Recientemente escribí una publicación sobre DISTINCT y GROUP BY. Fue una comparación que mostró que GROUP BY es generalmente una mejor opción que DISTINCT. Está en un sitio diferente, pero asegúrese de volver a sqlperformance.com inmediatamente después...
Una de las comparaciones de consultas que mostré en esa publicación fue entre GROUP BY y DISTINCT para una subconsulta, lo que muestra que DISTINCT es mucho más lento, porque tiene que obtener el nombre del producto para cada fila en la tabla de ventas, en lugar de que solo para cada ProductID diferente. Esto es bastante claro a partir de los planes de consulta, donde puede ver que en la primera consulta, Aggregate opera con datos de una sola tabla, en lugar de con los resultados de la combinación. Ah, y ambas consultas dan las mismas 266 filas.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

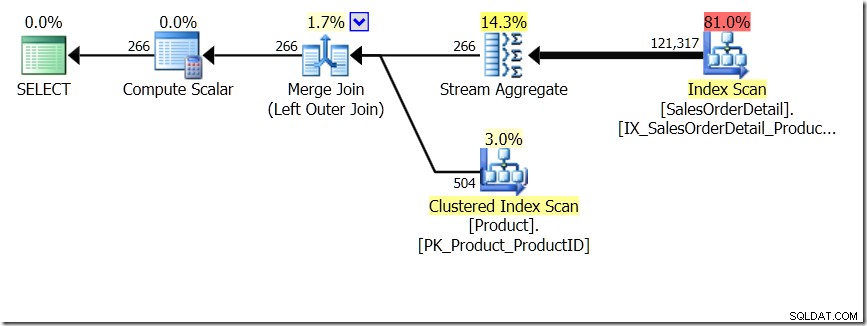
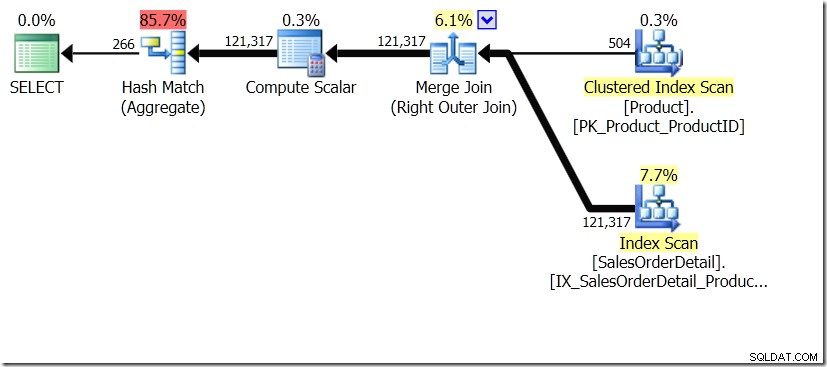
Ahora, se ha señalado, incluso por Adam Machanic (@adammachanic) en un tweet que hace referencia a la publicación de Aaron sobre GROUP BY v DISTINCT que las dos consultas son esencialmente diferentes, que una en realidad está solicitando el conjunto de combinaciones distintas en los resultados de la subconsulta, en lugar de ejecutar la subconsulta a través de los distintos valores que se pasan. Es lo que vemos en el plan y es la razón por la que el rendimiento es tan diferente.
Lo que pasa es que todos asumiríamos que los resultados van a ser idénticos.
Pero eso es una suposición, y no es buena.
Me voy a imaginar por un momento que el Optimizador de consultas ha ideado un plan diferente. Utilicé sugerencias para esto, pero como sabrá, el Optimizador de consultas puede optar por crear planes en todo tipo de formas por todo tipo de razones.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
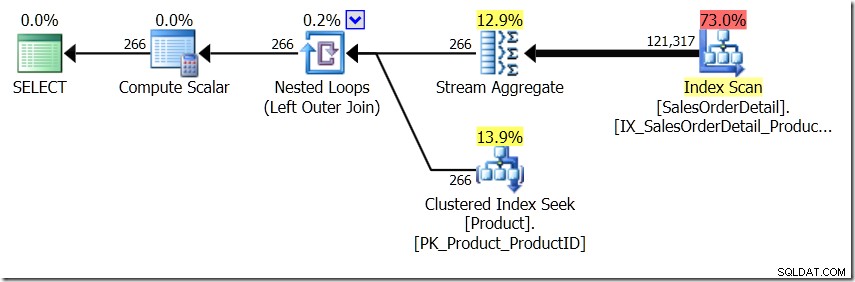
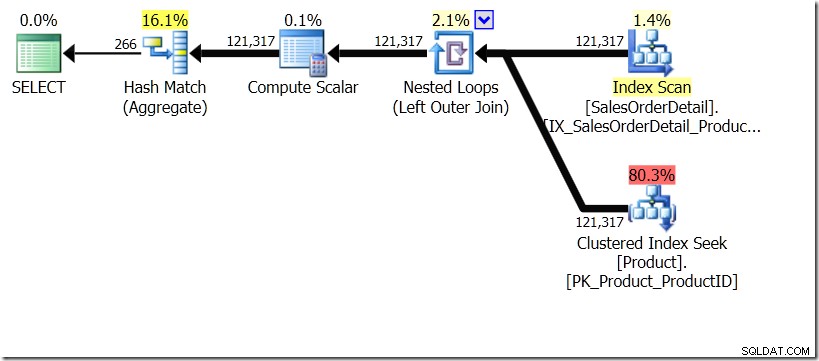
En esta situación, hacemos 266 búsquedas en la tabla de productos, una para cada ID de producto diferente que nos interese, o 121 317 búsquedas. Entonces, si estamos pensando en un ID de producto en particular, sabemos que vamos a obtener un solo nombre del primero. Y asumimos que vamos a obtener un solo nombre para ese ID de producto, incluso si tenemos que pedirlo cien veces. Simplemente asumimos que vamos a obtener los mismos resultados.
Pero, ¿y si no lo hacemos?
Esto suena como una cuestión de nivel de aislamiento, así que usemos NOLOCK cuando lleguemos a la tabla de productos. Y ejecutemos (en una ventana diferente) un script que cambia el texto en las columnas de Nombre. Lo haré una y otra vez, para intentar obtener algunos de los cambios entre mi consulta.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Ahora, mis resultados son diferentes. Los planes son los mismos (excepto por la cantidad de filas que salen del Hash Aggregate en la segunda consulta), pero mis resultados son diferentes.
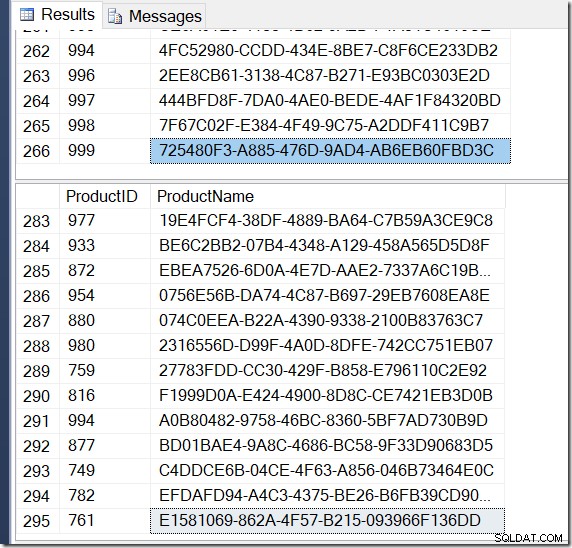
Efectivamente, tengo más filas con DISTINCT, porque encuentra diferentes valores de Nombre para el mismo ProductID. Y no necesariamente tengo 295 filas. Otro que lo ejecuto, podría obtener 273, o 300, o posiblemente, 121,317.
No es difícil encontrar un ejemplo de un ProductID que muestre múltiples valores de Nombre, lo que confirma lo que está pasando.

Claramente, para asegurarnos de que no vemos estas filas en los resultados, necesitaríamos NO usar DISTINCT o usar un nivel de aislamiento más estricto.
La cosa es que aunque mencioné usar NOLOCK para este ejemplo, no necesitaba hacerlo. Esta situación ocurre incluso con LECTURA COMPROMETIDA, que es el nivel de aislamiento predeterminado en muchos sistemas SQL Server.
Verá, necesitamos el nivel de aislamiento de LECTURA REPETIBLE para evitar esta situación, para mantener los bloqueos en cada fila una vez que se haya leído. De lo contrario, un subproceso separado podría cambiar los datos, como vimos.
Pero... no puedo mostrarte que los resultados son fijos, porque no pude evitar un interbloqueo en la consulta.
Así que cambiemos las condiciones, asegurándonos de que nuestra otra consulta sea un problema menor. En lugar de actualizar toda la tabla a la vez (lo que es mucho menos probable en el mundo real), actualicemos una sola fila a la vez.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Ahora, aún podemos demostrar el problema con un nivel de aislamiento menor, como LECTURA COMPROMETIDA o LECTURA NO COMPROMETIDA (aunque es posible que deba ejecutar la consulta varias veces si obtiene 266 la primera vez, porque la posibilidad de actualizar una fila durante la consulta es menor), y ahora podemos demostrar que REPEATABLE READ lo soluciona (sin importar cuántas veces ejecutemos la consulta).
LECTURA REPETIBLE hace lo que dice en la lata. Una vez que lee una fila dentro de una transacción, se bloquea para asegurarse de que pueda repetir la lectura y obtener los mismos resultados. Los niveles de aislamiento menores no eliminan esos bloqueos hasta que intenta cambiar los datos. Si su plan de consulta nunca necesita repetir una lectura (como es el caso con la forma de nuestros planes GROUP BY), entonces no necesitará LECTURA REPETIBLE.
Podría decirse que siempre deberíamos usar los niveles de aislamiento más altos, como LECTURA REPETIBLE o SERIALIZABLE, pero todo se reduce a averiguar qué necesitan nuestros sistemas. Estos niveles pueden introducir bloqueos no deseados, y los niveles de aislamiento SNAPSHOT requieren un control de versiones que también tiene un precio. Para mí, creo que es una compensación. Si solicito una consulta que podría verse afectada por el cambio de datos, es posible que deba aumentar el nivel de aislamiento por un tiempo.
Idealmente, simplemente no actualice los datos que se acaban de leer y es posible que deban leerse nuevamente durante la consulta, de modo que no necesite LECTURA REPETIBLE. Pero definitivamente vale la pena comprender lo que puede suceder y reconocer que este es el tipo de escenario en el que DISTINCT y GROUP BY pueden no ser lo mismo.
@rob_farley