Introducción
Averiguar qué tipo de infraestructura de base de datos necesita para cumplir con los requisitos de rendimiento, confiabilidad y escalabilidad de sus aplicaciones puede ser una tarea difícil. Las elecciones que haga para la topología de su base de datos pueden afectar la forma en que toda su pila de aplicaciones responde a diferentes tipos de uso y los escenarios de falla que puede tener en cuenta. Debido a esto, es importante comprender sus opciones y tomar una decisión informada que se alinee con sus objetivos.
Hay muchas maneras diferentes de pasar de una sola base de datos que maneja todas sus necesidades de infraestructura a sistemas más complejos. Junto con esto, hay muchas compensaciones a considerar.
En esta guía, presentaremos algunos de los patrones más comunes para la infraestructura de bases de datos relacionales y cómo se alinean con diferentes patrones de uso. Veremos las ventajas que ofrece cada configuración, así como algunas de las deficiencias que debe tener en cuenta. También hablaremos sobre el impacto de diferentes decisiones en la complejidad general de sus operaciones. Una vez que haya terminado, debería poder tomar una mejor decisión sobre qué diseños se adaptan mejor a sus necesidades actuales y qué opciones puede desear experimentar a medida que cambien sus necesidades.
Escalar verticalmente
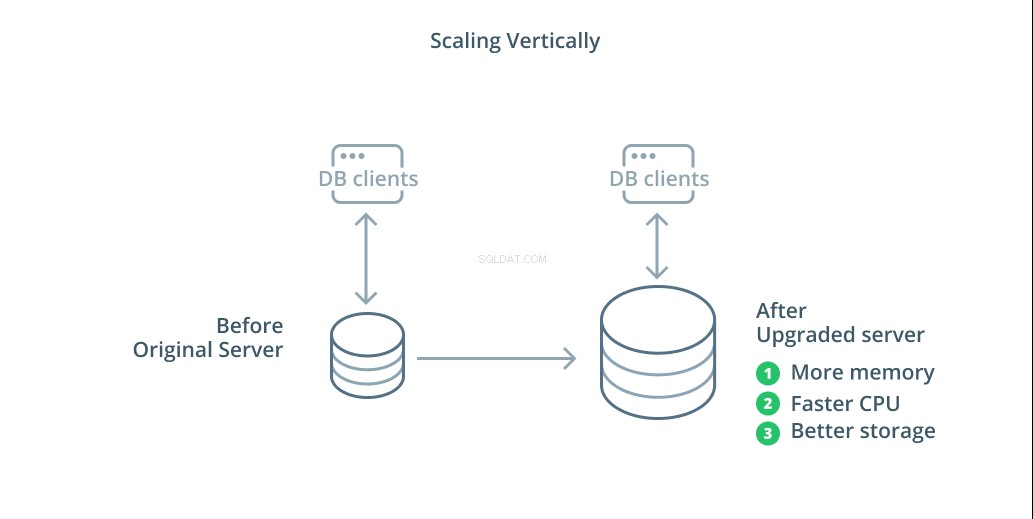
La forma más sencilla de escalar un sistema de base de datos es escalar verticalmente. Escalado verticalmente , también llamado ampliación , significa agregar capacidad al servidor que administra su base de datos. Al aumentar la potencia de procesamiento, la asignación de memoria o la capacidad de almacenamiento, puede aumentar el rendimiento y el volumen que puede manejar un sistema de base de datos sin aumentar la complejidad del sistema en su conjunto.
Como regla general, ampliar su base de datos es un buen primer paso, ya que aumenta las capacidades de su base de datos sin afectar la topología de su infraestructura. La ampliación también suele ser bastante simple, ya que una máquina de mayor capacidad se puede configurar como un seguidor de replicación hasta que se sincroniza y luego se puede activar una conmutación por error para convertirla en el nuevo servidor principal.
Sin embargo, la ampliación tiene sus limitaciones porque la cantidad de recursos que se pueden asignar razonablemente a una máquina está restringida. También representa un punto único de falla si no se configuran seguidores de replicación para tomar el control cuando ocurren problemas. Algunas de las otras opciones de escalado abordan estas preocupaciones.
Segregación de responsabilidad de consulta de comando (CQRS) y réplicas de solo lectura
La otra forma principal de escalar la infraestructura de su base de datos es escalar horizontalmente. Escalamiento horizontal significa que en lugar de aumentar la capacidad de un solo servidor, aumenta la cantidad de servidores dedicados a atender una necesidad específica. Por lo tanto, agrega capacidad agregando máquinas adicionales a su infraestructura.
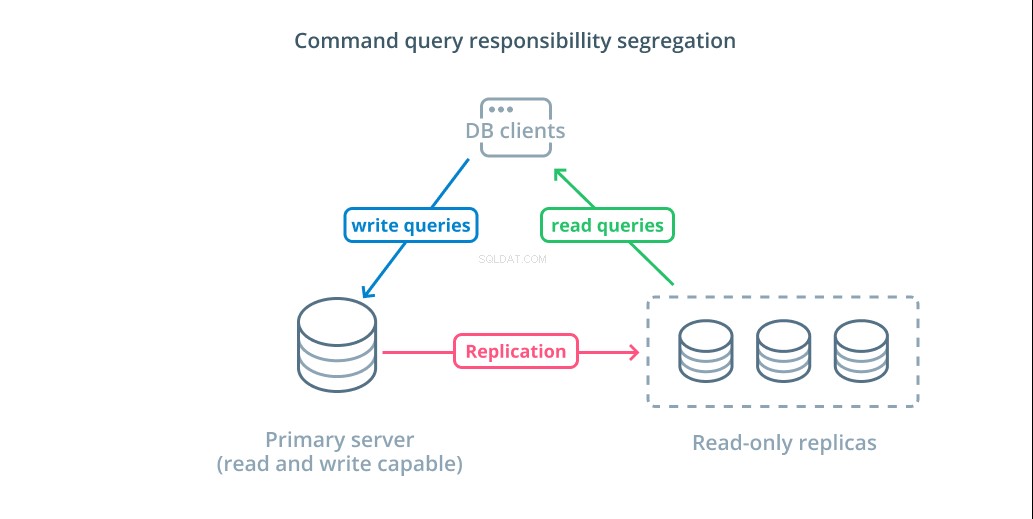
Segregación de responsabilidad de consultas de comando (CQRS) es un término que se usa para describir la adición de lógica para separar las consultas que mutan datos (consultas de escritura) de aquellas que no lo hacen (consultas de lectura). Esto le permite enrutar estas diferentes categorías de solicitudes a diferentes hosts para ayudar a distribuir la carga.
La infraestructura más básica para aprovechar este diseño es un servidor principal que puede aceptar consultas de lectura y escritura combinado con uno o más servidores réplica que siguen al servidor principal que puede aceptar consultas de lectura. Este diseño es apropiado para patrones de uso de aplicaciones que requieren mucha lectura, ya que cualquiera de los servidores de bases de datos puede manejar las operaciones de lectura.
Además, este sistema proporciona cierta redundancia a su arquitectura, ya que el sistema seguirá funcionando si alguno de los servidores deja de funcionar. Si un seguidor deja de funcionar, las solicitudes de lectura se pueden enrutar a los otros servidores. Si el servidor principal deja de funcionar, uno de los seguidores de réplica puede ser promovido para aceptar consultas de escritura.
Replicación multiprimaria
Si bien el uso de CQRS con réplicas de solo lectura lo ayuda a abordar una mayor cantidad de solicitudes de lectura, no afecta significativamente el rendimiento de escritura de su infraestructura. Para aumentar la cantidad de escrituras que su arquitectura puede manejar, debe considerar si puede adoptar un diseño de replicación principal múltiple.
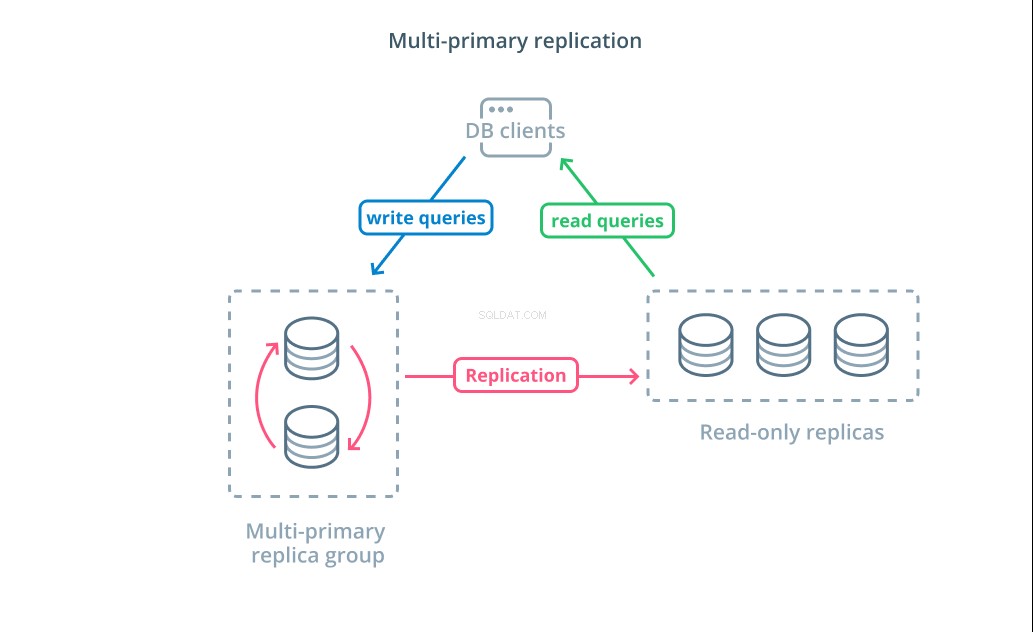
Replicación primaria múltiple es una forma de replicación en la que varios servidores pueden aceptar solicitudes de escritura. Algunos sistemas están configurados para que cualquier servidor pueda procesar solicitudes de escritura, mientras que otros están diseñados para que un grupo central de servidores primarios maneje las escrituras con una mayor cantidad de seguidores de solo lectura. Independientemente de la implementación, la replicación principal múltiple aumenta la cantidad de servidores responsables de las consultas de escritura.
Si bien este diseño suena ideal al principio, existen algunos desafíos importantes que impiden que este sea un patrón ampliamente adoptado. Si bien varios servidores pueden manejar solicitudes de escritura, aún deben coordinarse para replicar cambios entre sus servidores y resolver conflictos en los cambios de datos. Esto puede conducir a tiempos de respuesta prolongados a medida que se negocian conflictos o la posibilidad de datos inconsistentes.
Cada sistema elige su propio enfoque para manejar estos desafíos. Esta es una demostración del Teorema CAP — una declaración que describe la interacción entre consistencia, disponibilidad y tolerancia de partición en sistemas distribuidos — en acción. Algunos sistemas ofrecen garantías de coherencia más débiles para mantener la disponibilidad, mientras que otras bases de datos se niegan a aceptar cambios si sus pares no pueden coordinar la transacción en el momento de la escritura. Elegir el enfoque que mejor se adapte a sus necesidades es un factor importante al decidir entre varias implementaciones.
Leer almacenamiento en caché de consultas
Si bien el uso de réplicas de solo lectura es una forma de aumentar las bases de datos disponibles que pueden responder a las solicitudes de lectura, no mejora el rendimiento básico de las consultas de las operaciones de lectura complejas. Todavía se espera que uno de los servidores ejecute la operación de lectura cada vez que se realiza una solicitud, incluso si los resultados son idénticos a la búsqueda anterior.
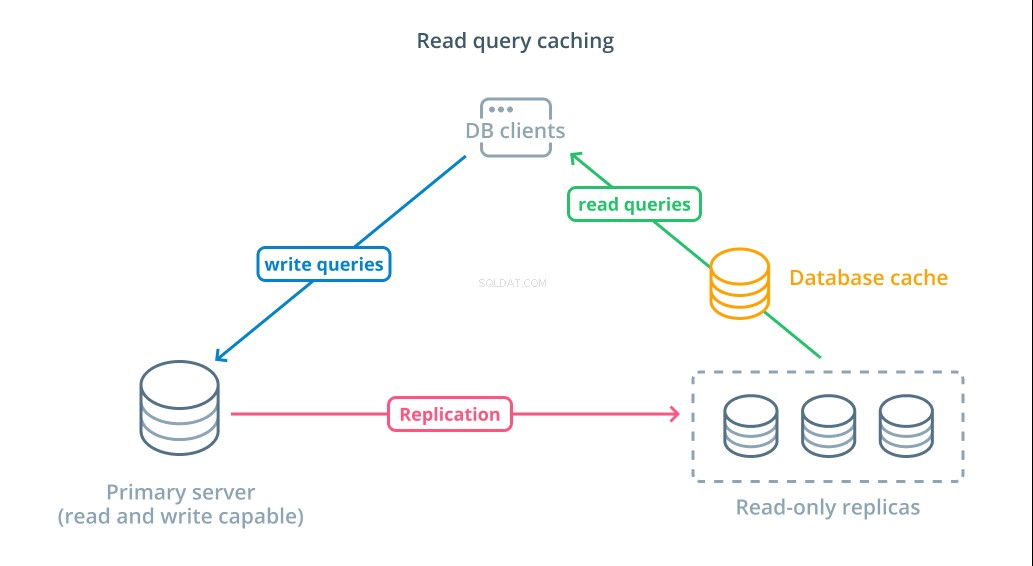
Para disminuir los tiempos de respuesta, un almacenamiento en caché de consultas de lectura Se puede introducir una capa. Agregar un caché entre los clientes de su base de datos y las propias bases de datos puede reducir significativamente el tiempo de consulta para solicitudes comunes. La aplicación puede solicitar resultados de lectura del caché y recibirlos casi de inmediato si están disponibles. Para los casos en los que los resultados no se encuentran en la memoria caché, se obtienen de la base de datos y se agregan a la memoria caché para la próxima vez.
Configurar el almacenamiento en caché de esta manera es increíblemente eficiente para escenarios en los que no es probable que los datos cambien cada vez que se realiza la solicitud. Es especialmente útil para consultas de lectura costosas que consultan varias tablas e incluyen operaciones de combinación complejas. Estos resultados pueden ejecutarse una vez y luego guardarse para futuras consultas.
En los casos en que los datos cambian más rápidamente, es posible que una caché de lectura no ayude tanto. Dependiendo del comportamiento configurado, los cachés corren el riesgo de devolver datos obsoletos en estas situaciones y se deben implementar estrategias de invalidación de caché bien pensadas para desalojar los datos obsoletos del caché cuando se modifican.
fragmentación de datos
Hasta ahora, los diseños que hemos discutido tienen componentes de base de datos segmentados en función de si responden a solicitudes de escritura o no. Sin embargo, otra forma de dividir la responsabilidad es dividir el conjunto de datos real en varias partes.
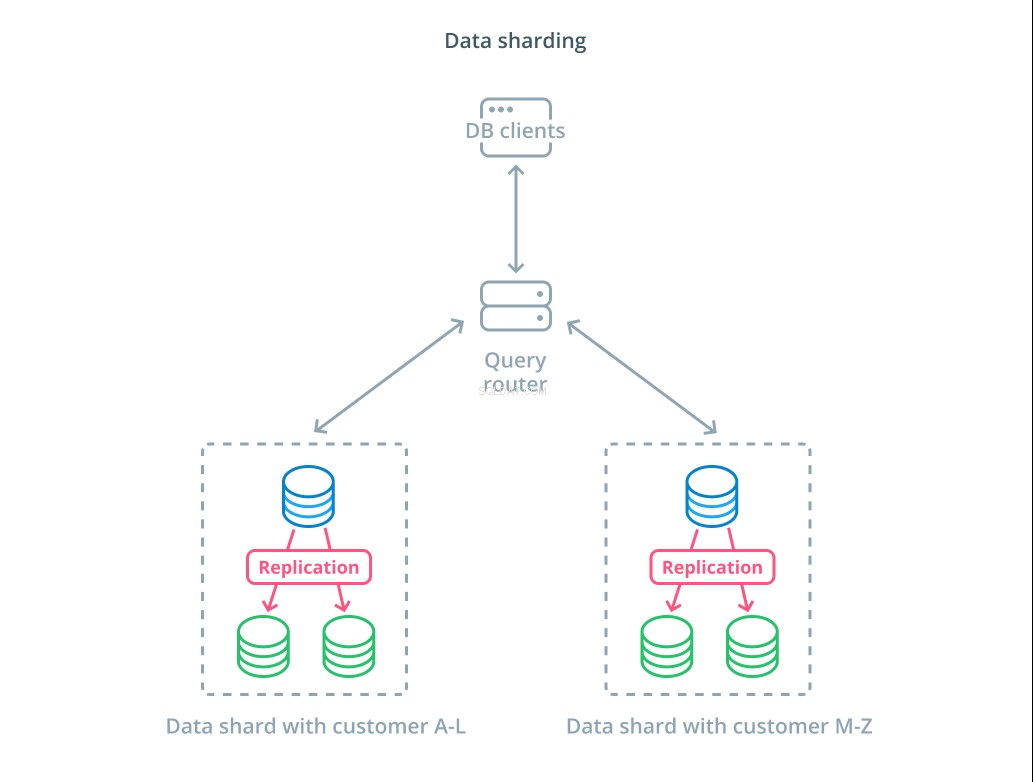
fragmentación es el proceso de dividir un conjunto de datos lógicos en subconjuntos más pequeños para distribuir su gestión a diferentes máquinas. Cada servidor de base de datos solo maneja una parte de los datos y se introduce una mecánica de enrutamiento que comprende qué máquinas son responsables de qué datos.
Por lo general, la fragmentación se realiza en escenarios en los que operar en todo el conjunto de datos a la vez es innecesario o poco común. El conjunto de datos se segmenta según el valor de cada registro para una clave específica, conocida como clave de fragmentación. . Por ejemplo, podría fragmentar manualmente los datos en función de la ubicación de los clientes. También puede fragmentar automáticamente usando un algoritmo hash para determinar qué nodos deben manejar qué claves. Esto puede ayudar a su sistema a evitar una distribución desequilibrada en los casos en que el espacio de claves del fragmento se distribuye de manera desigual.
La fragmentación introduce bastante complejidad en los sistemas de datos y no es adecuada para todos los escenarios. Las operaciones que interactúan con varios fragmentos sufrirán importantes penalizaciones de rendimiento a medida que recuperan los resultados de cada miembro. Esto puede suceder para consultas agregadas o si la clave de fragmento específica no se conoce con anticipación. Además, la asignación desigual de fragmentos también puede causar ineficiencias y cuellos de botella que deben solucionarse reequilibrando la distribución de todo el conjunto de datos.
Gestión de datos funcionales descentralizada
En lugar de dividir los valores de un conjunto de datos en varios segmentos, en muchos casos tiene más sentido utilizar diferentes bases de datos para diferentes propósitos funcionales. Por ejemplo, si tiene un servicio de cuentas y un servicio de productos, tener bases de datos dedicadas que coincidan con cada inquietud puede ayudarlo a escalar diferentes componentes de forma independiente.
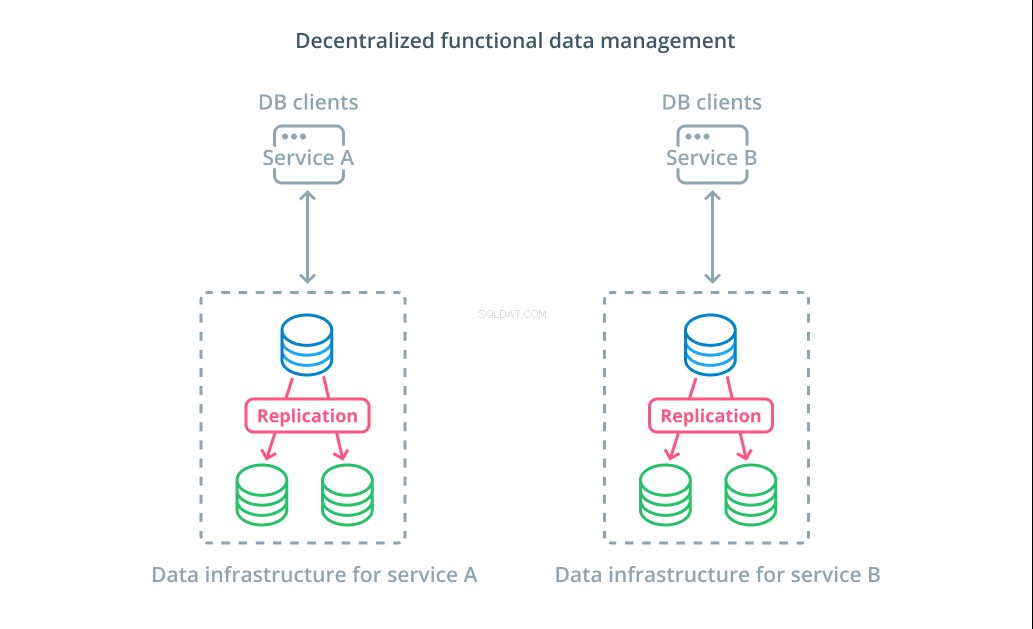
La gestión funcional de datos le permite dividir la infraestructura de su base de datos y administrar cada parte de acuerdo con las necesidades de sus clientes. Cada parte funcional se puede escalar usando cualquier estrategia que tenga más sentido. Le permite diseñar el esquema de la base de datos e implementarlo en la ubicación que mejor se adapte a los patrones de un caso de uso específico en lugar de requerir que sirva a toda la organización.
Para muchas organizaciones, esta estrategia tiene importantes ventajas que van más allá de las propiedades de los sistemas reales. La descentralización de la gestión de datos puede permitir que los equipos más pequeños sean dueños de sus propios datos sin coordinar los cambios con otras partes. Se alinea bien con la separación enfocada de preocupaciones promovida por las arquitecturas de aplicaciones orientadas a microservicios.
Bases de datos sin servidor
Las diferentes compensaciones que debe evaluar y la cantidad de infraestructura que se espera que administre para escalar adecuadamente pueden ser abrumadoras para muchas personas. Una opción para descargar esta complejidad es aprovechar los servicios de base de datos que administran la infraestructura y escalan para usted.
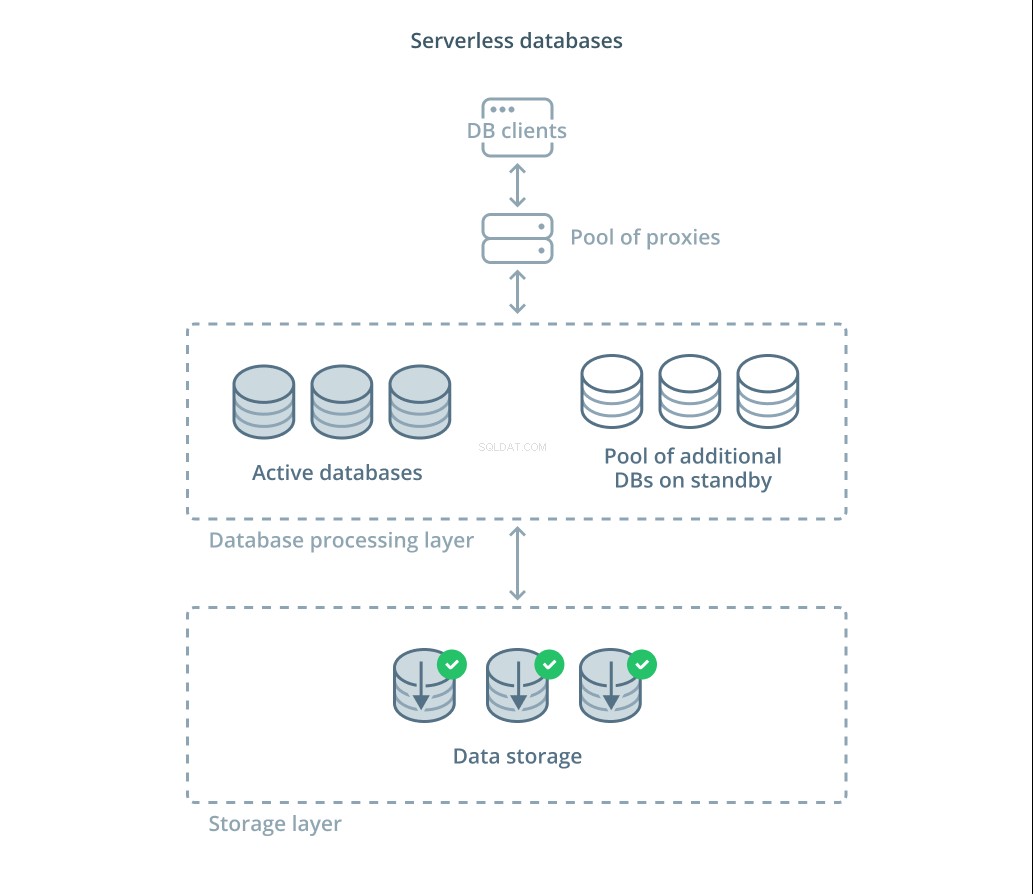
Bases de datos sin servidor son una categoría de servicios que separan el almacenamiento de datos del procesamiento de datos para escalar fácilmente los recursos en respuesta a los cambios en la demanda.
Una capa de almacenamiento de datos es responsable de mantener los datos reales administrados por el sistema. Delante de esta capa, se implementa un nivel de unidades de procesamiento de bases de datos escalables para manejar el procesamiento de consultas real en los conjuntos de datos. La cantidad de unidades activas en un momento dado está directamente relacionada con el uso actual, por lo que se asignan más recursos a medida que aumenta la demanda y las unidades de procesamiento vuelven al modo de espera si las cosas se calman.
Las consultas se envían a los procesadores de la base de datos a través de un proxy de enrutamiento que sabe cómo enviar solicitudes a los nodos activos y cuándo solicitar recursos adicionales.
Las bases de datos sin servidor tienen muchas de las mismas propiedades que los servicios de bases de datos tradicionales que implementan funciones de escalado automático. Ambos pueden asignar capacidad en función de la demanda. Sin embargo, las bases de datos sin servidor le permiten separar los costos de almacenamiento de los costos de procesamiento y pueden reducir el procesamiento a cero cuando no se necesite. Además, las soluciones sin servidor tienden a poder escalar mucho más rápido para satisfacer la demanda en comparación con el escalado automático que ofrecen las ofertas tradicionales.
Aunque las bases de datos sin servidor pueden ser una buena opción para algunos, no son una panacea. En los casos en que los procesadores de bases de datos eran reducido a cero, puede haber retrasos en el procesamiento nuevamente debido a arranques en frío. Además, la agitación de las conexiones entre los diversos componentes en una pila de base de datos sin servidor puede generar una latencia adicional.
Las plataformas de bases de datos sin servidor también pueden ser difíciles desde el punto de vista de las operaciones. Las implementaciones y los cambios en la base de datos pueden ser más difíciles de razonar y monitorear. El entorno de desarrollo local también puede diferir significativamente del entorno de producción debido al estado dinámico del sistema de base de datos. Y, por último, al igual que con cualquier otro servicio en la nube, el uso de bases de datos sin servidor puede ponerlo en peligro de quedar bloqueado por un proveedor. Es importante recordar estas ventajas y desventajas al diseñar en torno a una plataforma sin servidor.
Conclusión
Hay muchas maneras de diseñar, implementar y administrar su infraestructura de base de datos a medida que los requisitos de su aplicación se vuelven más serios. Cada solución tiene sus puntos fuertes y limitaciones que es importante comprender cuando se trata de encontrar una que se ajuste a su entorno.
Aprender acerca de cómo la infraestructura de la base de datos afecta la disponibilidad, el rendimiento y la integridad de sus datos le permite evitar errores costosos e implementaciones que no brindan las garantías que necesita. Si uno de los diseños anteriores no cubre sus requisitos, puede combinar algunos de los elementos de diferentes enfoques para obtener ventajas adicionales.
Si desea obtener más información sobre los patrones generales cubiertos anteriormente, aquí hay algunos recursos adicionales que puede consultar:
- Ampliar versus escalar horizontalmente
- Segregación de responsabilidad de consultas de comandos
- Replicación primaria múltiple
- Almacenamiento en caché de consultas de lectura
- Partición de datos
- Administración de datos descentralizada
- Bases de datos sin servidor