Cuando necesita implementar un sistema de análisis para una empresa, a menudo surge la duda de dónde se deben almacenar los datos. No siempre existe una opción perfecta para todos los requisitos y depende del presupuesto, la cantidad de datos y las necesidades de la empresa.
PostgreSQL, como la base de datos de código abierto más avanzada, es tan flexible que puede servir como una base de datos relacional simple, una base de datos de series de tiempo e incluso como una solución de almacenamiento de datos eficiente y de bajo costo. También puede integrarlo con varias herramientas de análisis.
Si está buscando un almacén de datos de alto rendimiento, bajo costo y ampliamente compatible, la mejor opción de base de datos podría ser PostgreSQL, pero ¿por qué? En este blog, veremos qué es un almacén de datos, por qué es necesario y por qué PostgreSQL podría ser la mejor opción aquí.
¿Qué es un almacén de datos?
Un almacén de datos es un sistema estandarizado, consistente e integrado que contiene datos actuales o históricos de una o más fuentes que se utilizan para informes y análisis de datos. Se considera un componente central de la inteligencia empresarial, que es la estrategia y la tecnología que utiliza una empresa para comprender mejor su contexto comercial.
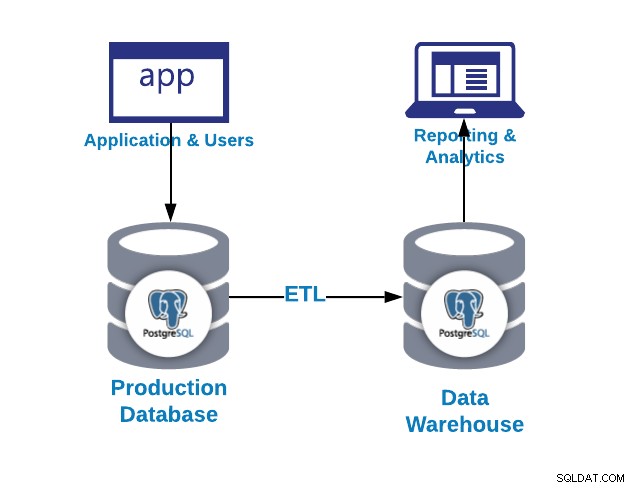
La primera pregunta que puede hacerse es ¿por qué necesito un almacén de datos?
- Integración:integre/centralice datos de múltiples sistemas/bases de datos
- Estandarizar:Estandarizar todos los datos en el mismo formato
- Analytics:analiza datos en un contexto histórico
Algunos de los beneficios de un almacén de datos pueden ser...
- Integre datos de múltiples fuentes en una sola base de datos
- Evite el bloqueo o la carga de producción debido a consultas de ejecución prolongada
- Almacenar información histórica
- Reestructurar los datos para que se ajusten a los requisitos analíticos
Como pudimos ver en la imagen anterior, podemos usar PostgreSQL tanto para propuestas OLAP como OLTP. Veamos la diferencia.
- OLTP:Procesamiento de transacciones en línea. En general, tiene una gran cantidad de transacciones cortas en línea (INSERTAR, ACTUALIZAR, ELIMINAR) generadas por la actividad del usuario. Estos sistemas enfatizan el procesamiento de consultas muy rápido y el mantenimiento de la integridad de los datos en entornos de acceso múltiple. Aquí, la eficacia se mide por el número de transacciones por segundo. Las bases de datos OLTP contienen datos detallados y actualizados.
- OLAP:Procesamiento analítico en línea. En general, tiene un bajo volumen de transacciones complejas generadas por grandes informes. El tiempo de respuesta es una medida de eficacia. Estas bases de datos almacenan datos históricos agregados en esquemas multidimensionales. Las bases de datos OLAP se utilizan para analizar datos multidimensionales de múltiples fuentes y perspectivas.
Tenemos dos formas de cargar datos en nuestra base de datos de análisis:
- ETL:extraer, transformar y cargar. Esta es la forma de generar nuestro almacén de datos. Primero, extraiga los datos de la base de datos de producción, transforme los datos de acuerdo con nuestros requisitos y luego cárguelos en nuestro almacén de datos.
- ELT:Extraer, cargar y transformar. Primero, extraiga los datos de la base de datos de producción, cárguelos en la base de datos y luego transforme los datos. Esta forma se llama Data Lake y es un nuevo concepto para gestionar nuestro big data.
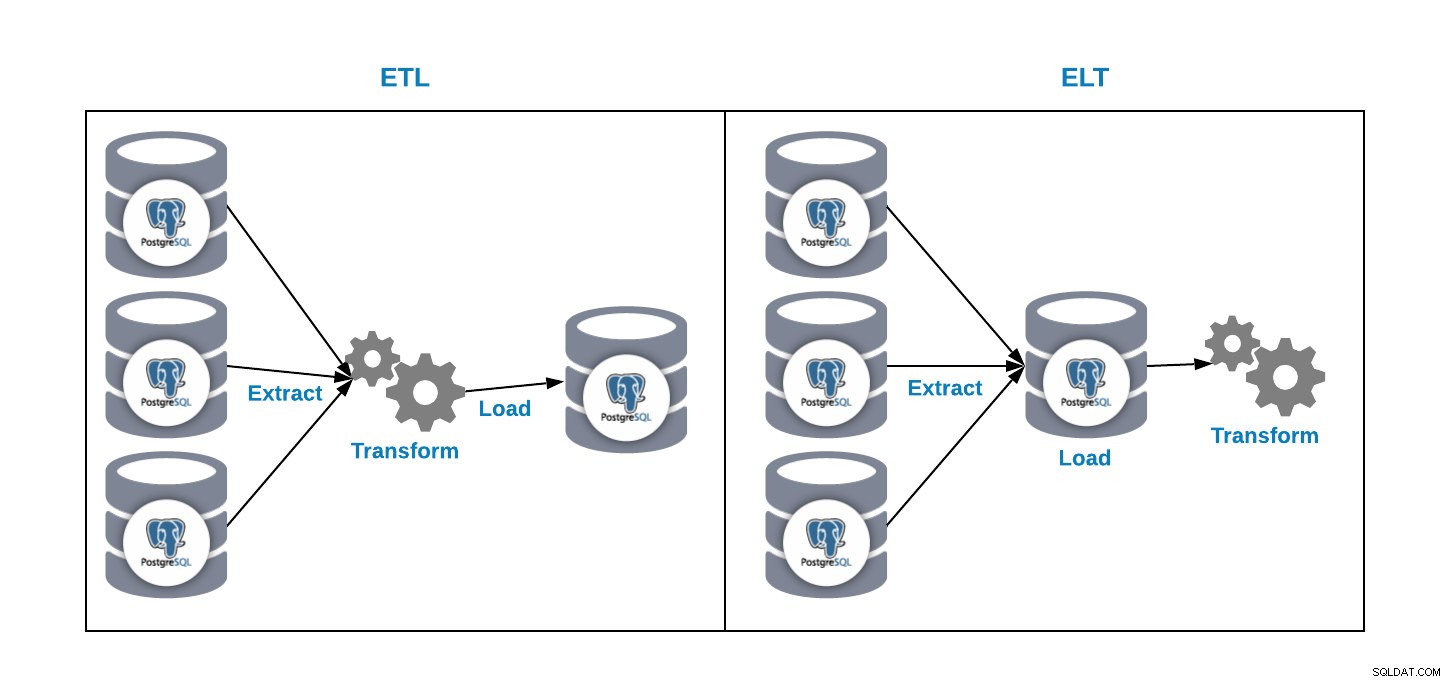
Y ahora, la segunda pregunta i, ¿por qué debo usar PostgreSQL para mi almacén de datos?
Beneficios de PostgreSQL como almacén de datos
Veamos algunos de los beneficios de usar PostgreSQL como almacén de datos...
- Costo:si usa un entorno local, el costo del producto en sí será de $0, incluso si usa algún producto en la nube, probablemente el costo de un producto basado en PostgreSQL sea menor que el resto de productos.
- Escala:puede escalar las lecturas de una manera simple agregando tantos nodos de réplica como desee.
- Rendimiento:Con una configuración correcta, PostgreSQL tiene un muy buen desempeño en diferentes escenarios.
- Compatibilidad:puede integrar PostgreSQL con herramientas o aplicaciones externas para minería de datos, OLAP e informes.
- Extensibilidad:PostgreSQL tiene funciones y tipos de datos definidos por el usuario.
También hay algunas funciones de PostgreSQL que pueden ayudarnos a administrar la información de nuestro almacén de datos...
- Tablas temporales:es una tabla de corta duración que existe durante la duración de una sesión de base de datos. PostgreSQL elimina automáticamente las tablas temporales al final de una sesión o transacción.
- Procedimientos almacenados:puede usarlo para crear procedimientos o funciones en varios idiomas (PL/pgSQL, PL/Perl, PL/Python, etc.).
- Particionamiento:esto es realmente útil para el mantenimiento de la base de datos, consultas usando la clave de partición y el rendimiento de INSERT.
- Vista materializada:los resultados de la consulta se muestran como una tabla.
- Tablespaces:puede cambiar la ubicación de los datos a un disco diferente. De esta forma, tendrá acceso al disco en paralelo.
- Compatible con PITR:puede crear copias de seguridad compatibles con la recuperación en un momento dado, por lo que, en caso de falla, puede restaurar el estado de la base de datos en un período de tiempo específico.
- Enorme comunidad:Y por último, pero no menos importante, PostgreSQL tiene una gran comunidad donde puede encontrar soporte en muchos temas diferentes.
Configuración de PostgreSQL para el uso del almacén de datos
No existe una mejor configuración para usar en todos los casos y en todas las tecnologías de base de datos. Depende de muchos factores, como el hardware, el uso y los requisitos del sistema. A continuación se presentan algunos consejos para configurar su base de datos PostgreSQL para que funcione como un almacén de datos de la manera correcta.
Basado en memoria
- max_connections:como base de datos de almacenamiento de datos, no necesita una gran cantidad de conexiones porque esto se usará para el trabajo de informes y análisis, por lo que puede limitar el número máximo de conexiones usando este parámetro.
- shared_buffers:establece la cantidad de memoria que utiliza el servidor de la base de datos para los búferes de memoria compartida. Un valor razonable puede ser del 15% al 25% de la memoria RAM.
- effect_cache_size:el planificador de consultas utiliza este valor para tener en cuenta los planes que pueden o no caber en la memoria. Esto se tiene en cuenta en las estimaciones de costos del uso de un índice; un valor alto hace que sea más probable que se utilicen exploraciones de índice y un valor bajo hace que sea más probable que se utilicen exploraciones secuenciales. Un valor razonable sería alrededor del 75% de la memoria RAM.
- work mem:especifica la cantidad de memoria que usarán las operaciones internas de ORDER BY, DISTINCT, JOIN y tablas hash antes de escribir en los archivos temporales en el disco. Al configurar este valor, debemos tener en cuenta que varias sesiones están ejecutando estas operaciones al mismo tiempo y cada operación podrá usar tanta memoria como especifica este valor antes de comenzar a escribir datos en archivos temporales. Un valor razonable puede rondar el 2% de la Memoria RAM.
- maintenance_work_mem:especifica la cantidad máxima de memoria que usarán las operaciones de mantenimiento, como VACUUM, CREATE INDEX y ALTER TABLE ADD FOREIGN KEY. Un valor razonable puede rondar el 15% de la Memoria RAM.
Basado en CPU
- Max_worker_processes:establece la cantidad máxima de procesos en segundo plano que el sistema puede admitir. Un valor razonable puede ser el número de CPU.
- Max_parallel_workers_per_gather:establece la cantidad máxima de trabajadores que puede iniciar un único nodo Gather o Gather Merge. Un valor razonable puede ser el 50 % del número de CPU.
- Max_parallel_workers:establece la cantidad máxima de trabajadores que el sistema puede admitir para consultas paralelas. Un valor razonable puede ser el número de CPU.
Como los datos cargados en nuestro almacén de datos no deberían cambiar, también podemos desactivar Autovacuum para evitar una carga adicional en su base de datos PostgreSQL. Los procesos Vacío y Análisis pueden ser parte del proceso de carga por lotes.
Conclusión
Si está buscando un almacén de datos ampliamente compatible, de bajo costo y de alto rendimiento, definitivamente debería considerar PostgreSQL como una opción para su base de datos de almacén de datos. PostgreSQL tiene muchos beneficios y funciones útiles para administrar nuestro almacén de datos, como particiones o procedimientos almacenados, y aún más.