@rob_farley su reciente solución de stackoverflow para ordenar primero por valor y luego por campo ¡genio! Quería darle las gracias personalmente.
— Joel Sacco (@Jsac90) 11 de agosto de 2016
Vi este tweet llegar...
Y me hizo ver a qué se refería, porque no había escrito nada 'recientemente' en StackOverflow sobre el pedido de datos. Resulta que fue esta respuesta que había escrito , que aunque no fue la respuesta aceptada, ha obtenido más de cien votos.
La persona que hizo la pregunta tenía un problema muy simple:deseaba que ciertas filas aparecieran primero. Y mi solución fue simple:
ORDER BY CASE WHEN city = 'New York' THEN 1 ELSE 2 END, City;
Parece haber sido una respuesta popular, incluso para Joel Sacco (según el tweet anterior).
La idea es formar una expresión, y ordenar por eso. A ORDER BY no le importa si es una columna real o no. Podrías haber hecho lo mismo usando APLICAR, si realmente prefieres usar una 'columna' en tu cláusula ORDER BY.
SELECT Users.* FROM Users CROSS APPLY ( SELECT CASE WHEN City = 'New York' THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, City;
Si utilizo algunas consultas contra WideWorldImporters, puedo mostrarle por qué estas dos consultas son exactamente iguales. Voy a consultar la tabla Ventas.Pedidos, solicitando que aparezcan primero los Pedidos para el Vendedor 7. También voy a crear un índice de cobertura apropiado:
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID) INCLUDE (OrderDate);
Los planes para estas dos consultas parecen idénticos. Funcionan de manera idéntica:las mismas lecturas, las mismas expresiones, realmente son la misma consulta. Si hay una ligera diferencia en la CPU o la duración real, entonces es una casualidad debido a otros factores.
SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders ORDER BY CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END, SalespersonPersonID; SELECT OrderID, SalespersonPersonID, OrderDate FROM Sales.Orders CROSS APPLY ( SELECT CASE WHEN SalespersonPersonID = 7 THEN 1 ELSE 2 END AS OrderingCol ) o ORDER BY o.OrderingCol, SalespersonPersonID;
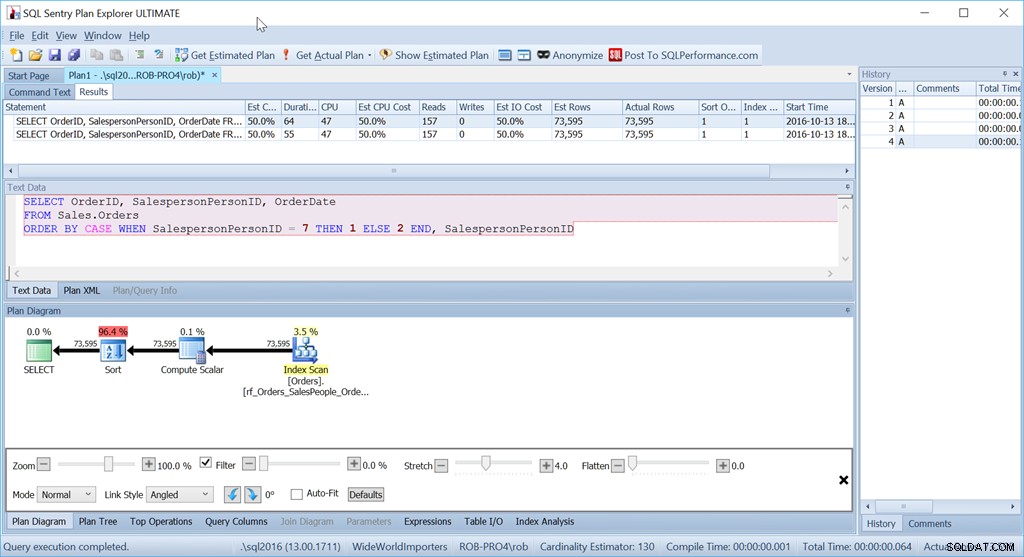
Y, sin embargo, esta no es la consulta que realmente usaría en esta situación. No si el rendimiento fuera importante para mí. (Por lo general, lo es, pero no siempre vale la pena escribir una consulta de manera larga si la cantidad de datos es pequeña).
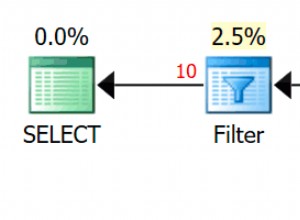
Lo que me molesta es ese operador Ordenar. ¡Es el 96,4% del costo!
Considere si simplemente queremos ordenar por SalespersonPersonID:
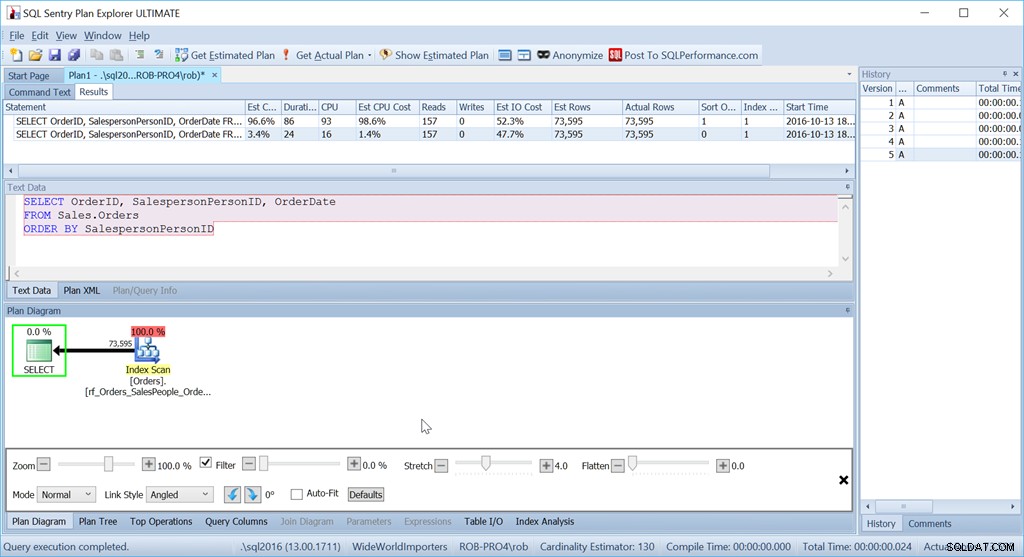
Vemos que el costo de CPU estimado de esta consulta más simple es el 1,4 % del lote, mientras que el de la versión ordenada personalizada es del 98,6 %. Eso es SETENTA VECES peor. Sin embargo, las lecturas son las mismas, eso es bueno. La duración es mucho peor, al igual que la CPU.
No soy aficionado a las clases. Pueden ser desagradables.
Una opción que tengo aquí es agregar una columna calculada a mi tabla e indexarla, pero eso tendrá un impacto en cualquier cosa que busque todas las columnas en la tabla, como ORM, Power BI o cualquier cosa que haga SELECCIONAR * . Así que eso no es tan bueno (aunque si alguna vez añadimos columnas calculadas ocultas, sería una muy buena opción aquí).
Otra opción, que es más larga (algunos podrían sugerir que me convendría, y si pensaron eso:¡Oi! ¡No sean tan groseros!), y usa más lecturas, es considerar lo que haríamos en la vida real si necesitábamos hacer esto.
Si tuviera una pila de 73.595 pedidos, clasificados por orden de Vendedor, y primero tuviera que devolverlos con un Vendedor en particular, no ignoraría el orden en que estaban y simplemente los ordenaría todos, comenzaría por sumergirme y encontrar los del Vendedor 7, manteniéndolos en el orden en que estaban. Luego encontraría los que no eran los que no eran el Vendedor 7, colocándolos a continuación y manteniéndolos nuevamente en el orden en que ya estaban en.
En T-SQL, eso se hace así:
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID; Esto obtiene dos conjuntos de datos y los concatena. Pero el Optimizador de consultas puede ver que necesita mantener el orden de SalespersonPersonID, una vez que se concatenan los dos conjuntos, por lo que realiza un tipo especial de concatenación que mantiene ese orden. Es una unión de fusión (concatenación) y el plan se ve así:
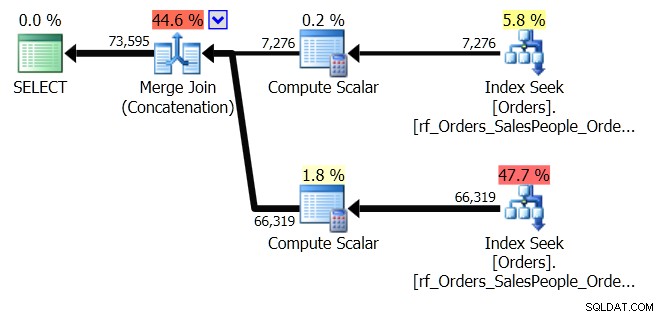
Puedes ver que es mucho más complicado. Pero, con suerte, también notará que no hay un operador Ordenar. Merge Join (Concatenación) extrae los datos de cada rama y produce un conjunto de datos que está en el orden correcto. En este caso, extraerá primero las 7.276 filas para el Vendedor 7 y luego extraerá las otras 66.319, porque ese es el orden requerido. Dentro de cada conjunto, los datos están en el orden SalespersonPersonID, que se mantiene a medida que fluyen los datos.
Mencioné anteriormente que usa más lecturas, y lo hace. Si muestro el resultado de SET STATISTICS IO, comparando las dos consultas, veo esto:
Mesa 'Mesa de Trabajo'. Recuento de escaneo 0, lecturas lógicas 0, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.Tabla 'Órdenes'. Recuento de escaneo 1, lecturas lógicas 157, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
Tabla 'Órdenes '. Recuento de escaneos 3, lecturas lógicas 163, lecturas físicas 0, lecturas anticipadas 0, lecturas lógicas lob 0, lecturas físicas lob 0, lecturas anticipadas lob 0.
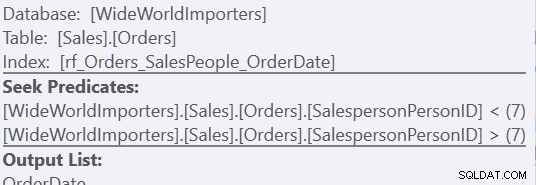
Usando la versión de "Ordenación personalizada", es solo un escaneo del índice, usando 157 lecturas. Usando el método "Unir todo", son tres escaneos:uno para SalespersonPersonID =7, uno para SalespersonPersonID <7 y otro para SalespersonPersonID> 7. Podemos ver los dos últimos mirando las propiedades de la segunda búsqueda de índice:
Sin embargo, para mí, el beneficio se manifiesta en la falta de una mesa de trabajo.
Mire el costo estimado de la CPU:

No es tan pequeño como nuestro 1,4 % cuando evitamos la ordenación por completo, pero sigue siendo una gran mejora con respecto a nuestro método de ordenación personalizada.
Pero una palabra de advertencia...
Supongamos que había creado ese índice de manera diferente y tenía OrderDate como una columna clave en lugar de una columna incluida.
CREATE INDEX rf_Orders_SalesPeople_OrderDate ON Sales.Orders(SalespersonPersonID, OrderDate);
Ahora, mi método "Unir todo" no funciona como debería.
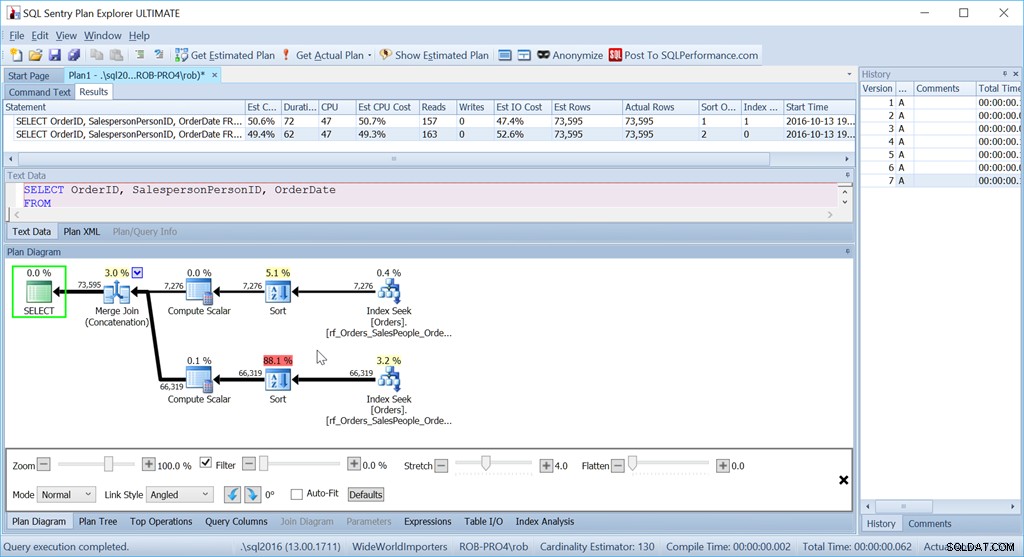
A pesar de usar exactamente las mismas consultas que antes, mi buen plan ahora tiene dos operadores de ordenación y funciona casi tan mal como mi versión original de Escanear + Ordenar.
La razón de esto es una peculiaridad del operador Merge Join (Concatenación), y la clave está en el operador Sort.

Está ordenando por SalespersonPersonID seguido de OrderID, que es la clave de índice agrupado de la tabla. Elige esto porque se sabe que es único y es un conjunto de columnas más pequeño para ordenar que SalespersonPersonID seguido de OrderDate seguido de OrderID, que es el orden del conjunto de datos producido por tres escaneos de rango de índice. Una de esas ocasiones en las que el Optimizador de consultas no detecta una mejor opción que está justo ahí.
Con este índice, también necesitaríamos nuestro conjunto de datos ordenado por Fecha de pedido para producir nuestro plan preferido.
SELECT OrderID, SalespersonPersonID, OrderDate
FROM
(
SELECT OrderID, SalespersonPersonID, OrderDate,
1 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID = 7
UNION ALL
SELECT OrderID, SalespersonPersonID, OrderDate,
2 AS OrderingCol
FROM Sales.Orders
WHERE SalespersonPersonID != 7
) o
ORDER BY o.OrderingCol, o.SalespersonPersonID, OrderDate;
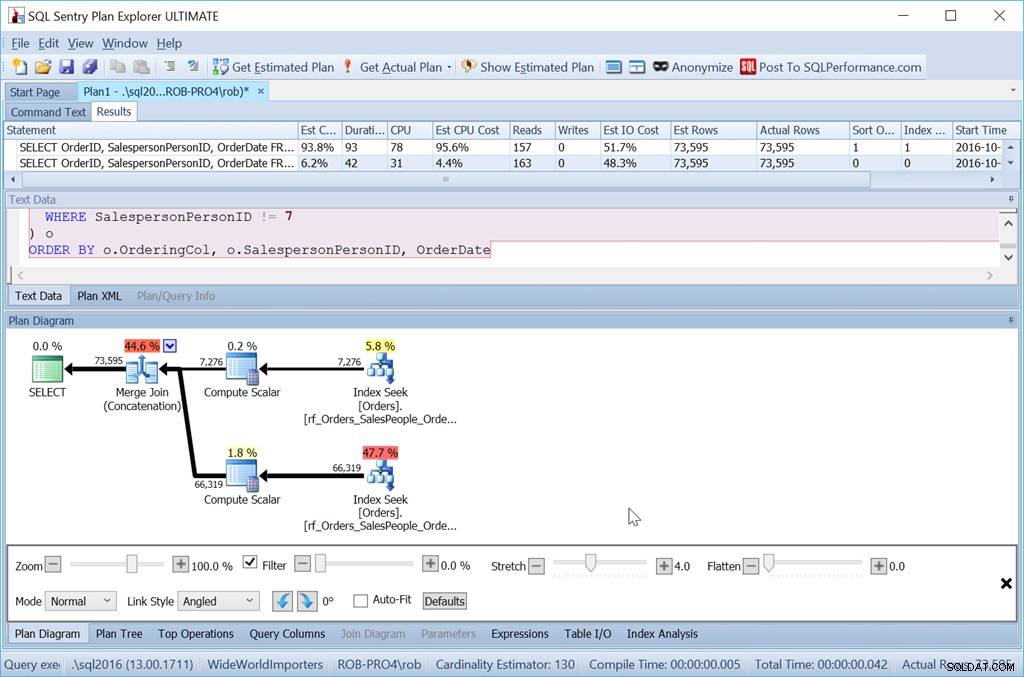
Así que definitivamente es más esfuerzo. La consulta es más larga para escribir, son más lecturas y tengo que tener un índice sin columnas clave adicionales. Pero ciertamente es más rápido. Con aún más filas, el impacto es aún mayor, y tampoco tengo que arriesgarme a que Sort se derrame en tempdb.
Para conjuntos pequeños, mi respuesta de StackOverflow sigue siendo buena. Pero cuando ese operador Ordenar me está costando en rendimiento, entonces voy con el método Unir todo / Combinar unir (Concatenación).