En mi última publicación, vimos cómo el optimizador podía transformar una consulta con un agregado escalar en una forma más eficiente. Como recordatorio, aquí está el esquema nuevamente:
CREATE TABLE dbo.T1 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T2 (pk integer PRIMARY KEY, c1 integer NOT NULL);
CREATE TABLE dbo.T3 (pk integer PRIMARY KEY, c1 integer NOT NULL);
GO
INSERT dbo.T1 (pk, c1)
SELECT n, n
FROM dbo.Numbers AS N
WHERE n BETWEEN 1 AND 50000;
GO
INSERT dbo.T2 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
INSERT dbo.T3 (pk, c1)
SELECT pk, c1 FROM dbo.T1;
GO
CREATE INDEX nc1 ON dbo.T1 (c1);
CREATE INDEX nc1 ON dbo.T2 (c1);
CREATE INDEX nc1 ON dbo.T3 (c1);
GO
CREATE VIEW dbo.V1
AS
SELECT c1 FROM dbo.T1
UNION ALL
SELECT c1 FROM dbo.T2
UNION ALL
SELECT c1 FROM dbo.T3;
GO
-- The test query
SELECT MAX(c1)
FROM dbo.V1; Opciones de planes
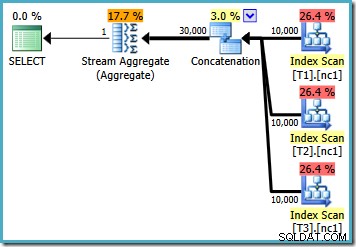
Con 10 000 filas en cada una de las tablas base, el optimizador presenta un plan simple que calcula el máximo leyendo las 30 000 filas en un agregado:
Con 50 000 filas en cada tabla, el optimizador dedica un poco más de tiempo al problema y encuentra un plan más inteligente. Lee solo la fila superior (en orden descendente) de cada índice y luego calcula el máximo de solo esas 3 filas:
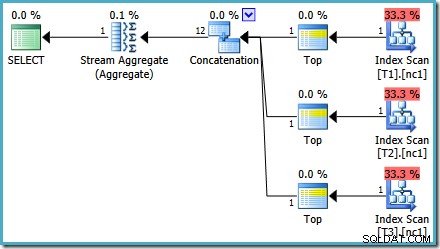
Un error del optimizador
Es posible que notes algo un poco extraño en ese estimado plan. ¡El operador de concatenación lee una fila de tres tablas y de alguna manera produce doce filas! Este es un error causado por un error en la estimación de cardinalidad que informé en mayo de 2011. Todavía no está solucionado a partir de SQL Server 2014 CTP 1 (incluso si se usa el nuevo estimador de cardinalidad) pero espero que se solucione para el lanzamiento final.
Para ver cómo surge el error, recuerde que una de las alternativas del plan consideradas por el optimizador para el caso de 50 000 filas tiene agregados parciales debajo del operador Concatenación:
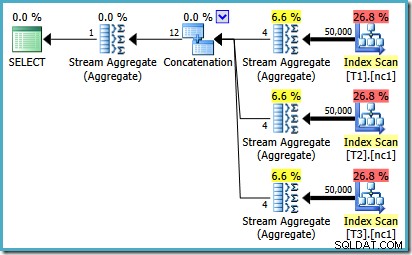
Es la estimación de cardinalidad para estos MAX parciales agregados que tienen la culpa. Estiman cuatro filas donde se garantiza que el resultado será una fila. Es posible que vea un número distinto de cuatro; depende de cuántos procesadores lógicos estén disponibles para el optimizador en el momento en que se compila el plan (consulte el enlace del error anterior para obtener más detalles).
Posteriormente, el optimizador reemplaza los agregados parciales con los operadores Top (1), que vuelven a calcular la cardinalidad estimada correctamente. Lamentablemente, el operador de concatenación aún refleja las estimaciones de los agregados parciales reemplazados (3 * 4 =12). Como resultado, terminamos con una Concatenación que lee 3 filas y produce 12.
Utilizar TOP en lugar de MAX
Mirando nuevamente el plan de 50,000 filas, parece que la mayor mejora encontrada por el optimizador es usar los operadores Top (1) en lugar de leer todas las filas y calcular el valor máximo usando la fuerza bruta. ¿Qué sucede si intentamos algo similar y reescribimos la consulta usando Top explícitamente?
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
El plan de ejecución para la nueva consulta es:
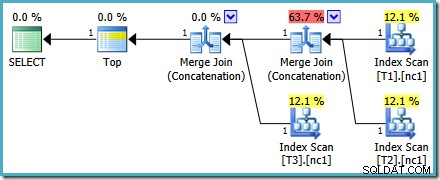
Este plan es bastante diferente al elegido por el optimizador para el MAX consulta. Cuenta con tres escaneos de índice ordenados, dos uniones de combinación que se ejecutan en modo de concatenación y un solo operador superior. Este nuevo plan de consulta tiene algunas características interesantes que vale la pena examinar con un poco de detalle.
Análisis de planes
La primera fila (en orden de índice descendente) se lee del índice no agrupado de cada tabla y se utiliza una combinación de combinación que funciona en modo de concatenación. Aunque el operador Merge Join no está realizando una unión en el sentido normal, el algoritmo de procesamiento de este operador se adapta fácilmente para concatenar sus entradas en lugar de aplicar criterios de unión.
El beneficio de usar este operador en el nuevo plan es que Merge Concatenation conserva el orden de clasificación en sus entradas. Por el contrario, un operador de concatenación regular lee sus entradas en secuencia. El siguiente diagrama ilustra la diferencia (haga clic para ampliar):
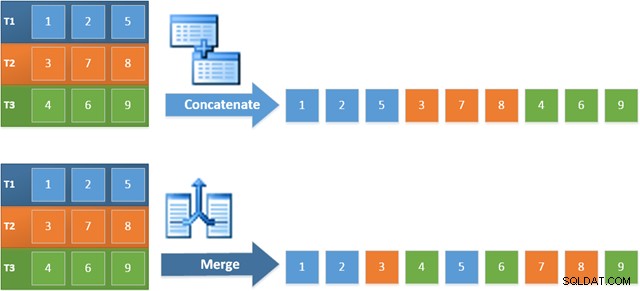
El comportamiento de preservación del orden de Merge Concatenation significa que se garantiza que la primera fila producida por el operador Merge más a la izquierda en el nuevo plan sea la fila con el valor más alto en la columna c1 en las tres tablas. Más específicamente, el plan opera de la siguiente manera:
- Una fila se lee de cada tabla (en orden descendente de índice); y
- Cada fusión realiza una prueba para ver cuál de sus filas de entrada tiene el valor más alto
Esta parece una estrategia muy eficiente, por lo que puede parecer extraño que el MAX del optimizador plan tiene un costo estimado de menos de la mitad del nuevo plan. En gran medida, la razón es que se supone que la concatenación de fusión que conserva el orden es más costosa que una simple concatenación. El optimizador no se da cuenta de que cada fusión solo puede ver un máximo de una fila y, como resultado, sobreestima su costo.
Más problemas de costos
Estrictamente hablando, aquí no estamos comparando manzanas con manzanas, porque los dos planes son para consultas diferentes. Comparar costos como ese generalmente no es algo válido, aunque SSMS hace exactamente eso al mostrar los porcentajes de costos para diferentes declaraciones en un lote. Pero estoy divagando.
Si observa el nuevo plan en SSMS en lugar de SQL Sentry Plan Explorer, verá algo como esto:
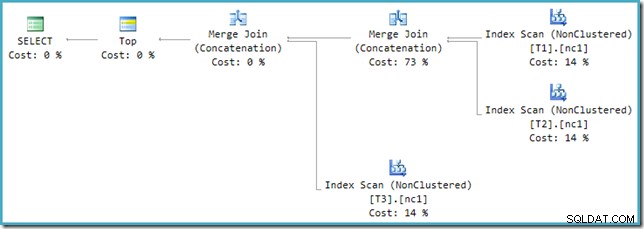
Uno de los operadores Merge Join Concatenation tiene un costo estimado del 73 %, mientras que el segundo (que opera exactamente en la misma cantidad de filas) no cuesta nada. Otra señal de que algo anda mal aquí es que los porcentajes de costos del operador en este plan no suman el 100%.
Optimizador frente a motor de ejecución
El problema radica en una incompatibilidad entre el optimizador y el motor de ejecución. En el optimizador, Union y Union All pueden tener 2 o más entradas. En el motor de ejecución, solo el operador Concatenación puede aceptar 2 o más entradas; Fusionar Unirse requiere exactamente dos entradas, incluso cuando están configuradas para realizar una concatenación en lugar de una unión.
Para resolver esta incompatibilidad, se aplica una reescritura posterior a la optimización para traducir el árbol de salida del optimizador a una forma que el motor de ejecución pueda manejar. Cuando se implementa una unión o unión de todos con más de dos entradas mediante Merge, se necesita una cadena de operadores. Con tres entradas a Union All en el presente caso, se necesitan dos Merge Unions:
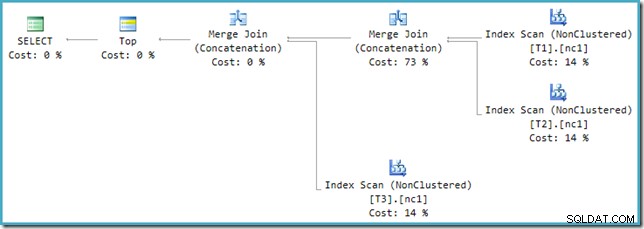
Podemos ver el árbol de salida del optimizador (con tres entradas a una unión de fusión física) usando el indicador de seguimiento 8607:
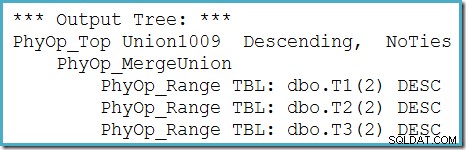
Una solución incompleta
Desafortunadamente, la reescritura posterior a la optimización no está perfectamente implementada. Hace un poco de lío de los números de costos. Dejando a un lado los problemas de redondeo, los costos del plan suman un 114 % y el 14 % adicional proviene de la entrada a la concatenación Merge Join adicional generada por la reescritura:
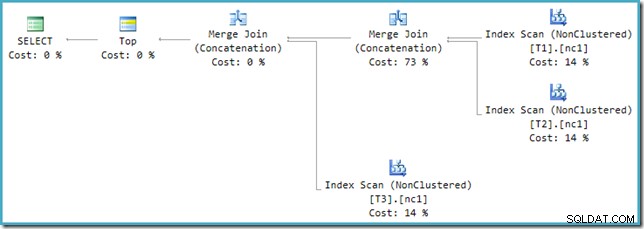
La combinación más a la derecha en este plan es el operador original en el árbol de salida del optimizador. Se asigna el costo total de la operación Unión Todo. La otra combinación se agrega mediante la reescritura y recibe un costo cero.
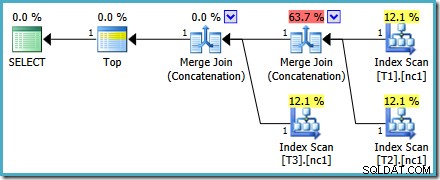
Cualquiera que sea la forma en que elijamos verlo (y hay diferentes problemas que afectan la concatenación regular), los números parecen extraños. Plan Explorer hace todo lo posible para evitar la información rota en el plan XML al menos asegurándose de que los números sumen 100 %:
Este problema de costos en particular se solucionó en SQL Server 2014 CTP 1:
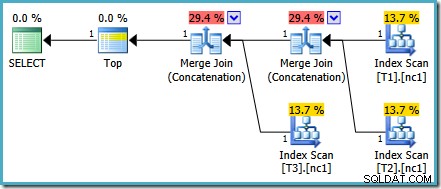
Los costos de Merge Concatenation ahora se dividen equitativamente entre los dos operadores, y los porcentajes suman 100%. Debido a que se ha corregido el XML subyacente, SSMS también logra mostrar los mismos números.
¿Qué plan es mejor?
Si escribimos la consulta usando MAX , tenemos que confiar en que el optimizador elija realizar el trabajo adicional necesario para encontrar un plan eficiente. Si el optimizador encuentra un plan aparentemente lo suficientemente bueno desde el principio, puede producir un plan relativamente ineficiente que lea cada fila de cada una de las tablas base:
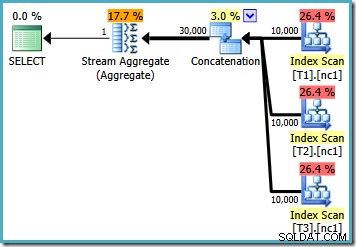
Si está ejecutando SQL Server 2008 o SQL Server 2008 R2, el optimizador aún elegirá un plan ineficiente, independientemente de la cantidad de filas en las tablas base. El siguiente plan se produjo en SQL Server 2008 R2 con 50 000 filas:
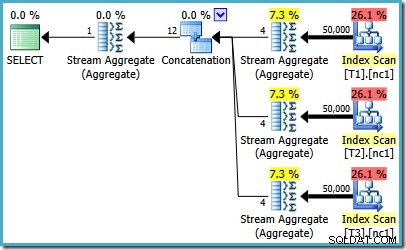
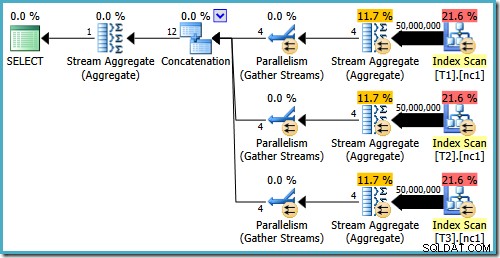
Incluso con 50 millones de filas en cada tabla, el optimizador R2 de 2008 y 2008 solo agrega paralelismo, no presenta los operadores principales:
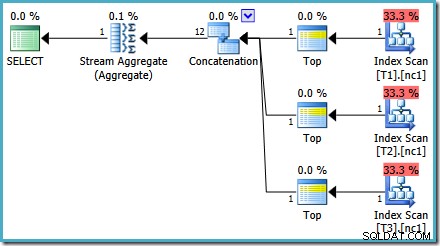
Como mencioné en mi publicación anterior, se requiere el indicador de seguimiento 4199 para obtener SQL Server 2008 y 2008 R2 para producir el plan con los mejores operadores. SQL Server 2005 y 2012 en adelante no requieren el indicador de rastreo:
ARRIBA con ORDEN POR
Una vez que comprendamos lo que está sucediendo en los planes de ejecución anteriores, podemos tomar una decisión consciente (e informada) para reescribir la consulta usando un TOP explícito con ORDER BY:
SELECT TOP (1) c1 FROM dbo.V1 ORDER BY c1 DESC;
El plan de ejecución resultante puede tener porcentajes de costos que parecen extraños en algunas versiones de SQL Server, pero el plan subyacente es sólido. La reescritura posterior a la optimización que hace que los números se vean extraños se aplica después de que se completa la optimización de consultas, por lo que podemos estar seguros de que la selección del plan del optimizador no se vio afectada por este problema.
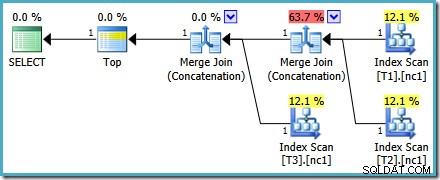
Este plan no cambia según el número de filas en la tabla base y no requiere ninguna marca de seguimiento para generar. Una pequeña ventaja adicional es que el optimizador encuentra este plan durante la primera fase de optimización basada en costos (búsqueda 0):
El mejor plan seleccionado por el optimizador para el MAX la consulta requería ejecutar dos etapas de optimización basada en costos (búsqueda 0 y buscar 1).
Hay una pequeña diferencia semántica entre TOP consulta y el MAX original forma que debo mencionar. Si ninguna de las tablas contiene una fila, la consulta original produciría un solo NULL resultado. El reemplazo TOP (1) la consulta no produce ningún resultado en las mismas circunstancias. Esta diferencia no suele ser importante en las consultas del mundo real, pero es algo a tener en cuenta. Podemos replicar el comportamiento de TOP usando MAX en SQL Server 2008 en adelante agregando un conjunto vacío GROUP BY :
SELECT MAX(c1) FROM dbo.V1 GROUP BY ();
Este cambio no afecta los planes de ejecución generados para el MAX consulta de forma que sea visible para los usuarios finales.
MAX con concatenación de fusión
Dado el éxito de Merge Join Concatenation en el TOP (1) plan de ejecución, es natural preguntarse si se podría generar el mismo plan óptimo para el MAX original consulta si forzamos al optimizador a usar Merge Concatenation en lugar de Concatenation regular para UNION ALL operación.
Hay una sugerencia de consulta para este propósito:MERGE UNION – pero lamentablemente solo funciona correctamente en SQL Server 2012 en adelante. En versiones anteriores, UNION la sugerencia solo afecta a UNION consultas, no UNION ALL . En SQL Server 2012 en adelante, podemos probar esto:
SELECT MAX(c1) FROM dbo.V1 OPTION (MERGE UNION)
Somos recompensados con un plan que presenta Merge Concatenation. Desafortunadamente, no es todo lo que esperábamos:
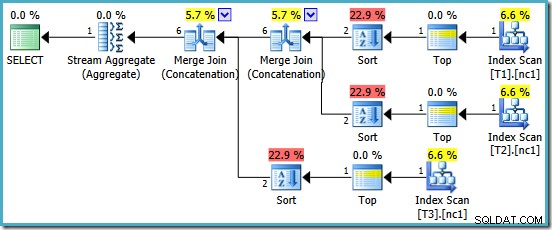
Los operadores interesantes en este plan son los géneros. Observe la estimación de cardinalidad de entrada de 1 fila y la estimación de 4 filas en la salida. La causa ya debería resultarle familiar:es el mismo error de estimación de cardinalidad agregada parcial que analizamos anteriormente.
La presencia de los géneros revela un problema más con los agregados parciales. No solo producen una estimación de cardinalidad incorrecta, sino que tampoco conservan la ordenación del índice que haría innecesaria la ordenación (Merge Concatenation requiere entradas ordenadas). Los agregados parciales son escalares MAX agregados, garantizados para producir una fila, por lo que el tema del orden debería ser discutible de todos modos (¡solo hay una forma de ordenar una fila!)
Es una pena, porque sin los tipos, este sería un plan de ejecución decente. Si los agregados parciales se implementaron correctamente y el MAX escrito con un GROUP BY () cláusula, incluso podríamos esperar que el optimizador pudiera detectar que los tres tops y el Stream Aggregate final podrían ser reemplazados por un solo operador Top final, dando exactamente el mismo plan que el TOP (1) explícito consulta. El optimizador no contiene esa transformación hoy, y no creo que sea lo suficientemente útil como para que su inclusión valga la pena en el futuro.
Palabras finales
Usando TOP no siempre será preferible a MIN o MAX . En algunos casos producirá un plan significativamente menos óptimo. El punto de esta publicación es que comprender las transformaciones aplicadas por el optimizador puede sugerir formas de reescribir la consulta original que pueden resultar útiles.