SQL Server ofrece dos métodos para recopilar datos de diagnóstico y solución de problemas sobre la carga de trabajo ejecutada en el servidor:seguimiento de SQL y eventos extendidos. A partir de SQL Server 2012, la implementación de Extended Events proporciona capacidades de recopilación de datos comparables a las de SQL Trace y se puede usar para comparar la sobrecarga en la que incurren estas dos características. En este artículo, analizaremos la comparación de la "sobrecarga del observador" que se produce al usar SQL Trace y Extended Events en varias configuraciones para determinar el impacto en el rendimiento que la recopilación de datos puede tener en nuestra carga de trabajo mediante el uso de una carga de trabajo de reproducción. captura y reproducción distribuida.
El entorno de prueba
El entorno de prueba se compone de seis máquinas virtuales, un controlador de dominio, un servidor SQL Server 2012 Enterprise edition y cuatro servidores cliente con el servicio de cliente Distributed Replay instalado en ellos. Se probaron diferentes configuraciones de host para este artículo y se obtuvieron resultados similares de las tres configuraciones diferentes que se probaron en función de la relación de impacto. El servidor de SQL Server Enterprise Edition está configurado con 4 vCPU y 4 GB de RAM. Los cinco servidores restantes están configurados con 1 CPU virtual y 1 GB de RAM. El servicio del controlador Distributed Replay se ejecutó en el servidor de la edición Enterprise de SQL Server 2012 porque requiere una licencia Enterprise para usar más de un cliente para la reproducción.
Carga de trabajo de prueba
La carga de trabajo de prueba utilizada para la captura de reproducción es la carga de trabajo de AdventureWorks Books Online que creé el año pasado para generar cargas de trabajo simuladas en SQL Server. Esta carga de trabajo utiliza las consultas de ejemplo de Books Online en la familia de bases de datos AdventureWorks y está controlada por PowerShell. La carga de trabajo se configuró en cada uno de los cuatro clientes de reproducción y se ejecutó con cuatro conexiones totales al servidor SQL desde cada uno de los servidores del cliente para generar una captura de seguimiento de reproducción de 1 GB. El seguimiento de la reproducción se creó con la plantilla TSQL_Replay de SQL Server Profiler, se exportó a un script y se configuró como un seguimiento del lado del servidor en un archivo. Una vez que se capturó el archivo de seguimiento de reproducción, se preprocesó para su uso con Distributed Replay y luego los datos de reproducción se usaron como la carga de trabajo de reproducción para todas las pruebas.
Configuración de reproducción
La operación de reproducción se configuró para usar la configuración del modo de estrés para impulsar la cantidad máxima de carga contra la instancia de prueba de SQL Server. Además, la configuración utiliza una escala de tiempo de pensar y conectar reducida, que ajusta la relación de tiempo entre el inicio del seguimiento de la reproducción y el momento en que realmente ocurrió un evento hasta el momento en que se reproduce durante la operación de reproducción, para permitir que los eventos se reproduzcan en escala máxima. La escala de estrés para la reproducción también se configura por spid. Los detalles del archivo de configuración para la operación de reproducción fueron los siguientes:
<?xml version="1.0" encoding="utf-8"?>
<Options>
<ReplayOptions>
<Server>SQL2K12-SVR1</Server>
<SequencingMode>stress</SequencingMode>
<ConnectTimeScale>1</ConnectTimeScale>
<ThinkTimeScale>1</ThinkTimeScale>
<HealthmonInterval>60</HealthmonInterval>
<QueryTimeout>3600</QueryTimeout>
<ThreadsPerClient>255</ThreadsPerClient>
<EnableConnectionPooling>Yes</EnableConnectionPooling>
<StressScaleGranularity>spid</StressScaleGranularity>
</ReplayOptions>
<OutputOptions>
<ResultTrace>
<RecordRowCount>No</RecordRowCount>
<RecordResultSet>No</RecordResultSet>
</ResultTrace>
</OutputOptions>
</Options> Durante cada una de las operaciones de reproducción, se recopilaron contadores de rendimiento en intervalos de cinco segundos para los siguientes contadores:
- Procesador\% Tiempo de procesador\_Total
- Servidor SQL\Estadísticas SQL\Solicitudes por lotes/seg
Estos contadores se utilizarán para medir la carga general del servidor y las características de rendimiento de cada una de las pruebas para comparar.
Configuraciones de prueba
Se probaron un total de siete configuraciones diferentes con Distributed Replay:
- Línea de base
- Rastreo del lado del servidor
- Perfilador en el servidor
- Perfilador de forma remota
- Eventos extendidos a event_file
- Eventos extendidos a ring_buffer
- Eventos extendidos a event_stream
Cada prueba se repitió tres veces para garantizar que los resultados fueran consistentes en las diferentes pruebas y para proporcionar un conjunto promedio de resultados para comparar. Para las pruebas de referencia iniciales, no se configuró ninguna recopilación de datos adicional para la instancia de SQL Server, pero las recopilaciones de datos predeterminadas que se envían con SQL Server 2012 se dejaron habilitadas:el seguimiento predeterminado y la sesión de eventos system_health. Esto refleja la configuración general de la mayoría de los servidores SQL, ya que, por lo general, no se recomienda deshabilitar la sesión predeterminada de rastreo o system_health debido a los beneficios que brindan a los administradores de bases de datos. Esta prueba se usó para determinar la línea de base general para la comparación con las pruebas en las que se realizó la recopilación de datos adicionales. Las pruebas restantes se basan en la plantilla TSQL_SPs que se incluye con SQL Server Profiler y recopila los siguientes eventos:
- Auditoría de seguridad\Inicio de sesión de auditoría
- Auditoría de seguridad\Cierre de sesión de auditoría
- Sesiones\Conexión existente
- Procedimientos almacenados\RPC:Iniciando
- Procedimientos almacenados\SP:Completado
- Procedimientos almacenados\SP:Iniciando
- Procedimientos almacenados\SP:StmtStarting
- TSQL\SQL:BatchStarting
Esta plantilla se seleccionó en función de la carga de trabajo utilizada para las pruebas, que son principalmente lotes de SQL capturados por SQL:BatchStarting evento, y luego una serie de eventos utilizando los diversos métodos de hierarchyid , que son capturados por el SP:Starting , SP:StmtStarting y SP:Completed eventos. Se generó una secuencia de comandos de seguimiento del lado del servidor a partir de la plantilla utilizando la funcionalidad de exportación en SQL Server Profiler, y los únicos cambios realizados en la secuencia de comandos fueron establecer el maxfilesize parámetro a 500 MB, habilite la sustitución del archivo de seguimiento y proporcione un nombre de archivo en el que se escribió el seguimiento.
La tercera y cuarta prueba utilizaron SQL Server Profiler para recopilar los mismos eventos que el seguimiento del lado del servidor para medir la sobrecarga de rendimiento del seguimiento mediante la aplicación Profiler. Estas pruebas se ejecutaron utilizando SQL Profiler de forma local en SQL Server y de forma remota desde un cliente independiente para determinar si había una diferencia en la sobrecarga al ejecutar Profiler de forma local o remota.
Las pruebas finales que utilizaron eventos extendidos recopilaron los mismos eventos y las mismas columnas basadas en una sesión de eventos creada con mi secuencia de comandos de conversión Trace to Extended Events para SQL Server 2012. Las pruebas incluyeron la evaluación de event_file, ring_buffer y el nuevo proveedor de transmisión en SQL Server. 2012 por separado para determinar la sobrecarga que cada destino podría imponer al rendimiento del servidor. Además, la sesión de eventos se configuró con las opciones predeterminadas del búfer de memoria, pero se cambió para especificar NO_EVENT_LOSS para el EVENT_RETENTION_MODE opción para que las pruebas event_file y ring_buffer coincidan con el comportamiento del seguimiento del lado del servidor en un archivo, lo que también garantiza que no se perderán eventos.
Resultados
Con una excepción, los resultados de las pruebas no fueron sorprendentes. La prueba de referencia pudo realizar la carga de trabajo de reproducción en trece minutos y treinta y cinco segundos, y promedió 2345 solicitudes por lotes por segundo durante las pruebas. Con Trace del lado del servidor ejecutándose, la operación de reproducción se completó en 16 minutos y 40 segundos, lo que representa una degradación del rendimiento del 18,1 %. Profiler Traces tuvo los peores resultados en general y requirió 149 minutos cuando Profiler se ejecutó localmente en el servidor, y 123 minutos y 20 segundos cuando Profiler se ejecutó de forma remota, lo que produjo una degradación del rendimiento del 90,8 % y el 87,6 %, respectivamente. Las pruebas de eventos extendidos fueron las de mejor rendimiento, con una duración de 15 minutos y 15 segundos para event_file y de 15 minutos y 40 segundos para el objetivo de ring_buffer, lo que resultó en una degradación del rendimiento del 10,4 % y el 11,6 %. Los resultados promedio de todas las pruebas se muestran en la Tabla 1 y se grafican en la Figura 2:
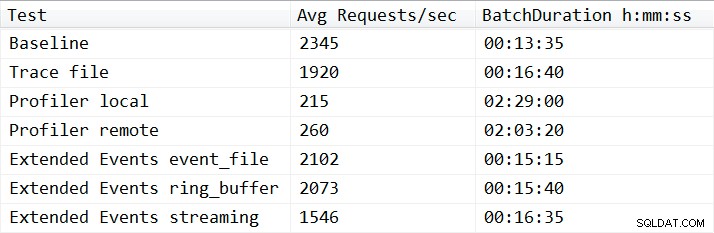
Tabla 1:resultados promedio de todas las pruebas
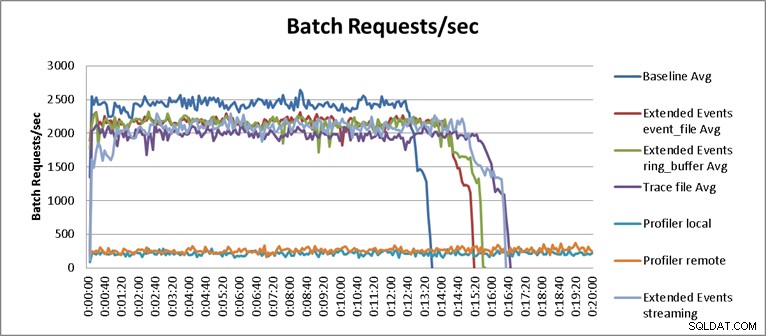
Figura 2:Gráfico de resultados
La prueba de transmisión de eventos extendidos no es un resultado justo en el contexto de las pruebas que se realizaron y requiere un poco más de explicación para comprender el resultado. En los resultados de la tabla, podemos ver que las pruebas de transmisión de eventos extendidos se completaron en dieciséis minutos y treinta y cinco segundos, lo que equivale a una degradación del rendimiento del 34,1 %. Sin embargo, si hacemos zoom en el gráfico y cambiamos su escala, como se muestra en la Figura 3, veremos que la transmisión tuvo un impacto mucho mayor en el rendimiento inicialmente y luego comenzó a funcionar de manera similar a las otras pruebas de eventos extendidos. :
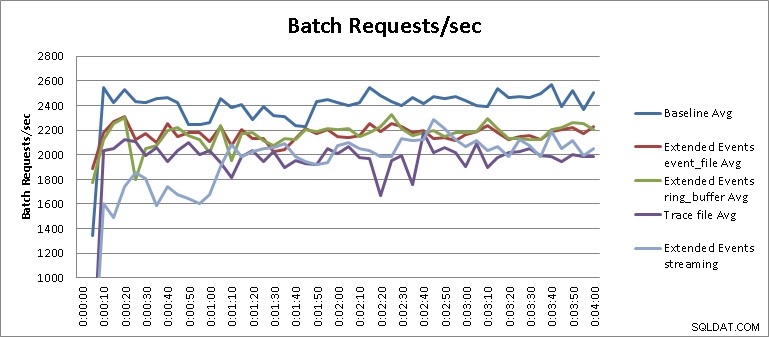
Figura 3:resultados ampliados
La explicación de esto se encuentra en el diseño del nuevo destino de transmisión de eventos extendidos en SQL Server 2012. Si los búferes de memoria interna para event_stream se llenan y la aplicación cliente no los consume lo suficientemente rápido, el Motor de base de datos forzará una desconexión de event_stream para evitar un impacto severo en el rendimiento del servidor. Esto da como resultado que se genere un error en SQL Server 2012 Management Studio similar al error en la Figura 4:
Figura 4:event_stream desconectado por el servidor
(Microsoft.SqlServer.XEvent.Linq)
Error 25726, gravedad 17, estado 0, pero no se encontró ningún mensaje con ese número de error en sys.messages. Si el error es mayor que 50000, asegúrese de que el mensaje definido por el usuario se agregue mediante sp_addmessage.
(Microsoft SQL Server, Error:18054)
Conclusiones
Todos los métodos de recopilación de datos de diagnóstico de SQL Server tienen una "sobrecarga del observador" asociada y pueden afectar el rendimiento de una carga de trabajo bajo una carga pesada. Para los sistemas que se ejecutan en SQL Server 2012, los eventos extendidos proporcionan la menor cantidad de sobrecarga y brindan capacidades similares para eventos y columnas como SQL Trace (algunos eventos en SQL Trace se acumulan en otros eventos en eventos extendidos). En caso de que SQL Trace sea necesario para capturar datos de eventos, lo que puede ser el caso hasta que las herramientas de terceros se recodifiquen para aprovechar los datos de eventos extendidos, un seguimiento del lado del servidor a un archivo generará la menor cantidad de sobrecarga de rendimiento. SQL Server Profiler es una herramienta que debe evitarse en servidores de producción ocupados, como lo demuestra el aumento de diez veces en la duración y la reducción significativa en el rendimiento de la reproducción.
Si bien los resultados parecen favorecer la ejecución remota de SQL Server Profiler cuando se debe usar Profiler, esta conclusión no se puede sacar definitivamente en función de las pruebas específicas que se ejecutaron en este escenario. Se tendrían que realizar pruebas y recopilación de datos adicionales para determinar si los resultados remotos de Profiler fueron el resultado de un cambio de contexto más bajo en la instancia de SQL Server, o si la red entre máquinas virtuales fue un factor en el menor impacto en el rendimiento de la recopilación remota. El objetivo de estas pruebas era mostrar la sobrecarga significativa en la que incurre Profiler, independientemente de dónde se ejecutara Profiler. Finalmente, la transmisión de eventos en vivo en Eventos extendidos también tiene una sobrecarga alta cuando está realmente conectada en la recopilación de datos, pero como se muestra en las pruebas, el Motor de base de datos desconectará una transmisión en vivo si se retrasa en los eventos para evitar un impacto severo en el rendimiento del servidor.