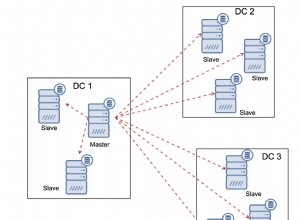
Hace unas semanas, comencé a configurar un entorno de demostración con varias configuraciones de grupos de disponibilidad AlwaysOn. Tenía un clúster WSFC de 5 nodos:cada nodo tenía una instancia con nombre independiente de SQL Server 2012, y también había dos instancias de clúster de conmutación por error (FCI) que se configuraron encima de estos nodos. Un diagrama rápido:
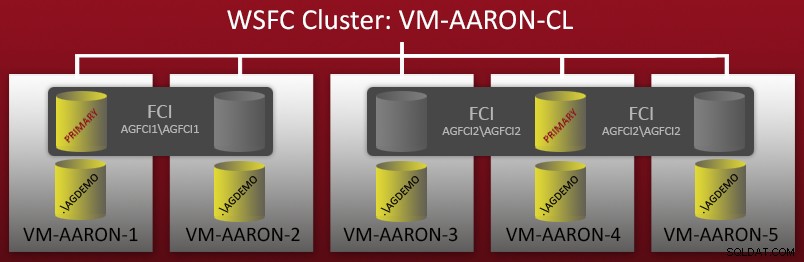
Entonces puede ver que hay 5 instancias independientes con nombre (.\AGDEMO en cada nodo), y luego dos FCI, uno con posibles propietarios VM-AARON-1 y VM-AARON-2 (AGFCI1\AGFCI1 ), y luego uno con los posibles propietarios VM-AARON-3, VM-AARON-4 y VM-AARON-5 (AGFCI2\AGFCI2 ). Ahora, diagramar esto manualmente tendría que volverse significativamente más complejo (más sobre eso más adelante), así que voy a evitarlo por razones obvias. Básicamente, el requisito era tener varios tipos de configuraciones de AG:
- Principal en una FCI con una réplica en una o más instancias independientes
- Principal en un FCI con una réplica en un FCI diferente
- Principal en una instancia independiente con una réplica en una o más FCI
- Principal en una instancia independiente con una réplica en una o más instancias independientes
- Principal en una instancia independiente con réplicas tanto en instancias independientes como en FCI
Y luego combinaciones (siempre que sea posible) de confirmación sincrónica frente a asincrónica, conmutación por error manual frente a automática y secundarias de solo lectura. Existen algunas limitaciones técnicas que limitarían las permutaciones posibles aquí, por ejemplo:
- La conmutación por error manual es necesaria con cualquier réplica que esté en una FCI
- Ningún nodo WSFC puede hospedar, o incluso ser posible propietario de, varias instancias, ya sean independientes o en clúster, que estén involucradas en el mismo grupo de disponibilidad. Recibe este mensaje de error:No se pudo crear, unir o agregar la réplica al grupo de disponibilidad 'Mi grupo', porque el nodo 'VM-AARON-1' es un posible propietario de la réplica 'AGFCI1\AGFCI1' y 'VM-AARON-1\ AGDEMO'. Si una réplica es una instancia de clúster de conmutación por error, elimine el nodo superpuesto de sus posibles propietarios y vuelva a intentarlo. (Microsoft SQL Server, Error:19405)
La mayoría de los escenarios que estaba tratando de representar no son prácticos en escenarios del mundo real, pero son en gran parte y teóricamente posibles . Si aún no lo ha adivinado, este entorno se está configurando explícitamente para probar la nueva funcionalidad en torno a los grupos de disponibilidad que planeamos ofrecer en una versión futura de SQL Sentry. Dimos un adelanto de algunas de estas tecnologías durante nuestro discurso de apertura con Fusion-io en la reciente conferencia SQL Intersection en Las Vegas.
Obstáculo #1
Configurar grupos de disponibilidad con el asistente en SSMS es bastante fácil. A menos que, por ejemplo, tenga rutas de archivo heterogéneas. El asistente tiene una validación que garantiza que existan las mismas rutas de datos y registros en todas las réplicas. Esto puede ser una molestia si está utilizando la ruta de datos predeterminada para dos instancias con nombres diferentes, o si tiene configuraciones de letras de unidad diferentes (lo que sucederá a menudo cuando haya FCI involucradas).
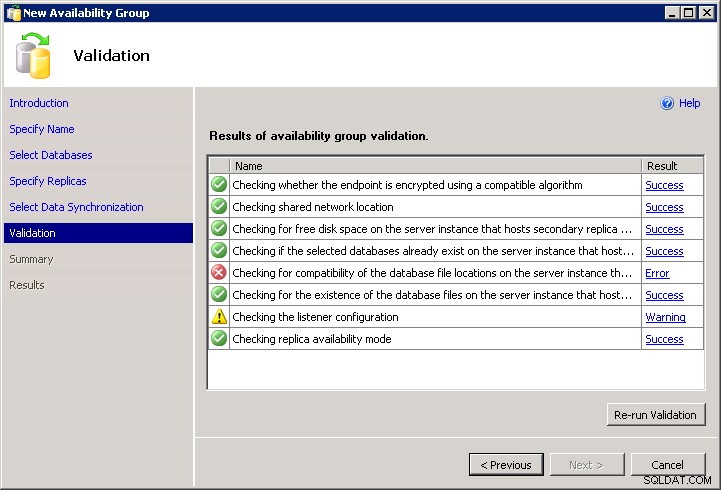
Al comprobar la compatibilidad de la ubicación del archivo de la base de datos en la réplica secundaria se produjo un error. (Microsoft.SqlServer.Management.HadrTasks)Las siguientes ubicaciones de carpetas no existen en la instancia del servidor que aloja la réplica secundaria VM-AARON-1\AGDEMO:
P:\MSSQL11.AGFCI2\MSSQL\DATA;
(Microsoft.SqlServer.Management.HadrTasks)
Ahora no hace falta decir que no desea configurar este escenario en ningún tipo de entorno que deba resistir el paso del tiempo. Las cosas irán mal muy rápidamente si, por ejemplo, luego agrega un nuevo archivo a una de las bases de datos. Pero para un entorno de prueba/demostración, una prueba de concepto o un entorno que espera que sea estable durante un tiempo considerable, no se preocupe:aún puede hacerlo sin el asistente.
Desafortunadamente, para colmo de males, el asistente no le permite escribirlo. No puede pasar el error de validación y no hay Script botón:
Entonces, esto significa que debe codificarlo usted mismo (ya que el DDL no realiza ninguna validación "útil" para usted). Si tiene otras instancias donde existen las mismas rutas, puede hacerlo siguiendo el mismo asistente, pasando la pantalla de validación y luego haciendo clic en Script en lugar de Finish y cambie los nombres de los servidores y agréguelos con WITH MOVE opciones para la restauración inicial. O simplemente puede escribir uno propio desde cero, algo como esto (la secuencia de comandos asume que ya tiene configurados los puntos finales y los permisos, y que todas las instancias tienen habilitada la función Grupos de disponibilidad):
-- Use SQLCMD mode and uncomment the :CONNECT commands
-- or just run the two segments separately / change connection
-- :CONNECT Server1
CREATE AVAILABILITY GROUP [GroupName]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY)
FOR DATABASE [Database1] --, ...
REPLICA ON -- primary:
N'Server1' WITH (ENDPOINT_URL = N'TCP://Server1:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO)),
-- secondary:
N'Server2' WITH (ENDPOINT_URL = N'TCP://Server2:5022',
FAILOVER_MODE = MANUAL, AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50, SECONDARY_ROLE(ALLOW_CONNECTIONS = NO));
ALTER AVAILABILITY GROUP [GroupName]
ADD LISTENER N'ListenerName'
(WITH IP ((N'10.x.x.x', N'255.255.255.0')), PORT=1433);
BACKUP DATABASE Database1 TO DISK = '\\Server1\Share\db1.bak'
WITH INIT, COPY_ONLY, COMPRESSION;
BACKUP LOG Database1 TO DISK = '\\Server1\Share\db1.trn'
WITH INIT, COMPRESSION;
-- :CONNECT Server2
ALTER AVAILABILITY GROUP [GroupName] JOIN;
RESTORE DATABASE Database1 FROM DISK = '\\Server1\Share\db1.bak'
WITH REPLACE, NORECOVERY, NOUNLOAD,
MOVE 'data_file_name' TO 'P:\path\file.mdf',
MOVE 'log_file_name' TO 'P:\path\file.ldf';
RESTORE LOG Database1 FROM DISK = '\\Server1\Share\db1.trn'
WITH NORECOVERY, NOUNLOAD;
ALTER DATABASE Database1 SET HADR AVAILABILITY GROUP = [GroupName]; Obstáculo #2
Si tiene varias instancias en el mismo servidor, es posible que ambas instancias no puedan compartir el puerto 5022 para su punto de enlace de creación de reflejo de la base de datos (que es el mismo punto de enlace que usan los grupos de disponibilidad). Esto significa que tendrá que soltar y volver a crear el punto final para establecerlo en un puerto disponible.
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (ROLE = ALL);
Ahora podría especificar una instancia con un punto final en ServerName:5023 .
Obstáculo #3
Sin embargo, una vez que hice esto, cuando llegaba al último paso en el script anterior, después de exactamente 48 segundos, cada vez, recibía este mensaje de error inútil:
Mensaje 35250, nivel 16, estado 7, línea 2La conexión a la réplica principal no está activa. No se puede procesar el comando.
Esto me hizo perseguir todo tipo de problemas potenciales:verificar los firewalls y el Administrador de configuración de SQL Server, por ejemplo, en busca de cualquier cosa que pudiera bloquear los puertos entre instancias. Nada. Encontré varios errores en el registro de errores de SQL Server:
El intento de inicio de sesión de la creación de reflejo de la base de datos falló con el error:'Falló el protocolo de enlace de conexión. No existe un algoritmo de cifrado compatible. Estado 22.'.El intento de inicio de sesión de la creación de reflejo de la base de datos falló con el error:'Falló el protocolo de enlace de conexión. Una llamada del sistema operativo falló:(80090303) 0x80090303 (el objetivo especificado es desconocido o inalcanzable). Estado 66.'.
Se agotó el tiempo de espera de la conexión al intentar establecer una conexión con la réplica de disponibilidad 'VM-AARON-1\AGDEMO' con id [5AF5B58D-BBD5-40BB-BE69-08AC50010BE0]. Existe un problema de red o de firewall, o la dirección del punto final proporcionada para la réplica no es el punto final de creación de reflejo de la base de datos de la instancia del servidor host.
Resulta (y gracias a Thomas Stringer (@SQLife)) que este problema estaba causado por una combinación de síntomas:(a) Kerberos no se configuró correctamente y (b) el algoritmo de cifrado para hadr_endpoint que había creado predeterminado a RC4. Esto estaría bien si todas las instancias independientes también usaran RC4, pero no lo hicieron. Para resumir, descarté y volví a crear los puntos finales otra vez , en todas las instancias. Como se trataba de un entorno de laboratorio y realmente no necesitaba la compatibilidad con Kerberos (y como ya había invertido suficiente tiempo en estos problemas, tampoco quería perseguir los problemas de Kerberos), configuré todos los puntos finales para usar Negociar con AES:
DROP ENDPOINT [Hadr_endpoint];
GO
CREATE ENDPOINT [Hadr_endpoint]
STATE = STARTED
AS TCP ( LISTENER_PORT = 5023 )
FOR DATABASE_MIRRORING (
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES,
ROLE = ALL); (Ted Krueger (@onpnt) también escribió recientemente en su blog sobre un problema similar).
Ahora, finalmente, pude crear grupos de disponibilidad con todos los diversos requisitos que tenía, entre nodos con rutas de archivo heterogéneas y utilizando varias instancias en el mismo nodo (pero no en el mismo grupo). Aquí hay un vistazo de cómo se verá una de nuestras vistas de Administración AlwaysOn (haga clic para ampliar para obtener una descripción general mucho mejor):
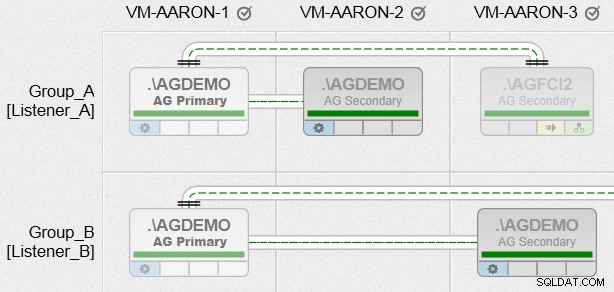
Ahora, eso es solo un poco de burla, y es totalmente intencional. ¡Estaré blogueando más sobre esta funcionalidad en las próximas semanas!
Conclusión
Cuando pasas el tiempo suficiente mirando un problema, puedes pasar por alto algunas cosas bastante obvias. En este caso, hubo algunos problemas obvios ocultos por algunos mensajes de error francamente poco intuitivos. Quiero agradecer a Joe Sack (@JosephSack), Allan Hirt (@SQLHA) y Thomas Stringer (@SQLife) por dejar todo para ayudar a un miembro de la comunidad que lo necesita.