No me malinterpreten; Me encantan los índices filtrados. Crean oportunidades para un uso mucho más eficiente de E/S y finalmente nos permiten implementar restricciones únicas adecuadas que cumplen con ANSI (donde se permite más de un NULL). Sin embargo, están lejos de ser perfectos. Quería señalar algunas áreas en las que se podrían mejorar los índices filtrados y hacerlos mucho más útiles y prácticos para una gran parte de las cargas de trabajo.
Primero, las buenas noticias
Los índices filtrados pueden hacer que las consultas que antes eran caras funcionen muy rápido, y lo hacen usando menos espacio (y, por lo tanto, menos E/S, incluso cuando se escanean).
Un ejemplo rápido usando Sales.SalesOrderDetailEnlarged (construido usando este script por Jonathan Kehayias (@SQLPoolBoy)). Esta tabla tiene filas de 4.8MM, con 587 MB de datos y 363 MB de índices. Solo hay una columna anulable, CarrierTrackingNumber , así que vamos a jugar con eso. Tal como está, la tabla actualmente tiene aproximadamente la mitad de estos valores (2,4 mm) como NULL. Voy a reducir eso a alrededor de 240 000 para simular un escenario en el que un pequeño porcentaje de las filas de la tabla son realmente elegibles para un índice, a fin de resaltar mejor los beneficios de un índice filtrado. La siguiente consulta afecta a 2,17 millones de filas, dejando 241 507 filas con un valor NULL para CarrierTrackingNumber :
UPDATE Sales.SalesOrderDetailEnlarged
SET CarrierTrackingNumber = 'x'
WHERE CarrierTrackingNumber IS NULL
AND SalesOrderID % 10 <> 3; Ahora, supongamos que hay un requisito comercial en el que constantemente queremos revisar los pedidos que tienen productos a los que aún no se les ha asignado un número de seguimiento (piense en pedidos que se dividen y se envían por separado). En la tabla actual, ejecutaríamos estas consultas (y he agregado los comandos DBCC para garantizar la caché en frío en todos los casos):
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; SELECT COUNT(*) FROM Sales.SalesOrderDetailEnlarged WHERE CarrierTrackingNumber IS NULL; SELECT ProductID, SalesOrderID FROM Sales.SalesOrderDetailEnlarged WHERE CarrierTrackingNumber IS NULL;
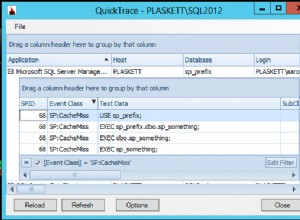
Que requieren escaneos de índices agrupados y producen las siguientes métricas de tiempo de ejecución (tal como se capturan con SQL Sentry Plan Explorer):

En los días "antiguos" (es decir, desde SQL Server 2005), habríamos creado este índice (y, de hecho, incluso en SQL Server 2012, este es el índice que recomienda SQL Server):
CREATE INDEX IX_NotVeryHelpful ON [Sales].[SalesOrderDetailEnlarged] ([CarrierTrackingNumber]) INCLUDE ([SalesOrderID],[ProductID]);
Con ese índice en su lugar y ejecutando las consultas anteriores nuevamente, aquí están las métricas, con ambas consultas utilizando una búsqueda de índice como era de esperar:

Y luego soltar ese índice y crear uno ligeramente diferente, simplemente agregando un WHERE cláusula:
CREATE INDEX IX_Filtered_CTNisNULL ON [Sales].[SalesOrderDetailEnlarged] ([CarrierTrackingNumber]) INCLUDE ([SalesOrderID],[ProductID]) WHERE CarrierTrackingNumber IS NULL;
Obtenemos estos resultados, y ambas consultas usan el índice filtrado para sus búsquedas:

Este es el espacio adicional requerido por cada índice, en comparación con la reducción del tiempo de ejecución y la E/S de las consultas anteriores:
| Índice | Espacio de índice | Espacio añadido | Duración | Lecturas |
|---|---|---|---|---|
| Sin índice dedicado | 363 MB | 15 700 ms | ~164.000 | |
| Índice no filtrado | 530 MB | 167 MB (+46 %) | 169ms | 1084 |
| Índice filtrado | 367 MB | 4 MB (+1 %) | 170ms | 1084 |
Entonces, como puede ver, el índice filtrado ofrece mejoras de rendimiento que son casi idénticas al índice no filtrado (ya que ambos pueden obtener sus datos utilizando la misma cantidad de lecturas), pero con un almacenamiento mucho más bajo. costo, ya que el índice filtrado solo tiene que almacenar y mantener las filas que coinciden con el predicado del filtro.
Ahora, devolvamos la tabla a su estado original:
UPDATE Sales.SalesOrderDetailEnlarged SET CarrierTrackingNumber = NULL WHERE CarrierTrackingNumber = 'x'; DROP INDEX IX_NotVeryHelpful ON Sales.SalesOrderDetailEnlarged; DROP INDEX IX_Filtered_CTNisNULL ON Sales.SalesOrderDetailEnlarged;
Tim Chapman (@chapmandew) y Michelle Ufford (@sqlfool) han hecho un trabajo fantástico al describir los beneficios de rendimiento de los índices filtrados a su manera, y también debería consultar sus publicaciones:
- Michelle Ufford:Índices filtrados:lo que necesita saber
- Tim Chapman:Las alegrías de los índices filtrados
Además, restricciones únicas compatibles con ANSI (más o menos)
Pensé que también mencionaría brevemente las restricciones únicas que cumplen con ANSI. En SQL Server 2005, crearíamos una restricción única como esta:
CREATE TABLE dbo.Personnel ( EmployeeID INT PRIMARY KEY, SSN CHAR(9) NULL, -- ... other columns ... CONSTRAINT UQ_SSN UNIQUE(SSN) );
(También podríamos crear un índice único no agrupado en lugar de una restricción; la implementación subyacente es esencialmente la misma).
Ahora, esto no es un problema si se conocen los SSN en el momento de la entrada:
INSERT dbo.Personnel(EmployeeID, SSN) VALUES(1,'111111111'),(2,'111111112');
También está bien si tenemos el SSN ocasional que no se conoce en el momento de la entrada (piense en un solicitante de visa o quizás incluso en un trabajador extranjero que no tiene un SSN y nunca lo tendrá):
INSERT dbo.Personnel(EmployeeID, SSN) VALUES(3,NULL);
Hasta aquí todo bien. Pero, ¿qué sucede cuando tenemos un segundo empleado con un SSN desconocido?
INSERT dbo.Personnel(EmployeeID, SSN) VALUES(4,NULL);
Resultado:
Mensaje 2627, Nivel 14, Estado 1, Línea 1Violación de la restricción de CLAVE ÚNICA 'UQ_SSN'. No se puede insertar una clave duplicada en el objeto 'dbo.Personal'. El valor de la clave duplicada es (
La declaración ha sido terminada.
Entonces, en cualquier momento, solo puede existir un valor NULL en esta columna. A diferencia de la mayoría de los escenarios, este es un caso en el que SQL Server trata dos valores NULL como iguales (en lugar de determinar que la igualdad es simplemente desconocida y, a su vez, falsa). La gente se ha estado quejando de esta inconsistencia durante años.
Si este es un requisito, ahora podemos solucionarlo usando índices filtrados:
ALTER TABLE dbo.Personnel DROP CONSTRAINT UQ_SSN; GO CREATE UNIQUE INDEX UQ_SSN ON dbo.Personnel(SSN) WHERE SSN IS NOT NULL;
Ahora nuestra cuarta inserción funciona bien, ya que la unicidad solo se aplica a los valores que no son NULL. Esto es una especie de trampa, pero cumple con los requisitos básicos que pretendía el estándar ANSI (aunque SQL Server no nos permite usar ALTER TABLE ... ADD CONSTRAINT sintaxis para crear una restricción única filtrada).
Pero, sujeta el teléfono
Estos son excelentes ejemplos de lo que podemos hacer con los índices filtrados, pero hay muchas cosas que todavía no podemos hacer y, como resultado, surgen varias limitaciones y problemas.
Actualizaciones de estadísticas
Esta es una de las limitaciones más importantes en mi humilde opinión. Los índices filtrados no se benefician de la actualización automática de las estadísticas en función de un cambio porcentual del subconjunto de la tabla que identifica el predicado del filtro; se basa (como todos los índices no filtrados) en el abandono de toda la tabla. Esto significa que, según el porcentaje de la tabla que se encuentre en el índice filtrado, el número de filas del índice podría cuadruplicarse o reducirse a la mitad y las estadísticas no se actualizarán a menos que lo haga manualmente. Kimberly Tripp ha brindado excelente información sobre esto (y Gail Shaw cita un ejemplo en el que se necesitaron 257 000 actualizaciones antes de que se actualizaran las estadísticas para un índice filtrado que contenía solo 10 000 filas):
https://www.sqlskills.com/blogs/kimberly/filtered-indexes-and-filtered-stats-might-become-seriously-out-of-date/
https://www.sqlskills.com/ blogs/kimberly/category/filtered-indexes/
Además, el colega de Kimberly, Joe Sack (@JosephSack), presentó un elemento de conexión que sugiere corregir este comportamiento tanto para los índices filtrados como para las estadísticas filtradas.
Limitaciones de expresión de filtro
Hay varias construcciones que no puede usar en un predicado de filtro, como NOT IN , OR y predicados dinámicos/no deterministas como WHERE col >= DATEADD(DAY, -1, GETDATE()) . Además, es posible que el optimizador no reconozca un índice filtrado si el predicado no coincide exactamente con WHERE cláusula en la definición del índice. Aquí hay algunos elementos de Connect que intentan obtener algo de apoyo para una mejor cobertura aquí:
| El índice filtrado no permite filtros en disyunciones | (cerrado:por diseño) |
| La creación del índice filtrado falló con la cláusula NOT IN | (cerrado:por diseño) |
| Compatibilidad con cláusulas WHERE más complejas en índices filtrados | (activo) |
Otros usos potenciales actualmente no son posibles
Actualmente no podemos crear un índice filtrado en una columna calculada persistente, incluso si es determinista. No podemos apuntar una clave externa a un índice filtrado único; si queremos un índice que admita la clave externa además de las consultas admitidas por el índice filtrado, debemos crear un segundo índice redundante sin filtrar. Y aquí hay algunas otras limitaciones similares que se han pasado por alto o que aún no se han considerado:
| Debería ser posible crear un índice filtrado en una columna calculada persistente determinista | (activo) |
| Permitir que el índice único filtrado sea una clave candidata para una clave externa | (activo) |
| capacidad para crear índices de filtro en vistas indexadas | (cerrado:no se arreglará) |
| Error de partición 1908:mejorar la partición | (cerrado:no se arreglará) |
| CREAR ÍNDICE DE ALMACÉN DE COLUMNAS "FILTRADO" | (activo) |
Problemas con MERGE
Y MERGE hace otra aparición en mi lista de "cuidado":
| MERGE evalúa el índice filtrado por fila, no la operación de publicación, lo que provoca una infracción del índice filtrado | (cerrado:no se arreglará) |
| MERGE no se actualiza con el índice filtrado en su lugar | (cerrado:fijo) |
| Error en la instrucción MERGE cuando se usa INSERT/DELETE y se filtra el índice | (activo) |
| MERGE informa incorrectamente de infracciones de clave única | (activo) |
Si bien uno de estos errores (aparentemente estrechamente relacionados) dice que está solucionado en SQL Server 2012, es posible que deba comunicarse con PSS si encuentra alguna variación de este problema, particularmente en versiones anteriores (o deja de usar MERGE , como he sugerido antes).
Herramienta / DMV / limitaciones integradas
Hay muchos DMV, comandos DBCC, procedimientos del sistema y herramientas de cliente en los que comenzamos a confiar con el tiempo. Sin embargo, no todas estas cosas se actualizan para aprovechar las nuevas funciones; los índices filtrados no son una excepción. Los siguientes elementos de Connect señalan algunos problemas que pueden causarle problemas si espera que funcionen con índices filtrados:
| No hay forma de crear un índice filtrado desde SSMS mientras se diseña una nueva tabla | (cerrado:no se arreglará) |
| La expresión de filtro de un índice filtrado se pierde cuando el Diseñador de tablas modifica una tabla | (cerrado:no se arreglará) |
| El diseñador de tablas no escribe la cláusula WHERE en índices filtrados | (activo) |
| El diseñador de tablas SSMS no conserva la expresión del filtro de índice en la reconstrucción de la tabla | (cerrado:no se arreglará) |
| Salida incorrecta de la PÁGINA DBCC con índices filtrados | (activo) |
| Sugerencias de índice filtrado de SQL 2008 de vistas de DM y DTA | (cerrado:no se arreglará) |
| Mejoras en los índices faltantes DMV para índices filtrados | (cerrado:no se arreglará) |
| Error de sintaxis al replicar índices filtrados comprimidos | (cerrado:no se arreglará) |
| Agente:los trabajos usan opciones no predeterminadas cuando se ejecuta un script T-SQL | (cerrado:no se arreglará) |
| Ver dependencias falla con el error 515 de Transact-SQL | (activo) |
| Ver dependencias falla en ciertos objetos | (cerrado:no se arreglará) |
| Las diferencias de opciones de índice no se detectan en la comparación de esquemas para dos bases de datos | (cerrado:externo) |
| Sugerir exponer la condición del filtro de índice en todas las vistas de la información del índice | (cerrado:no se arreglará) |
| Los resultados de sp_helpIndex deben incluir la expresión de filtro de los índices de filtro | (activo) |
| Sobrecargar sp_help, sp_columns, sp_helpindex para funciones de 2008 | (cerrado:no se arreglará) |
Para los últimos tres, no contenga la respiración:es muy poco probable que Microsoft invierta tiempo en los procedimientos sp_, DMV, vistas de INFORMACION_SCHEMA, etc. En su lugar, vea las reescrituras de sp_helpindex de Kimberly Tripp, que incluyen información sobre índices con otras características nuevas que Microsoft ha dejado atrás.
Limitaciones del optimizador
Hay varios elementos de Connect que describen casos en los que el optimizador *podría* utilizar índices filtrados, pero en su lugar se ignoran. En algunos casos, estos no se consideran "errores", sino "brechas en la funcionalidad"...
| SQL no usa índice filtrado en una consulta simple | (cerrado:por diseño) |
| El plan de ejecución del índice filtrado no está optimizado | (cerrado:no se arreglará) |
| Índice filtrado no utilizado y búsqueda de claves sin salida | (cerrado:no se arreglará) |
| El uso del índice filtrado en la columna BIT depende de la expresión SQL exacta utilizada en la cláusula WHERE | (activo) |
| La consulta del servidor vinculado no se optimiza correctamente cuando existe un índice único filtrado | (cerrado:no se arreglará) |
| Row_Number() da resultados impredecibles sobre servidores vinculados donde se utilizan índices filtrados | (cerrado:sin reproducción) |
| Índice filtrado obvio no utilizado por QP | (cerrado:por diseño) |
| Reconocer índices filtrados únicos como únicos | (activo) |
Paul White (@SQL_Kiwi) publicó recientemente aquí en SQLPerformance.com una publicación que detalla en detalle un par de las limitaciones del optimizador anteriores.
Y Tim Chapman escribió una excelente publicación que describe algunas otras limitaciones de los índices filtrados, como la incapacidad de hacer coincidir el predicado con una variable local (corregido en 2008 R2 SP1) y la incapacidad de especificar un índice filtrado en una sugerencia de índice.
Conclusión
Los índices filtrados tienen un gran potencial y tenía muchas esperanzas puestas en ellos cuando se introdujeron por primera vez en SQL Server 2008. Sin embargo, la mayoría de las limitaciones que se incluyeron con su primera versión todavía existen hoy en día, uno y medio (o dos, dependiendo de su perspectiva) lanzamientos principales posteriores. Lo anterior parece una lista bastante extensa de elementos que deben abordarse, pero no quise que se viera de esa manera. Solo quiero que las personas sean conscientes de la gran cantidad de posibles problemas que deben tener en cuenta al aprovechar los índices filtrados.