En caso de que no lo haya visto, acabamos de lanzar ClusterControl 1.7.5 con importantes mejoras y nuevas funciones útiles. Algunas de las características incluyen mantenimiento de todo el clúster, compatibilidad con la versión CentOS 8 y Debian 10, compatibilidad con PostgreSQL 12, compatibilidad con MongoDB 4.2 y Percona MongoDB v4.0, así como el nuevo MySQL Freeze Frame.
Espera, pero ¿qué es un cuadro congelado de MySQL? ¿Es esto algo nuevo para MySQL?
Bueno, no es algo nuevo dentro del Kernel de MySQL. Es una característica nueva que agregamos a ClusterControl 1.7.5 que es específica para las bases de datos MySQL. MySQL Freeze Frame en ClusterControl 1.7.5 cubrirá las siguientes cosas:
- Instantánea del estado de MySQL antes de que falle el clúster.
- Instantánea de la lista de procesos de MySQL antes de que falle el clúster (próximamente).
- Inspeccione los incidentes del clúster en los informes operativos o desde la herramienta de línea de comandos s9s.
Estos son valiosos conjuntos de información que pueden ayudar a rastrear errores y corregir sus clústeres de MySQL/MariaDB cuando las cosas van mal. En el futuro, planeamos incluir también instantáneas de los valores de estado de SHOW ENGINE InnoDB. Por lo tanto, permanezca atento a nuestros futuros lanzamientos.
Tenga en cuenta que esta función aún está en estado beta, esperamos recopilar más conjuntos de datos a medida que trabajamos con nuestros usuarios. En este blog, le mostraremos cómo aprovechar esta característica, especialmente cuando necesite más información al diagnosticar su clúster MySQL/MariaDB.
ClusterControl en el manejo de fallas de clúster
Para fallas del clúster, ClusterControl no hace nada a menos que la recuperación automática (clúster/nodo) esté habilitada como se muestra a continuación:

Una vez habilitado, ClusterControl intentará recuperar un nodo o recuperar el clúster mediante mostrar toda la topología del clúster.
Para MySQL, por ejemplo en una replicación maestro-esclavo, debe tener al menos un maestro vivo en un momento dado, independientemente de la cantidad de esclavos disponibles. ClusterControl intenta corregir la topología al menos una vez para los clústeres de replicación, pero proporciona más reintentos para la replicación multimaestro como NDB Cluster y Galera Cluster. La recuperación de nodos intenta recuperar un nodo de base de datos que falla, p. cuando el proceso se eliminó (cierre anormal) o el proceso sufrió un OOM (fuera de memoria). ClusterControl se conectará al nodo a través de SSH e intentará abrir MySQL. Anteriormente escribimos en un blog sobre cómo ClusterControl realiza la recuperación automática de bases de datos y la conmutación por error, así que visite ese artículo para obtener más información sobre el esquema para la recuperación automática de ClusterControl.
En la versión anterior de ClusterControl <1.7.5, esos intentos de recuperación activaban alarmas. Pero una cosa que nuestros clientes se perdieron fue un informe de incidentes más completo con información del estado justo antes de la falla del clúster. Hasta que nos dimos cuenta de este déficit y agregamos esta función en ClusterControl 1.7.5. Lo llamamos el "Marco de congelación de MySQL". MySQL Freeze Frame, a partir de este escrito, ofrece un breve resumen de los incidentes que conducen a cambios de estado del clúster justo antes del bloqueo. Lo que es más importante, incluye al final del informe la lista de hosts y sus valores y variables de estado global de MySQL.
¿En qué se diferencia MySQL Freeze Frame de la recuperación automática?
MySQL Freeze Frame no forma parte de la recuperación automática de ClusterControl. Ya sea que la Recuperación automática esté deshabilitada o habilitada, MySQL Freeze Frame siempre hará su trabajo siempre que se haya detectado una falla de clúster o nodo.
¿Cómo funciona MySQL Freeze Frame?
En ClusterControl, hay ciertos estados que clasificamos como diferentes tipos de estado de clúster. MySQL Freeze Frame generará un informe de incidentes cuando se activen estos dos estados:
- CLUSTER_DEGRADADO
- CLUSTER_FAILURE
En ClusterControl, un CLUSTER_DEGRADED es cuando puede escribir en un clúster, pero uno o más nodos están inactivos. Cuando esto ocurra, ClusterControl generará el informe de incidencias.
Para CLUSTER_FAILURE, aunque su nomenclatura se explica por sí sola, es el estado en el que su clúster falla y ya no puede procesar lecturas o escrituras. Entonces ese es un estado CLUSTER_FAILURE. Independientemente de si un proceso de recuperación automática intenta solucionar el problema o si está deshabilitado, ClusterControl generará el informe de incidentes.
¿Cómo se habilita MySQL Freeze Frame?
MySQL Freeze Frame de ClusterControl está habilitado de forma predeterminada y solo genera un informe de incidente cuando se activan o se encuentran los estados CLUSTER_DEGRADED o CLUSTER_FAILURE. Por lo tanto, no es necesario que el usuario establezca ningún ajuste de configuración de ClusterControl, ClusterControl lo hará automáticamente por usted.
Ubicación del informe de incidentes de cuadro congelado de MySQL
Al momento de escribir este artículo, hay 4 formas en las que puede localizar el informe del incidente. Estos se pueden encontrar haciendo las siguientes secciones a continuación.
Uso de la pestaña Informes operativos
Los informes operativos de las versiones anteriores se utilizan solo para crear, programar o enumerar los informes operativos generados por los usuarios. Desde la versión 1.7.5, incluimos el informe de incidentes generado por nuestra función MySQL Freeze Frame. Vea el siguiente ejemplo:
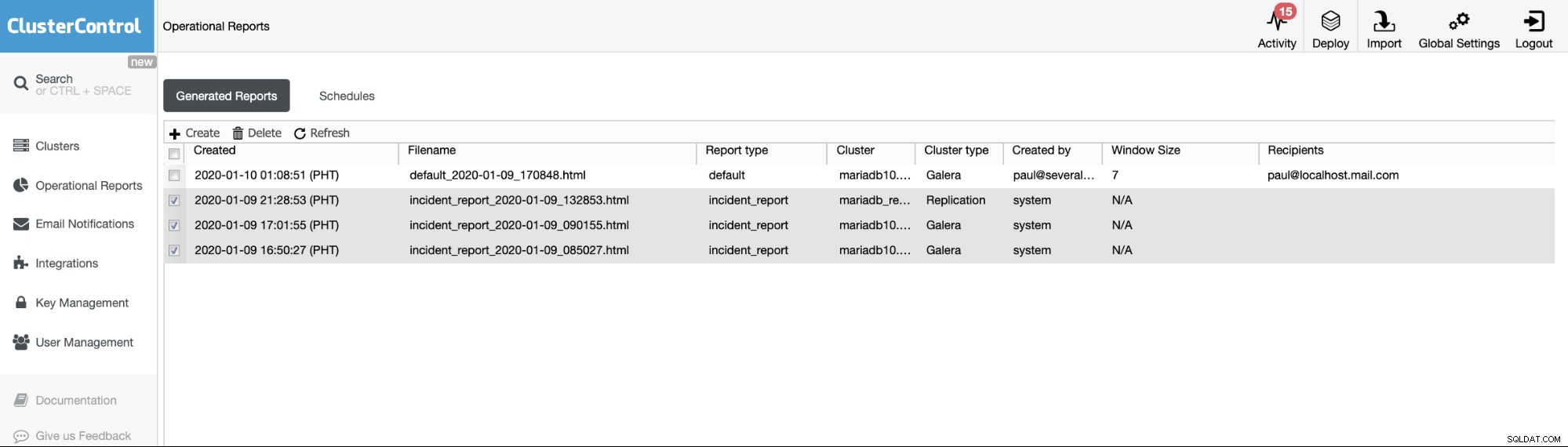
Los ítems marcados o ítems con Report type ==incident_report, son el incidente informes generados por la función MySQL Freeze Frame en ClusterControl.
Uso de informes de errores
Al seleccionar el clúster y generar un informe de errores, es decir, siguiendo este proceso:
Uso de la línea de comandos CLI de s9s
En un informe de incidente generado, incluye instrucciones o sugerencias sobre cómo puede usar esto con el comando CLI s9s. A continuación se muestra lo que se muestra en el informe de incidentes:
¡Consejo! El uso de la herramienta CLI s9s le permite agrupar fácilmente los datos en este informe, por ejemplo:
s9s report --list --long
s9s report --cat --report-id=NEntonces, si desea ubicar y generar un informe de error, puede usar este enfoque:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportSi quiero grep las variables wsrep_* en un host específico, puedo hacer lo siguiente:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Ubicación manual a través de la ruta del archivo del sistema
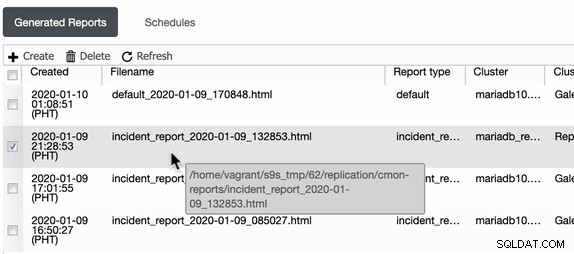
ClusterControl genera estos informes de incidentes en el host donde se ejecuta ClusterControl. ClusterControl crea un directorio en /home/
¿Existen peligros o advertencias al usar MySQL Freeze Frame?
ClusterControl no cambia ni modifica nada en sus nodos o clúster de MySQL. MySQL Freeze Frame solo leerá MOSTRAR ESTADO GLOBAL (a partir de este momento) a intervalos específicos para guardar registros, ya que no podemos predecir el estado de un nodo o clúster MySQL cuando puede fallar o cuando puede tener problemas de hardware o disco. No es posible predecir esto, por lo que guardamos los valores y, por lo tanto, podemos generar un informe de incidentes en caso de que un nodo en particular se caiga. En ese caso, el peligro de tener esto es casi nulo. En teoría, puede agregar una serie de solicitudes de clientes a los servidores en caso de que se mantengan algunos bloqueos dentro de MySQL, pero aún no lo hemos notado. háganoslo saber o presente un ticket de soporte en caso de que surjan problemas.
Hay ciertas situaciones en las que un informe de incidentes podría no ser capaz de recopilar variables de estado global si un problema de red era el problema antes de que ClusterControl congelara un marco específico para recopilar datos. Eso es completamente razonable porque no hay forma de que ClusterControl pueda recopilar datos para un diagnóstico posterior ya que, en primer lugar, no hay conexión con el nodo.
Por último, quizás se pregunte por qué no se muestran todas las variables en la sección ESTADO GLOBAL. Mientras tanto, configuramos un filtro donde los valores vacíos o 0 se excluyen en el informe de incidentes. La razón es que queremos ahorrar algo de espacio en disco. Una vez que estos informes de incidentes ya no sean necesarios, puede eliminarlos a través de la pestaña Informes operativos.
Prueba de la función de cuadro congelado de MySQL
Creemos que está ansioso por probar este y ver cómo funciona. Pero, por favor, asegúrese de no ejecutar o probar esto en un entorno real o de producción. Cubriremos 2 fases del escenario en MySQL/MariaDB, una para la configuración maestro-esclavo y otra para la configuración tipo Galera.
Escenario de prueba de configuración maestro-esclavo
En una configuración maestro-esclavo(s), es fácil y simple de probar.
Paso uno
Asegúrese de haber deshabilitado los modos de recuperación automática (clúster y nodo), como se muestra a continuación:

para que no intente solucionar el escenario de prueba.
Paso Dos
Vaya a su nodo maestro e intente configurarlo en solo lectura:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Paso tres
Esta vez, se emitió una alarma y se generó un informe de incidente. Vea a continuación cómo se ve mi clúster:

y saltó la alarma:

y se generó el reporte de incidente:

Escenario de prueba de configuración de clúster de Galera
Para la configuración basada en Galera, debemos asegurarnos de que el clúster ya no estará disponible, es decir, una falla en todo el clúster. A diferencia de la prueba Maestro-Esclavo, puede habilitar la recuperación automática ya que jugaremos con las interfaces de red.
Nota:para esta configuración, asegúrese de tener varias interfaces si está probando los nodos en una instancia remota, ya que no puede activar la interfaz cuando desactiva la interfaz a la que está conectado.
Paso uno
Cree un clúster Galera de 3 nodos (por ejemplo, usando vagrant)
Paso Dos
Emita el comando (como se muestra a continuación) para simular un problema de red y haga esto en todos los nodos
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Paso tres
Ahora, quitó mi clúster y tiene este estado:

provocó una alarma,

y genera un reporte de incidente:

Para obtener un informe de incidente de muestra, puede usar este archivo sin formato y guardarlo como html.
Es bastante simple de intentar, pero nuevamente, hágalo solo en un entorno que no sea en vivo y sin producción.
Conclusión
MySQL Freeze Frame en ClusterControl puede ser útil al diagnosticar fallas. Al solucionar problemas, necesita una gran cantidad de información para determinar la causa y eso es exactamente lo que proporciona MySQL Freeze Frame.