Todos cometemos errores y todos podemos aprender de los errores de otras personas. En esta publicación, veremos numerosos recursos en línea para evitar un diseño deficiente de la base de datos que puede generar muchos problemas y costar tiempo y dinero. Y en un próximo artículo, le diremos dónde encontrar consejos y mejores prácticas.
Errores de diseño de bases de datos y errores a evitar
Existen numerosos recursos en línea para ayudar a los diseñadores de bases de datos a evitar errores y errores comunes. Obviamente, este artículo no es una lista exhaustiva de todos los artículos que existen. En su lugar, hemos revisado y comentado una variedad de fuentes diferentes para que pueda encontrar la que mejor se adapte a sus necesidades.
Nuestra recomendación
Si solo hay un artículo entre estos recursos que va a leer, debería ser 'Cómo hacer que el diseño de la base de datos sea terriblemente incorrecto' de Robert Sheldon
Comencemos con el blog DATAVERSITY que proporciona un amplio conjunto de recursos bastante buenos:
Errores de clave principal y clave externa que se deben evitar
por Michael Blaha | blog DATAVERSIDAD | 2 de septiembre de 2015
Más errores de diseño de bases de datos:confusión con relaciones de muchos a muchos
por Michael Blaha | blog DATAVERSIDAD | 30 de septiembre de 2015
Errores varios en el diseño de la base de datos
por Michael Blaha | blog DATAVERSIDAD | 26 de octubre de 2015
Michael Blaha ha contribuido con un buen conjunto de tres artículos. Cada artículo aborda diferentes dificultades del modelado de bases de datos y el diseño físico; los temas incluyen claves, relaciones y errores generales. Además, hay discusiones con Michael sobre algunos de los puntos. Si está buscando trampas en torno a las claves y las relaciones, este sería un buen lugar para comenzar.
El Sr. Blaha afirma que "alrededor del 20% de las bases de datos violan las reglas de clave principal". ¡Guau! Eso significa que alrededor del 20 % de los desarrolladores de bases de datos no crearon correctamente las claves primarias. Si esta estadística es cierta, entonces realmente muestra la importancia de las herramientas de modelado de datos que "fomentan" fuertemente o incluso requieren que los modeladores definan claves primarias.
El Sr. Blaha también comparte la heurística de que "alrededor del 50 % de las bases de datos" tienen problemas de clave externa (según su experiencia con bases de datos heredadas que ha estudiado). Nos recuerda que evitemos la vinculación informal entre tablas incrustando el valor de una tabla en otra en lugar de usar una clave externa.
He visto este problema muchas veces. Admito que el enlace informal puede ser requerido por la funcionalidad a implementar, pero más a menudo ocurre por simple pereza. Por ejemplo, es posible que deseemos mostrar la identificación de usuario de alguien que modificó algo, por lo que almacenamos la identificación de usuario directamente en la tabla. Pero, ¿qué pasa si ese usuario cambia su identificación de usuario? Entonces este vínculo informal se rompe. Esto a menudo se debe a un diseño y modelado deficientes.
Diseñando su base de datos:los 5 principales errores a evitar
por Henrique Netzka | blog DATAVERSIDAD | 2 de noviembre de 2015
Me decepcionó un poco este artículo, ya que tenía un par de elementos bastante específicos (protocolo de almacenamiento en un CLOB) y algunos muy generales (piense en la localización). En general, el artículo está bien, pero ¿son estos realmente los 5 errores principales que se deben evitar? En mi opinión, hay varios otros errores comunes que deberían figurar en la lista.
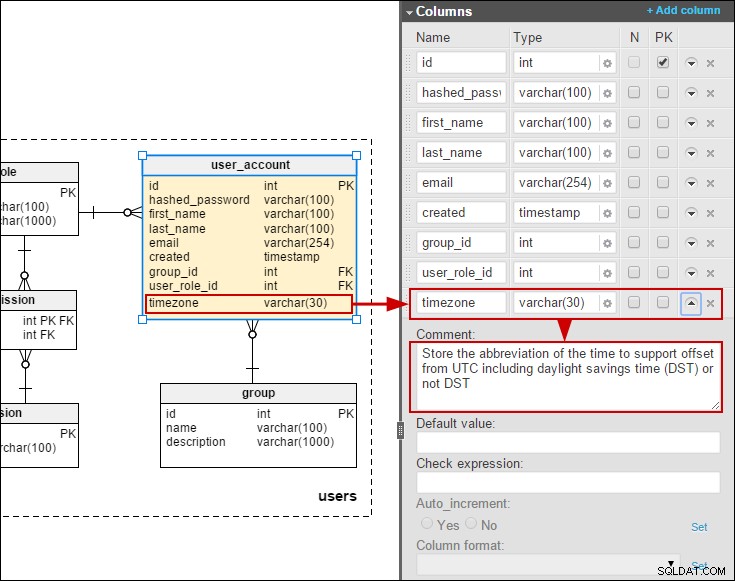
Sin embargo, como nota positiva, este es uno de los pocos artículos que menciona la globalización y la localización de manera significativa. Trabajo en un entorno muy multilingüe y he visto varias implementaciones horribles de localización, por lo que me alegró encontrar que se mencionara este problema. Las columnas de idioma y las columnas de zona horaria pueden parecer obvias, pero rara vez aparecen en los modelos de bases de datos.
Dicho esto, pensé que sería interesante crear un modelo que incluya traducciones que los usuarios finales puedan modificar (en lugar de usar paquetes de recursos). Hace algún tiempo, escribí sobre un modelo para una base de datos de encuestas en línea. Aquí he modelado una traducción simplificada de preguntas y opciones de respuesta:
Suponiendo que debemos permitir que los usuarios finales mantengan las traducciones, el método preferido sería agregar tablas de traducción para preguntas y respuestas:
También agregué una zona horaria a la user_account tabla para que podamos almacenar fechas/horas en la hora local de los usuarios:
7 errores comunes de diseño de bases de datos
por Grzegorz Kaczor | Vertabelo blog | 17 de julio de 2015
Voy a hacer un poco de autopromoción aquí. Nos esforzamos por publicar regularmente artículos interesantes y atractivos aquí.
Este artículo en particular señala varias áreas importantes de preocupación, como nombres, indexación, consideraciones de volumen y registros de auditoría. El artículo incluso aborda cuestiones relacionadas con sistemas DBM específicos, como las limitaciones de Oracle en los nombres de las tablas. Me gustan mucho los buenos ejemplos claros, incluso si ilustran cómo los diseñadores cometen errores y errores.
Obviamente, no es posible enumerar todos los errores de diseño y es posible que los que aparecen en la lista no sean su errores más comunes. Cuando escribimos sobre errores comunes, nos basamos en los que hemos cometido o hemos encontrado en el trabajo de otros. Una lista completa de errores, clasificados en términos de frecuencia, sería imposible de compilar para una sola persona. Sin embargo, creo que este artículo proporciona varias ideas útiles sobre posibles peligros. Es un buen recurso sólido en general.
Si bien el Sr. Kaczor hace varios puntos interesantes en su artículo, sus comentarios sobre "no considerar el posible volumen o tráfico" me parecieron bastante interesantes. En particular, la recomendación de separar los datos de uso frecuente de los datos históricos es particularmente pertinente. Esta es una solución que usamos con frecuencia en nuestras aplicaciones de mensajería; debemos tener un historial de búsqueda de todos los mensajes, pero es más probable que se acceda a los mensajes que se han publicado en los últimos días. Por lo tanto, dividir los datos "activos" o recientes a los que se accede con frecuencia (un volumen de datos mucho menor) de los datos históricos a largo plazo (la gran masa de datos) suele ser una muy buena técnica.
Errores comunes en el diseño de bases de datos
por Troy Blake | Blog sénior de DBA | 11 de julio de 2015
El artículo de Troy Blake es otro buen recurso, aunque podría haber cambiado el nombre de este artículo a "Errores comunes de diseño de SQL Server".
Por ejemplo, tenemos el comentario:"los procedimientos almacenados son su mejor amigo cuando se trata de usar SQL Server de manera efectiva". Está bien, pero ¿es un error general común o es más específico de SQL Server? Tendría que optar por que esto sea un poco específico de SQL Server, ya que existen desventajas en el uso de procedimientos almacenados, como terminar con procedimientos almacenados específicos del proveedor y, por lo tanto, el bloqueo del proveedor. Por lo tanto, no soy partidario de incluir "No utilizar procedimientos almacenados" en esta lista.
Sin embargo, en el lado positivo, creo que el autor identificó algunos errores muy comunes, como una planificación deficiente, un diseño de sistema de mala calidad, documentación limitada, estándares de nomenclatura débiles y falta de pruebas.
Así que clasificaría esto como una referencia muy útil para los practicantes de SQL Server y una referencia útil para otros.
Siete errores de modelado de datos
por Kurt Cagle | LinkedIn | 12 de junio de 2015
Realmente disfruté leyendo la lista de errores de modelado de bases de datos del Sr. Cagle. Estos son desde la visión de las cosas de un arquitecto de base de datos; identifica claramente los errores de modelado de alto nivel que deben evitarse. Con esta vista de imagen más grande, puede abortar un posible lío de modelado.
Algunos de los tipos mencionados en el artículo se pueden encontrar en otros lugares, pero algunos de ellos son únicos:se vuelven abstractos demasiado pronto o mezclan modelos conceptuales, lógicos y físicos. Estos no son mencionados a menudo por otros autores, probablemente porque se centran en el proceso de modelado de datos en lugar de la vista más grande del sistema.
En particular, el ejemplo de "Hacerse demasiado abstracto demasiado pronto" describe un proceso de pensamiento interesante de crear algunas "historias" de muestra y probar qué relaciones son importantes en este dominio. Esto enfoca el pensamiento en las relaciones entre los objetos que se modelan. Da como resultado preguntas como cuáles son las relaciones importantes en este dominio ?
Con base en esta comprensión, creamos el modelo en torno a las relaciones en lugar de comenzar con elementos de dominio individuales y construir las relaciones sobre ellos. Si bien muchos de nosotros podríamos usar este enfoque, entre estos recursos, ningún otro autor lo comentó. Encontré esta descripción y los ejemplos bastante interesantes.
Cómo hacer que el diseño de la base de datos sea terriblemente incorrecto
de Robert Sheldon | Charla sencilla | 6 de marzo de 2015
Si solo hay un artículo entre estos recursos que vas a leer, debería ser este de Robert Sheldon
Lo que realmente me gusta de este artículo es que para cada uno de los errores mencionados hay consejos sobre cómo hacerlo bien. La mayoría de estos se centran en evitar el fallo en lugar de corregirlo, pero sigo pensando que son muy útiles. Hay muy poca teoría aquí; en su mayoría respuestas directas sobre cómo evitar errores durante el modelado de datos. Hay algunos puntos específicos de SQL Server, pero principalmente SQL Server se usa para proporcionar ejemplos de cómo evitar errores o formas de salir de fallas.
El alcance del artículo también es bastante amplio:cubre descuidar la planificación, no molestarse con la documentación, usar convenciones de nomenclatura pésimas, tener problemas en la normalización (demasiado o muy poco), fallar en las claves y restricciones, no indexar correctamente y realizar pruebas inadecuadas.
En particular, me gustaron los consejos prácticos sobre la integridad de los datos:cuándo usar restricciones de verificación y cuándo definir claves externas. Además, el Sr. Sheldon también describe la situación en la que los equipos se remiten a la aplicación para hacer cumplir la integridad. Está en lo cierto cuando afirma que se puede acceder a una base de datos de múltiples maneras y mediante numerosas aplicaciones. Su concluye que “los datos deben protegerse donde residen:dentro de la base de datos”. Esto es tan cierto que se puede repetir a los equipos de desarrollo y gerentes para explicarles la importancia de implementar controles de integridad en el modelo de datos.
Este es mi tipo de artículo, y se nota que otros están de acuerdo en base a los numerosos comentarios que lo respaldan. Entonces, máximas calificaciones aquí; es un recurso muy valioso.
Diez errores comunes en el diseño de bases de datos
por Louis Davidson | Charla sencilla | 26 de febrero de 2007
Encontré este artículo bastante bueno, ya que cubría muchos errores comunes de diseño. Había analogías significativas, ejemplos, modelos e incluso algunas citas clásicas de William Shakespeare y J.R.R. Tolkien.
Un par de errores se explicaron con mayor detalle que otros, con ejemplos largos y extractos de SQL que encontré un poco engorrosos. Pero eso es cuestión de gustos.
Una vez más, tenemos algunos temas específicos de SQL Server. Por ejemplo, el punto de no usar procedimientos almacenados para acceder a los datos es bueno para SQL, pero los SP no siempre son una buena idea cuando el objetivo es admitir múltiples DBMS. Además, se nos advierte que no intentemos codificar objetos T-SQL genéricos. Como rara vez trabajo con SQL Server o Sybase, este consejo no me pareció relevante.
La lista es bastante similar a la de Robert Sheldon, pero si está trabajando principalmente en SQL Server, encontrará algunas pepitas de información adicionales.
Cinco errores simples de diseño de bases de datos que debe evitar
por Anith Sen Larson | Charla sencilla | 16 de octubre de 2009
Este artículo brinda algunos ejemplos significativos para cada uno de los errores de diseño simples que cubre. Por otro lado, se centra más bien en tipos de errores similares:tablas de búsqueda comunes, tablas de entidad-atributo-valor y división de atributos.
Las observaciones están bien, e incluso el artículo tiene referencias, que suelen ser escasas. Aún así, me gustaría ver errores de diseño de base de datos más generales. Estos errores parecían bastante específicos, pero, como ya he escrito, los errores sobre los que escribimos son generalmente aquellos con los que tenemos experiencia personal.
Un elemento que me gustó fue una regla general específica para decidir cuándo usar una restricción de verificación en lugar de una tabla separada con una restricción de clave externa. Varios autores brindan recomendaciones similares, pero el Sr. Larson las divide en "debe", "considerar" y "caso fuerte", con la admisión de que "el diseño es una mezcla de arte y ciencia y, por lo tanto, implica compensaciones". Encuentro esto muy cierto.
Los diez errores de diseño de bases de datos físicas más comunes
por Craig Mullins | Datos y tecnología hoy | 5 de agosto de 2013
Como su nombre lo indica, "Los diez errores de diseño de bases de datos físicos más comunes" está ligeramente más orientado al diseño físico que al diseño lógico y conceptual. Ninguno de los errores que menciona el autor Craig Mullins realmente se destaca o es único, por lo que recomendaría esta información a las personas que trabajan en el lado físico de DBA.
Además, las descripciones son un poco cortas, por lo que en ocasiones es difícil ver por qué un error en particular va a causar problemas. No hay nada intrínsecamente malo en las descripciones breves, pero no dan mucho en qué pensar. Y no se presentan ejemplos.
Hay un punto interesante planteado en relación con la falta de intercambio de datos. Este punto se menciona ocasionalmente en otros artículos, pero no como un error de diseño. Sin embargo, veo este problema con bastante frecuencia cuando las bases de datos se "recrean" en función de requisitos muy similares, pero por parte de un nuevo equipo o para un nuevo producto.
.A menudo sucede que el equipo de producto se da cuenta más tarde de que les hubiera gustado usar datos que ya estaban presentes en el "padre" de su base de datos actual. Sin embargo, en realidad, deberían haber mejorado al padre en lugar de crear una nueva descendencia. Las aplicaciones están destinadas a compartir datos; un buen diseño puede permitir que una base de datos se reutilice con más frecuencia.
¿Cometes estos 5 errores de diseño de bases de datos?
por Thomas Larock | El blog de Thomas Larock | 2 de enero de 2012
Es posible que encuentre algunos puntos interesantes al responder la pregunta de Thomas Larock:¿Comete estos 5 errores de diseño de bases de datos?
Este artículo tiene una gran importancia para las claves (claves externas, claves sustitutas y claves generadas). Sin embargo, tiene un punto importante:uno no debe asumir que las funciones de DBMS son las mismas en todos los sistemas. Creo que este es un punto muy bueno. También es uno que no se encuentra en la mayoría de los otros artículos, quizás porque muchos autores se enfocan y trabajan predominantemente con un solo DBMS.
Diseñar una base de datos:7 cosas que no quieres hacer
por Thomas Larock | El blog de Thomas Larock | 16 de enero de 2013
El Sr. Larock recicló un par de sus "5 errores de diseño de bases de datos" al escribir "7 cosas que no quiere hacer", pero hay otros puntos buenos aquí.
Curiosamente, algunos de los puntos que plantea el Sr. Larock no se encuentran en muchas otras fuentes. Obtiene un par de observaciones bastante únicas, como "no tener expectativas de rendimiento". Este es un error grave y que, según mi experiencia, ocurre con bastante frecuencia. Incluso cuando se desarrolla el código de la aplicación, a menudo es después de que se hayan creado el modelo de datos, la base de datos y la aplicación en sí que las personas comienzan a pensar en los requisitos no funcionales (cuando se deben crear pruebas no funcionales) y comienzan a definir las expectativas de rendimiento. .
Por el contrario, hay algunos puntos que no incluiría en mi propia lista Top Ten, como "ir a lo grande, por si acaso". Veo el punto, pero no es tan alto en mi lista al crear un modelo de datos. No hay especificidad para un sistema DBM en particular, por lo que es una ventaja.
Para concluir, muchos de estos puntos podrían resumirse bajo el punto:"no entender los requisitos", que realmente está en mi lista de los 10 errores principales.
Cómo evitar 8 errores comunes en el desarrollo de bases de datos
por Base36 | 6 de diciembre de 2012
Estaba bastante interesado en leer este artículo. Sin embargo, me decepcionó un poco. No hay mucha discusión sobre la evitación, y el punto del artículo realmente parece ser "estos son errores comunes de la base de datos" y "por qué son errores"; las descripciones de cómo evitar el error son menos prominentes.
Además, algunos de los 8 errores principales del artículo están en disputa. El mal uso de la clave principal es un ejemplo. Base36 nos dice que deben ser generados por el sistema y no basados en datos de aplicación en la fila. Si bien estoy de acuerdo con esto hasta cierto punto, no estoy convencido de que todas Los PK deben siempre ser generado; eso es un poco demasiado categórico.
Por otro lado, el error de "Borrados duros" es interesante y no se menciona a menudo en otros lugares. Las eliminaciones parciales causan otros problemas, pero es cierto que el simple hecho de marcar una fila como inactiva tiene sus ventajas cuando se trata de averiguar a dónde fueron a parar los datos que estaban ayer en el sistema. Buscar en los registros de transacciones no es mi idea de una forma agradable de pasar el día.
Siete pecados capitales del diseño de bases de datos
por Jason Tiret | Revista de sistemas empresariales | 16 de febrero de 2010
Tenía muchas esperanzas cuando comencé a leer el artículo de Jason Tiret, "Los siete pecados capitales del diseño de bases de datos". Así que me alegró descubrir que no solo reciclaba los errores que se encuentran en muchos otros artículos. Por el contrario, ofrecía un “pecado” que no había encontrado en otras listas:tratar de realizar todo el diseño de la base de datos “por adelantado” y no actualizar el modelo después de que la base de datos está en producción, cuando se realizan cambios en la base de datos. (O, como dice Jason, "No tratar el modelo de datos como un organismo vivo que respira").
He visto este error muchas veces. La mayoría de las personas solo se dan cuenta de su error cuando deben realizar actualizaciones en un modelo que ya no coincide con la base de datos real. Por supuesto, el resultado es un modelo inútil. Como dice el artículo, "los cambios deben volver al modelo".
Por otro lado, la mayoría de los elementos de la lista de Jason son bastante conocidos. Las descripciones son buenas, pero no hay muchos ejemplos. Más ejemplos y detalles serían útiles.
Los errores de diseño de bases de datos más comunes
por Brian Prince | eWeek.com | 19 de marzo de 2008

El artículo “Los errores de diseño de bases de datos más comunes” es en realidad una serie de diapositivas de una presentación. Hay algunos pensamientos interesantes, pero algunos de los elementos únicos son quizás un poco esotéricos. Tengo en mente puntos como "Conozca RAID" y la participación de las partes interesadas.
En general, no pondría esto en su lista de lectura a menos que se centre en cuestiones generales (planificación, denominación, normalización, índices) y detalles físicos.
10 errores comunes de diseño
por davidm | Blogs de SQL Server – SQLTeam.com | 12 de septiembre de 2005
Algunos de los puntos de "Diez errores comunes de diseño" son interesantes y relativamente novedosos. Sin embargo, algunos de estos errores son bastante controvertidos, como "usar NULL" y desnormalizar.
Acepto que crear todas las columnas como anulables es un error, pero definir una columna como anulable puede ser necesario para una función comercial en particular. ¿Puede por tanto considerarse como un error genérico? Creo que no.
Otro punto con el que discrepo es la desnormalización. Esto no siempre es un error de diseño. Por ejemplo, la desnormalización puede ser necesaria por motivos de rendimiento.
Este artículo también carece en gran medida de detalles y ejemplos. Las conversaciones entre DBA y el programador o gerente son divertidas, pero hubiera preferido ejemplos más concretos y justificaciones detalladas para estos errores comunes.
OTLT y EAV:los dos grandes errores de diseño que cometen todos los principiantes
por Tony Andrews | Tony Andrews sobre Oracle y las bases de datos | 21 de octubre de 2004
El artículo del Sr. Andrews nos recuerda los errores de "One True Lookup Table" (OTLT) y Entity-Attribute-Value (EAV) que se mencionan en otros artículos. Un buen punto de esta presentación es que se centra en estos dos errores, por lo que las descripciones y los ejemplos son precisos. Además, se brinda una posible explicación de por qué algunos diseñadores implementan OTLT y EAV.
Para recordarle, la tabla OTLT generalmente se parece a esto, con entradas de múltiples dominios en la misma tabla:
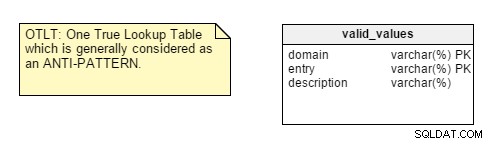
Como de costumbre, existe una discusión sobre si OTLT es una solución viable y un buen patrón de diseño. Debo decir que estoy del lado del grupo anti-OTLT; estas tablas introducen numerosos problemas. Podríamos usar la analogía de usar un solo enumerador para representar todos los valores posibles de todas las constantes posibles. Nunca he visto eso, hasta ahora.
Errores comunes de bases de datos
por John Paul Ashenfelter | del Dr. Dobb | 01 de enero de 2002
El artículo del Sr. Ashenfelter enumera 15 errores comunes en las bases de datos. Incluso hay algunos errores que no se mencionan con frecuencia en otros artículos. Desafortunadamente, las descripciones son relativamente cortas y no hay ejemplos. El mérito de este artículo es que la lista cubre mucho terreno y puede usarse como una "lista de verificación" de los errores que se deben evitar. Si bien es posible que no los clasifique como los errores de base de datos más importantes, ciertamente se encuentran entre los más comunes.
Como nota positiva, este es uno de los pocos artículos que menciona la necesidad de manejar la internacionalización de formatos para datos como fecha, moneda y dirección. Un ejemplo estaría bien aquí. Podría ser tan simple como “asegúrese de que State sea una columna anulable; en muchos países, no hay un estado asociado con una dirección”.
Anteriormente en este artículo, mencioné otras preocupaciones y algunos enfoques para prepararse para la globalización de su base de datos, como las zonas horarias y las traducciones (localización). El hecho de que ningún otro artículo mencione la preocupación por los formatos de moneda y fecha es preocupante. ¿Están nuestras bases de datos preparadas para el uso global de nuestras aplicaciones?
Menciones de honor
Obviamente, hay otros artículos que describen errores y errores comunes en el diseño de bases de datos, pero queríamos brindarle una revisión amplia de diferentes recursos. Puede encontrar información adicional en artículos como:
10 errores comunes en el diseño de bases de datos | Blog de la clase MIS | 29 de enero de 2012
10 errores comunes en el diseño de bases de datos | IDG.es | 24 de junio de 2010
Recursos en línea:¿Por dónde empezar? ¿Adónde ir?
Como se mencionó anteriormente, esta lista definitivamente no pretende ser un examen exhaustivo de todos los artículos en línea que describen errores y errores en el diseño de la base de datos. Más bien, hemos identificado varias fuentes que son particularmente útiles o tienen un enfoque específico que podría resultarle útil.
No dude en recomendar artículos adicionales.