Todos los sistemas de bases de datos modernos admiten un módulo Query Optimizer para identificar automáticamente la estrategia más eficiente para ejecutar las consultas SQL. La estrategia eficiente se llama “Plan” y se mide en términos de costo que es directamente proporcional al “Tiempo de Ejecución/Respuesta de Consulta”. El plan se representa en forma de una salida de árbol del Optimizador de consultas. Los nodos del árbol del plan se pueden dividir principalmente en las siguientes 3 categorías:
- Escanear nodos :Como se explicó en mi blog anterior "Una descripción general de los diversos métodos de escaneo en PostgreSQL", indica la forma en que se deben obtener los datos de una tabla base.
- Unirse a nodos :Como se explicó en mi blog anterior "Una descripción general de los métodos JOIN en PostgreSQL", indica cómo se deben unir dos tablas para obtener el resultado de dos tablas.
- Nodos de materialización :También llamados nodos auxiliares. Los dos tipos de nodos anteriores estaban relacionados con cómo obtener datos de una tabla base y cómo unir datos recuperados de dos tablas. Los nodos de esta categoría se aplican sobre los datos recuperados para analizar o preparar informes, etc. Clasificación de los datos, agregado de datos, etc.
Considere un ejemplo de consulta simple como...
SELECT * FROM TBL1, TBL2 where TBL1.ID > TBL2.ID order by TBL.ID;Suponga que se generó un plan correspondiente a la consulta de la siguiente manera:
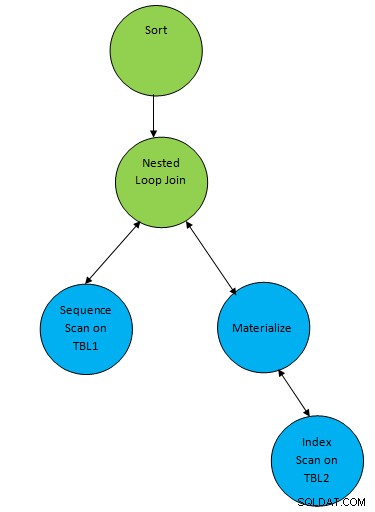
Así que aquí se agrega un nodo auxiliar "Ordenar" encima del resultado de unión para ordenar los datos en el orden requerido.
Algunos de los nodos auxiliares generados por el optimizador de consultas de PostgreSQL son los siguientes:
- Ordenar
- Agregado
- Agrupar por agregado
- Límite
- Único
- Bloquear filas
- EstablecerOp
Vamos a entender cada uno de estos nodos.
Ordenar
Como sugiere el nombre, este nodo se agrega como parte de un árbol del plan cada vez que se necesitan datos ordenados. Los datos ordenados se pueden solicitar de forma explícita o implícita, como se muestra a continuación en dos casos:
El escenario del usuario requiere datos ordenados como salida. En este caso, el nodo Ordenar puede estar al tanto de la recuperación de datos completos, incluido el resto del procesamiento.
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 10000);
INSERT 0 10000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demotable order by num;
QUERY PLAN
----------------------------------------------------------------------
Sort (cost=819.39..844.39 rows=10000 width=15)
Sort Key: num
-> Seq Scan on demotable (cost=0.00..155.00 rows=10000 width=15)
(3 rows)Nota: Aunque el usuario requirió la salida final en orden ordenado, es posible que el nodo Ordenar no se agregue en el plan final si hay un índice en la tabla correspondiente y la columna de ordenación. En este caso, puede elegir un escaneo de índice que dará como resultado un orden de datos ordenado implícitamente. Por ejemplo, creemos un índice en el ejemplo anterior y veamos el resultado:
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# explain select * from demotable order by num;
QUERY PLAN
--------------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.29..534.28 rows=10000 width=15)
(1 row)Como se explicó en mi blog anterior Una descripción general de los métodos JOIN en PostgreSQL, Merge Join requiere que ambos datos de la tabla se clasifiquen antes de unirse. Por lo tanto, puede suceder que Merge Join resulte más económico que cualquier otro método de combinación, incluso con un costo adicional de clasificación. Entonces, en este caso, el nodo Ordenar se agregará entre el método de combinación y escaneo de la tabla para que los registros ordenados puedan pasarse al método de combinación.
postgres=# create table demo1(id int, id2 int);
CREATE TABLE
postgres=# insert into demo1 values(generate_series(1,1000), generate_series(1,1000));
INSERT 0 1000
postgres=# create table demo2(id int, id2 int);
CREATE TABLE
postgres=# create index demoidx2 on demo2(id);
CREATE INDEX
postgres=# insert into demo2 values(generate_series(1,100000), generate_series(1,100000));
INSERT 0 100000
postgres=# analyze;
ANALYZE
postgres=# explain select * from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
------------------------------------------------------------------------------------
Merge Join (cost=65.18..109.82 rows=1000 width=16)
Merge Cond: (demo2.id = demo1.id)
-> Index Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(6 rows)Agregado
El nodo agregado se agrega como parte de un árbol del plan si se utiliza una función agregada para calcular resultados únicos de varias filas de entrada. Algunas de las funciones agregadas utilizadas son COUNT, SUM, AVG (PROMEDIO), MAX (MÁXIMO) y MIN (MÍNIMO).
Un nodo agregado puede aparecer encima de un escaneo de relación base o (y) en la unión de relaciones. Ejemplo:
postgres=# explain select count(*) from demo1;
QUERY PLAN
---------------------------------------------------------------
Aggregate (cost=17.50..17.51 rows=1 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=0)
(2 rows)
postgres=# explain select sum(demo1.id) from demo1, demo2 where demo1.id=demo2.id;
QUERY PLAN
-----------------------------------------------------------------------------------------------
Aggregate (cost=112.32..112.33 rows=1 width=8)
-> Merge Join (cost=65.18..109.82 rows=1000 width=4)
Merge Cond: (demo2.id = demo1.id)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..3050.29 rows=100000 width=4)
-> Sort (cost=64.83..67.33 rows=1000 width=4)
Sort Key: demo1.id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)Agregado hash / Agregado de grupo
Este tipo de nodos son extensiones del nodo "Agregado". Si las funciones agregadas se utilizan para combinar varias filas de entrada según su grupo, estos tipos de nodos se agregan a un árbol del plan. Entonces, si la consulta tiene alguna función agregada utilizada y junto con eso hay una cláusula GROUP BY en la consulta, entonces se agregará el nodo HashAggregate o GroupAggregate al árbol del plan.
Dado que PostgreSQL usa el Optimizador basado en costos para generar un árbol de planes óptimo, es casi imposible adivinar cuál de estos nodos se usará. Pero entendamos cuándo y cómo se usa.
Agregado hash
HashAggregate funciona construyendo la tabla hash de los datos para agruparlos. Por lo tanto, HashAggregate puede ser utilizado por agregados a nivel de grupo si el agregado se produce en un conjunto de datos sin clasificar.
postgres=# explain select count(*) from demo1 group by id2;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=20.00..30.00 rows=1000 width=12)
Group Key: id2
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Aquí los datos del esquema de la tabla demo1 son como en el ejemplo que se muestra en la sección anterior. Dado que solo hay 1000 filas para agrupar, el recurso requerido para construir una tabla hash es menor que el costo de ordenar. El planificador de consultas decide elegir HashAggregate.
Grupo Agregado
GroupAggregate funciona con datos ordenados, por lo que no requiere ninguna estructura de datos adicional. GroupAggregate puede ser utilizado por agregados a nivel de grupo si la agregación está en un conjunto de datos ordenados. Para agrupar datos ordenados, puede ordenarlos explícitamente (agregando el nodo Ordenar) o podría funcionar con datos obtenidos por índice, en cuyo caso se ordena implícitamente.
postgres=# explain select count(*) from demo2 group by id2;
QUERY PLAN
-------------------------------------------------------------------------
GroupAggregate (cost=9747.82..11497.82 rows=100000 width=12)
Group Key: id2
-> Sort (cost=9747.82..9997.82 rows=100000 width=4)
Sort Key: id2
-> Seq Scan on demo2 (cost=0.00..1443.00 rows=100000 width=4)
(5 rows) Aquí los datos del esquema de la tabla demo2 son como en el ejemplo que se muestra en la sección anterior. Dado que aquí hay 100000 filas para agrupar, el recurso necesario para crear una tabla hash puede ser más costoso que el costo de clasificación. Entonces, el planificador de consultas decide elegir GroupAggregate. Observe aquí que los registros seleccionados de la tabla "demo2" están ordenados explícitamente y para los cuales hay un nodo agregado en el árbol del plan.
Vea a continuación otro ejemplo, donde los datos ya se recuperaron ordenados debido al escaneo de índice:
postgres=# create index idx1 on demo1(id);
CREATE INDEX
postgres=# explain select sum(id2), id from demo1 where id=1 group by id;
QUERY PLAN
------------------------------------------------------------------------
GroupAggregate (cost=0.28..8.31 rows=1 width=12)
Group Key: id
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(4 rows) Vea a continuación un ejemplo más, que a pesar de que tiene un escaneo de índice, aún necesita clasificarse explícitamente como la columna en la que el índice y la columna de agrupación no son lo mismo. Así que todavía necesita ordenarse según la columna de agrupación.
postgres=# explain select sum(id), id2 from demo1 where id=1 group by id2;
QUERY PLAN
------------------------------------------------------------------------------
GroupAggregate (cost=8.30..8.32 rows=1 width=12)
Group Key: id2
-> Sort (cost=8.30..8.31 rows=1 width=8)
Sort Key: id2
-> Index Scan using idx1 on demo1 (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = 1)
(6 rows)Nota: GroupAggregate/HashAggregate se puede usar para muchas otras consultas indirectas aunque la agregación con el grupo no esté presente en la consulta. Depende de cómo el planificador interprete la consulta. P.ej. Digamos que necesitamos obtener un valor distinto de la tabla, luego se puede ver como un grupo en la columna correspondiente y luego tomar un valor de cada grupo.
postgres=# explain select distinct(id) from demo1;
QUERY PLAN
---------------------------------------------------------------
HashAggregate (cost=17.50..27.50 rows=1000 width=4)
Group Key: id
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=4)
(3 rows)Así que aquí se usa HashAggregate a pesar de que no hay agregación ni grupo involucrado.
Límite
Los nodos de límite se agregan al árbol del plan si se usa la cláusula "límite/compensación" en la consulta SELECT. Esta cláusula se usa para limitar el número de filas y, opcionalmente, proporcionar un desplazamiento para comenzar a leer datos. Ejemplo a continuación:
postgres=# explain select * from demo1 offset 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.15..15.00 rows=990 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.00..0.15 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)
postgres=# explain select * from demo1 offset 5 limit 10;
QUERY PLAN
---------------------------------------------------------------
Limit (cost=0.07..0.22 rows=10 width=8)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=8)
(2 rows)Único
Este nodo se selecciona para obtener un valor distinto del resultado subyacente. Tenga en cuenta que, dependiendo de la consulta, la selectividad y otra información de recursos, el valor distintivo se puede recuperar usando HashAggregate/GroupAggregate también sin usar el nodo Único. Ejemplo:
postgres=# explain select distinct(id) from demo2 where id<100;
QUERY PLAN
-----------------------------------------------------------------------------------
Unique (cost=0.29..10.27 rows=99 width=4)
-> Index Only Scan using demoidx2 on demo2 (cost=0.29..10.03 rows=99 width=4)
Index Cond: (id < 100)
(3 rows)Bloquear filas
PostgreSQL proporciona funcionalidad para bloquear todas las filas seleccionadas. Las filas se pueden seleccionar en modo "Compartido" o modo "Exclusivo" dependiendo de la cláusula "PARA COMPARTIR" y "PARA ACTUALIZAR" respectivamente. Se agrega un nuevo nodo "LockRows" al árbol del plan para lograr esta operación.
postgres=# explain select * from demo1 for update;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)
postgres=# explain select * from demo1 for share;
QUERY PLAN
----------------------------------------------------------------
LockRows (cost=0.00..25.00 rows=1000 width=14)
-> Seq Scan on demo1 (cost=0.00..15.00 rows=1000 width=14)
(2 rows)ConfigurarOp
PostgreSQL proporciona funcionalidad para combinar los resultados de dos o más consultas. Entonces, a medida que se selecciona el tipo de nodo Join para unir dos tablas, se selecciona un tipo similar de nodo SetOp para combinar los resultados de dos o más consultas. Por ejemplo, considere una tabla con empleados con su identificación, nombre, edad y salario de la siguiente manera:
postgres=# create table emp(id int, name char(20), age int, salary int);
CREATE TABLE
postgres=# insert into emp values(1,'a', 30,100);
INSERT 0 1
postgres=# insert into emp values(2,'b', 31,90);
INSERT 0 1
postgres=# insert into emp values(3,'c', 40,105);
INSERT 0 1
postgres=# insert into emp values(4,'d', 20,80);
INSERT 0 1 Ahora busquemos empleados con más de 25 años:
postgres=# select * from emp where age > 25;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
2 | b | 31 | 90
3 | c | 40 | 105
(3 rows) Ahora busquemos empleados con salarios superiores a 95M:
postgres=# select * from emp where salary > 95;
id | name | age | salary
----+----------------------+-----+--------
1 | a | 30 | 100
3 | c | 40 | 105
(2 rows)Ahora, para obtener empleados con una edad superior a 25 años y un salario superior a 95 millones, podemos escribir a continuación la consulta de intersección:
postgres=# explain select * from emp where age>25 intersect select * from emp where salary > 95;
QUERY PLAN
---------------------------------------------------------------------------------
HashSetOp Intersect (cost=0.00..72.90 rows=185 width=40)
-> Append (cost=0.00..64.44 rows=846 width=40)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp (cost=0.00..25.88 rows=423 width=36)
Filter: (age > 25)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..30.11 rows=423 width=40)
-> Seq Scan on emp emp_1 (cost=0.00..25.88 rows=423 width=36)
Filter: (salary > 95)
(8 rows) Así que aquí, se agrega un nuevo tipo de nodo HashSetOp para evaluar la intersección de estas dos consultas individuales.
Tenga en cuenta que hay otros dos tipos de nuevos nodos agregados aquí:
Anexar
Este nodo se agrega para combinar varios conjuntos de resultados en uno.
Exploración de subconsulta
Este nodo se agrega para evaluar cualquier subconsulta. En el plan anterior, la subconsulta se agrega para evaluar un valor de columna constante adicional que indica qué conjunto de entrada contribuyó con una fila específica.
HashedSetop funciona usando el hash del resultado subyacente, pero es posible generar una operación SetOp basada en clasificación mediante el optimizador de consultas. El nodo Setop basado en la clasificación se denota como "Setop".
Nota:es posible lograr el mismo resultado que se muestra en el resultado anterior con una sola consulta, pero aquí se muestra usando intersect solo para una demostración sencilla.
Conclusión
Todos los nodos de PostgreSQL son útiles y se seleccionan según la naturaleza de la consulta, los datos, etc. Muchas de las cláusulas se asignan una a una con los nodos. Para algunas cláusulas, existen múltiples opciones para los nodos, que se deciden en función de los cálculos de costos de datos subyacentes.