La semana pasada publiqué una publicación llamada #BackToBasics:DATEFROMPARTS() , donde mostré cómo usar esta función 2012+ para consultas de rango de fechas más limpias y fáciles de analizar. Lo usé para demostrar que si usa un predicado de fecha abierta y tiene un índice en la columna de fecha/hora relevante, puede terminar con un uso de índice mucho mejor y menos E/S (o, en el peor de los casos , lo mismo, si no se puede usar una búsqueda por algún motivo, o si no existe un índice adecuado):
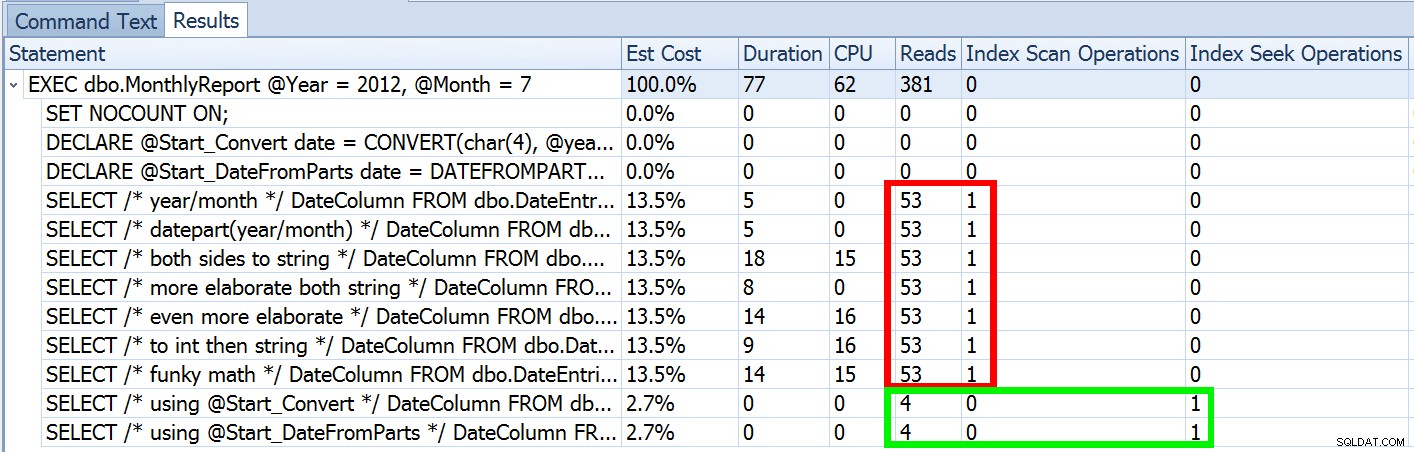
Pero eso es solo una parte de la historia (y para ser claros, DATEFROMPARTS() no es técnicamente necesario para obtener una búsqueda, en ese caso es más limpio). Si nos alejamos un poco, notamos que nuestras estimaciones están lejos de ser precisas, una complejidad que no quería presentar en la publicación anterior:
Esto no es poco común tanto para los predicados de desigualdad como para los escaneos forzados. Y, por supuesto, ¿el método que sugerí no arrojaría las estadísticas más inexactas? Este es el enfoque básico (puede obtener el esquema de la tabla, los índices y los datos de muestra de mi publicación anterior):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Ahora, las estimaciones inexactas no siempre serán un problema, pero pueden causar problemas con opciones de planes ineficientes en los dos extremos. Es posible que un plan único no sea óptimo cuando el rango elegido producirá un porcentaje muy pequeño o muy grande de la tabla o índice, y esto puede ser muy difícil de predecir para SQL Server cuando la distribución de datos es desigual. Joseph Sack describió las cosas más típicas que pueden afectar las malas estimaciones en su publicación, "Diez amenazas comunes para la calidad del plan de ejecución:"
"[...] las estimaciones de filas incorrectas pueden afectar una variedad de decisiones, incluida la selección de índices, operaciones de búsqueda frente a escaneo, ejecución en paralelo frente a serie, selección de algoritmos de unión, selección de unión física interna frente a externa (por ejemplo, compilación frente a sondeo), generación de spool, búsquedas de marcadores frente a acceso completo a la tabla agrupada o en montón, selección de agregados de flujo o hash, y si una modificación de datos utiliza o no un plan amplio o estrecho".
También hay otros, como las concesiones de memoria que son demasiado grandes o demasiado pequeñas. Continúa describiendo algunas de las causas más comunes de malas estimaciones, pero la causa principal en este caso no se encuentra en su lista:las estimaciones aproximadas. Porque estamos usando una variable local para cambiar el int entrante parámetros a una sola date local variable, SQL Server no sabe cuál será el valor, por lo que hace conjeturas estandarizadas de cardinalidad basadas en toda la tabla.
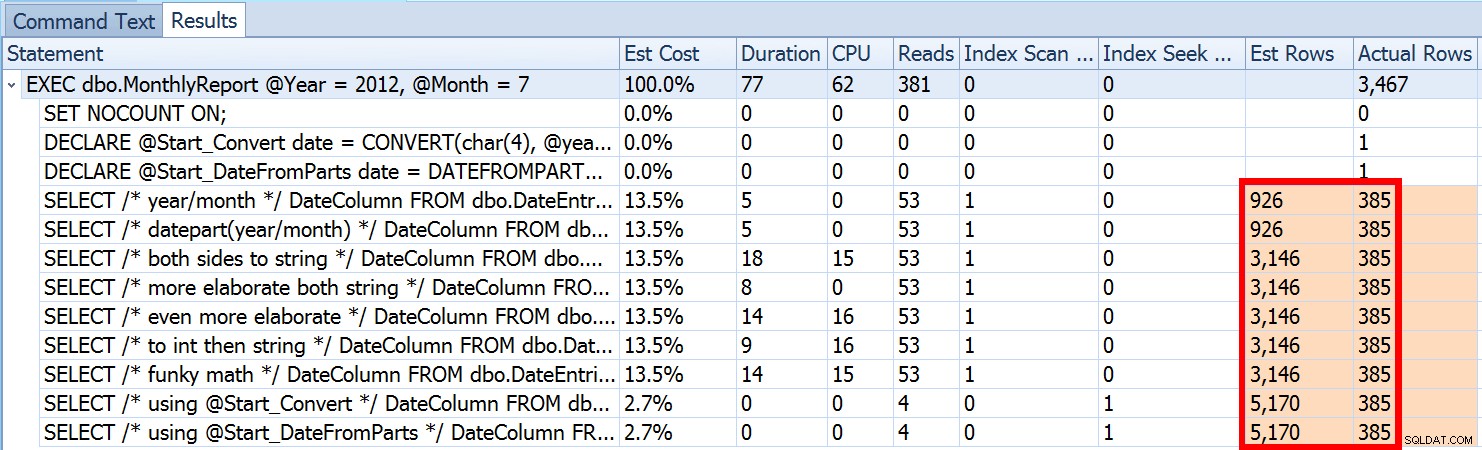
Vimos arriba que la estimación para mi enfoque sugerido era de 5170 filas. Ahora, sabemos que con un predicado de desigualdad, y con SQL Server sin conocer los valores de los parámetros, adivinará el 30% de la tabla. 31,645 * 0.3 no es 5,170. Tampoco 31,465 * 0.3 * 0.3 , cuando recordamos que en realidad hay dos predicados trabajando contra la misma columna. Entonces, ¿de dónde viene este valor de 5170?
Como Paul White describe en su publicación, "Estimación de cardinalidad para múltiples predicados", el nuevo estimador de cardinalidad en SQL Server 2014 utiliza un retroceso exponencial, por lo que multiplica el recuento de filas de la tabla (31 465) por la selectividad del primer predicado (0,3) , y luego lo multiplica por la raíz cuadrada de la selectividad del segundo predicado (~0.547723).
31.645 * (0,3) * SQRT(0,3) ~=5.170,227Entonces, ahora podemos ver de dónde salió SQL Server con su estimación; ¿Cuáles son algunos de los métodos que podemos usar para hacer algo al respecto?
OPTION (RECOMPILE) . Con el pequeño costo de la compilación cada vez que se ejecuta la consulta, esto obliga a SQL Server a optimizar en función de los valores presentados cada vez, en lugar de optimizar un solo plan para valores de parámetros desconocidos, primeros o promedio. (Para obtener un tratamiento completo de este tema, consulte "Opciones de rastreo de parámetros, incrustación y RECOMPILE" de Paul White.date construida fuerza la parametrización adecuada (como si hubiera llamado a un procedimiento almacenado con una date parámetro), pero es un poco feo y más difícil de mantener.No voy a sugerir que esta es una lista exhaustiva, y no voy a reiterar el consejo de Paul sobre sugerencias o señales de seguimiento, así que solo me concentraré en mostrar cómo los primeros cuatro enfoques pueden mitigar el problema con estimaciones incorrectas. .
1. Parámetros de fecha
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Procedimiento de envoltura
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. OPCIÓN (RECOMPILAR)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. SQL dinámico
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Las Pruebas
Con los cuatro conjuntos de procedimientos implementados, fue fácil construir pruebas que me mostraran los planes y las estimaciones derivadas de SQL Server. Dado que algunos meses están más ocupados que otros, elegí tres meses diferentes y los ejecuté varias veces.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
¿El resultado? Todos los planes generan la misma búsqueda de índice, pero las estimaciones solo son correctas en los tres intervalos de fechas. en la OPTION (RECOMPILE) versión. El resto continúa usando las estimaciones derivadas del primer conjunto de parámetros (julio de 2012), y así mientras obtienen mejores estimaciones para el primero ejecución, esa estimación no será necesariamente mejor para subsecuente ejecuciones usando diferentes parámetros (un caso clásico de libro de texto de análisis de parámetros):
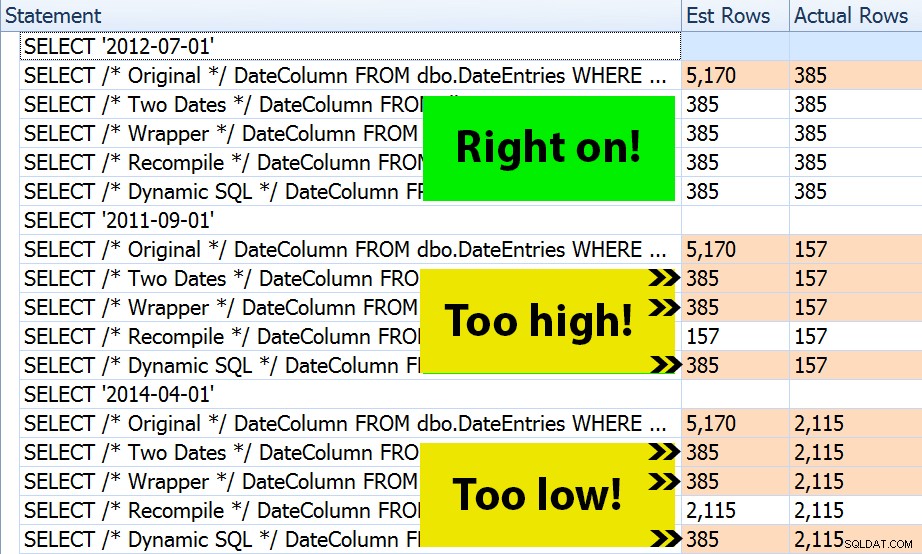
Tenga en cuenta que lo anterior no es un resultado *exacto* de SQL Sentry Plan Explorer; por ejemplo, eliminé las filas del árbol de declaraciones que mostraban las llamadas a procedimientos almacenados externos y las declaraciones de parámetros.
Dependerá de usted determinar si la táctica de compilar cada vez es mejor para usted, o si necesita "arreglar" algo en primer lugar. Aquí, terminamos con los mismos planes y sin diferencias notables en las métricas de rendimiento del tiempo de ejecución. Pero en tablas más grandes, con una distribución de datos más sesgada y mayores variaciones en los valores predicados (por ejemplo, considere un informe que puede cubrir una semana, un año y cualquier punto intermedio), puede valer la pena investigar un poco. Y tenga en cuenta que puede combinar métodos aquí; por ejemplo, puede cambiar a los parámetros de fecha adecuados *y* agregar OPTION (RECOMPILE) , si quisieras.
Conclusión
En este caso específico, que es una simplificación intencional, el esfuerzo de obtener las estimaciones correctas realmente no valió la pena:no obtuvimos un plan diferente y el rendimiento del tiempo de ejecución fue equivalente. Sin embargo, ciertamente hay otros casos en los que esto marcará la diferencia, y es importante reconocer la disparidad de estimaciones y determinar si podría convertirse en un problema a medida que sus datos crecen y/o su distribución se desvía. Desafortunadamente, no hay una respuesta absoluta, ya que muchas variables afectarán si se justifica la sobrecarga de compilación, como ocurre con muchos escenarios, IT DEPENDS™ …