En varias de mis publicaciones durante el último año, he usado el tema de las personas que ven un tipo de espera en particular y luego reaccionan de manera "instintiva" a la espera que está allí. Por lo general, esto significa seguir algunos consejos de Internet deficientes y tomar una acción drástica e inapropiada o llegar a una conclusión precipitada sobre cuál es la causa raíz del problema y luego perder tiempo y esfuerzo en una búsqueda inútil.
Uno de los tipos de espera donde las reacciones instintivas son más fuertes y donde existen algunos de los peores consejos es la espera CXPACKET. También es el tipo de espera que suele ser la espera principal en los servidores de las personas (según mis dos grandes encuestas de tipos de espera de 2010 y 2014; consulta los detalles aquí), así que lo trataré en esta publicación.
¿Qué significa el tipo de espera CXPACKET?
La explicación más simple es que CXPACKET significa que tiene consultas ejecutándose en paralelo y *siempre* verá que CXPACKET espera una consulta en paralelo. Las esperas de CXPACKET NO significan que tenga un paralelismo problemático:debe profundizar más para determinarlo.
Como ejemplo de un operador paralelo, considere el operador Repartition Streams, que tiene el siguiente ícono en los planes de consulta gráfica:

Y aquí hay una imagen que muestra lo que sucede en términos de subprocesos paralelos para este operador, con un grado de paralelismo (DOP) igual a 4:
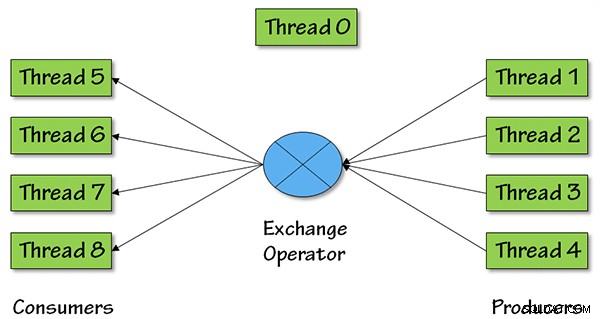
Para DOP =4, habrá cuatro subprocesos de producción, extrayendo datos de antes en el plan de consulta, los datos luego regresan al resto del plan de consulta a través de cuatro subprocesos de consumidor.
Puede ver los diversos subprocesos en un operador paralelo que están esperando un recurso utilizando sys.dm_os_waiting_tasks DMV, en el exec_context_id columna (esta publicación tiene mi script para hacer esto).
Siempre hay un subproceso de 'control' para cualquier plan paralelo, que por accidente histórico siempre es el ID de subproceso 0. El subproceso de control siempre registra una espera CXPACKET, con una duración igual al tiempo que tarda el plan en ejecutarse. Paul White tiene una excelente explicación de los subprocesos en planes paralelos aquí.
La única vez que los subprocesos que no son de control registrarán las esperas de CXPACKET es si se completan antes que los otros subprocesos en el operador. Esto puede suceder si uno de los subprocesos se queda atascado esperando un recurso durante mucho tiempo, así que busque el tipo de espera del subproceso que no muestra CXPACKET (usando mi secuencia de comandos anterior) y resuelva el problema de manera adecuada. Esto también puede suceder debido a una distribución de trabajo sesgada entre los subprocesos, y profundizaré en ese caso en mi próxima publicación aquí (es causado por estadísticas desactualizadas y otros problemas de estimación de cardinalidad).
Tenga en cuenta que en SQL Server 2016 SP2 y SQL Server 2017 RTM CU3, los subprocesos de consumo ya no registran esperas de CXPACKET. Registran esperas de CXCONSUMER, que son benignas y se pueden ignorar. Esto es para reducir la cantidad de esperas de CXPACKET que se generan, y es más probable que las restantes sean accionables.
¿Paralelismo inesperado?
Dado que CXPACKET simplemente significa que tiene paralelismo, lo primero que debe observar es si espera paralelismo para la consulta que lo está utilizando. Mi consulta le dará la identificación del nodo del plan de consulta donde está ocurriendo el paralelismo (extrae la identificación del nodo del plan de consulta XML si el tipo de espera del subproceso es CXPACKET), así que busque esa identificación del nodo y determine si el paralelismo tiene sentido. .
Uno de los casos comunes de paralelismo inesperado es cuando ocurre un escaneo de tabla donde espera una búsqueda o escaneo de índice más pequeño. Verá esto en el plan de consulta o verá muchas esperas de PAGEIOLATCH_SH (discutidas en detalle aquí) junto con las esperas de CXPACKET (un patrón de estadísticas de espera clásico a tener en cuenta). Hay una variedad de causas de escaneos de tablas inesperados, que incluyen:
- Falta el índice no agrupado, por lo que una exploración de la tabla es la única alternativa
- Estadísticas desactualizadas, por lo que el Optimizador de consultas cree que una exploración de tabla es el mejor método de acceso a datos que se puede utilizar.
- Una conversión implícita, debido a una discrepancia en el tipo de datos entre una columna de tabla y una variable o parámetro, lo que significa que no se puede usar un índice no agrupado
- La aritmética se realiza en una columna de tabla en lugar de una variable o parámetro, lo que significa que no se puede usar un índice no agrupado
En todos estos casos, la solución está dictada por lo que encuentre que es la causa raíz.
Pero, ¿qué sucede si no hay un caso raíz obvio y la consulta se considera lo suficientemente costosa como para justificar un plan paralelo?
Evitar el paralelismo
Entre otras cosas, el Optimizador de consultas decide producir un plan de consultas en paralelo si el plan en serie tiene un costo mayor que el cost threshold for parallelism , una configuración de sp_configure para la instancia. El umbral de costo para el paralelismo (o CTFP) se establece en cinco de forma predeterminada, lo que significa que un plan no tiene que ser muy costoso para desencadenar la creación de un plan paralelo.
Una de las formas más fáciles de evitar el paralelismo no deseado es aumentar el CTFP a un número mucho más alto, cuanto más alto lo configure, menos probable es que se creen planes paralelos. Algunas personas recomiendan configurar CTFP entre 25 y 50, pero como con todas las configuraciones modificables, es mejor probar varios valores y ver qué funciona mejor para su entorno. Si desea un poco más de un método programático para ayudarlo a elegir un buen valor de CTFP, Jonathan escribió una publicación de blog que muestra una consulta para analizar el caché del plan y producir un valor sugerido para CTFP. Como ejemplos, tenemos un cliente con CTFP establecido en 200 y otro establecido en el máximo, 32767, como una forma de evitar por la fuerza cualquier paralelismo.
Quizás se pregunte por qué el segundo cliente tuvo que usar CTFP como un método mazo para evitar el paralelismo cuando pensaría que simplemente podría configurar el 'grado máximo de paralelismo' (o MAXDOP) del servidor en 1. Bueno, cualquier persona con cualquier nivel de permiso puede especifique una sugerencia de MAXDOP de consulta y anule la configuración de MAXDOP del servidor, pero no se puede anular CTFP.
Y ese es otro método para limitar el paralelismo:establecer una sugerencia MAXDOP en la consulta que no desea que vaya en paralelo.
También puede reducir la configuración MAXDOP del servidor, pero esa es una solución drástica, ya que puede evitar que todo use el paralelismo. Hoy en día, es común que los servidores tengan cargas de trabajo mixtas, por ejemplo, con algunas consultas OLTP y algunas consultas de informes. Si reduce el MAXDOP del servidor, afectará el rendimiento de las consultas de informes.
Una mejor solución cuando hay una carga de trabajo mixta sería usar CTFP como describí anteriormente o utilizar Resource Governor (que, me temo, es solo para empresas). Puede usar el regulador de recursos para separar las cargas de trabajo en grupos de cargas de trabajo y luego establecer un MAX_DOP (el guión bajo no es un error tipográfico) para cada grupo de cargas de trabajo. Y lo bueno de usar Resource Governor es que MAX_DOP no puede ser anulado por una sugerencia de consulta MAXDOP.
Resumen
No caiga en la trampa de pensar que CXPACKET espera automáticamente significa que está ocurriendo un paralelismo malo, y ciertamente no siga algunos de los consejos de Internet que he visto sobre bloquear el servidor configurando MAXDOP en 1. Tómese el tiempo para investigar por qué está viendo esperas de CXPACKET y si es algo que debe abordarse o simplemente un artefacto de una carga de trabajo que se ejecuta correctamente.
En lo que respecta a las estadísticas generales de espera, puede encontrar más información sobre cómo usarlas para solucionar problemas de rendimiento en:
- La serie de publicaciones de mi blog SQLskills, que comienza con las estadísticas de espera o, por favor, dígame dónde le duele.
- Mi biblioteca de tipos de espera y clases de bloqueo aquí
- Curso de capacitación en línea My Pluralsight SQL Server:solución de problemas de rendimiento mediante estadísticas de espera
- Asesor de rendimiento de SQL Sentry
En el siguiente artículo de la serie, hablaré sobre el paralelismo sesgado y le daré una forma sencilla de verlo. Hasta entonces, ¡feliz resolución de problemas!