¿Alguna vez se ha puesto en contacto con Microsoft o un socio de Microsoft y discutido con ellos cuánto costaría migrar a la nube? Si es así, es posible que haya oído hablar de la calculadora DTU de la base de datos SQL de Azure y que también haya leído acerca de cómo Andy Mallon realizó ingeniería inversa. La calculadora de DTU es una herramienta gratuita que puede usar para cargar métricas de rendimiento desde su servidor y usar los datos para determinar el nivel de servicio adecuado si tuviera que migrar ese servidor a una base de datos SQL de Azure (o a un grupo elástico de base de datos SQL).
Para hacer esto, debe programar o ejecutar manualmente un script (línea de comando o Powershell, disponible para descargar en el sitio web de la calculadora de DTU) durante un período de una carga de trabajo de producción típica.
Si está tratando de analizar un entorno grande o desea analizar datos de puntos específicos en el tiempo, esto puede convertirse en una tarea. En muchos casos, muchos DBA tienen una especie de herramienta de monitoreo que ya está capturando datos de rendimiento para ellos. En muchos casos, es probable que ya esté capturando las métricas necesarias o que se pueda configurar fácilmente para capturar los datos que necesita. Hoy veremos cómo aprovechar SentryOne para poder proporcionar los datos apropiados a la calculadora de DTU.
Para comenzar, veamos la información extraída por la utilidad de línea de comandos y el script de PowerShell disponible en el sitio web de la calculadora de DTU; hay 4 contadores de monitor de rendimiento que captura:
- Procesador:% de tiempo del procesador
- Disco lógico:lecturas de disco/seg
- Disco lógico:escrituras en disco/seg
- Base de datos:bytes de registro vaciados/seg
El primer paso es determinar si estas métricas ya están capturadas como parte de la recopilación de datos en SQL Sentry. Para el descubrimiento, sugiero leer esta publicación de blog de Jason Hall, donde habla sobre cómo se distribuyen los datos y cómo puede consultarlos. No voy a explicar cada paso de esto aquí, pero lo animo a leer y marcar toda la serie de blogs.
Cuando revisé la base de datos de SentryOne, descubrí que 3 de los 4 contadores ya estaban siendo capturados de manera predeterminada. El único que faltaba era [Database – Log Bytes Flushed/sec] , así que necesitaba poder activar eso. Hubo otra publicación de blog de Justin Randall que explica cómo hacerlo.
En resumen, puede consultar el [PerformanceAnalysisCounter] mesa.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Notará que por defecto el [PerformanceAnalysisSampleIntervalID] se establece en 0, lo que significa que está deshabilitado. Deberá ejecutar el siguiente comando para habilitar esto. Simplemente extraiga el ID de la consulta SELECT que acaba de ejecutar y utilícelo en esta ACTUALIZACIÓN:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
Después de ejecutar la actualización, deberá reiniciar los servicios de monitoreo de SentryOne relevantes para este objetivo, de modo que se puedan recopilar los nuevos datos del contador.
Tenga en cuenta que configuré el [PerformanceAnalysisSampleIntervalID] a 1 para que los datos se capturen cada 10 segundos; sin embargo, puede capturar estos datos con menos frecuencia para minimizar el tamaño de los datos recopilados a costa de una menor precisión. Ver el [PerformanceAnalysisSampleInterval] tabla para obtener una lista de valores que puede usar.
No espere que los datos comiencen a fluir a las tablas inmediatamente; esto tomará tiempo para hacer su camino a través del sistema. Puede verificar la población con la siguiente consulta:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
Una vez que confirme que aparecen los datos, debe tener datos para cada una de las métricas requeridas por la calculadora de DTU, aunque es posible que desee esperar para extraerlos hasta que tenga una muestra representativa de una carga de trabajo completa o un ciclo comercial.
Si lee la publicación del blog de Jason, verá que los datos se almacenan en varias tablas acumulativas y que cada una de estas tablas acumulativas tiene diferentes tasas de retención. Muchos de estos son más bajos de lo que me gustaría si estuviera analizando cargas de trabajo durante un período de tiempo. Si bien es posible cambiarlos, puede que no sea lo más inteligente. Debido a que lo que le muestro no es compatible, es posible que desee evitar jugar demasiado con la configuración de SentryOne, ya que podría tener un impacto negativo en el rendimiento, el crecimiento o ambos.
Para compensar esto, creé una secuencia de comandos que me permite extraer los datos que necesito para las diversas tablas acumulativas y almacenar esos datos en su propia ubicación, para poder controlar mi propia retención y no interferir con la funcionalidad de SentryOne.
TABLA:dbo.AzureDatabaseDTUData
Creé una tabla llamada [AzureDatabaseDTUData] y lo almacenó en la base de datos de SentryOne. El procedimiento que creé generará automáticamente esta tabla si no existe, por lo que no es necesario hacerlo manualmente a menos que desee personalizar dónde se almacena. Puede almacenar esto en una base de datos separada si lo desea, solo necesitaría editar el script para poder hacerlo. La tabla se ve así:
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Procedimiento:dbo.Custom_CollectDTUDataForDevice
Este es el procedimiento almacenado que puede usar para extraer todos los datos específicos de la DTU a la vez (siempre que haya recopilado el contador de bytes de registro durante un período de tiempo suficiente) o programarlo para que se agregue periódicamente a los datos recopilados hasta que está listo para enviar la salida a la calculadora de DTU. Al igual que la tabla anterior, el procedimiento se crea en la base de datos de SentryOne, pero puede crearlo fácilmente en otro lugar, simplemente agregue nombres de tres o cuatro partes a las referencias de objetos. La interfaz del procedimiento es la siguiente:
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Nota :Todo el procedimiento es un poco largo, por lo que se adjunta a esta publicación (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Hay un par de parámetros que puede utilizar. Cada uno tiene un valor predeterminado, por lo que no es necesario que los especifique si está de acuerdo con los valores predeterminados.
- @ID de dispositivo – Esto le permite especificar si desea recopilar datos para un servidor SQL específico o todo. El valor predeterminado es -1, lo que significa copiar todos los servidores SQL observados. Si solo desea exportar información para una instancia específica, busque el
DeviceIDcorrespondiente al host en el[dbo].[Device]tabla, y pasar ese valor. Solo puede pasar un@DeviceIDa la vez, por lo que si desea pasar por un conjunto de servidores, puede llamar al procedimiento varias veces o puede modificar el procedimiento para admitir un conjunto de dispositivos. - @DaysToPurge – Esto representa la edad a la que desea eliminar los datos. El valor predeterminado es 14 días, lo que significa que solo extraerá datos de hasta 14 días de antigüedad y se eliminarán todos los datos que tengan más de 14 días en su tabla personalizada.
Los otros cuatro parámetros están ahí para garantizar el futuro, en caso de que las enumeraciones de SentryOne para las ID de los contadores cambien alguna vez.
Un par de notas sobre el guión:
- Cuando se extraen los datos, toma el valor máximo del minuto truncado y lo exporta. Esto significa que hay un valor por métrica por minuto, pero es el valor máximo capturado. Esto es importante debido a la forma en que se deben presentar los datos a la calculadora de DTU.
- La primera vez que ejecuta la exportación, puede tardar un poco más. Esto se debe a que extrae todos los datos que puede en función de los valores de sus parámetros. En cada ejecución adicional, los únicos datos extraídos son los nuevos desde la última ejecución, por lo que debería ser mucho más rápido.
- Tendrá que programar este procedimiento para que se ejecute en un horario que se mantenga por delante del proceso de purga de SentryOne. Lo que hice fue crear un trabajo del Agente SQL para ejecutar todas las noches que recopila todos los datos nuevos desde la noche anterior.
- Debido a que el proceso de depuración en SentryOne puede variar según la métrica, podría terminar con filas en su copia que no contienen los 4 contadores durante un período de tiempo. Es posible que desee comenzar a analizar sus datos solo desde el momento en que inicia el proceso de extracción.
- Usé un bloque de código de los procedimientos existentes de SentryOne para determinar la tabla acumulada para cada contador. Podría haber codificado los nombres actuales de las tablas, sin embargo, al usar el método SentryOne, debería ser compatible con cualquier cambio en los procesos integrados de acumulación.
Una vez que sus datos se mueven a una tabla independiente, puede usar una consulta PIVOT para transformarlos en la forma que espera la calculadora de DTU.
Procedimiento:dbo.Custom_ExportDataForDTUCalculator
Creé otro procedimiento para extraer los datos en formato CSV. También se adjunta el código de este procedimiento (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Hay tres parámetros:
- @ID de dispositivo – Smallint correspondiente a uno de los dispositivos que está recopilando y que desea enviar a la calculadora.
- @BeginTime – fecha y hora que representa la hora de inicio, en hora local; por ejemplo,
'2018-12-04 05:47:00.000'. El procedimiento se traducirá a UTC. Si se omite, se recopilará desde el valor más antiguo de la tabla. - @EndTime – fecha y hora que representa la hora de finalización, nuevamente en hora local; por ejemplo,
'2018-12-06 12:54:00.000'. Si se omite, recopilará hasta el último valor de la tabla.
Una ejecución de ejemplo, para obtener todos los datos recopilados para SQLInstanceA entre el 4 de diciembre a las 5:47 y el 6 de diciembre a las 12:54.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Los datos deberán exportarse a un archivo CSV. No se preocupe por los datos en sí; Me aseguré de mostrar los resultados para que no haya información de identificación sobre su servidor en el archivo csv, solo fechas y métricas.
Si ejecuta la consulta en SSMS, puede hacer clic con el botón derecho y exportar los resultados; sin embargo, tiene opciones limitadas aquí y tendrá que manipular la salida para obtener el formato esperado por la calculadora DTU. (Siéntase libre de intentarlo y avíseme si encuentra una manera de hacerlo).
Recomiendo simplemente usar el asistente de exportación integrado en SSMS. Haga clic derecho en la base de datos y vaya a Tareas -> Exportar datos. Para su fuente de datos, use "SQL Server Native Client" y apúntelo a su base de datos SentryOne (o donde sea que tenga su copia de los datos almacenados). Para su destino, querrá seleccionar "Destino de archivo plano". Busque una ubicación, asigne un nombre al archivo y guárdelo como CSV.
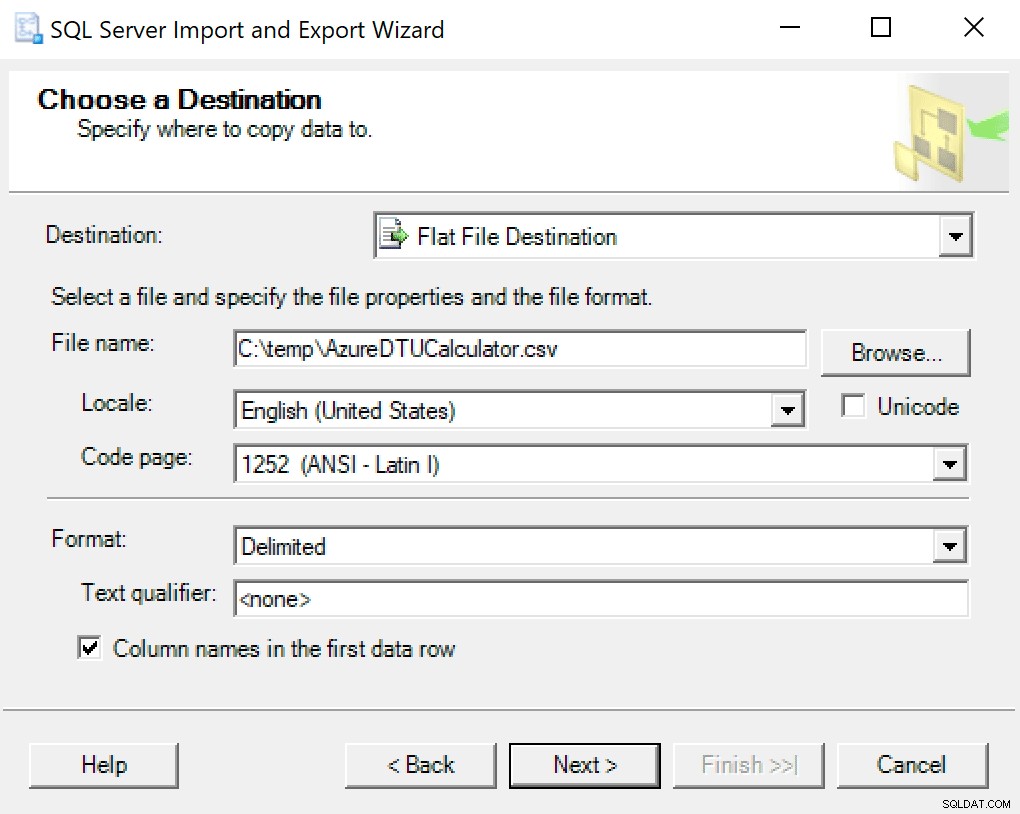
Tenga cuidado de no tocar la página de códigos; algunos pueden devolver errores. Sé que 1252 funciona bien. El resto de valores se dejan por defecto.
En la siguiente pantalla, seleccione la opción Escribir una consulta para especificar los datos a transferir .
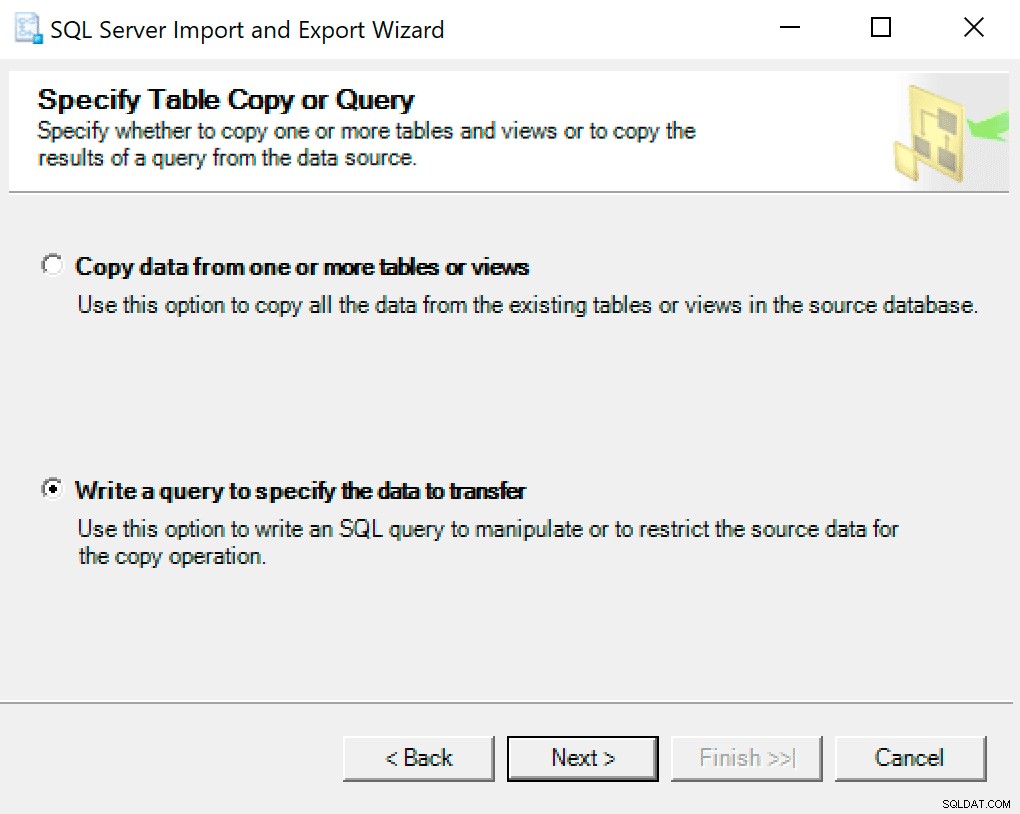
En la siguiente ventana, copie la llamada al procedimiento con sus parámetros establecidos. Presiona siguiente.
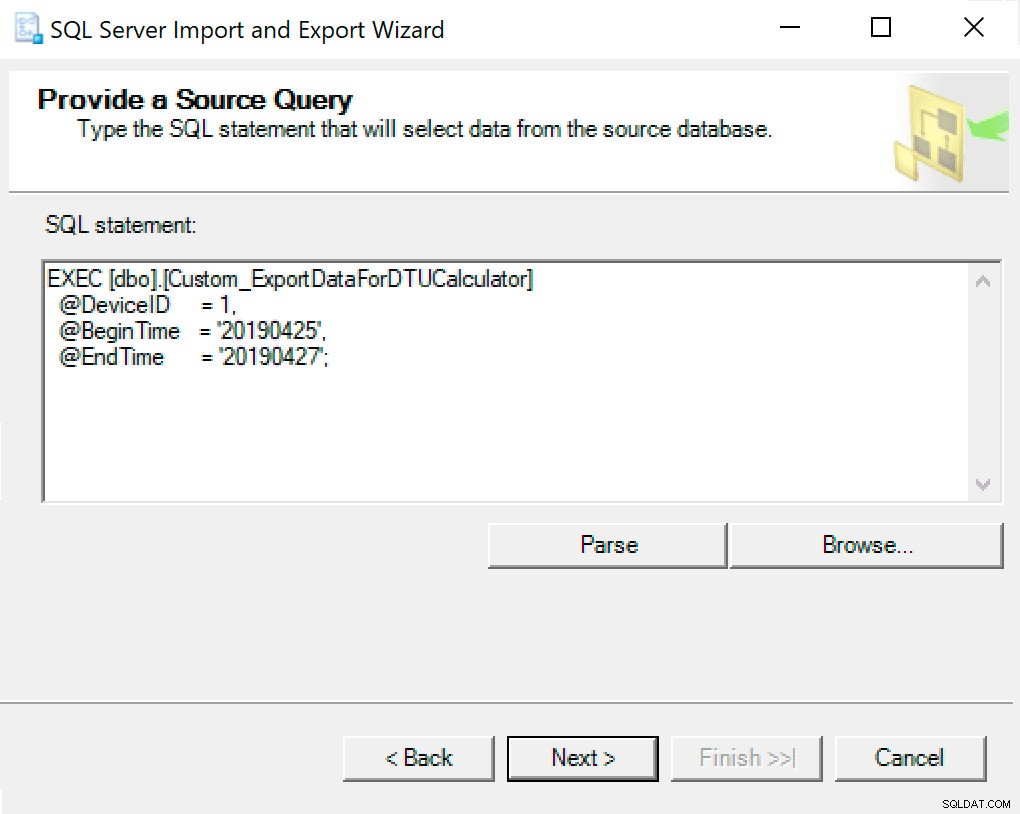
Cuando llega a Configurar destino de archivo sin formato, dejo las opciones como predeterminadas. Aquí hay una captura de pantalla en caso de que la tuya sea diferente:
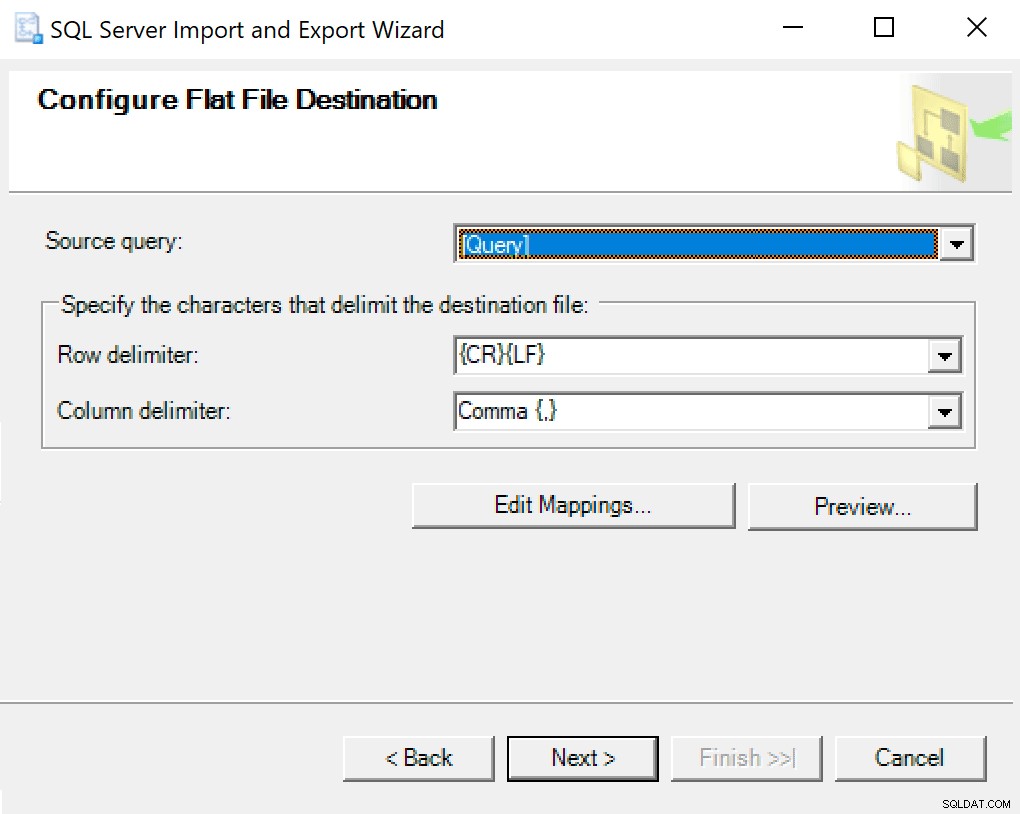
Presiona siguiente y ejecuta inmediatamente. Se creará un archivo que utilizará en el último paso.
NOTA :podría crear un paquete SSIS para usar para esto y luego pasar los valores de sus parámetros al paquete SSIS si va a hacer esto mucho. Esto le evitaría tener que pasar por el asistente cada vez.
Navegue a la ubicación donde guardó el archivo y verifique que esté allí. Cuando lo abras, debería verse así:
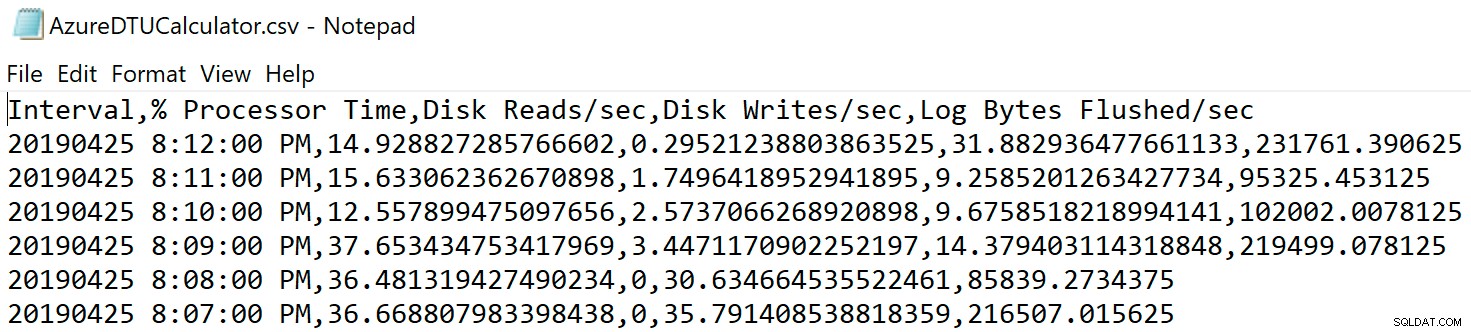
Abra el sitio web de la calculadora DTU y desplácese hacia abajo hasta la parte que dice "Cargar el archivo CSV y calcular". Ingrese la cantidad de núcleos que tiene el servidor, cargue el archivo CSV y haga clic en Calcular. Obtendrá un conjunto de resultados como este (haga clic en cualquier imagen para hacer zoom):
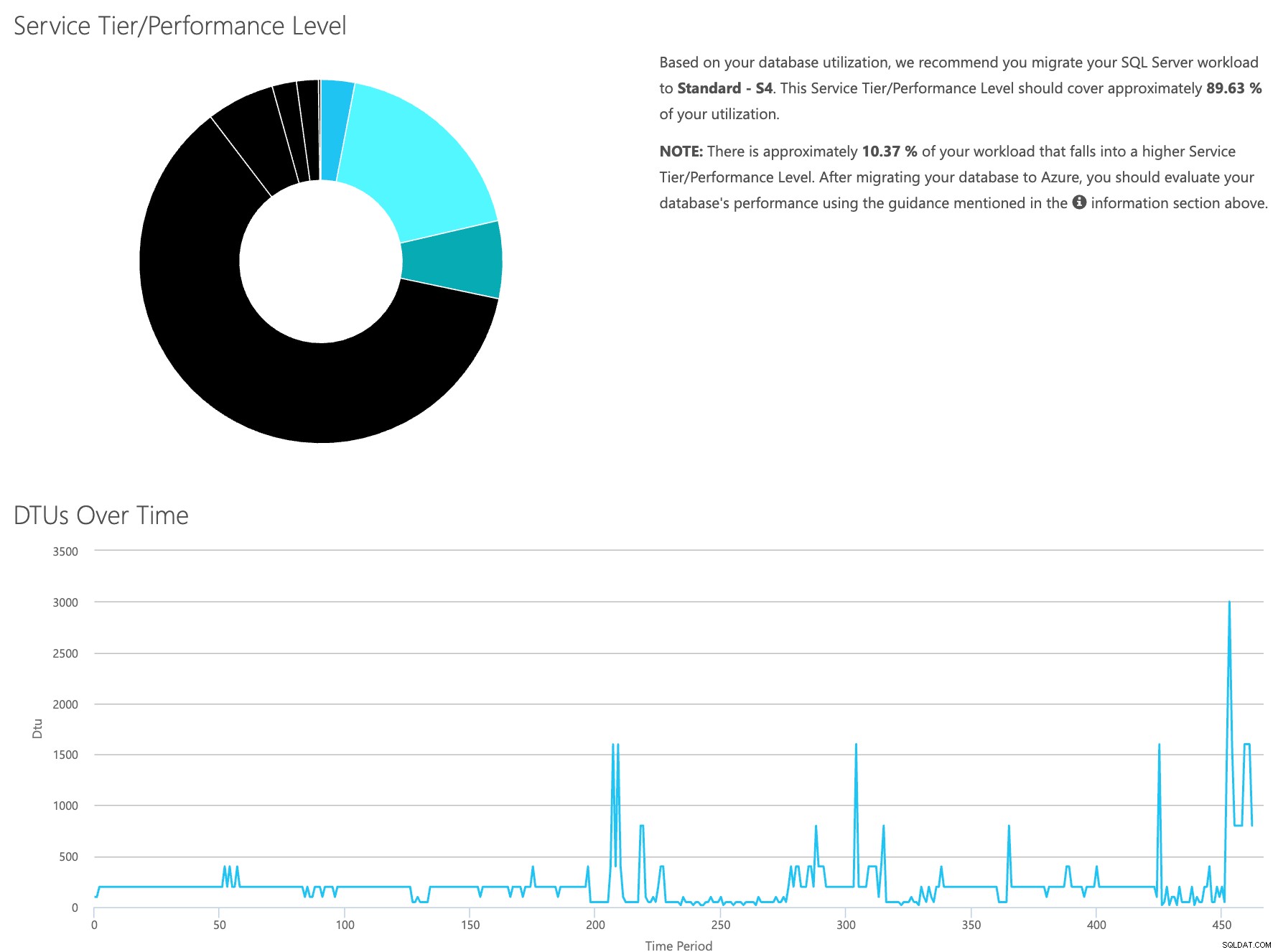
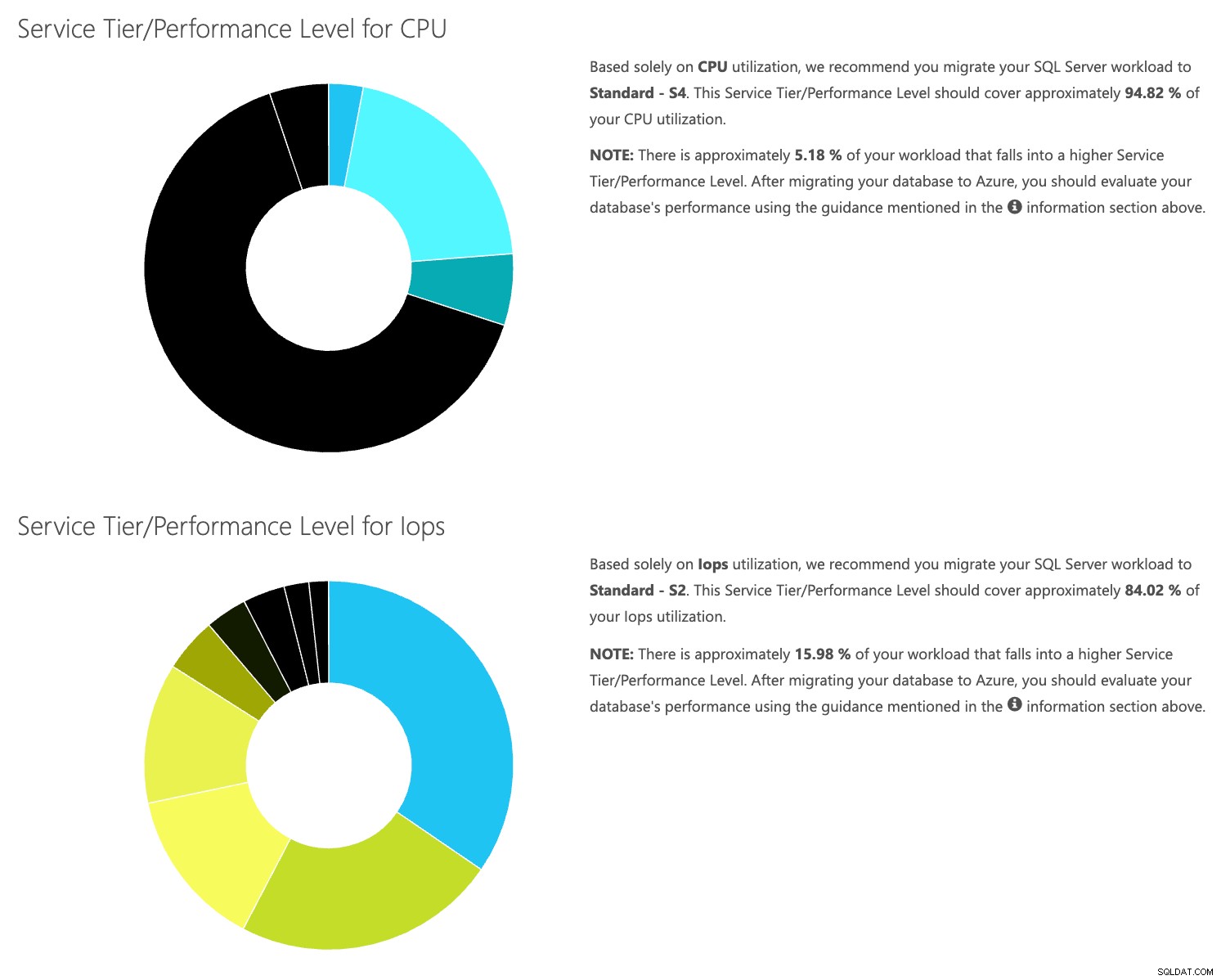
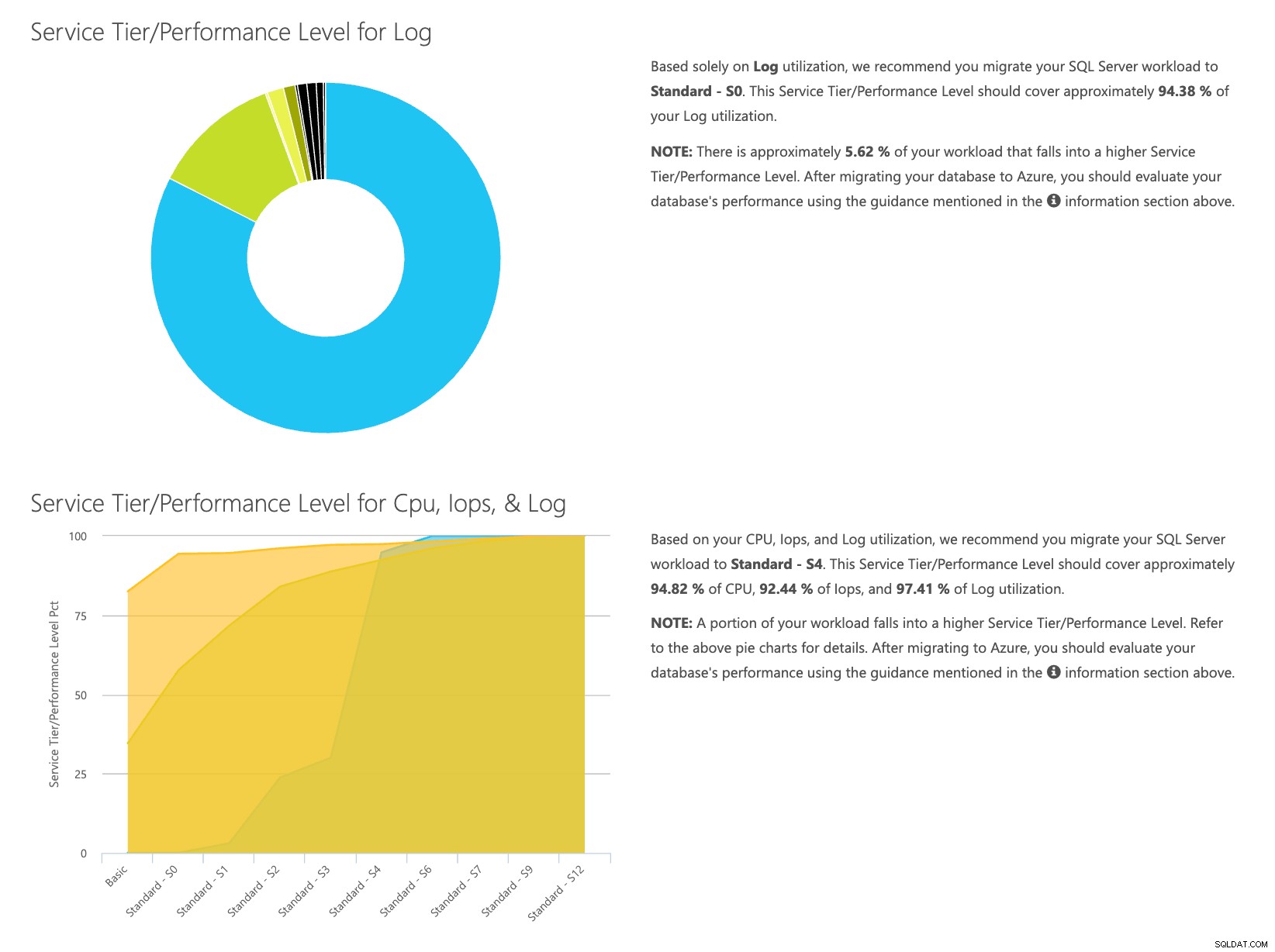
Dado que los datos se almacenan por separado, puede analizar las cargas de trabajo en diferentes momentos, y puede hacerlo sin tener que ejecutar\programar manualmente la utilidad de comandos\secuencia de comandos powershell para cualquier servidor que ya esté usando SentryOne para monitorear.
Para resumir brevemente los pasos, esto es lo que debe hacerse:
- Habilite el contador [Base de datos:registro de bytes vaciados/seg] y verifique que se estén recopilando los datos
- Copie los datos de las tablas de SentryOne en su propia tabla (y programe eso cuando corresponda).
- Exportar los datos de la nueva tabla en el formato correcto para la calculadora de DTU
- Subir el CSV a la calculadora de DTU
Para cualquier servidor/instancia que esté considerando migrar a la nube y que actualmente esté monitoreando con SQL Sentry, esta es una forma relativamente sencilla de estimar qué tipo de nivel de servicio necesitará y cuánto costará. Sin embargo, aún necesitará monitorearlo una vez que esté allí; para eso, consulte SentryOne DB Sentry.
Sobre el autor
 Dustin Dorsey es actualmente el ingeniero de gestión de bases de datos de LifePoint Health, en el que dirige un equipo responsable de la gestión y la ingeniería de soluciones en tecnologías de base de datos para 90 hospitales. Ha estado trabajando con y dando soporte a SQL Server predominantemente en el cuidado de la salud desde 2008 en una capacidad de administración, arquitectura, desarrollo y BI. Le apasiona encontrar formas de resolver los problemas que afectan al DBA todos los días y le encanta compartir esto con los demás. Se le puede encontrar hablando en eventos de la comunidad de SQL, así como blogueando en DustinDorsey.com.
Dustin Dorsey es actualmente el ingeniero de gestión de bases de datos de LifePoint Health, en el que dirige un equipo responsable de la gestión y la ingeniería de soluciones en tecnologías de base de datos para 90 hospitales. Ha estado trabajando con y dando soporte a SQL Server predominantemente en el cuidado de la salud desde 2008 en una capacidad de administración, arquitectura, desarrollo y BI. Le apasiona encontrar formas de resolver los problemas que afectan al DBA todos los días y le encanta compartir esto con los demás. Se le puede encontrar hablando en eventos de la comunidad de SQL, así como blogueando en DustinDorsey.com.