Los profesionales de datos no siempre pueden usar bases de datos que tengan un diseño óptimo. A veces las cosas que te hacen llorar son cosas que nos hemos hecho a nosotros mismos, porque nos parecieron buenas ideas en ese momento. A veces se deben a aplicaciones de terceros. A veces simplemente te preceden.
En lo que estoy pensando en esta publicación es cuando su columna datetime (o datetime2, o mejor aún, datetimeoffset) es en realidad dos columnas:una para la fecha y otra para la hora. (Si tiene una columna separada nuevamente para la compensación, entonces le daré un abrazo la próxima vez que lo vea, porque probablemente haya tenido que lidiar con todo tipo de dolor).
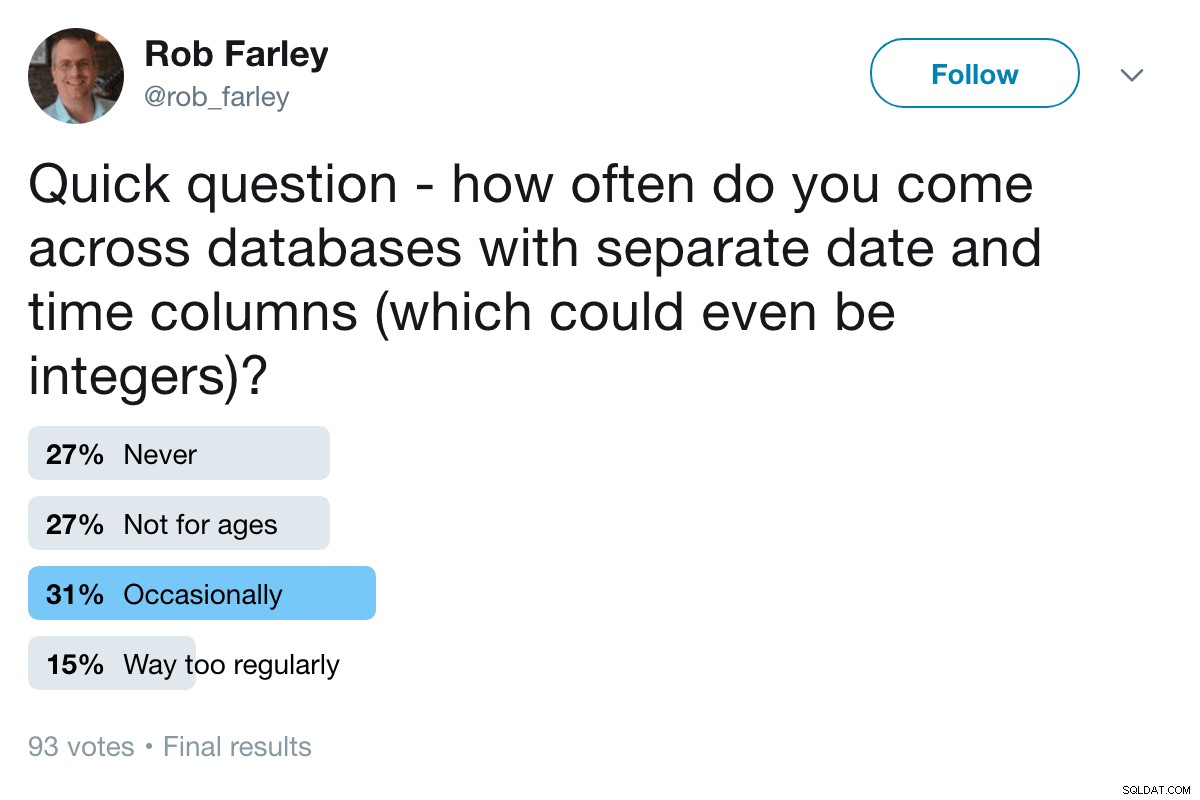
Hice una encuesta en Twitter y descubrí que este es un problema muy real con el que aproximadamente la mitad de ustedes tiene que lidiar de vez en cuando.
AdventureWorks casi hace esto:si observa la tabla Sales.SalesOrderHeader, verá una columna de fecha y hora llamada OrderDate, que siempre tiene fechas exactas. Apuesto a que si es un desarrollador de informes en AdventureWorks, probablemente haya escrito consultas que busquen la cantidad de pedidos en un día en particular, usando GROUP BY OrderDate, o algo así. Incluso si supiera que se trata de una columna de fecha y hora y que existe la posibilidad de que también almacene una hora distinta de la medianoche, aún diría GROUP BY OrderDate solo por el hecho de usar un índice correctamente. GROUP BY CAST (OrderDate AS DATE) simplemente no es suficiente.
Tengo un índice en OrderDate, como lo haría si estuviera consultando regularmente esa columna, y puedo ver que la agrupación por CAST (OrderDate AS DATE) es aproximadamente cuatro veces peor desde la perspectiva de la CPU.
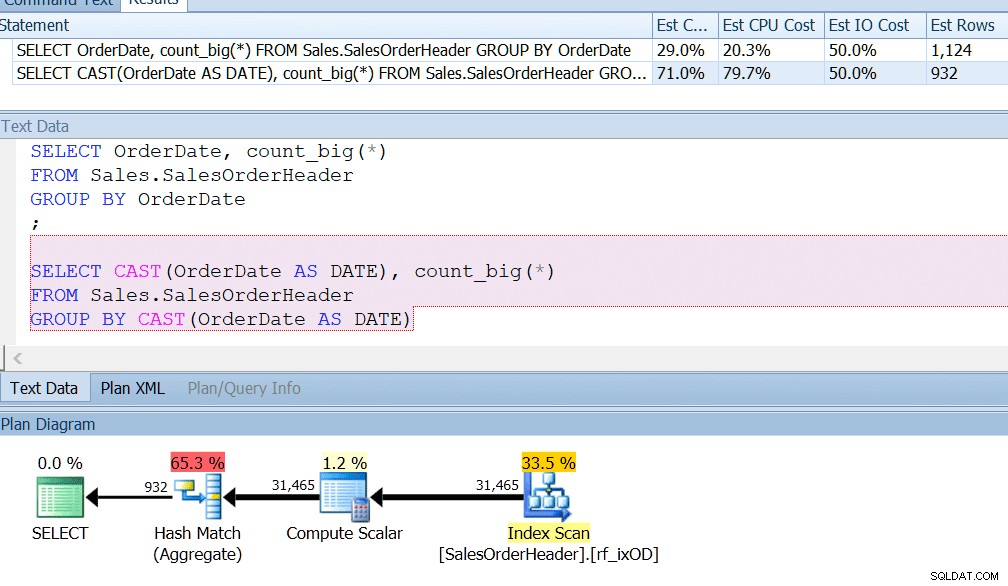
Así que entiendo por qué estaría feliz de consultar su columna como si fuera una fecha, simplemente sabiendo que tendrá un mundo de dolor si cambia el uso de esa columna. Tal vez resuelva esto teniendo una restricción en la mesa. Tal vez solo escondes la cabeza en la arena.
Y cuando alguien viene y dice "Sabes, también deberíamos almacenar la hora en que suceden los pedidos", bueno, piensa en todo el código que asume que OrderDate es simplemente una fecha, y piensa que tener una columna separada llamada OrderTime (tipo de datos de tiempo, por favor) será la opción más sensata. Entiendo. No es ideal, pero funciona sin romper demasiadas cosas.
En este punto, le recomiendo que también cree OrderDateTime, que sería una columna calculada que une las dos (lo que debe hacer agregando la cantidad de días desde el día 0 a CAST (OrderDate as datetime2), en lugar de intentar agregar la hora a fecha, que generalmente es mucho más desordenada). Y luego indexe OrderDateTime, porque eso sería sensato.
Pero muy a menudo, se encontrará con la fecha y la hora como columnas separadas, básicamente sin nada que pueda hacer al respecto. No puede agregar una columna calculada, porque es una aplicación de terceros y no sabe qué podría fallar. ¿Estás seguro de que nunca hacen SELECT *? Espero que algún día nos permitan agregar columnas y ocultarlas, pero por el momento, ciertamente corre el riesgo de romper cosas.
Y, ya sabes, incluso msdb hace esto. Ambos son enteros. Y es por compatibilidad con versiones anteriores, supongo. Pero dudo que esté considerando agregar una columna calculada a una tabla en msdb.
Entonces, ¿cómo consultamos esto? Supongamos que queremos encontrar las entradas que estaban dentro de un rango de fecha y hora en particular.
Hagamos algunos experimentos.
Primero, creemos una tabla con 3 millones de filas e indexemos las columnas que nos interesan.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Podría haberlo convertido en un índice agrupado, pero me imagino que un índice no agrupado es más típico para su entorno).
Nuestros datos se ven así, y quiero encontrar filas entre, digamos, el 2 de agosto de 2011 a las 8:30 y el 5 de agosto de 2011 a las 21:30.
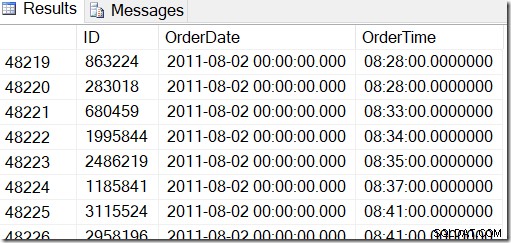
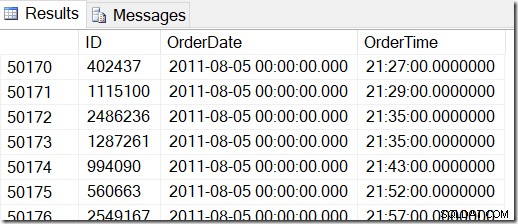
Al revisar los datos, puedo ver que quiero todas las filas entre 48221 y 50171. Eso es 50171-48221+1=1951 filas (el +1 es porque es un rango inclusivo). Esto me ayuda a estar seguro de que mis resultados son correctos. Probablemente tendría algo similar en su máquina, pero no exacto, porque utilicé valores aleatorios al generar mi tabla.
Sé que no puedo hacer algo como esto:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
…porque esto no incluiría algo que sucedió durante la noche del día 4. Esto me da 1268 filas, claramente no está bien.
Una opción es combinar las columnas:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Esto da los resultados correctos. Lo hace. Es solo que esto es completamente no sargable y nos da un escaneo en todas las filas de nuestra tabla. En nuestras 3 millones de filas, puede llevar unos segundos ejecutar esto.
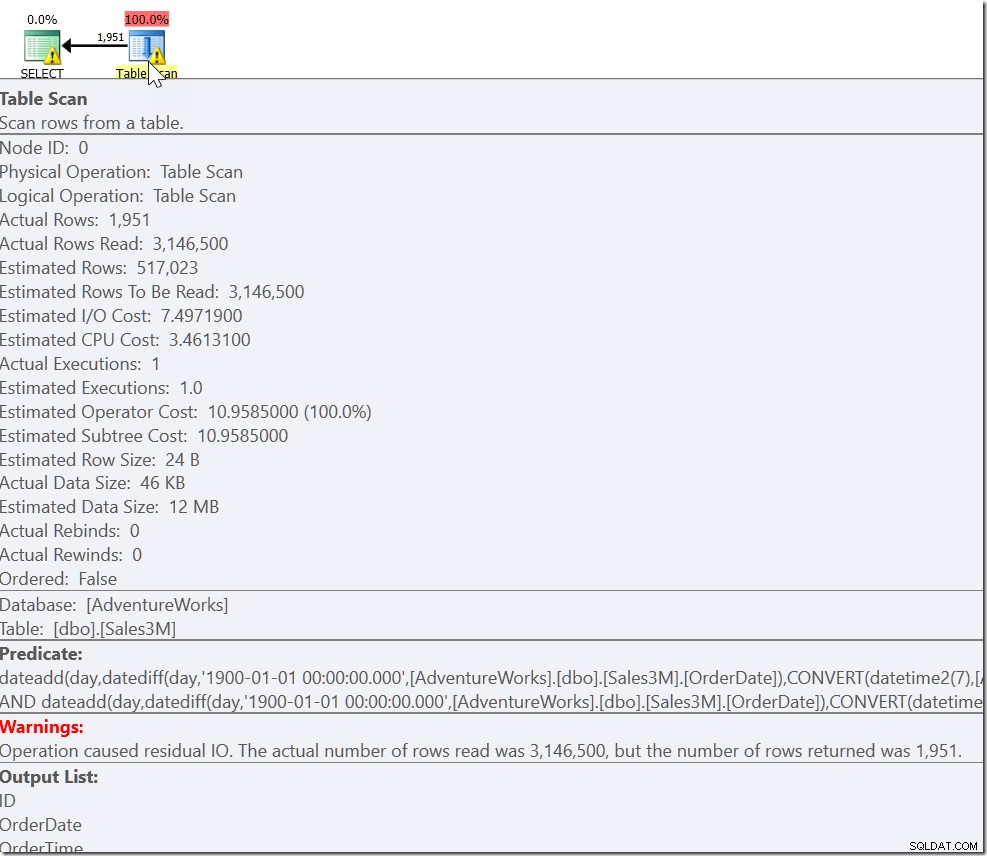
Nuestro problema es que tenemos un caso ordinario y dos casos especiales. Sabemos que cada fila que satisface OrderDate> '20110802' AND OrderDate <'20110805' es una que queremos. Pero también necesitamos cada fila que sea a las 8:30 o después de 20110802 y a las 21:30 o antes de 20110805. Y eso nos lleva a:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
O es horrible, lo sé. También puede dar lugar a escaneos, aunque no necesariamente. Aquí veo tres búsquedas de índice, que se concatenan y luego se verifica su singularidad. El Optimizador de consultas obviamente se da cuenta de que no debe devolver la misma fila dos veces, pero no se da cuenta de que las tres condiciones son mutuamente excluyentes. Y, de hecho, si estuviera haciendo esto en un rango dentro de un solo día, obtendría resultados incorrectos.
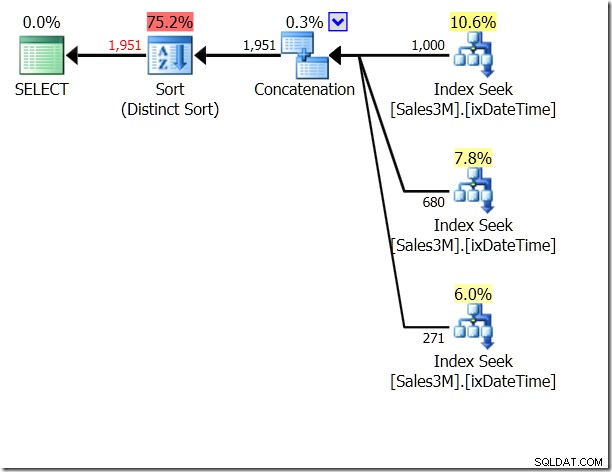
Podríamos usar UNION ALL en esto, lo que significaría que al QO no le importaría si las condiciones eran mutuamente excluyentes. Esto nos da tres búsquedas que están concatenadas, eso es bastante bueno.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Pero todavía son tres búsquedas. Estadísticas IO me dice que son 20 lecturas en mi máquina.

Ahora, cuando pienso en sargabilidad, no solo pienso en evitar poner columnas de índices dentro de expresiones, también pienso en lo que podría ayudar a algo a aparentar sargable
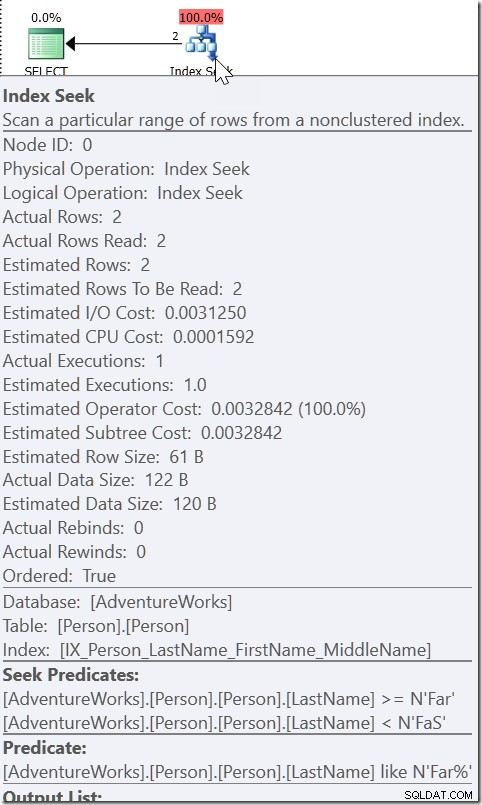
Tome WHERE LastName LIKE 'Far%' por ejemplo. Cuando observo el plan para esto, veo un Seek, con un Predicado Seek que busca cualquier nombre desde Far hasta (pero sin incluir) FaS. Y luego hay un predicado residual que verifica la condición LIKE. Esto no se debe a que el QO considere que LIKE es sargable. Si lo fuera, podría usar LIKE en el predicado de búsqueda. Es porque sabe que todo lo que se satisface con esa condición LIKE debe estar dentro de ese rango.
Tome WHERE CAST(OrderDate AS DATE) ='20110805'
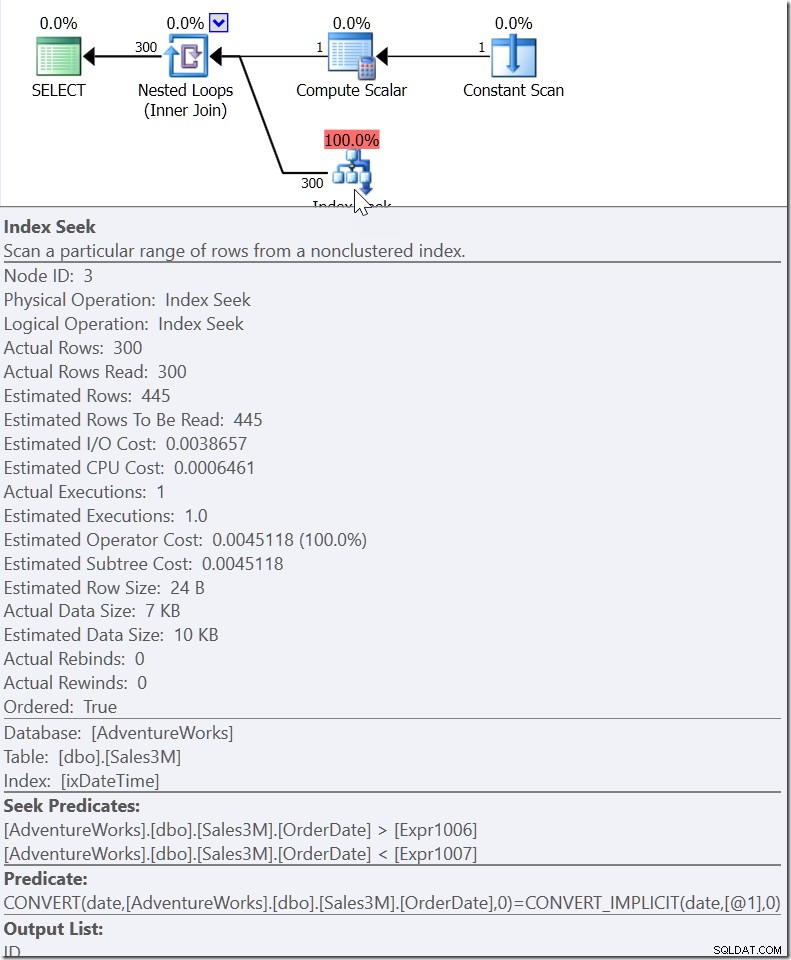
Aquí vemos un Seek Predicate que busca valores de OrderDate entre dos valores que se han elaborado en otra parte del plan, pero creando un rango en el que deben existir los valores correctos. Esto no es>=20110805 00:00 y <20110806 00:00 (que es lo que yo hubiera hecho), es otra cosa. El valor para el inicio de este intervalo debe ser menor que 20110805 00:00, porque es>, no>=. Todo lo que realmente podemos decir es que cuando alguien dentro de Microsoft implementó cómo debería responder el QO a este tipo de predicado, le dieron suficiente información para generar lo que yo llamo un "predicado auxiliar".
Ahora, me encantaría que Microsoft hiciera más funciones sargables, pero esa solicitud en particular se cerró mucho antes de que retiraran Connect.
Pero tal vez lo que quiero decir es que hagan más predicados auxiliares.
El problema con los predicados auxiliares es que es casi seguro que leen más filas de las que desea. Pero sigue siendo mucho mejor que mirar a través de todo el índice.
Sé que todas las filas que quiero devolver tendrán OrderDate entre 20110802 y 20110805. Es solo que hay algunas que no quiero.
Podría simplemente eliminarlos, y esto sería válido:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
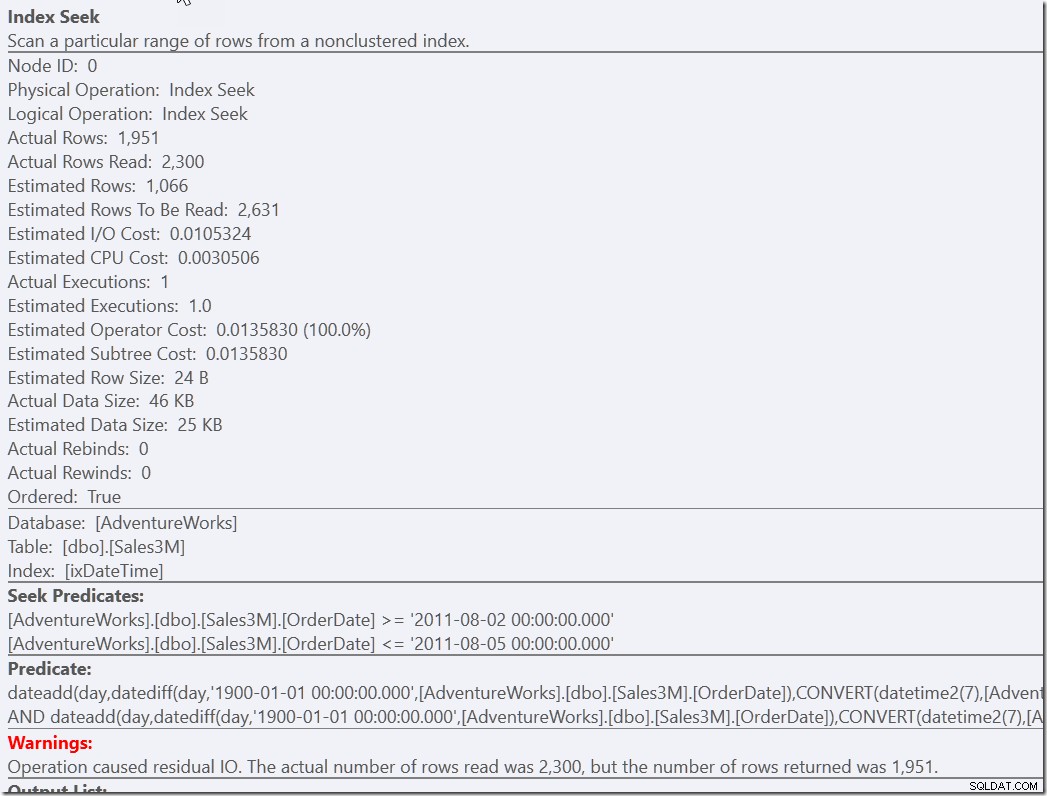
Pero siento que esta es una solución que requiere un poco de esfuerzo de pensamiento para encontrarla. Menos esfuerzo por parte del desarrollador es simplemente proporcionar un predicado auxiliar a nuestra versión correcta pero lenta.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Ambas consultas encuentran las 2300 filas que están en los días correctos y luego deben verificar todas esas filas con los otros predicados. Uno debe verificar las dos condiciones NOT, el otro debe hacer alguna conversión de tipos y operaciones matemáticas. Pero ambos son mucho más rápidos que los que teníamos antes y hacen una sola búsqueda (13 lecturas). Claro, recibo advertencias sobre un RangeScan ineficiente, pero esta es mi preferencia sobre hacer tres eficientes.
De alguna manera, el mayor problema con este último ejemplo es que alguna persona bien intencionada vería que el predicado auxiliar es redundante y podría eliminarlo. Este es el caso con todos los predicados auxiliares. Así que pon un comentario.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Si tiene algo que no encaja en un buen predicado sargable, elabore uno que sí lo sea y luego averigüe qué necesita excluir de él. Es posible que se le ocurra una solución más agradable.
@rob_farley