JPA (Anotación de persistencia de Java ) es la solución estándar de Java para cerrar la brecha entre los modelos de dominio orientados a objetos y los sistemas de bases de datos relacionales. La idea es asignar clases de Java a tablas relacionales y propiedades de esas clases a las filas de la tabla. Esto cambia la semántica de la experiencia general de la codificación de Java mediante la colaboración perfecta de dos tecnologías diferentes dentro del mismo paradigma de programación. Este artículo proporciona una descripción general y su implementación de soporte en Java.
Una visión general
Las bases de datos relacionales son quizás las más estables de todas las tecnologías de persistencia disponibles en la informática en lugar de todas las complejidades que implica. Esto se debe a que hoy en día, incluso en la era de los llamados "grandes datos", las bases de datos relacionales "NoSQL" tienen una demanda constante y prosperan. Las bases de datos relacionales son tecnología estable no por meras palabras sino por su existencia a través de los años. NoSQL puede ser bueno para manejar grandes cantidades de datos estructurados en la empresa, pero las numerosas cargas de trabajo transaccionales se manejan mejor a través de bases de datos relacionales. Además, existen excelentes herramientas analíticas asociadas con las bases de datos relacionales.
Para comunicarse con la base de datos relacional, ANSI ha estandarizado un lenguaje llamado SQL (Lenguaje de consulta estructurado ). Una sentencia escrita en este lenguaje se puede utilizar tanto para definir como para manipular datos. Pero, el problema de SQL al tratar con Java es que tienen una estructura sintáctica no coincidente y muy diferente en el núcleo, lo que significa que SQL es procedimental mientras que Java está orientado a objetos. Por lo tanto, se busca una solución de trabajo tal que Java pueda hablar de manera orientada a objetos y la base de datos relacional aún pueda entenderse entre sí. JPA es la respuesta a esa llamada y proporciona el mecanismo para establecer una solución de trabajo entre los dos.
Relacional a Mapeo de Objetos
Los programas Java interactúan con las bases de datos relacionales utilizando el JDBC (Conectividad de base de datos Java ) API. Un controlador JDBC es la clave para la conectividad y permite que un programa Java manipule esa base de datos utilizando la API JDBC. Una vez que se establece la conexión, el programa Java lanza consultas SQL en forma de String s para comunicar operaciones de creación, inserción, actualización y eliminación. Esto es suficiente para todos los propósitos prácticos, pero inconveniente desde el punto de vista de un programador de Java. ¿Qué sucede si la estructura de las tablas relacionales se puede remodelar en clases de Java puras y luego se puede tratar con ellas de la manera habitual orientada a objetos? La estructura de una tabla relacional es una representación lógica de datos en forma tabular. Las tablas se componen de columnas que describen los atributos de la entidad y las filas son la colección de entidades. Por ejemplo, una tabla EMPLEADO puede contener las siguientes entidades con sus atributos.
| Emp_number | Nombre | n°depto | Salario | Lugar |
| 112233 | Pedro | 123 | 1200 | LA |
| 112244 | Rayo | 234 | 1300 | Nueva York |
| 112255 | Sandip | 123 | 1400 | Nueva Jersey |
| 112266 | Kalpana | 234 | 1100 | LA |
Las filas son únicas por clave principal (emp_number) dentro de una tabla; esto permite una búsqueda rápida. Una tabla puede estar relacionada con una o más tablas por alguna clave, como una clave externa (dept_no), que se relaciona con la fila equivalente en otra tabla.
De acuerdo con la especificación de Persistencia de Java 2.1, JPA agrega compatibilidad con la generación de esquemas, métodos de conversión de tipos, uso de gráficos de entidades en consultas y operaciones de búsqueda, contexto de persistencia no sincronizado, invocación de procedimientos almacenados e inyección en clases de escucha de entidades. También incluye mejoras en el lenguaje de consultas de Java Persistence, la API de Criterios y la asignación de consultas nativas.
En resumen, hace todo lo posible para proporcionar la ilusión de que no hay una parte procesal al tratar con bases de datos relacionales y todo está orientado a objetos.
Implementación de JPA
JPA describe la gestión de datos relacionales en la aplicación Java. Es una especificación y hay una serie de implementaciones de la misma. Algunas implementaciones populares son Hibernate, EclipseLink y Apache OpenJPA. JPA define los metadatos mediante anotaciones en clases Java o mediante archivos de configuración XML. Sin embargo, podemos usar XML y anotaciones para describir los metadatos. En tal caso, la configuración XML anula las anotaciones. Esto es razonable porque las anotaciones se escriben con el código Java, mientras que los archivos de configuración XML son externos al código Java. Por lo tanto, más adelante, si es necesario, se deben realizar cambios en los metadatos; en el caso de una configuración basada en anotaciones, requiere acceso directo al código Java. Esto puede no ser siempre posible. En tal caso, podemos escribir una configuración de metadatos nueva o modificada en un archivo XML sin ningún indicio de cambio en el código original y aún tener el efecto deseado. Esta es la ventaja de utilizar la configuración XML. Sin embargo, la configuración basada en anotaciones es más cómoda de usar y es la opción popular entre los programadores.
- Hibernar es la popular y más avanzada entre todas las implementaciones de JPA gracias a Red Hat. Utiliza sus propios ajustes y características adicionales que pueden usarse además de su implementación JPA. Tiene una comunidad de usuarios más grande y está bien documentado. Algunas de las características patentadas adicionales son la compatibilidad con múltiples inquilinos, la unión de entidades no asociadas en consultas, la gestión de marcas de tiempo, etc.
- EclipseLink se basa en TopLink y es una implementación de referencia de las versiones de JPA. Proporciona funcionalidades estándar de JPA además de algunas características patentadas interesantes, como la compatibilidad con múltiples inquilinos, el manejo de eventos de cambio de base de datos, etc.
Uso de JPA en un programa Java SE
Para usar JPA en un programa Java, necesita un proveedor de JPA como Hibernate o EclipseLink, o cualquier otra biblioteca. Además, necesita un controlador JDBC que se conecte a la base de datos relacional específica. Por ejemplo, en el siguiente código, hemos utilizado las siguientes bibliotecas:
- Proveedor: EclipseLink
- Controlador JDBC: Controlador JDBC para MySQL (Conector/J)
Estableceremos una relación entre dos tablas, Empleado y Departamento, como uno a uno y uno a muchos, como se muestra en el siguiente diagrama EER (consulte la Figura 1).
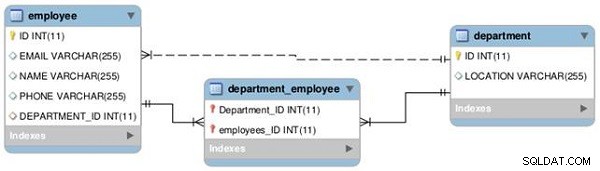
Figura 1: Relaciones de tablas
El empleado la tabla se asigna a una clase de entidad mediante la anotación de la siguiente manera:
package org.mano.jpademoapp;
import javax.persistence.*;
@Entity
@Table(name = "employee")
public class Employee {
@Id
private int id;
private String name;
private String phone;
private String email;
@OneToOne
private Department department;
public Employee() {
super();
}
public Employee(int id, String name, String phone,
String email) {
super();
this.id = id;
this.name = name;
this.phone = phone;
this.email = email;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public String getEmail() {
return email;
}
public void setEmail(String email) {
this.email = email;
}
public Department getDepartment() {
return department;
}
public void setDepartment(Department department) {
this.department = department;
}
}
Y, el departamento la tabla se asigna a una clase de entidad de la siguiente manera:
package org.mano.jpademoapp;
import java.util.*;
import javax.persistence.*;
@Entity
@Table(name = "department")
public class Department {
@Id
private int id;
private String location;
@OneToMany
private List<Employee> employees = new ArrayList<>();
public Department() {
super();
}
public Department(int id, String location) {
super();
this.id = id;
this.location = location;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getLocation() {
return location;
}
public void setLocation(String location) {
this.location = location;
}
public List<Employee> getEmployees() {
return employees;
}
public void setEmployees(List<Employee> employees) {
this.employees = employees;
}
}
El archivo de configuración, persistence.xml , se crea en el META-INF directorio. Este archivo contiene la configuración de la conexión, como el controlador JDBC utilizado, el nombre de usuario y la contraseña para acceder a la base de datos y otra información relevante requerida por el proveedor de JPA para establecer la conexión a la base de datos.
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.1"
xmlns_xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi_schemaLocation="https://xmlns.jcp.org/xml/ns/persistence
https://xmlns.jcp.org/xml/ns/persistence/persistence_2_1.xsd">
<persistence-unit name="JPADemoProject"
transaction-type="RESOURCE_LOCAL">
<class>org.mano.jpademoapp.Employee</class>
<class>org.mano.jpademoapp.Department</class>
<properties>
<property name="javax.persistence.jdbc.driver"
value="com.mysql.jdbc.Driver" />
<property name="javax.persistence.jdbc.url"
value="jdbc:mysql://localhost:3306/testdb" />
<property name="javax.persistence.jdbc.user"
value="root" />
<property name="javax.persistence.jdbc.password"
value="secret" />
<property name="javax.persistence.schema-generation
.database.action"
value="drop-and-create"/>
<property name="javax.persistence.schema-generation
.scripts.action"
value="drop-and-create"/>
<property name="eclipselink.ddl-generation"
value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
Las entidades no persisten en sí mismas. Se debe aplicar la lógica para manipular entidades para administrar su ciclo de vida persistente. El EntityManager La interfaz proporcionada por JPA permite que la aplicación administre y busque entidades en la base de datos relacional. Creamos un objeto de consulta con la ayuda de EntityManager para comunicarse con la base de datos. Para obtener EntityManager para una base de datos dada, usaremos un objeto que implementa una EntityManagerFactory interfaz. Hay una estática método, llamado createEntityManagerFactory , en la Persistencia clase que devuelve EntityManagerFactory para la unidad de persistencia especificada como String argumento. En la siguiente implementación rudimentaria, hemos implementado la lógica.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public enum PersistenceManager {
INSTANCE;
private EntityManagerFactory emf;
private PersistenceManager() {
emf=Persistence.createEntityManagerFactory("JPADemoProject");
}
public EntityManager getEntityManager() {
return emf.createEntityManager();
}
public void close() {
emf.close();
}
}
Ahora, estamos listos para ir y crear la interfaz principal de la aplicación. Aquí, hemos implementado solo la operación de inserción en aras de la simplicidad y las limitaciones de espacio.
package org.mano.jpademoapp;
import javax.persistence.EntityManager;
public class Main {
public static void main(String[] args) {
Department d1=new Department(11, "NY");
Department d2=new Department(22, "LA");
Employee e1=new Employee(111, "Peter",
"9876543210", "example@sqldat.com");
Employee e2=new Employee(222, "Ronin",
"993875630", "example@sqldat.com");
Employee e3=new Employee(333, "Kalpana",
"9876927410", "example@sqldat.com");
Employee e4=new Employee(444, "Marc",
"989374510", "example@sqldat.com");
Employee e5=new Employee(555, "Anik",
"987738750", "example@sqldat.com");
d1.getEmployees().add(e1);
d1.getEmployees().add(e3);
d1.getEmployees().add(e4);
d2.getEmployees().add(e2);
d2.getEmployees().add(e5);
EntityManager em=PersistenceManager
.INSTANCE.getEntityManager();
em.getTransaction().begin();
em.persist(e1);
em.persist(e2);
em.persist(e3);
em.persist(e4);
em.persist(e5);
em.persist(d1);
em.persist(d2);
em.getTransaction().commit();
em.close();
PersistenceManager.INSTANCE.close();
}
}
| Nota: Consulte la documentación adecuada de la API de Java para obtener información detallada sobre las API utilizadas en el código anterior. |
Conclusión
Como debería ser obvio, la terminología central de JPA y el contexto de persistencia es más amplia que el vistazo que se brinda aquí, pero comenzar con una descripción general rápida es mejor que el código sucio largo e intrincado y sus detalles conceptuales. Si tiene un poco de experiencia en programación en el núcleo JDBC, sin duda apreciará cómo JPA puede simplificar su vida. Profundizaremos en JPA gradualmente a medida que avancemos en los próximos artículos.