Introducción
Lograr registro mínimo con INSERT...SELECT puede ser un negocio complicado. Las consideraciones enumeradas en la Guía de rendimiento de carga de datos siguen siendo bastante completas, aunque también es necesario leer SQL Server 2016, Registro mínimo e Impacto del tamaño del lote en las operaciones de carga masiva por Parikshit Savjani del SQL Server Tiger Team para obtener una imagen actualizada de SQL Server 2016 y versiones posteriores, cuando se realiza una carga masiva en tablas de almacén de filas agrupadas. Dicho esto, este artículo se centra únicamente en proporcionar nuevos detalles. sobre registro mínimo al cargar de forma masiva tablas de almacenamiento dinámico tradicionales (no "optimizadas para memoria") usando INSERT...SELECT . Las tablas con un índice agrupado de árbol b se tratan por separado en la segunda parte de esta serie.
Tablas de montón
Al insertar filas usando INSERT...SELECT en un montón sin índices no agrupados, la documentación establece universalmente que dichas inserciones se registrarán mínimamente siempre que un TABLOCK la pista está presente. Esto se refleja en las tablas de resumen incluidas en la Guía de rendimiento de carga de datos y el puesto del Tiger Team. Las filas de resumen de las tablas de montones sin índices son las mismas en ambos documentos (sin cambios para SQL Server 2016):

Un TABLOCK explícito la sugerencia no es la única forma de cumplir con el requisito de bloqueo a nivel de tabla . También podemos establecer el ‘table lock on bulk load’ opción para la tabla de destino usando sp_tableoption o habilitando el indicador de seguimiento documentado 715. (Nota:estas opciones no son suficientes para habilitar el registro mínimo cuando se usa INSERT...SELECT porque INSERT...SELECT no admite bloqueos de actualización masiva).
El “posible concurrente” La columna del resumen solo se aplica a métodos de carga masiva que no sean INSERT...SELECT . La carga simultánea de una tabla de almacenamiento dinámico no es posible con INSERT...SELECT . Como se indica en la Guía de rendimiento de carga de datos , carga masiva con INSERT...SELECT toma una exclusiva X bloqueo sobre la mesa, no la actualización masiva BU bloqueo requerido para cargas masivas simultáneas.
Aparte de todo eso, y suponiendo que no haya otra razón para no esperar un registro mínimo al cargar de forma masiva un montón no indexado con TABLOCK (o equivalente):el inserto todavía podría no estar mínimamente registrado…
Una excepción a la regla
El siguiente script de demostración debe ejecutarse en una instancia de desarrollo en una nueva base de datos de prueba configurado para usar el SIMPLE modelo de recuperación. Carga una cantidad de filas en una tabla heap usando INSERT...SELECT con TABLOCK e informes sobre los registros de transacciones generados:
CREATE TABLE dbo.TestHeap
(
id integer NOT NULL IDENTITY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.TestHeap WITH (TABLOCK)
(c1)
SELECT TOP (897)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_HEAP'
AND FD.AllocUnitName = N'dbo.TestHeap'; El resultado muestra que las 897 filas fueron completamente registradas a pesar de que aparentemente cumple con todas las condiciones para un registro mínimo (solo se muestra una muestra de los registros por razones de espacio):
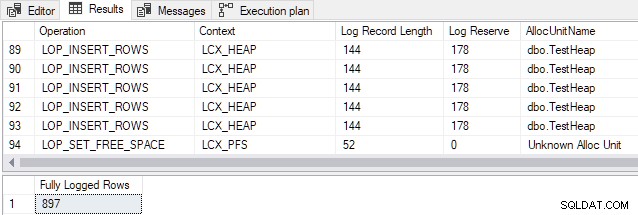
Se ve el mismo resultado si se repite la inserción (es decir, no importa si la tabla del montón está vacía o no). Este resultado contradice la documentación.
El umbral mínimo de registro para montones
El número de filas que uno necesita agregar en un solo INSERT...SELECT declaración para lograr registro mínimo en un montón no indexado con el bloqueo de tablas habilitado depende de un cálculo que realiza SQL Server al estimar el tamaño total de los datos a insertar. Las entradas para este cálculo son:
- La versión de SQL Server.
- El número estimado de filas que conducen al Insertar operador.
- Tamaño de fila de la tabla objetivo.
Para SQL Server 2012 y versiones anteriores , el punto de transición para esta tabla en particular es 898 filas . Cambiando el número en el script de demostración TOP cláusula de 897 a 898 produce el siguiente resultado:
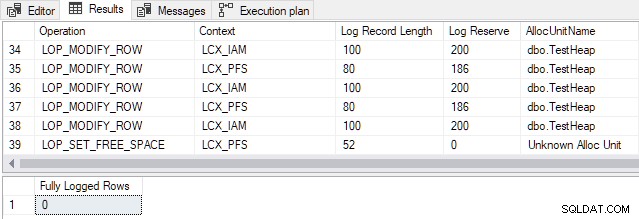
Las entradas del registro de transacciones generadas están relacionadas con la asignación de páginas y el mantenimiento del mapa de asignación de índice (IAM) y Espacio libre de página (PFS) estructuras. Recuerde que registro mínimo significa que SQL Server no registra cada inserción de fila individualmente. En su lugar, solo se registran los cambios en los metadatos y las estructuras de asignación. Cambiar de 897 a 898 filas permite un registro mínimo para esta tabla específica.
Para SQL Server 2014 y versiones posteriores , el punto de transición es 950 filas para esta mesa. Ejecutando INSERT...SELECT con TOP (949) utilizará registro completo – cambiando a TOP (950) producirá registro mínimo .
Los umbrales no depende de la estimación de cardinalidad modelo en uso o el nivel de compatibilidad de la base de datos.
El cálculo del tamaño de los datos
Si SQL Server decide usar carga masiva de conjuntos de filas — y, por lo tanto, si registro mínimo está disponible o no — depende del resultado de una serie de cálculos realizados en un método llamado sqllang!CUpdUtil::FOptimizeInsert , que devuelve verdadero para un registro mínimo, o falso para el registro completo. A continuación se muestra una pila de llamadas de ejemplo:
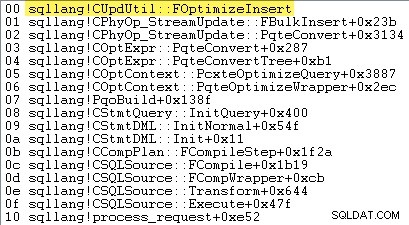
La esencia de la prueba es:
- El inserto debe ser para más de 250 filas .
- El tamaño total de los datos insertados debe calcularse como al menos 8 páginas .
La comprobación de más de 250 filas depende únicamente del número estimado de filas que llegan al inserto de tabla operador. Esto se muestra en el plan de ejecución como ‘Número estimado de filas’ . Ten cuidado con esto. Es fácil producir un plan con un número estimado bajo de filas, por ejemplo, usando una variable en el TOP cláusula sin OPTION (RECOMPILE) . En ese caso, el optimizador calcula 100 filas, lo que no alcanzará el umbral y, por lo tanto, evitará la carga masiva y el registro mínimo.
El cálculo del tamaño total de los datos es más complejo y no coincide el 'Tamaño de fila estimado' fluyendo hacia el inserto de tabla operador. La forma en que se realiza el cálculo es ligeramente diferente en SQL Server 2012 y versiones anteriores en comparación con SQL Server 2014 y versiones posteriores. Aún así, ambos producen un resultado de tamaño de fila que es diferente de lo que se ve en el plan de ejecución.
El cálculo del tamaño de fila
El tamaño total de los datos de inserción se calcula multiplicando el número estimado de filas por el tamaño de fila máximo esperado . El cálculo del tamaño de fila es el punto que difiere entre las versiones de SQL Server.
En SQL Server 2012 y versiones anteriores, el cálculo lo realiza sqllang!OptimizerUtil::ComputeRowLength . Para la tabla de almacenamiento dinámico de prueba (diseñada deliberadamente con columnas simples no nulas de longitud fija usando el FixedVar original formato de almacenamiento de filas) un resumen del cálculo es:
- Inicializar un FixedVar generador de metadatos.
- Obtenga información de tipo y atributo para cada columna en el inserto de tabla flujo de entrada.
- Agregue columnas escritas y atributos a los metadatos.
- Finalice el generador y pídale el tamaño máximo de fila.
- Agregue sobrecarga para el mapa de bits nulo y número de columnas.
- Agregue cuatro bytes para la fila bits de estado y desplazamiento de fila al número de datos de columnas.
Tamaño de fila físico
Se podría esperar que el resultado de este cálculo coincida con el tamaño de la fila física, pero no es así. Por ejemplo, con el control de versiones de filas desactivado para la base de datos:
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.min_record_size_in_bytes,
DDIPS.max_record_size_in_bytes,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.TestHeap', N'U'),
0, -- heap
NULL, -- all partitions
'DETAILED'
) AS DDIPS; …da un tamaño de registro de 60 bytes en cada fila de la tabla de prueba:

Esto es como se describe en Calcular el tamaño de un montón:
- Tamaño total en bytes de todos los de longitud fija columnas =53 bytes:
id integer NOT NULL=4 bytesc1 integer NOT NULL=4 bytespadding char(45) NOT NULL=45 bytes.
- Mapa de bits nulo =3 bytes :<último>
- =2 + int((Num_Cols + 7) / 8)
- =2 + int((3 + 7) / 8)
- =3 bytes.
También coincide con el tamaño de fila estimado que se muestra en el plan de ejecución:

Detalles de cálculo interno
El cálculo interno utilizado para determinar si se utiliza la carga masiva genera un resultado diferente, según la siguiente inserción de flujo información de columna obtenida mediante un depurador. Los números de tipo utilizados coinciden con sys.types :
- Total de longitud fija tamaño de columna =66 bytes :<último>
- Escriba id 173
binary(8)=8 bytes (interno). - Escriba id 56
integer=4 bytes (interno). - Tipo id 104
bit=1 byte (interno). - Escriba id 56
integer=4 bytes (idcolumna). - Escriba id 56
integer=4 bytes (c1columna). - Escriba id 175
char(45)=45 bytes (paddingcolumna).
La diferencia es que el flujo de entrada que alimenta la inserción de tabla el operador contiene tres columnas internas adicionales . Estos se eliminan cuando se genera el plan de presentación. Las columnas adicionales conforman el localizador de inserción de tabla , que incluye el marcador (RID o localizador de filas) como primer componente. Son metadatos para el inserto y no termina siendo agregado a la tabla.
Las columnas adicionales explican la discrepancia entre el cálculo realizado por OptimizerUtil::ComputeRowLength y el tamaño físico de las filas. Esto podría verse como un error :SQL Server no debe contar las columnas de metadatos en el flujo de inserción hacia el tamaño físico final de la fila. Por otro lado, el cálculo puede ser simplemente una estimación de mejor esfuerzo usando la actualización genérica operador.
El cálculo tampoco tiene en cuenta otros factores como la sobrecarga de 14 bytes del control de versiones de filas. Esto se puede probar volviendo a ejecutar el script de demostración con cualquiera de los aislamiento de instantánea o leer aislamiento de instantánea confirmado opciones de base de datos habilitadas. El tamaño físico de la fila aumentará en 14 bytes (de 60 bytes a 74), pero el umbral para registro mínimo permanece sin cambios en 898 filas.
Cálculo de umbral
Ahora tenemos todos los detalles que necesitamos para ver por qué el umbral es de 898 filas para esta tabla en SQL Server 2012 y versiones anteriores:
- 898 filas cumple con el primer requisito para más de 250 filas .
- Tamaño de fila calculado =73 bytes.
- Número estimado de filas =897.
- Tamaño total de datos =73 bytes * 897 filas =65481 bytes.
- Páginas totales =65481/8192 =7,9932861328125.
- Esto está justo debajo del segundo requisito para>=8 páginas.
- Para 898 filas, el número de páginas es 8,002197265625.
- Esto es >=8 páginas entonces registro mínimo está activado.
En SQL Server 2014 y posterior , los cambios son:
- El tamaño de fila lo calcula el generador de metadatos.
- La columna entera interna en el localizador de tablas ya no está presente en el flujo de inserción. Esto representa el uniquificador , que solo se aplica a los índices. Parece probable que esto se eliminó como una corrección de errores.
- El tamaño de fila esperado cambia de 73 a 69 bytes debido a la columna de enteros omitida (4 bytes).
- El tamaño físico sigue siendo de 60 bytes. La diferencia restante de 9 bytes se explica por el RID adicional de 8 bytes y las columnas internas de bits de 1 byte en el flujo de inserción.
Para alcanzar el umbral de 8 páginas con 69 bytes por fila:
- 8 páginas * 8192 bytes por página =65536 bytes.
- 65535 bytes/69 bytes por fila =949,7971014492754 filas.
- Por lo tanto, esperamos un mínimo de 950 filas para habilitar la carga masiva de conjuntos de filas para esta tabla en SQL Server 2014 en adelante.
Resumen y pensamientos finales
A diferencia de los métodos de carga masiva que admiten tamaño de lote , como se explica en la publicación de Parikshit Savjani, INSERT...SELECT en un montón no indexado (vacío o no) no siempre dan como resultado un registro mínimo cuando se especifica el bloqueo de tablas.
Para habilitar el registro mínimo con INSERT...SELECT , SQL Server debe esperar más de 250 filas con un tamaño total de al menos una extensión (8 páginas).
Al calcular el tamaño de inserción total estimado (para comparar con el umbral de 8 páginas), SQL Server multiplica el número estimado de filas por un tamaño de fila máximo calculado. SQL Server cuenta columnas internas presente en el flujo de inserción al calcular el tamaño de la fila. Para SQL Server 2012 y versiones anteriores, esto agrega 13 bytes por fila. Para SQL Server 2014 y versiones posteriores, agrega 9 bytes por fila. Esto solo afecta el cálculo; no afecta el tamaño físico final de las filas.
Cuando la carga masiva de almacenamiento dinámico mínimamente registrada está activa, SQL Server no insertar filas una a la vez. Las extensiones se asignan por adelantado y las filas que se insertarán se recopilan en páginas completamente nuevas mediante sqlmin!RowsetBulk antes de agregarse a la estructura existente. A continuación se muestra una pila de llamadas de ejemplo:
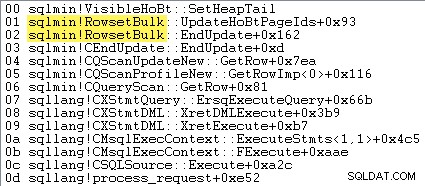
Las lecturas lógicas no se informan para la tabla de destino cuando se utiliza una carga masiva de almacenamiento dinámico mínimamente registrada:la inserción de tabla el operador no necesita leer una página existente para ubicar el punto de inserción para cada nueva fila.
Los planes de ejecución actualmente no se muestran cuántas filas o páginas se insertaron mediante carga masiva de conjunto de filas y registro mínimo . Quizás esta información útil se agregue al producto en una versión futura.