El modelo relacional de gestión de datos fue desarrollado por primera vez por el Dr. Edgar F. Codd en 1969. Los sistemas modernos de gestión de bases de datos relacionales (RDBMS) están alineados con el paradigma. La estructura clave identificada con RDBMS es la estructura lógica llamada "tabla". Las tablas se componen principalmente de filas y columnas (también llamadas registros y atributos o tuplas y campos). En un sentido estrictamente matemático, el término tabla se refiere en realidad como una relación y representa el término "Modelo relacional". En matemáticas, una relación es una representación de un conjunto.
El atributo de expresión brinda una buena descripción del propósito de una columna:caracteriza el conjunto de filas asociadas con ella. Cada columna debe ser de un tipo de datos particular y cada fila debe tener algunas características de identificación únicas llamadas "claves". El cambio de datos suele ser más eficiente cuando se realiza con el modelo relacional, mientras que la recuperación de datos puede ser más rápida con el modelo jerárquico anterior que se ha redefinido en los sistemas modelo NoSQL.
La normalización de datos es un proceso matemático de modelado de datos comerciales en un formato que garantiza que cada entidad esté representada por una sola relación (tabla). Los primeros defensores del modelo relacional propusieron un concepto de formas normales. Edgar Codd definió la primera, la segunda y la tercera forma normal. Luego se le unió Raymond F. Boyce. Juntos definieron la Forma Normal de Boyce-Codd. Por ahora, se definen teóricamente seis formas normales, pero en la mayoría de las aplicaciones prácticas, generalmente extendemos la normalización hasta la tercera forma normal. Cada formulario normal se esfuerza por evitar anomalías durante la modificación de datos, reducir la redundancia y la dependencia de los datos dentro de una tabla. Cada nivel de normalización tiende a introducir más tablas, reduce la redundancia, aumenta la simplicidad de cada tabla pero también aumenta la complejidad de todo el sistema de gestión de bases de datos relacionales. Entonces, estructuralmente, los sistemas RDBM tienden a ser más complejos que los sistemas jerárquicos.
Por qué normalizar la base de datos:cuatro anomalías
El almacenamiento de datos sin normalización provoca una serie de problemas con el consumo de datos. Los defensores de la normalización llamaron anomalías a estos problemas. Para describir estas anomalías, veamos los datos presentados en la Fig. 1.

Fig. 1 mesa de empleados
Listado 1. Tabla básica para demostrar la normalización de la base de datos.
1.1. Crear tabla
use privatework go create table staffers ( staffID int identity (1,1) ,StaffName varchar(50) ,Role varchar(50) ,Department varchar (100) ,Manager varchar (50) ,Gender char(1) ,DateofBirth datetime2 )
1.2. Insertar filas
insert into staffers values ('John Doe','Engineering','Kweku Amarh','M','06-Oct-1965');
insert into staffers values ('Henry Ofori','Engineering','Kweku Amarh','M','06-Mar-1982');
insert into staffers values ('Jessica Yuiah','Engineering','Kweku Amarh','F','06-Oct-1965');
insert into staffers values ('Ahmed Assah','Engineering','Kweku Amarh','M','06-Oct-1965'); 1.3. Consultar la Tabla
select * from staffers;
Esta tabla representa, en esencia, dos conjuntos de datos que se han combinado sin darse cuenta:nombres de personal y departamentos. Tenga en cuenta que todo el personal es del mismo departamento:Ingeniería. Eso se hizo por simplicidad y para demostrar la normalización. Hay tres problemas principales asociados con la manipulación de esta estructura:
La anomalía de inserción
Para insertar un nuevo registro, tenemos que seguir repitiendo los nombres del departamento y del gerente.
La anomalía de eliminación
Para eliminar el registro de un miembro del personal, también debemos eliminar el gerente y el departamento asociado. Si es necesario eliminar TODOS los registros de los empleados, también debemos eliminar todos los departamentos y todos los gerentes.
La anomalía de actualización
Si es necesario cambiar el gerente de cualquier departamento, debemos realizar el cambio en cada fila de esta tabla, ya que los valores se duplican para cada miembro del personal.
Formas normales de base de datos
En las siguientes secciones del artículo, intentaremos describir la 1.ª, la 2.ª y la 3.ª forma normal que es mucho más probable que se observe en los sistemas RDBM reales. Hay otras extensiones de la teoría, como la cuarta, la quinta y las formas normales de Boyce-Codd, pero en este artículo nos limitaremos a las tres formas normales.
La primera forma normal
La primera forma normal se define por cuatro reglas:
Cada columna debe contener valores del mismo tipo de datos.
La mesa Staffers ya cumple con esta regla.
Cada columna de una tabla debe ser atómica.
Básicamente, esto significa que debe dividir el contenido de una columna hasta que ya no se pueda dividir. Observe que el Rol columna en Empleados la tabla rompe la regla 2 para la fila con StaffID=3.
Cada fila de una tabla debe ser única.
La unicidad en las tablas normalizadas generalmente se logra mediante claves principales. Una clave principal define de forma única cada fila de una tabla. La mayoría de las veces, una clave principal está definida por una sola columna. Una clave principal compuesta por más de una columna se denomina clave compuesta.
El orden en que se almacenan los registros no importa.
Para alinear los datos en Staffers tabla con los principios de la Primera Forma Normal, necesitamos dividir la tabla como se muestra en las Figuras 2, 3 y 4.
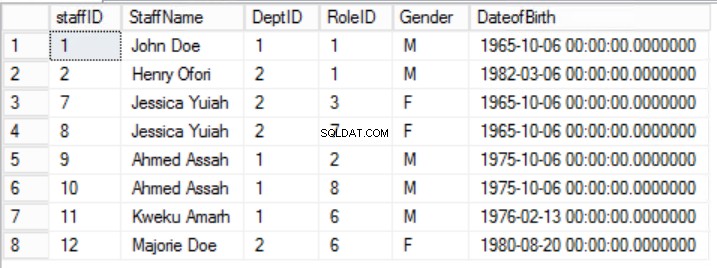
Fig. 2 Mesa de personal
Hemos reducido los datos en Empleados table e implementó una clave principal compuesta para garantizar la unicidad. También hemos creado dos tablas adicionales Roles y Departamentos que tienen relaciones con el núcleo Staffers tabla implementada usando Foreign Keys. Revise el DDL en el Listado 2.
Listado 2. DDL de nuevos personal Tabla de la Primera Forma Normal.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID] [int] NOT NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC, [RoleID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers1NF] WITH CHECK ADD FOREIGN KEY([RoleID]) REFERENCES [dbo].[Roles] ([RoleID]) GO
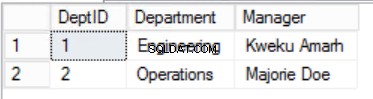
Fig. Tabla 3 Departamentos
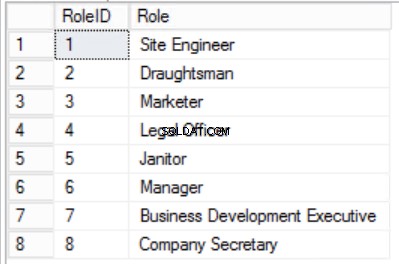
Fig. Tabla de 4 roles
La segunda forma normal
La primera forma normal ya debe estar en su lugar.
Cada columna sin clave no debe tener dependencia parcial de la clave principal.
La idea central de la segunda regla es que todas las columnas de la tabla deben depender de todas las columnas que componen la clave principal juntas. Mirando hacia atrás en las tablas de las Figuras 2, 3 y 4, encontramos que hemos logrado todos los requisitos de la Primera Forma Normal. También hemos logrado los requisitos de la Segunda Forma Normal para dos tablas Roles y Departamentos . Sin embargo, en el caso de los Staffers mesa, todavía tenemos un problema. Nuestra clave principal está compuesta por las columnas StaffID y RoleID.
La regla 2 de la segunda forma normal se rompe aquí por el hecho de que el género y la fecha de nacimiento del personal no dependen del ID de rol. Hay una Dependencia Parcial.
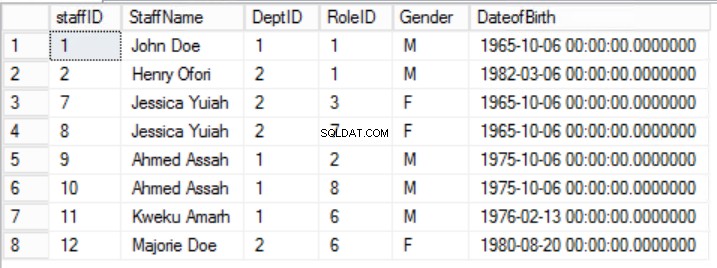
Fig. 5 miembros del personal para la primera forma normal
En el ejemplo dado, podemos intentar solucionar esto eliminando RoleID de la clave principal, pero si hacemos esto, romperemos otra regla:el papel de unicidad establecido en la primera forma normal. Debemos adoptar otro enfoque. Modificaremos los Staffers mesa con el entendimiento de que un miembro del personal puede desempeñar más de un papel. Consulte la figura 6.
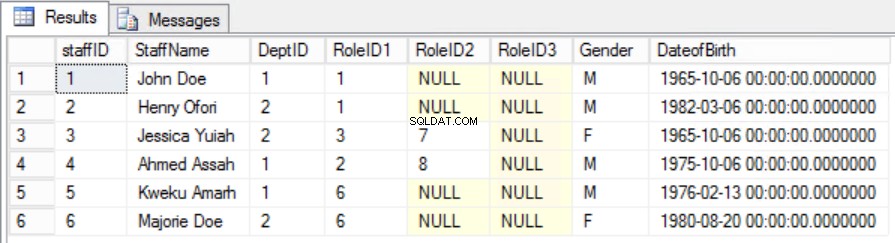
Fig. 6 Tabla de personal para la segunda forma normal
Hemos logrado mantener la singularidad y eliminar la dependencia parcial.
Listado 3. DDL de la Tabla New Staffers para la Segunda Forma Normal.
USE [PrivateWork] GO CREATE TABLE [dbo].[staffers2NF]( [staffID] [int] IDENTITY(1,1) NOT NULL, [StaffName] [varchar](50) NULL, [DeptID] [int] NOT NULL, [RoleID1] [int] NOT NULL, [RoleID2] [int] NULL, [RoleID3] [int] NULL, [Gender] [char](1) NULL, [DateofBirth] [datetime2](7) NULL, PRIMARY KEY CLUSTERED ( [staffID] ASC )WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY] ) ON [PRIMARY] GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([DeptID]) REFERENCES [dbo].[Department] ([DeptID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID1]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID2]) REFERENCES [dbo].[Roles] ([RoleID]) GO ALTER TABLE [dbo].[staffers2NF] WITH CHECK ADD FOREIGN KEY([RoleID3]) REFERENCES [dbo].[Roles] ([RoleID]) GO
La Tercera Forma Normal
La segunda forma normal ya debe estar en su lugar.
Cada columna sin clave no debe tener dependencia transitiva en la clave principal.
La idea central de la tercera forma normal es que no debe haber ninguna columna que dependa de columnas sin clave, incluso si esas columnas sin clave ya dependen de la clave principal.
Como ejemplo, supongamos que decidimos agregar una columna adicional a Empleados como se muestra en la Fig. 7 para ver claramente al gerente del empleado. Al hacerlo, habríamos roto la segunda regla de la tercera forma normal, porque el nombre del gerente depende del DeptID y el DeptID, a su vez, depende del StaffID. Esta es una dependencia transitiva.
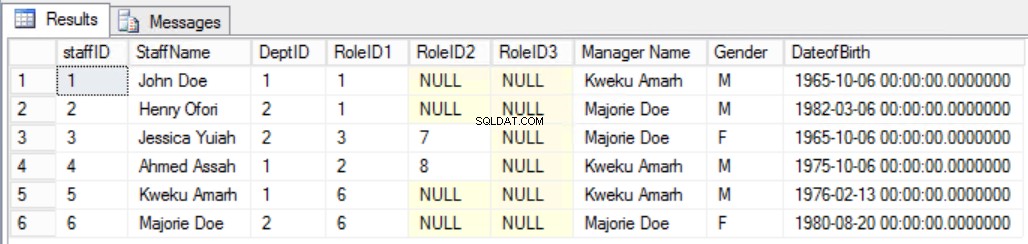
Fig. 7 Tabla de personal para la tercera forma normal (regla rota)
Sería mejor conservar el formulario anterior y mostrar la información requerida mediante una unión entre la tabla Staffers y la tabla Department.
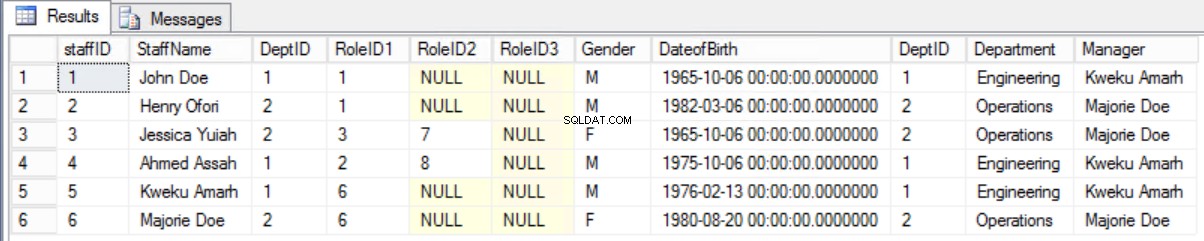
Fig. 8 Unión entre empleado y departamento
Listado 4. Consulta para mostrar personal y gerentes.
select * from staffers2NF s join Department d on s.DeptID=d.DeptID;
Aplicación práctica
La mayoría de las aplicaciones maduras implementan las reglas de normalización en la medida de lo razonable. Vemos que la implementación de la normalización de datos da lugar al uso de restricciones de clave principal y restricciones de clave externa. Además, problemas como la indexación de Foreign Keys también aparecen a medida que profundizamos en el tema. Anteriormente mencionamos cómo la falta de normalización puede afectar la manipulación fluida de los datos como se describe en Anomalías de inserción, eliminación y actualización. La falta de una normalización adecuada también puede afectar indirectamente el rendimiento de las consultas.
Recientemente me encontré con una tabla que tenía el formato que se muestra en la tabla 1 a la que llamaremos Customer_Accounts.
S/No | Nombre | Cuenta_No | Número_de_teléfono |
1 | Kenneth Igiri | 9922344592 | 2348039988456, 2348039988456, 2348039988456 |
2 | Ernest Doe | 6677554897 | 2348022887546, 2348039988456 |
Tabla 1 Customer_Accounts
El principal problema de esta tabla es que rompe la segunda regla de la Primera Forma Normal. El resultado en nuestro caso fue que la búsqueda de clientes en función de sus números de teléfono requería el uso de un LIKE en la cláusula WHERE y un %.
Select account_no from Customer_Accounts where Phone_No like ‘%2348039988456%’;
El impacto de la construcción anterior fue que el optimizador nunca usó un índice, lo que supuso un gran problema de rendimiento.
Conclusión
La normalización de datos se encuentra en el ámbito del diseño de bases de datos y tanto los desarrolladores como los administradores de bases de datos deben prestar atención a las reglas descritas en este artículo. Siempre es mejor realizar la normalización antes de que la base de datos entre en producción. Los beneficios de un sistema de administración de bases de datos relacionales correctamente diseñado simplemente valen la pena.