Cuando SQL Server 2012 aún estaba en versión beta, escribí en un blog sobre el nuevo FORMAT() función:SQL Server v.Next (Denali):Mejoras de CTP3 T-SQL:FORMAT().
En ese momento, estaba tan entusiasmado con la nueva funcionalidad que ni siquiera pensé en hacer ninguna prueba de rendimiento. Abordé esto en una publicación de blog más reciente, pero únicamente en el contexto de eliminar el tiempo de una fecha y hora:Recortar el tiempo de una fecha y hora:un seguimiento.
La semana pasada, mi buen amigo Jason Horner (blog | @jasonhorner) me bromeó con estos tuits:
| |
Mi problema con esto es que FORMAT() parece conveniente, pero es extremadamente ineficiente en comparación con otros enfoques (ah, y eso AS VARCHAR la cosa también está mal). Si está haciendo este oney-twosy y para conjuntos de resultados pequeños, no me preocuparía demasiado por eso; pero a escala, puede ser bastante caro. Permítanme ilustrar con un ejemplo. Primero, creemos una pequeña tabla con 1000 fechas pseudoaleatorias:
SELECT TOP (1000) d = DATEADD(DAY, CHECKSUM(NEWID())%1000, o.create_date) INTO dbo.dtTest FROM sys.all_objects AS o ORDER BY NEWID(); GO CREATE CLUSTERED INDEX d ON dbo.dtTest(d);
Ahora, preparemos el caché con los datos de esta tabla e ilustremos tres de las formas comunes en que las personas tienden a presentar la hora exacta:
SELECT d, CONVERT(DATE, d), CONVERT(CHAR(10), d, 120), FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest;
Ahora, realicemos consultas individuales que utilicen estas diferentes técnicas. Los ejecutaremos cada 5 veces y ejecutaremos las siguientes variaciones:
- Seleccionar las 1000 filas
- Seleccionar TOP (1) ordenado por la clave de índice agrupado
- Asignación a una variable (lo que fuerza un análisis completo, pero evita que la representación de SSMS interfiera con el rendimiento)
Aquí está el guión:
-- select all 1,000 rows GO SELECT d FROM dbo.dtTest; GO 5 SELECT d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5 -- select top 1 GO SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORDER BY d; GO 5 SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER BY d; GO 5 -- force scan but leave SSMS mostly out of it GO DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; GO 5 DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest; GO 5 DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest; GO 5
Ahora, podemos medir el rendimiento con la siguiente consulta (mi sistema es bastante silencioso; en el suyo, es posible que deba realizar un filtrado más avanzado que solo execution_count ):
SELECT [t] = CONVERT(CHAR(255), t.[text]), s.total_elapsed_time, avg_elapsed_time = CONVERT(DECIMAL(12,2),s.total_elapsed_time / 5.0), s.total_worker_time, avg_worker_time = CONVERT(DECIMAL(12,2),s.total_worker_time / 5.0), s.total_clr_time FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.[sql_handle]) AS t WHERE s.execution_count = 5 AND t.[text] LIKE N'%dbo.dtTest%' ORDER BY s.last_execution_time;
Los resultados en mi caso fueron bastante consistentes:
| Consulta (truncada) | Duración (microsegundos) | |||
|---|---|---|---|---|
| total_transcurrido | avg_elapsed | total_clr | ||
| SELECCIONE 1000 filas | SELECT d FROM dbo.dtTest ORDER BY d; |
1,170 |
234.00 |
0 |
SELECT d = CONVERT(DATE, d) FROM dbo.dtTest ORDER BY d; |
2,437 |
487.40 |
0 |
|
SELECT d = CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ORD ... |
151,521 |
30,304.20 |
0 |
|
SELECT d = FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest ORDER ... |
240,152 |
48,030.40 |
107,258 |
|
| SELECT TOP (1) | SELECT TOP (1) d FROM dbo.dtTest ORDER BY d; |
251 |
50.20 |
0 |
SELECT TOP (1) CONVERT(DATE, d) FROM dbo.dtTest ORDER BY ... |
440 |
88.00 |
0 |
|
SELECT TOP (1) CONVERT(CHAR(10), d, 120) FROM dbo.dtTest ... |
301 |
60.20 |
0 |
|
SELECT TOP (1) FORMAT(d, 'yyyy-MM-dd') FROM dbo.dtTest O ... |
1,094 |
218.80 |
589 |
|
| Assign variable | DECLARE @d DATE; SELECT @d = d FROM dbo.dtTest; |
639 |
127.80 |
0 |
DECLARE @d DATE; SELECT @d = CONVERT(DATE, d) FROM dbo.d ... |
644 |
128.80 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = CONVERT(CHAR(10), d, 12 ... | 1,972 |
394.40 |
0 |
|
DECLARE @d CHAR(10); SELECT @d = FORMAT(d, 'yyyy-MM-dd') ... |
118,062 |
23,612.40 |
98,556 |
|
And to visualize the avg_elapsed_time salida (haga clic para ampliar):
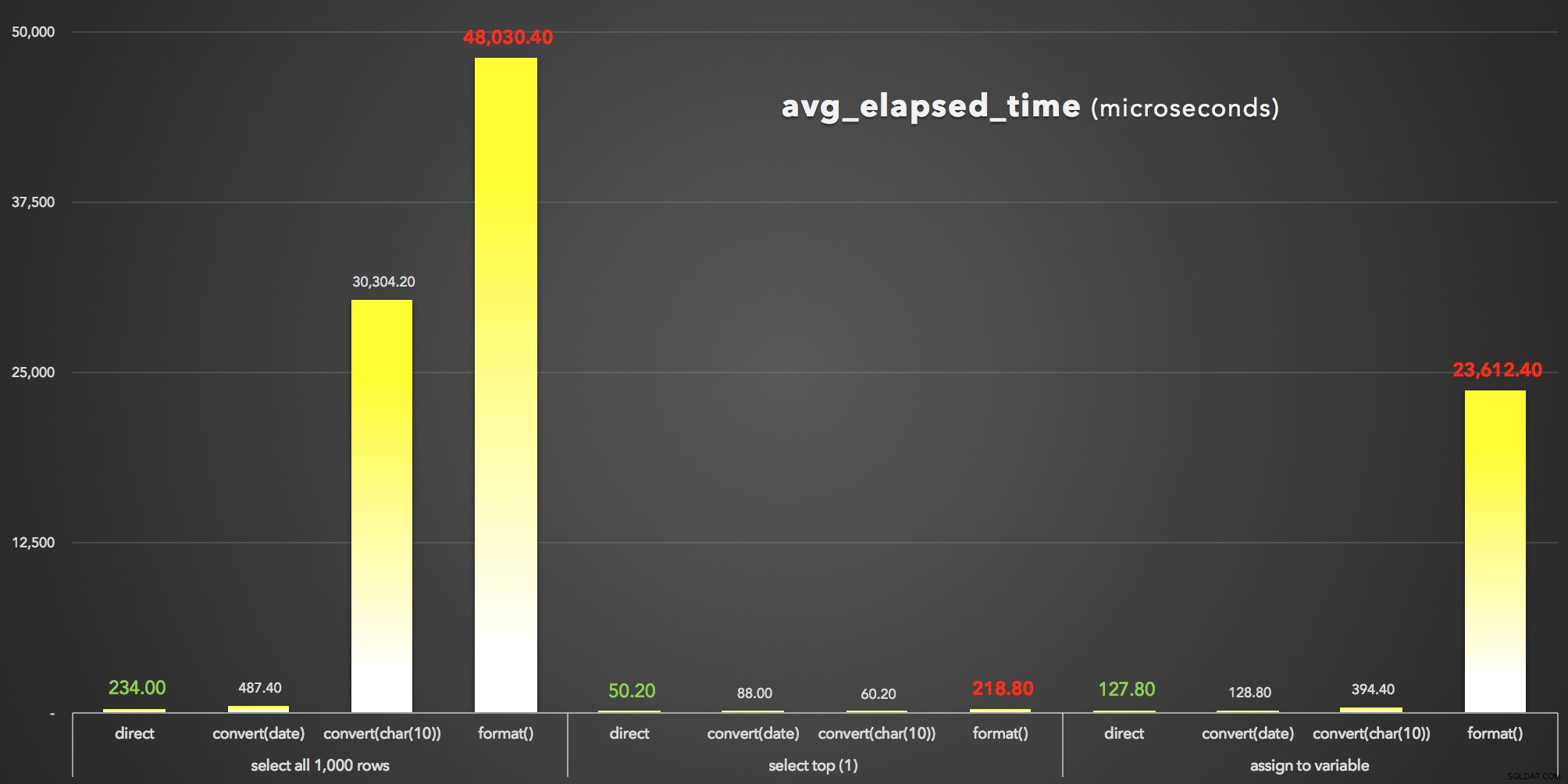 FORMAT() es claramente el perdedor:avg_elapsed_time resultados (microsegundos)
FORMAT() es claramente el perdedor:avg_elapsed_time resultados (microsegundos)
Lo que podemos aprender de estos resultados (nuevamente):
- En primer lugar,
FORMAT()es caro . FORMAT()puede, sin duda, proporcionar más flexibilidad y brindar métodos más intuitivos que sean consistentes con los de otros lenguajes como C#. Sin embargo, además de su sobrecarga, y mientrasCONVERT()los números de estilo son crípticos y menos exhaustivos, es posible que deba usar el enfoque anterior de todos modos, ya queFORMAT()solo es válido en SQL Server 2012 y posteriores.- Incluso el
CONVERT()en espera El método puede ser drásticamente costoso (aunque solo gravemente en el caso de que SSMS tuviera que generar los resultados; claramente maneja las cadenas de forma diferente a los valores de fecha). - Simplemente extraer el valor de fecha y hora directamente de la base de datos siempre fue más eficiente. Debe perfilar el tiempo adicional que le toma a su aplicación formatear la fecha según lo desee en el nivel de presentación; es muy probable que no desee que SQL Server se involucre en absoluto con el formato bonito (y de hecho muchos argumentarían que aquí es donde esa lógica siempre pertenece).
Aquí solo estamos hablando de microsegundos, pero también estamos hablando de 1000 filas. Escale eso a los tamaños reales de su tabla, y el impacto de elegir el enfoque de formato incorrecto podría ser devastador.
Si desea probar este experimento en su propia máquina, he subido un script de muestra:FormatIsNiceAndAllBut.sql_.zip



