Cuando está profundamente involucrado en la resolución de un problema en SQL Server, a veces desea saber el orden exacto en que se ejecutaron las consultas. Veo esto con procedimientos almacenados más complicados que contienen capas de lógica o en escenarios donde hay mucho código redundante. Extended Events es una opción natural aquí, ya que normalmente se usa para capturar información sobre la ejecución de consultas. A menudo puede usar session_id y la marca de tiempo para comprender el orden de los eventos, pero hay una opción de sesión para XE que es aún más confiable:Rastrear causalidad.
Cuando habilita Rastrear causalidad para una sesión, agrega un GUID y un número de secuencia a cada evento, que luego puede usar para recorrer el orden en que ocurrieron los eventos. La sobrecarga es mínima y puede suponer un importante ahorro de tiempo en muchos escenarios de solución de problemas.
Configurar
Usando la base de datos de WideWorldImporters, crearemos un procedimiento almacenado para usar:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO
Luego crearemos una sesión de evento:
CREATE EVENT SESSION [TrackQueries] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
WHERE ([sqlserver].[is_system]=(0))),
ADD EVENT sqlserver.sql_statement_completed(
WHERE ([sqlserver].[is_system]=(0)))
ADD TARGET package0.event_file
(
SET filename=N'C:\temp\TrackQueries',max_file_size=(256)
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
); También vamos a ejecutar consultas ad-hoc, por lo que capturaremos tanto sp_statement_completed (instrucciones completadas dentro de un procedimiento almacenado) como sql_statement_completed (instrucciones completadas que no están dentro de un procedimiento almacenado). Tenga en cuenta que la opción TRACK_CAUSALITY para la sesión está activada. Nuevamente, esta configuración es específica para la sesión del evento y debe habilitarse antes de iniciarla. No puede habilitar la configuración sobre la marcha, como puede agregar o eliminar eventos y objetivos mientras se ejecuta la sesión.
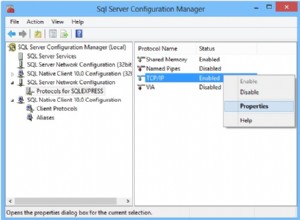
Para iniciar la sesión del evento a través de la interfaz de usuario, simplemente haga clic derecho sobre él y seleccione Iniciar sesión.
Pruebas
Dentro de Management Studio ejecutaremos el siguiente código:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan'; Aquí está nuestra salida XE:

Tenga en cuenta que la primera consulta ejecutada, que está resaltada, es SELECT @@SPID y tiene un GUID de FDCCB1CF-CA55-48AA-8FBA-7F5EBF870674. No ejecutamos esta consulta, se produjo en segundo plano y, aunque la sesión XE está configurada para filtrar las consultas del sistema, esta, por el motivo que sea, aún se captura.
Las siguientes cuatro líneas representan el código que realmente ejecutamos. Están las dos consultas del procedimiento almacenado, el propio procedimiento almacenado y luego nuestra consulta ad-hoc. Todos tienen el mismo GUID, ACBFFD99-2400-4AFF-A33F-351821667B24. Junto al GUID se encuentra el ID de secuencia (seq) y las consultas están numeradas del uno al cuatro.
En nuestro ejemplo, no usamos GO para separar las declaraciones en diferentes lotes. Observe cómo cambia la salida cuando hacemos eso:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
GO
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan';
GO

Todavía tenemos el mismo número de filas totales, pero ahora tenemos tres GUID. Uno para SELECT @@SPID (E8D136B8-092F-439D-84D6-D4EF794AE753), uno para las tres consultas que representan el procedimiento almacenado (F962B9A4-0665-4802-9E6C-B217634D8787) y otro para la consulta ad-hoc (5DD6A5FE -9702-4DE5-8467-8D7CF55B5D80).
Esto es lo que probablemente verá cuando consulte los datos de su aplicación, pero depende de cómo funcione la aplicación. Si utiliza la agrupación de conexiones y las conexiones se restablecen regularmente (lo que se espera), entonces cada conexión tendrá su propio GUID.
Puede recrear esto usando el código de muestra de PowerShell a continuación:
while(1 -eq 1)
{
$SqlConn = New-Object System.Data.SqlClient.SqlConnection;
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;Integrated Security=True;Application Name = MyCoolApp";
$SQLConn.Open()
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT TOP 1 CustomerID FROM Sales.Customers ORDER BY NEWID();"
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlReader = $SqlCmd.ExecuteReader();
$Results = New-Object System.Collections.ArrayList;
while ($SqlReader.Read())
{
$Results.Add($SqlReader.GetSqlInt32(0)) | Out-Null;
}
$SqlReader.Close();
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "Sales.usp_CustomerTransactionInfo"
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CustomerID", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::Int;
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
$Names = New-Object System.Collections.Generic.List``1[System.String]
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT FullName FROM Application.People ORDER BY NEWID();";
$dr = $SqlCmd.ExecuteReader();
while($dr.Read())
{
$Names.Add($dr.GetString(0));
}
$SqlConn.Close();
$name = Get-Random -InputObject $Names;
$query = [String]::Format("SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = '{0}';", $name);
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $sqlconnection.CreateCommand();
$SqlCmd.CommandText = $query
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
} Aquí hay un ejemplo de la salida de eventos extendidos después de dejar que el código se ejecute por un momento:

Hay cuatro GUID diferentes para nuestras cinco declaraciones, y si observa el código anterior, verá que se han realizado cuatro conexiones diferentes. Si modifica la sesión del evento para incluir el evento rpc_completed, puede ver las entradas con exec sp_reset_connection.
Su salida XE dependerá de su código y su aplicación; Mencioné inicialmente que esto era útil para solucionar problemas de procedimientos almacenados más complejos. Considere el siguiente ejemplo:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetFullCustomerInfo]; GO CREATE PROCEDURE [Sales].[usp_GetFullCustomerInfo] @CustomerID INT AS SELECT [o].[CustomerID], [o].[OrderDate], [ol].[StockItemID], [ol].[Quantity], [ol].[UnitPrice] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID ORDER BY [o].[OrderDate] DESC; SELECT [o].[CustomerID], SUM([ol].[Quantity]*[ol].[UnitPrice]) FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID GROUP BY [o].[CustomerID] ORDER BY [o].[CustomerID] ASC; GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetCustomerData]; GO CREATE PROCEDURE [Sales].[usp_GetCustomerData] @CustomerID INT AS BEGIN SELECT * FROM [Sales].[Customers] EXEC [Sales].[usp_CustomerTransactionInfo] @CustomerID EXEC [Sales].[usp_GetFullCustomerInfo] @CustomerID END GO
Aquí tenemos dos procedimientos almacenados, usp_TransctionInfo y usp_GetFullCustomerInfo, que son llamados por otro procedimiento almacenado, usp_GetCustomerData. No es raro ver esto, o incluso ver niveles adicionales de anidamiento con procedimientos almacenados. Si ejecutamos usp_GetCustomerData desde Management Studio, vemos lo siguiente:
EXEC [Sales].[usp_GetCustomerData] 981;

Aquí, todas las ejecuciones ocurrieron en el mismo GUID, BF54CD8F-08AF-4694-A718-D0C47DBB9593, y podemos ver el orden de ejecución de la consulta de uno a ocho usando la columna seq. En los casos en los que se llaman a varios procedimientos almacenados, no es raro que el valor de ID de secuencia llegue a los cientos o miles.
Por último, en el caso de que esté analizando la ejecución de consultas y haya incluido Seguimiento de la causalidad, y encuentre una consulta que tenga un rendimiento deficiente, porque clasificó el resultado según la duración o alguna otra métrica, tenga en cuenta que puede encontrar la otra consultas por agrupación en el GUID:
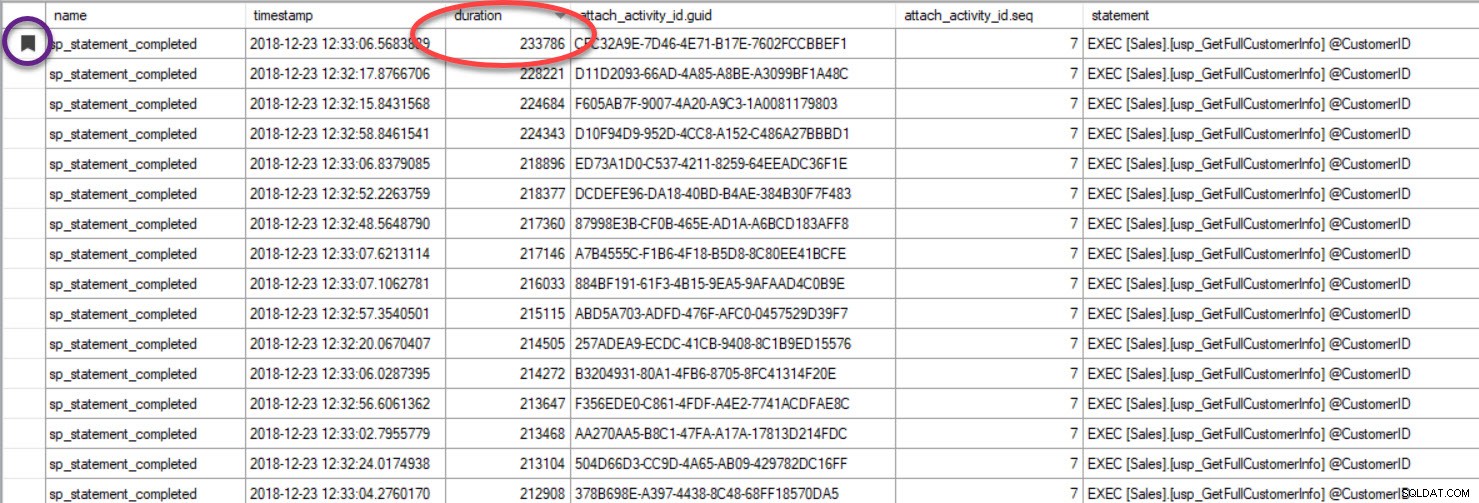
La salida se ha ordenado por duración (el valor más alto en un círculo rojo) y lo marqué (en púrpura) con el botón Alternar marcador. Si queremos ver las otras consultas para el GUID, agrupe por GUID (haga clic con el botón derecho en el nombre de la columna en la parte superior, luego seleccione Agrupar por esta columna) y luego use el botón Siguiente marcador para volver a nuestra consulta:
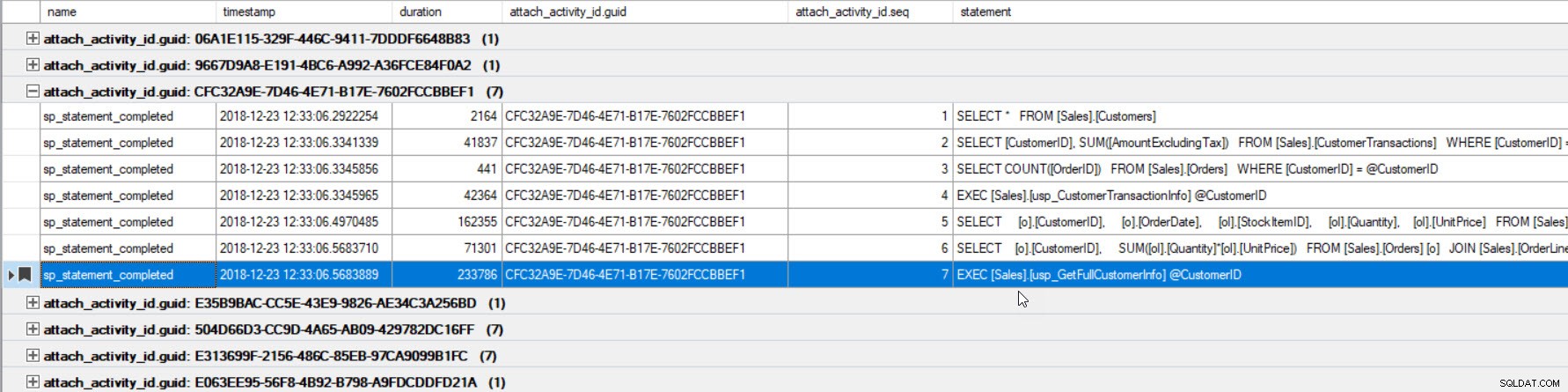
Ahora podemos ver todas las consultas que se ejecutaron dentro de la misma conexión y en el orden de ejecución.
Conclusión
La opción Rastrear causalidad puede ser inmensamente útil para solucionar problemas de rendimiento de consultas y tratar de comprender el orden de los eventos dentro de SQL Server. También es útil cuando se configura una sesión de evento que usa el objetivo pair_matching, para asegurarse de que está haciendo coincidir el campo/acción correcto y encontrando el evento no coincidente adecuado. Nuevamente, esta es una configuración de nivel de sesión, por lo que debe aplicarse antes de iniciar la sesión del evento. Para una sesión que se está ejecutando, detenga la sesión del evento, habilite la opción y luego vuelva a iniciarla.