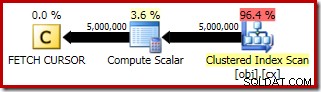
El plan de ejecución para FETCH RELATIVE La declaración muestra el cursor dinámico reposicionándose eficientemente a la primera fila requerida para el cálculo de la mediana:
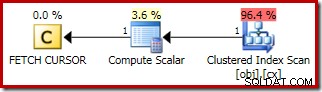
El plan para el FETCH NEXT (solo se requiere si hay una segunda fila en el medio, como en estas pruebas) es una búsqueda de una sola fila desde la posición guardada del cursor:
Las ventajas de usar un cursor dinámico aquí son:
- Evita recorrer todo el conjunto (la lectura se detiene después de encontrar las filas medianas); y
- No se realiza ninguna copia temporal de los datos en tempdb , como lo sería para un cursor estático o de conjunto de teclas.
Tenga en cuenta que no podemos especificar un FAST_FORWARD cursor aquí (dejando la elección de un plan estático o dinámico al optimizador) porque el cursor debe ser desplazable para admitir FETCH RELATIVE . Dynamic es la opción óptima aquí de todos modos.
Cuando se ejecuta con una recopilación de planes de ejecución y caché tibios desactivada, esta consulta se ejecuta durante 930 ms en promedio en mi máquina de prueba. Esto es un poco más lento que los 910 ms para el OFFSET solución, pero el cursor dinámico es significativamente más rápido que los otros métodos probados por Aaron y Rob, y no requiere SQL Server 2012 (o posterior).
No voy a repetir la prueba de los otros métodos anteriores a 2012 aquí, pero como ejemplo del tamaño de la brecha de rendimiento, la siguiente solución de numeración de filas toma 1550 ms en promedio (70% más lento):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Prueba de cursor dinámico de mediana agrupada
Es simple extender la solución de cursor dinámico de mediana única para calcular medianas agrupadas. En aras de la coherencia, voy a utilizar cursores anidados (sí, en serio):
- Abra un cursor estático sobre el personal de ventas y el recuento de filas.
- Calcule la mediana de cada persona usando un nuevo cursor dinámico cada vez.
- Guarde cada resultado en una variable de tabla a medida que avanzamos.
El código se muestra a continuación:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); El cursor exterior es deliberadamente estático porque se tocarán todas las filas de ese conjunto (además, un cursor dinámico no está disponible debido a la operación de agrupación en la consulta subyacente). Esta vez no hay nada particularmente nuevo o interesante que ver en los planes de ejecución.
Lo interesante es el rendimiento. A pesar de la creación y desasignación repetidas del cursor dinámico interno, esta solución funciona muy bien en el conjunto de datos de prueba. Con una caché tibia y planes de ejecución desactivados, la secuencia de comandos del cursor se completa en 330 ms. en promedio en mi máquina de prueba. Esto es nuevamente un poco más lento que los 320 ms registrado por el OFFSET mediana agrupada, pero supera a las otras soluciones estándar enumeradas en los artículos de Aaron y Rob por un amplio margen.
De nuevo, como ejemplo de la brecha de rendimiento con los otros métodos que no son de 2012, la siguiente solución de numeración de filas se ejecuta durante 485 ms en promedio en mi plataforma de prueba (50% peor):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Resumen de resultados
En la prueba de mediana única, el cursor dinámico se ejecutó durante 930 ms frente a 910 ms para el OFFSET método.
En la prueba de la mediana agrupada, el cursor anidado se ejecutó durante 330 ms frente a 320 ms para OFFSET .
En ambos casos, el método del cursor fue significativamente más rápido que los otros no OFFSET métodos. Si necesita calcular una mediana individual o agrupada en una instancia anterior a 2012, un cursor dinámico o un cursor anidado realmente podría ser la opción óptima.
Rendimiento de caché en frío
Algunos de ustedes pueden preguntarse sobre el rendimiento de la memoria caché en frío. Ejecutar lo siguiente antes de cada prueba:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Estos son los resultados de la prueba de la mediana única:
OFFSET método:940 ms
Cursor dinámico:955 ms
Para la mediana agrupada:
OFFSET método:380 ms
Cursores anidados:385 ms
Reflexiones finales
Las soluciones de cursor dinámico realmente son significativamente más rápidas que las que no son OFFSET métodos para medianas individuales y agrupadas, al menos con estos conjuntos de datos de muestra. Elegí deliberadamente reutilizar los datos de prueba de Aaron para que los conjuntos de datos no se desviaran intencionalmente hacia el cursor dinámico. podría Habría otras distribuciones de datos para las que el cursor dinámico no es una buena opción. Sin embargo, muestra que todavía hay momentos en los que un cursor puede ser una solución rápida y eficiente para el tipo correcto de problema. Incluso cursores dinámicos y anidados.
Los lectores con ojo de águila pueden haber notado el PAGLOCK pista en el OFFSET prueba de medianas agrupadas. Esto es necesario para un mejor rendimiento, por razones que trataré en mi próximo artículo. Sin él, la solución de 2012 en realidad pierde frente al cursor anidado por un margen decente (590ms frente a 330ms ).