Esta publicación es parte de una serie sobre objetivos de fila. Puedes encontrar las otras partes aquí:
- Parte 1:Establecer e identificar objetivos de fila
- Parte 2:semiuniones
- Parte 3:Anti-uniones
Aplicar Anti Join con un operador superior
A menudo verá un operador Superior (1) en el lado interno en aplicar combinación anti planes de ejecución. Por ejemplo, usando la base de datos AdventureWorks:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); El plan muestra un operador Superior (1) en el lado interno de la unión anti de aplicación (referencias externas):
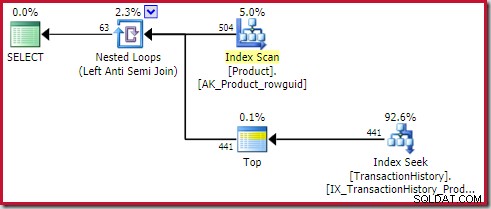
Este operador superior es completamente redundante . No es necesario para la corrección, la eficiencia o para garantizar que se establezca un objetivo de fila.
El operador de aplicación anti-unión dejará de buscar filas en el lado interno (para la iteración actual) tan pronto como se vea una fila en la unión. Es perfectamente posible generar un plan de aplicación anti unión sin la parte superior. Entonces, ¿por qué hay un operador Top en este plan?
Fuente del operador Top
Para comprender de dónde proviene este operador Top sin sentido, debemos seguir los pasos principales que se tomaron durante la compilación y optimización de nuestra consulta de ejemplo.
Como de costumbre, la consulta se analiza primero en un árbol. Esto presenta un operador lógico 'no existe' con una subconsulta, que se asemeja mucho a la forma escrita de la consulta en este caso:

La subconsulta no existe se despliega en una unión anti-aplicación:

Luego, esto se transforma aún más en una antisemi-unión izquierda lógica. El árbol resultante pasado a la optimización basada en costos se ve así:

La primera exploración realizada por el optimizador basado en costos es introducir un distintivo lógico operación en la entrada anti-unión inferior, para producir valores únicos para la tecla anti-unión. La idea general es que, en lugar de probar valores duplicados en la unión, el plan podría beneficiarse de agrupar esos valores por adelantado.
La regla de exploración responsable se llama LASJNtoLASJNonDist (semi unión izquierda anti semi unión a izquierda anti semi unión en distinto). Aún no se ha realizado una implementación física ni se ha calculado el coste, por lo que solo se trata del optimizador que explora una equivalencia lógica, basada en la presencia de ProductID duplicados. valores. El nuevo árbol con la operación de agrupación agregada se muestra a continuación:

La siguiente transformación lógica considerada es reescribir la combinación como aplicar . Esto se explora usando la regla LASJNtoApply (semi unión izquierda anti para aplicar con selección relacional). Como se mencionó anteriormente en la serie, la transformación anterior de aplicar a unir fue para habilitar transformaciones que funcionan específicamente en uniones. Siempre es posible reescribir una unión como una aplicación, por lo que esto amplía el rango de optimizaciones disponibles.
Ahora, el optimizador no siempre considere aplicar una reescritura como parte de la optimización basada en costos. Tiene que haber algo en el árbol lógico para que valga la pena empujar el predicado de unión hacia abajo en el lado interior. Por lo general, esto será la existencia de un índice coincidente, pero existen otros objetivos prometedores. En este caso, es la clave lógica en ProductID creado por la operación agregada.
El resultado de esta regla es una unión anti correlacionada con selección en el lado interior:

A continuación, el optimizador considera mover la selección relacional (el predicado de combinación correlacionada) más abajo en el lado interno, más allá de la distinción (agrupar por agregado) introducida previamente por el optimizador. Esto se hace mediante la regla SelOnGbAgg , que mueve tanto de una selección (predicado) más allá de un grupo adecuado por agregado como puede (parte de la selección puede quedar atrás). Esta actividad ayuda a empujar selecciones lo más cerca posible de los operadores de acceso a datos de nivel de hoja, para eliminar filas antes y facilitar la comparación de índices posterior.
En este caso, el filtro está en la misma columna que la operación de agrupación, por lo que la transformación es válida. Da como resultado que toda la selección se coloque debajo del agregado:

La operación final de interés se realiza mediante la regla GbAggToConstScanOrTop . Esta transformación busca reemplazar un grupo por agregado con un Escaneo Constante o Superior operación lógica. Esta regla coincide con nuestro árbol porque la columna de agrupación es constante para cada fila que pasa por la selección empujada hacia abajo. Se garantiza que todas las filas tengan el mismo ProductID . La agrupación en ese valor único siempre producirá una fila. Por lo tanto, es válido transformar el agregado a un Top (1). Así que aquí es de donde viene la parte superior.
Implementación y Costeo
El optimizador ahora ejecuta una serie de reglas de implementación para encontrar operadores físicos para cada una de las alternativas lógicas prometedoras que ha considerado hasta ahora (almacenadas de manera eficiente en una estructura de memo). Las opciones físicas hash y merge anti join provienen del árbol inicial con agregado introducido (cortesía de regla LASJNtoLASJNonDist recordar). La aplicación necesita un poco más de trabajo para construir una parte superior física y hacer coincidir la selección con una búsqueda de índice.
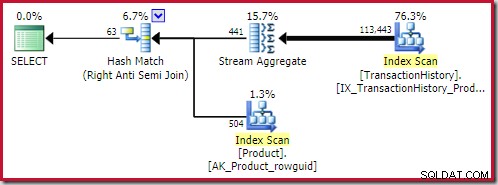
El mejor hash anti-join la solución encontrada tiene un costo de 0.362143 unidades:
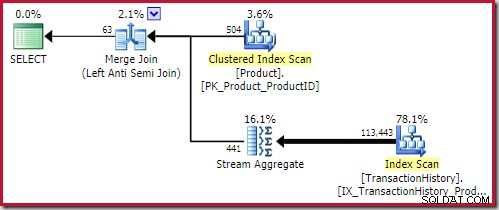
La mejor combinación anti-unión la solución viene en 0.353479 unidades (ligeramente más barato):
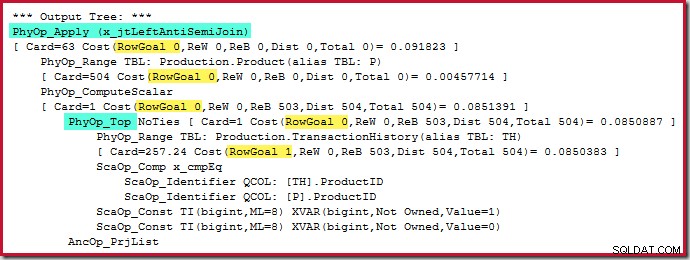
El aplicar anti unión cuesta 0.091823 unidades (más barato por un amplio margen):
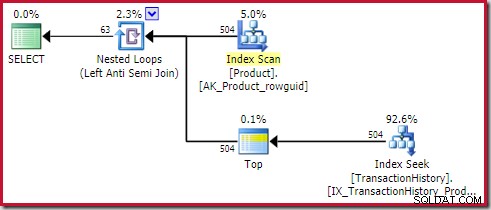
El lector astuto puede notar que los recuentos de filas en el lado interior de la unión antiaplicación (504) difieren de la captura de pantalla anterior del mismo plan. Esto se debe a que este es un plan estimado, mientras que el plan anterior era posterior a la ejecución. Cuando se ejecuta este plan, solo se encuentran un total de 441 filas en el lado interno en todas las iteraciones. Esto resalta una de las dificultades de visualización con la aplicación de planes de combinación semi/anti:la estimación mínima del optimizador es una fila, pero una combinación semi o anti siempre ubicará una fila o ninguna fila en cada iteración. Las 504 filas que se muestran arriba representan 1 fila en cada una de las 504 iteraciones. Para que los números coincidan, la estimación debería ser 441/504 =0,875 filas cada vez, lo que probablemente confundiría a la gente.
De todos modos, el plan anterior es lo suficientemente 'afortunado' como para calificar para un gol de fila en el lado interior de la unión anti de aplicación por dos razones:
- La unión anti se transforma de una unión a una aplicación en el optimizador basado en costos. Esto establece un objetivo de fila (como se establece en la parte tres).
- El operador Top(1) también establece un objetivo de fila en su subárbol.
El operador Superior en sí no tiene un objetivo de fila (de la aplicación) ya que el objetivo de fila de 1 no sería menor que la estimación regular, que también es 1 fila (Tarjeta =1 para el PhyOp_Top a continuación):
El patrón Anti Unión Anti
La siguiente forma de plan general es una que considero un patrón anti:
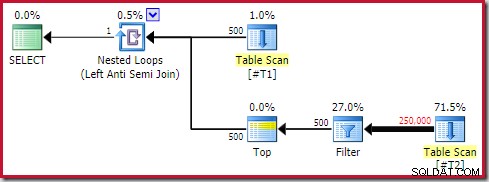
No todos los planes de ejecución que contengan una antiunión de aplicación con un operador Superior (1) en su lado interno serán problemáticos. Sin embargo, es un patrón a reconocer y que casi siempre requiere más investigación.
Los cuatro elementos principales a tener en cuenta son:
- Un bucle anidado correlacionado (aplicar ) contra la unión
- A Parte superior (1) operador inmediatamente en el lado interior
- Un número significativo de filas en la entrada externa (por lo que el lado interno se ejecutará muchas veces)
- Un potencialmente caro subárbol debajo de la parte superior
El subárbol "$$$" es uno que es potencialmente costoso en tiempo de ejecución . Esto puede ser difícil de reconocer. Si tenemos suerte, habrá algo obvio como una tabla completa o un escaneo de índice. En casos más desafiantes, el subárbol se verá perfectamente inocente a primera vista, pero contendrá algo costoso cuando se mire más de cerca. Para dar un ejemplo bastante común, es posible que vea una búsqueda de índice que se espera que devuelva una pequeña cantidad de filas, pero que contiene un predicado residual costoso que prueba una gran cantidad de filas para encontrar las pocas que califican.
El ejemplo de código anterior de AdventureWorks no tenía un subárbol "potencialmente costoso". Index Seek (sin predicado residual) sería un método de acceso óptimo independientemente de las consideraciones de objetivo de fila. Este es un punto importante:proporcionar al optimizador un siempre eficiente La ruta de acceso a datos en el lado interno de una combinación correlacionada siempre es una buena idea. Esto es aún más cierto cuando la aplicación se ejecuta en modo antiunión con un operador Superior (1) en el lado interior.
Veamos ahora un ejemplo que tiene un rendimiento de tiempo de ejecución bastante bajo debido a este patrón anti.
Ejemplo
El siguiente script crea dos tablas temporales de montón. El primero tiene 500 filas que contienen los números enteros del 1 al 500 inclusive. La segunda tabla tiene 500 copias de cada fila de la primera tabla, para un total de 250.000 filas. Ambas tablas usan sql_variant tipo de datos.
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Rendimiento
Ahora ejecutamos una consulta en busca de filas en la tabla más pequeña que no están presentes en la tabla más grande (por supuesto que no hay ninguna):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); Esta consulta se ejecuta durante aproximadamente 20 segundos , que es un tiempo terriblemente largo para comparar 500 filas con 250,000. El plan estimado de SSMS hace que sea difícil ver por qué el rendimiento podría ser tan bajo:
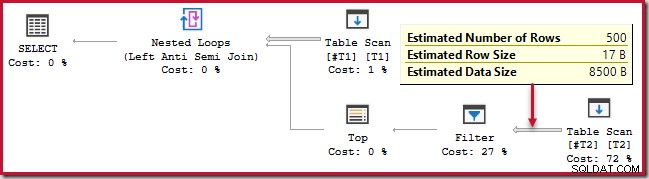
El observador debe tener en cuenta que los planes estimados de SSMS muestran estimaciones del lado interno por iteración de la unión de bucle anidado. De manera confusa, los planes reales de SSMS muestran el número de filas en todas las iteraciones . Plan Explorer realiza automáticamente los cálculos simples necesarios para que los planes estimados también muestren el número total de filas esperadas:
Aun así, el rendimiento del tiempo de ejecución es mucho peor de lo estimado. El plan de ejecución posterior a la ejecución (real) es:
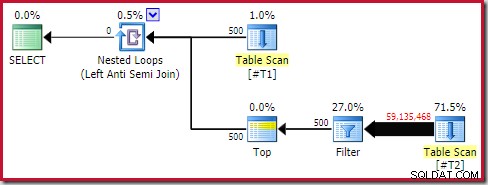
Tenga en cuenta el filtro separado, que normalmente se empujaría hacia abajo en el escaneo como un predicado residual. Esta es la razón para usar sql_variant tipo de datos; evita empujar el predicado, lo que hace que la gran cantidad de filas del escaneo sea más fácil de ver.
Análisis
El motivo de la discrepancia se reduce a cómo el optimizador estima la cantidad de filas que necesitará leer de Table Scan para cumplir con el objetivo de una fila establecido en el filtro. La suposición simple es que los valores se distribuyen uniformemente en la tabla, por lo que para encontrar 1 de los 500 valores únicos presentes, SQL Server deberá leer 250 000/500 =500 filas. Más de 500 iteraciones, lo que equivale a 250 000 filas.
La suposición de uniformidad del optimizador es general, pero no funciona bien aquí. Puede leer más sobre esto en Solicitud de objetivo de una fila de Joe Obbish y votar por su sugerencia en el foro de comentarios de reemplazo de Connect en Use More Than Density to Cost a Scan on the Inner Side of a Nested Loop with TOP.
Mi opinión sobre este aspecto específico es que el optimizador debe retroceder rápidamente de una suposición de uniformidad simple cuando el operador está en el lado interno de una unión de bucles anidados (es decir, los rebobinados estimados más los reenlaces son mayores que uno). Una cosa es suponer que necesitamos leer 500 filas para encontrar una coincidencia en la primera iteración del ciclo. Asumir esto en cada iteración parece muy poco probable que sea exacto; significa que las primeras 500 filas encontradas deben contener uno de cada valor distinto. Es muy poco probable que este sea el caso en la práctica.
Una serie de eventos desafortunados
Independientemente de la forma en que se cuesten los principales operadores repetidos, me parece que toda la situación debe ser evitada en primer lugar . Recuerde cómo se creó el Top en este plan:
- El optimizador introdujo un agregado distinto en el lado interno como una optimización del rendimiento .
- Este agregado proporciona una clave en la columna de unión por definición (produce unicidad).
- Esta clave construida proporciona un objetivo para la conversión de una unión a una aplicación.
- El predicado (selección) asociado con la aplicación se empuja más allá del agregado.
- Ahora se garantiza que el agregado operará en un solo valor distinto por iteración (dado que es un valor de correlación).
- El agregado se reemplaza por un Top (1).
Todas estas transformaciones son válidas individualmente. Son parte de las operaciones normales del optimizador, ya que busca un plan de ejecución razonable. Desafortunadamente, el resultado aquí es que el agregado especulativo introducido por el optimizador termina convirtiéndose en un Top (1) con un objetivo de fila asociado. . El objetivo de la fila conduce a un cálculo de costos inexacto basado en la suposición de uniformidad y luego a la selección de un plan que es muy poco probable que funcione bien.
Ahora, uno podría objetar que la combinación anti aplicar tendría un objetivo de fila de todos modos, sin la secuencia de transformación anterior. El contraargumento es que el optimizador no consideraría transformación de anti unión a aplicar unión anti (estableciendo el objetivo de la fila) sin el agregado introducido por el optimizador dando el LASJNtoApply gobernar algo a lo que atar. Además, hemos visto (en la tercera parte) que si la combinación anti hubiera ingresado a la optimización basada en costos como una aplicación (en lugar de una combinación), nuevamente habría objetivo sin fila. .
En resumen, el objetivo de fila en el plan final es completamente artificial y no tiene base en la especificación de consulta original. El problema con el objetivo superior y fila es un efecto secundario de este aspecto más fundamental.
Soluciones alternativas
Hay muchas soluciones potenciales a este problema. La eliminación de cualquiera de los pasos en la secuencia de optimización anterior garantizará que el optimizador no produzca una implementación de aplicación anti-unión con costos reducidos dramáticamente (y artificialmente). Con suerte, este problema se solucionará en SQL Server más pronto que tarde.
Mientras tanto, mi consejo es que tenga cuidado con el patrón anti unión anti. Asegúrese de que el lado interno de una unión anti-aplicación siempre tenga una ruta de acceso eficiente para todas las condiciones de tiempo de ejecución. Si esto no es posible, es posible que deba usar sugerencias, deshabilitar objetivos de fila, usar una guía de plan o forzar un plan de almacenamiento de consultas para obtener un rendimiento estable de las consultas anti-unión.
Resumen de la serie
Hemos cubierto mucho terreno en las cuatro entregas, así que aquí hay un resumen de alto nivel:
- Parte 1:Establecer e identificar objetivos de fila
- La sintaxis de consulta no determina la presencia o ausencia de un objetivo de fila.
- Solo se establece un objetivo de fila cuando el objetivo es inferior a la estimación habitual.
- Los operadores principales físicos (incluidos los introducidos por el optimizador) agregan un objetivo de fila a su subárbol.
- UN
FASToSET ROWCOUNTestablece un objetivo de fila en la raíz del plan. - Semi unión y anti unión pueden agregar un objetivo de fila.
- SQL Server 2017 CU3 agrega el atributo de plan de presentación EstimateRowsWithoutRowGoal para operadores afectados por un objetivo de fila
- La información del objetivo de la fila se puede revelar mediante indicadores de seguimiento no documentados 8607 y 8612.
- Parte 2:semiuniones
- No es posible expresar una combinación semi directamente en T-SQL, por lo que usamos sintaxis indirecta, p.
IN,EXISTS, oINTERSECT. - Estas sintaxis se analizan en un árbol que contiene una aplicación (unión correlacionada).
- El optimizador intenta transformar la aplicación en una unión regular (no siempre es posible).
- Las semiuniones de hash, fusión y bucles anidados normales no establecen un objetivo de fila.
- Aplicar unión semi siempre establece un objetivo de fila.
- La aplicación de semiunión se puede reconocer al tener referencias externas en el operador de unión de bucles anidados.
- Aplicar semiunión no utiliza un operador Superior (1) en el lado interior.
- Parte 3:Anti-uniones
- También analizado en una aplicación, con un intento de reescribirlo como una unión (no siempre es posible).
- Las anticombinaciones de hash, merge y bucles anidados regulares no establecen un objetivo de fila.
- Aplicar anti-unión no siempre establece un objetivo de fila.
- Solo las reglas de optimización basada en costos (CBO) que transforman la combinación anti para aplicar un objetivo de fila establecido.
- La combinación anti debe ingresar CBO como una combinación (no se aplica). De lo contrario, la unión para aplicar la transformación no puede ocurrir.
- Para ingresar a CBO como una unión, la reescritura previa a la CBO de aplicar para unirse debe haber tenido éxito.
- CBO solo explora la reescritura de una unión anti a una aplicación en casos prometedores.
- Las simplificaciones previas a la CBO se pueden ver con el indicador de seguimiento no documentado 8621.
- Parte 4:Anti Unión Anti Patrón
- El optimizador solo establece un objetivo de fila para aplicar anti-unión cuando existe una razón prometedora para hacerlo.
- Desafortunadamente, varias transformaciones del optimizador que interactúan agregan un operador Superior (1) al lado interno de una combinación anti-aplicación.
- El operador Superior es redundante; no es necesario para la corrección o la eficiencia.
- La parte superior siempre establece un objetivo de fila (a diferencia de la aplicación, que necesita una buena razón).
- El objetivo de fila injustificado puede generar un rendimiento extremadamente bajo.
- Cuidado con un subárbol potencialmente costoso debajo de la parte superior artificial (1).