Introducción
En SQL Server 2012, la agregación agrupada (vectorial) podía usar la ejecución en modo por lotes en paralelo, pero solo para la agregación parcial (por subproceso). El agregado global asociado siempre se ejecutó en modo de fila, después de un Flujos de partición intercambio.
SQL Server 2014 agregó la capacidad de realizar una agregación agrupada en modo por lotes en paralelo dentro de un solo hash Match Aggregate operador. Esto eliminó el procesamiento de modo de fila innecesario y eliminó la necesidad de un intercambio.
SQL Server 2016 introdujo el procesamiento en modo por lotes en serie y empuje hacia abajo agregado . Cuando la inserción es exitosa, la agregación se realiza dentro del Escaneo de almacén de columnas operador mismo, posiblemente operando directamente en datos comprimidos y aprovechando las instrucciones de la CPU SIMD.
Las posibles mejoras de rendimiento con la reducción agregada pueden ser muy sustanciales. La documentación enumera algunas de las condiciones requeridas para lograr la inserción, pero hay casos en los que la falta de "filas agregadas localmente" no se puede explicar completamente solo con esos detalles.
Este artículo cubre factores adicionales que afectan el pushdown agregado para GROUP BY solo consultas . Empuje de agregado escalar (agregación sin GROUP BY cláusula), filtro pushdown y expresión pushdown pueden tratarse en una publicación futura.
Almacenamiento de almacén de columnas
Lo primero que hay que decir es que la inserción agregada solo se aplica a los datos comprimidos, por lo que las filas en un almacén delta no son elegibles. Más allá de eso, pushdown puede depender del tipo de compresión utilizada. Para entender esto, primero es necesario revisar cómo funciona el almacenamiento de almacén de columnas a un alto nivel:
Un grupo de filas comprimido contiene un segmento de columna para cada columna. Los valores de columna sin procesar están codificados en un entero de 4 u 8 bytes usando valor o diccionario codificación.
Codificación de valores puede reducir la cantidad de bits necesarios para el almacenamiento mediante la traducción de valores sin procesar mediante un modificador de magnitud y compensación de base. Por ejemplo, los valores {1100, 1200, 1300} se pueden almacenar como (0, 1, 2) escalando primero por un factor de 0,01 para dar {11, 12, 13}, luego rebasando en 11 para dar {0, 1, 2}.
Codificación de diccionario se utiliza cuando hay valores duplicados. Se puede utilizar con datos no numéricos. Cada valor único se almacena en un diccionario y se le asigna una identificación de número entero. Los datos del segmento luego hacen referencia a los números de identificación en el diccionario en lugar de los valores originales.
Después de la codificación, los datos del segmento se pueden comprimir aún más mediante la codificación de longitud de ejecución (RLE) y el empaquetamiento de bits:
RLE reemplaza los elementos repetidos con los datos y el número de repeticiones, por ejemplo, {1, 1, 1, 1, 1, 2, 2, 2} podría reemplazarse con {5×1, 3×2}. El ahorro de espacio RLE aumenta con la longitud de las ejecuciones repetidas. Las tiradas cortas pueden ser contraproducentes.
Empaquetado de bits almacena la forma binaria de los datos en una ventana común lo más estrecha posible. Por ejemplo, los números {7, 9, 15} se almacenan en números enteros binarios (de un solo byte para el espacio) como {00000111, 00001001, 00001111}. Al empaquetar estos bits en una ventana fija de cuatro bits se obtiene el flujo {011110011111}. Saber que hay un tamaño de ventana fijo significa que no hay necesidad de un delimitador.
La codificación y la compresión son pasos separados, por lo que RLE y el empaquetamiento de bits se aplican al resultado de la codificación de valores o la codificación de diccionario de los datos sin procesar. Además, los datos dentro del mismo segmento de columna pueden tener una mezcla de RLE y compresión de paquetes de bits. Los datos comprimidos con RLE se denominan puros. y los datos comprimidos empaquetados en bits se denominan impuros. . Un segmento de columna puede contener datos puros e impuros.
El ahorro de espacio que se puede lograr mediante la codificación y la compresión puede depender del pedido. Todos los segmentos de columna dentro de un grupo de filas deben ordenarse implícitamente de la misma manera para que SQL Server pueda reconstruir de manera eficiente filas completas a partir de los segmentos de columna. Sabiendo que la fila 123 está almacenada en la misma posición (123) en cada segmento de columna, significa que no es necesario almacenar el número de fila.
Una desventaja de este arreglo es que un orden de clasificación común debe elegirse para todos los segmentos de columna en un grupo de filas. Un orden particular puede adaptarse muy bien a una columna, pero perder oportunidades significativas en otras columnas. Este es el caso más claro con la compresión RLE. SQL Server utiliza la tecnología Vertipaq para determinar una buena forma de clasificar las columnas en cada grupo de filas para obtener un buen resultado general de compresión.
SQL Server actualmente solo usa RLE dentro de un segmento de columna cuando hay un mínimo de 64 valores repetidos contiguos. Los valores restantes en el segmento están empaquetados en bits. Como se indicó, si los valores repetidos aparecen como contiguos en un segmento de columna depende del orden elegido para el grupo de filas.
SQL Server admite SIMD especializados desempaquetado de bits para anchos de bits de 1 a 10 inclusive, 12 y 21 bits. SQL Server también puede usar tamaños enteros estándar, p. 16, 32 y 64 bits con empaquetado de bits. Estos números se eligieron porque encajan muy bien en una unidad de 64 bits. Por ejemplo, una unidad puede contener tres subunidades de 21 bits o 5 subunidades de 12 bits. SQL Server no cruce un límite de 64 bits al empaquetar bits.
SIMD utiliza registros de 256 bits cuando el procesador admite instrucciones AVX2 y registros de 128 bits cuando las instrucciones SSE4.2 están disponibles. De lo contrario, se puede utilizar el desempaquetado sin SIMD.
Condiciones pushdown agregadas agrupadas
La mayoría de los planes con un hash Match Aggregate operador directamente encima de un Columnstore Scan el operador calificará potencialmente para la reducción agregada agrupada, sujeto a las condiciones generales indicadas en la documentación.
En ocasiones, también se pueden agregar filtros y expresiones adicionales sin evitar la inserción agregada agrupada. La regla general es que el filtro o la expresión también debe ser capaz de empujar hacia abajo (aunque las expresiones compatibles aún pueden aparecer en un Compute Scalar separado ). Como se señaló en la introducción, estos aspectos pueden tratarse en detalle en artículos separados.
Actualmente no hay nada en los planes de ejecución que indique si un agregado en particular se consideró generalmente compatible con pushdown agregado agrupado o no. Aún así, cuando el plan generalmente califica para pushdown agregado agrupado, las rutas de código pushdown (rápido) y no pushdown (lento) están disponibles.
Cada lote de salida de escaneo (de hasta 900 filas) toma una decisión de tiempo de ejecución entre las rutas de código rápidas y lentas. Esta flexibilidad permite que tantos lotes como sea posible se beneficien del pushdown. En el peor de los casos, ningún lote utilizará la ruta rápida en tiempo de ejecución, a pesar de un plan "generalmente compatible".
El plan de ejecución muestra el resultado del procesamiento pushdown de ruta rápida como ‘filas agregadas localmente’ sin salida de fila correspondiente del escaneo. Los lotes de ruta lenta aparecen como filas de salida del escaneo del almacén de columnas como de costumbre, con la agregación realizada por un operador independiente en lugar del escaneo.
Una única combinación de escaneo y agregado agrupado puede enviar algunos lotes por la ruta rápida y otros por la ruta lenta, por lo que es perfectamente posible ver algunas filas, pero no todas, agregadas localmente. Cuando la inserción de agregados agrupados es exitosa, cada lote de salida del análisis contiene claves de agrupación y un agregado parcial que representa las filas que contribuyen.
Verificaciones detalladas
Hay una serie de comprobaciones en tiempo de ejecución para determinar si se puede utilizar el procesamiento pushdown. Entre los controles levemente documentados se encuentran:
- No debe haber posibilidad de desbordamiento agregado .
- Cualquier impuro (paquete de bits) claves de agrupación debe tener un ancho máximo de 10 bits . Las claves de agrupación puras (codificación RLE) se tratan como si tuvieran un ancho impuro de cero, por lo que generalmente presentan pocos obstáculos.
- Se debe seguir considerando que el procesamiento pushdown vale la pena , utilizando una "medida de beneficio" actualizada al final de cada lote de salida.
La posibilidad de desbordamiento agregado se evalúa de forma conservadora para cada lote según el tipo de agregado, el tipo de datos de resultado, los valores de agregación parciales actuales y la información sobre los datos de entrada. Por ejemplo, SQL Server conoce los valores mínimos y máximos de los metadatos del segmento tal como se exponen en el sys.column_store_segments del DMV. . Cuando exista riesgo de desbordamiento, el lote utilizará un proceso de ruta lenta. Esto es principalmente un riesgo para el SUM agregado.
La restricción del ancho de clave de agrupación impura vale la pena enfatizar. Solo se aplica a las columnas del GROUP BY cláusula que se utilizan realmente en el plan de ejecución como base para la agrupación. Estos conjuntos no siempre son exactamente iguales porque el optimizador tiene libertad para eliminar columnas de agrupación redundantes o para reescribir agregados, siempre que se garantice que los resultados finales de la consulta coincidan con la especificación de la consulta original. Donde hay una disparidad, lo que importa son las columnas de agrupación que se muestran en el plan de ejecución.
La mayor dificultad es saber si alguna de las columnas de agrupación se almacena utilizando el empaquetamiento de bits y, de ser así, qué ancho se utilizó. También sería útil saber cuántos valores se codificaron usando RLE. Esta información podría estar en column_store_segments DMV, pero ese no es el caso hoy. Hasta donde yo sé, no hay una forma documentada en este momento de obtener información de RLE y empaquetado de bits de los metadatos. Eso nos deja buscando alternativas indocumentadas.
Búsqueda de RLE e información de empaquetado de bits
El DBCC CSINDEX no documentado puede darnos la información que necesitamos. El indicador de seguimiento 3604 debe estar activado para que este comando genere un resultado en la pestaña de mensajes de SSMS. Dada la información sobre el segmento de columna que nos interesa, este comando devuelve:
- Atributos de segmento (similar a
column_store_segments) - Información RLE
- Marcadores en datos RLE
- Información del paquete de bits
Al no estar documentado, hay algunas peculiaridades (como tener que agregar uno a los ID de columna para el almacén de columnas agrupado, pero no para el almacén de columnas no agrupado), e incluso un par de errores menores. No debe usarlo en nada excepto en un sistema de prueba personal. Con suerte, algún día se proporcionará un método compatible para acceder a estos datos.
Ejemplos
La mejor manera de mostrar DBCC CSINDEX y demostrar los puntos tratados hasta ahora en este texto es trabajar con algunos ejemplos. Los scripts que siguen asumen que hay una tabla llamada dbo.Numbers en la base de datos actual que contiene números enteros desde 1 hasta al menos 16.384. Aquí hay un script para crear mi versión estándar de esta tabla con diez millones de enteros:
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
Todos los ejemplos usan la misma tabla de prueba básica:La primera columna c1 contiene un número único para cada fila. La segunda columna c2 se rellena con una cantidad de duplicados para cada uno de una pequeña cantidad de valores distintos.
Se crea un índice de almacén de columnas agrupado después del llenado de datos para que todos los datos de prueba terminen en un único grupo de filas comprimido (sin almacenamiento delta). Está construido reemplazando un índice agrupado de árbol b en la columna c2 para alentar al algoritmo VertiPaq a considerar la utilidad de ordenar en esa columna desde el principio. Esta es la configuración básica de la prueba:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
Las dos variables son para el número de valores distintos para insertar en la columna c2 y el número de duplicados para cada uno de esos valores.
La consulta de prueba es un COUNT_BIG agrupado muy simple agregación usando la columna c2 como clave:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
La información del índice del almacén de columnas se mostrará usando DBCC CSINDEX después de cada ejecución de consulta de prueba:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); Las pruebas se realizaron en la última versión publicada de SQL Server disponible en el momento de escribir este artículo:Microsoft SQL Server 2017 RTM-CU13-OD compilación 14.0.3049 Developer Edition (64 bits) en Windows 10 Pro. Las cosas también deberían funcionar bien en la última versión de SQL Server 2016.
Prueba 1:Pushdown, claves impuras de 9 bits
Esta prueba utiliza la secuencia de comandos de población de datos de prueba exactamente como se escribió anteriormente, produciendo una tabla con 32,256 filas. Columna c1 contiene números del 1 al 32,256.
Columna c2 contiene 512 valores distintos de 0 a 511 inclusive. Cada valor en c2 se duplica 63 veces , pero no aparecen como bloques contiguos cuando se ven en c1 pedido; recorren 63 veces los valores de 0 a 511.
Dada la discusión anterior, esperamos que SQL Server almacene el c2 datos de columna usando:
- Codificación de diccionario ya que hay un número significativo de valores duplicados.
- Sin RLE . El número de duplicados (63) por valor no alcanza el umbral de 64 requerido para RLE.
- Empaquetadura de brocas tamaño 9 . Las 512 entradas distintas del diccionario encajarán exactamente en 9 bits (2^9 =512). Cada unidad de 64 bits contendrá hasta siete subunidades de 9 bits.
Todo esto se confirma como correcto usando DBCC CSINDEX consulta:
Los atributos del segmento la sección de la salida muestra codificación de diccionario (tipo 2; los valores para encodingType son como se documentan en sys.column_store_segments ).
Versión =1 tipo de codificación =2 hasNulls =0
BaseId =-1 Magnitud =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 Número de filas =32256
La sección RLE muestra ningún dato RLE , solo un puntero a la región llena de bits y una entrada vacía para el valor cero:
Encabezado RLE:
Tipo de lob =3 Recuento de matriz RLE (en términos de unidades nativas) =2
Tamaño de entrada de matriz RLE =8
Datos RLE:
Índice =0 Matriz Bitpack Índice =0 Recuento =32256
Índice =1 Valor =0 Recuento =0
El encabezado de datos de Bitpack la sección muestra bitpack tamaño 9 y 4608 unidades bitpack usadas:
Encabezado de datos de paquete de bits:
Bitpack Entry Size =9 Bitpack Unit Count =4608 Bitpack MinId =3
Bitpack DataSize =36864
Los datos de Bitpack La sección muestra los valores almacenados en las dos primeras unidades de bitpack según lo solicitado por los dos últimos parámetros al DBCC CSINDEX dominio. Recuerde que cada unidad de 64 bits puede contener 7 subunidades (numeradas del 0 al 6) de 9 bits cada una (7 x 9 =63 bits). Las 4608 unidades en total contienen 4608 * 7 =32 256 filas:
Unidad 0 Subunidad 0 =383
Unidad 0 Subunidad 1 =255
Unidad 0 Subunidad 2 =127
Unidad 0 Subunidad 3 =510
Unidad 0 Subunidad 4 =381
Unidad 0 SubUnidad 5 =253
Unidad 0 SubUnidad 6 =125
Unidad 1 Subunidad 0 =508
Unidad 1 Subunidad 1 =379
Unidad 1 Subunidad 2 =251
Unidad 1 Subunidad 3 =123
Unidad 1 Subunidad 4 =506
Unidad 1 SubUnidad 5 =377
Unidad 1 SubUnidad 6 =249
Dado que las claves de agrupación utilizan empaquetado de bits con un tamaño menor o igual a 10 , esperamos empuje hacia abajo agregado agrupado para trabajar aquí. De hecho, el plan de ejecución muestra que todas las filas se agregaron localmente en el Exploración del índice de almacén de columnas operador:

El xml del plan contiene ActualLocallyAggregatedRows="32256" en la información de tiempo de ejecución para el escaneo de índice.
Prueba 2:Sin pushdown, claves impuras de 12 bits
Esta prueba cambia los @values parámetro a 1025, manteniendo @dupes en 63. Esto da una tabla de 64 575 filas, con 1025 valores distintos en la columna c2 va de 0 a 1024 inclusive. Cada valor en c2 se duplica 63 veces .
SQL Server almacena el c2 datos de columna usando:
- Codificación de diccionario ya que hay un número significativo de valores duplicados.
- Sin RLE . El número de duplicados (63) por valor no alcanza el umbral de 64 requerido para RLE.
- Repleto de bits con tamaño 12 . Las 1025 entradas distintas del diccionario no caben del todo en 10 bits (2^10 =1024). Cabrían en 11 bits, pero SQL Server no admite ese tamaño de empaquetado de bits como se mencionó anteriormente. El siguiente tamaño más pequeño es de 12 bits. Usando unidades de 64 bits con bordes rígidos para el empaquetado de bits, no caben más subunidades de 11 bits en 64 bits que las subunidades de 12 bits. De cualquier manera, caben 5 subunidades en una unidad de 64 bits.
El DBCC CSINDEX la salida confirma el análisis anterior:
Versión =1 tipo de codificación =2 hasNulls =0
BaseId =-1 Magnitud =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 Número de filas =64575
Encabezado RLE:
Tipo de lob =3 Recuento de matriz RLE (en términos de unidades nativas) =2
Tamaño de entrada de matriz RLE =8
Datos RLE:
Índice =0 Matriz Bitpack Índice =0 Recuento =64575
Índice =1 Valor =0 Recuento =0
Encabezado de datos de paquete de bits:
Bitpack Entry Size =12 Bitpack Unit Count =12915 Bitpack MinId =3
Bitpack DataSize =103320
Bitpack Data:
Unidad 0 Subunidad 0 =767
Unidad 0 Subunidad 1 =510
Unidad 0 Subunidad 2 =254
Unidad 0 Subunidad 3 =1021
Unidad 0 Subunidad 4 =765
Unidad 1 Subunidad 0 =507
Unidad 1 Subunidad 1 =250
Unidad 1 Subunidad 2 =1019
Unidad 1 Subunidad 3 =761
Unidad 1 Subunidad 4 =505
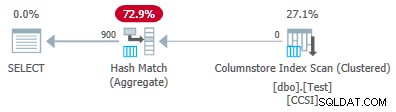
Desde el impuro las claves de agrupación tienen un tamaño superior a 10 , esperamos empuje hacia abajo agregado agrupado no trabajar aquí. Esto lo confirma el plan de ejecución que muestra cero filas agregadas localmente en el Exploración del índice de almacén de columnas operador:
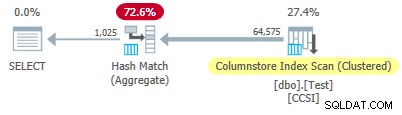
Las 64 575 filas son emitidas (en lotes) por el Escaneo de índice de almacén de columnas y agregados en modo por lotes por el hash Match Aggregate operador. ActualLocallyAggregatedRows falta el atributo de la información de tiempo de ejecución del plan xml para el escaneo de índice.
Prueba 3:Pushdown, Pure Keys
Esta prueba cambia el @dupes parámetro de 63 a 64 para permitir RLE. Los @values El parámetro se cambia a 16,384 (el máximo para el número total de filas que todavía caben en un solo grupo de filas). El número exacto elegido para @values no es importante:el punto es generar 64 duplicados de cada valor único para que se pueda usar RLE.
SQL Server almacena el c2 datos de columna usando:
- Codificación de diccionario debido a los valores duplicados.
- RLE. Se utiliza para cada valor distinto, ya que cada uno alcanza el umbral de 64.
- Sin datos empaquetados en bits . Si hubiera alguno, usaría el tamaño 16. El tamaño 12 no es lo suficientemente grande (2^12 =4096 valores distintos) y el tamaño 21 sería un desperdicio. Los 16 384 valores distintos caben en 14 bits pero, como antes, no pueden caber más en una unidad de 64 bits que las subunidades de 16 bits.
El DBCC CSINDEX la salida confirma lo anterior (solo se muestran algunas entradas RLE y marcadores por razones de espacio):
Versión =1 tipo de codificación =2 hasNulls =0
BaseId =-1 Magnitud =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 Número de filas =1048576
Encabezado RLE:
Tipo de lob =3 Recuento de matriz RLE (en términos de unidades nativas) =16385
Tamaño de entrada de matriz RLE =8
Datos RLE:
Índice =0 Valor =3 Conteo =64
Índice =1 Valor =1538 Conteo =64
Índice =2 Valor =3072 Conteo =64
Índice =3 Valor =4608 Conteo =64
Índice =4 Valor =6142 Recuento =64
…
Índice =16381 Valor =8954 Recuento =64
Índice =16382 Valor =10489 Recuento =64
Índice =16383 Valor =12025 Recuento =64
Índice =16384 Valor =0 Recuento =0
Encabezado de marcador:
Cantidad de marcadores =65 Distancia de marcadores =16384 Tamaño de marcadores =520
Datos del marcador:
Posición =0 Índice =64
Posición =512 Índice =16448
Posición =1024 Índice =32832
…
Posición =31744 Índice =1015872
Posición =32256 Índice =1032256
Posición =32768 Índice =1048577
Encabezado de datos de paquete de bits:
Bitpack Entry Size =16 Bitpack Unit Count =0 Bitpack MinId =3
Bitpack DataSize =0
Dado que las claves de agrupación son puras (se utiliza RLE), empuje hacia abajo agregado agrupado se espera aquí. El plan de ejecución lo confirma mostrando todas las filas agregadas localmente en el Exploración del índice de almacén de columnas operador:
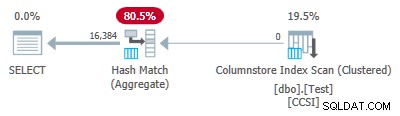
El xml del plan contiene ActualLocallyAggregatedRows="1048576" en la información de tiempo de ejecución para el escaneo de índice.
Prueba 4:claves impuras de 10 bits
Esta prueba establece @values al 1024 y @dupes a 63, dando una tabla de 64.512 filas, con 1.024 valores distintos en la columna c2 con valores de 0 a 1.023 inclusive. Cada valor en c2 se duplica 63 veces .
Lo más importante , el índice agrupado de árbol b ahora se crea en la columna c1 en lugar de la columna c2 . El almacén de columnas agrupado sigue reemplazando el índice agrupado de árbol b. Esta es la parte modificada del script:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQL Server almacena el c2 datos de columna usando:
- Codificación de diccionario debido a los duplicados.
- Sin RLE . El número de duplicados (63) por valor no alcanza el umbral de 64 requerido para RLE.
- Embalaje de bits con tamaño 10 . Las 1024 entradas distintas del diccionario encajan exactamente en 10 bits (2^10 =1024). Se pueden almacenar seis subunidades de 10 bits cada una en cada unidad de 64 bits.
El DBCC CSINDEX la salida es:
Versión =1 tipo de codificación =2 hasNulls =0
BaseId =-1 Magnitud =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 Número de filas =64512
Encabezado RLE:
Tipo de lob =3 Recuento de matriz RLE (en términos de unidades nativas) =2
Tamaño de entrada de matriz RLE =8
Datos RLE:
Índice =0 Matriz Bitpack Índice =0 Recuento =64512
Índice =1 Valor =0 Recuento =0
Encabezado de datos de paquete de bits:
Bitpack Entry Size =10 Bitpack Unit Count =10752 Bitpack MinId =3
Bitpack DataSize =86016
Bitpack Data:
Unidad 0 Subunidad 0 =766
Unidad 0 Subunidad 1 =509
Unidad 0 Subunidad 2 =254
Unidad 0 Subunidad 3 =1020
Unidad 0 Subunidad 4 =764
Unidad 0 Subunidad 5 =506
Unidad 1 Subunidad 0 =250
Unidad 1 Subunidad 1 =1018
Unidad 1 Subunidad 2 =760
Unidad 1 Subunidad 3 =504
Unidad 1 Subunidad 4 =247
Unidad 1 Subunidad 5 =1014
Desde el impuro las claves de agrupación usan un tamaño inferior o igual a 10, esperaríamos empuje hacia abajo agregado agrupado para trabajar aquí. Pero eso no es lo que sucede . El plan de ejecución muestra que 54 612 de las 64 512 filas se agregaron en el hash Match Aggregate operador:
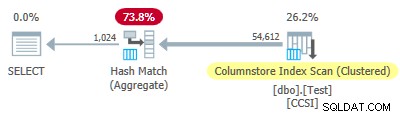
El xml del plan contiene ActualLocallyAggregatedRows="9900" en la información de tiempo de ejecución para la exploración de índice. Esto significa empuje hacia abajo agregado agrupado se usó para 9900 filas, ¡pero no se usó para las otras 54 612!
El mecanismo de retroalimentación
SQL Server comenzó usando empuje hacia abajo agregado agrupado para esta ejecución porque las claves de agrupación impuras cumplían con el criterio de 10 bits o menos. Esto duró un total de 11 lotes (de 900 filas cada uno =9900 filas en total). En ese punto, un mecanismo de retroalimentación que mide la efectividad de desplazamiento agregado agrupado decidió que no estaba funcionando y lo apagó . Los lotes restantes se procesaron con pushdown deshabilitado.
La retroalimentación esencialmente compara la cantidad de filas agregadas con la cantidad de grupos producidos. Comienza con un valor de 100 y se ajusta al final de cada lote de salida pushdown. Si el valor cae a 10 o menos, la inserción se desactiva para la operación de agrupación actual.
La “medida de beneficio pushdown” se reduce más o menos dependiendo de qué tan mal vaya el esfuerzo de agregación pushdown. Si hay menos de 8 filas por clave de agrupación en promedio en el lote de salida, el valor de beneficio actual se reduce en un 22 %. Si hay más de 8 pero menos de 16, la métrica se reduce en un 11 %.
Por otro lado, si las cosas mejoran, y posteriormente se encuentran 16 o más filas por clave de agrupación para un lote de salida, la métrica se restablece a 100 y continúa ajustándose a medida que el escaneo produce lotes agregados parciales.
Los datos en esta prueba se presentaron en un orden particularmente poco útil para la inserción debido al índice agrupado de árbol b original en la columna c1 . Cuando se presenta de esta manera, los valores en la columna c2 comienzan en 0 e incrementan en 1 hasta llegar a 1023, luego comienzan el ciclo nuevamente. Los 1023 valores distintos son más que suficientes para garantizar que cada lote de salida de 900 filas contenga solo una fila parcialmente agregada para cada clave. Este no es un estado feliz.
Si hubiera habido 64 duplicados por valor en lugar de 63, SQL Server habría considerado ordenar por c2 mientras creaba el índice de almacén de columnas, y así producía la compresión RLE. Tal como están las cosas, la penalización del 22% se activa después de cada lote. Comenzando en 100 y utilizando la misma aritmética de enteros redondeados, la secuencia de valores métricos es:
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
El undécimo lote reduce la métrica a 10 o menos y se desactiva la inserción. Los 11 lotes de 900 filas representan las 9900 filas agregadas localmente que se muestran en el plan de ejecución.
Variación con 900 valores distintos
El mismo comportamiento se puede ver en la prueba 4 con tan solo 901 valores distintos, suponiendo que las filas se presenten en el mismo orden poco útil.
Cambiando los @values parámetro a 900 mientras mantiene todo lo demás igual tiene un efecto dramático en el plan de ejecución:
¡Ahora los 900 grupos se agregan en el escaneo! Las propiedades del plan xml muestran ActualLocallyAggregatedRows="56700" . Esto se debe a que el pushdown de agregados agrupados mantiene 900 claves de agrupación y agregados parciales en un solo lote. It never encounters a new key value not in the batch, so there is no reason to start a fresh output batch.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Note: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.