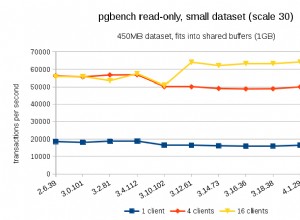
Administrar el tráfico a la base de datos puede volverse más y más difícil a medida que aumenta en cantidad y la base de datos se distribuye en varios servidores. Los clientes de PostgreSQL generalmente se comunican con un solo punto final. Cuando falla un nodo principal, los clientes de la base de datos seguirán intentando con la misma IP. En caso de que haya realizado la conmutación por error a un nodo secundario, la aplicación debe actualizarse con el nuevo punto final. Aquí es donde desearía colocar un equilibrador de carga entre las aplicaciones y las instancias de la base de datos. Puede dirigir aplicaciones a nodos de bases de datos disponibles/en buen estado y conmutación por error cuando sea necesario. Otro beneficio sería aumentar el rendimiento de lectura mediante el uso efectivo de réplicas. Es posible crear un puerto de solo lectura que equilibre las lecturas entre réplicas. En este blog, cubriremos HAProxy. Veremos qué es, cómo funciona y cómo implementarlo para PostgreSQL.
¿Qué es HAProxy?
HAProxy es un proxy de código abierto que se puede utilizar para implementar alta disponibilidad, equilibrio de carga y proxy para aplicaciones basadas en TCP y HTTP.
Como equilibrador de carga, HAProxy distribuye el tráfico desde un origen a uno o más destinos y puede definir reglas y/o protocolos específicos para esta tarea. Si alguno de los destinos deja de responder, se marca como desconectado y el tráfico se envía al resto de destinos disponibles.
Cómo instalar y configurar HAProxy manualmente
Para instalar HAProxy en Linux puede usar los siguientes comandos:
En SO Ubuntu/Debian:
$ apt-get install haproxy -yEn SO CentOS/RedHat:
$ yum install haproxy -yY luego necesitamos editar el siguiente archivo de configuración para administrar nuestra configuración HAProxy:
$ /etc/haproxy/haproxy.cfgConfigurar nuestro HAProxy no es complicado, pero necesitamos saber lo que estamos haciendo. Tenemos varios parámetros para configurar, dependiendo de cómo queramos que funcione HAProxy. Para más información, podemos seguir la documentación sobre la configuración de HAProxy.
Veamos un ejemplo de configuración básica. Suponga que tiene la siguiente topología de base de datos:
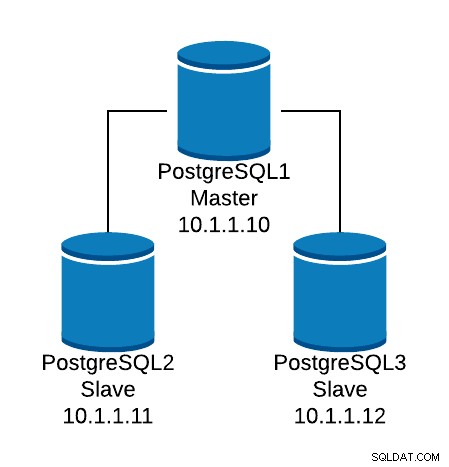 Ejemplo de topología de base de datos
Ejemplo de topología de base de datos Queremos crear un agente de escucha HAProxy para equilibrar el tráfico de lectura entre los tres nodos.
listen haproxy_read
bind *:5434
balance roundrobin
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkComo mencionamos antes, hay varios parámetros para configurar aquí, y esta configuración depende de lo que queramos hacer. Por ejemplo:
listen haproxy_read
bind *:5434
mode tcp
timeout client 10800s
timeout server 10800s
tcp-check expect string is\ running
balance leastconn
option tcp-check
default-server port 9201 inter 2s downinter 5s rise 3 fall 2 slowstart 60s maxconn 64 maxqueue 128 weight 100
server postgres1 10.1.1.10:5432 check
server postgres2 10.1.1.11:5432 check
server postgres3 10.1.1.12:5432 checkCómo funciona HAProxy en ClusterControl
Para PostgreSQL, ClusterControl configura HAProxy con dos puertos diferentes de forma predeterminada, uno de lectura y escritura y otro de solo lectura.
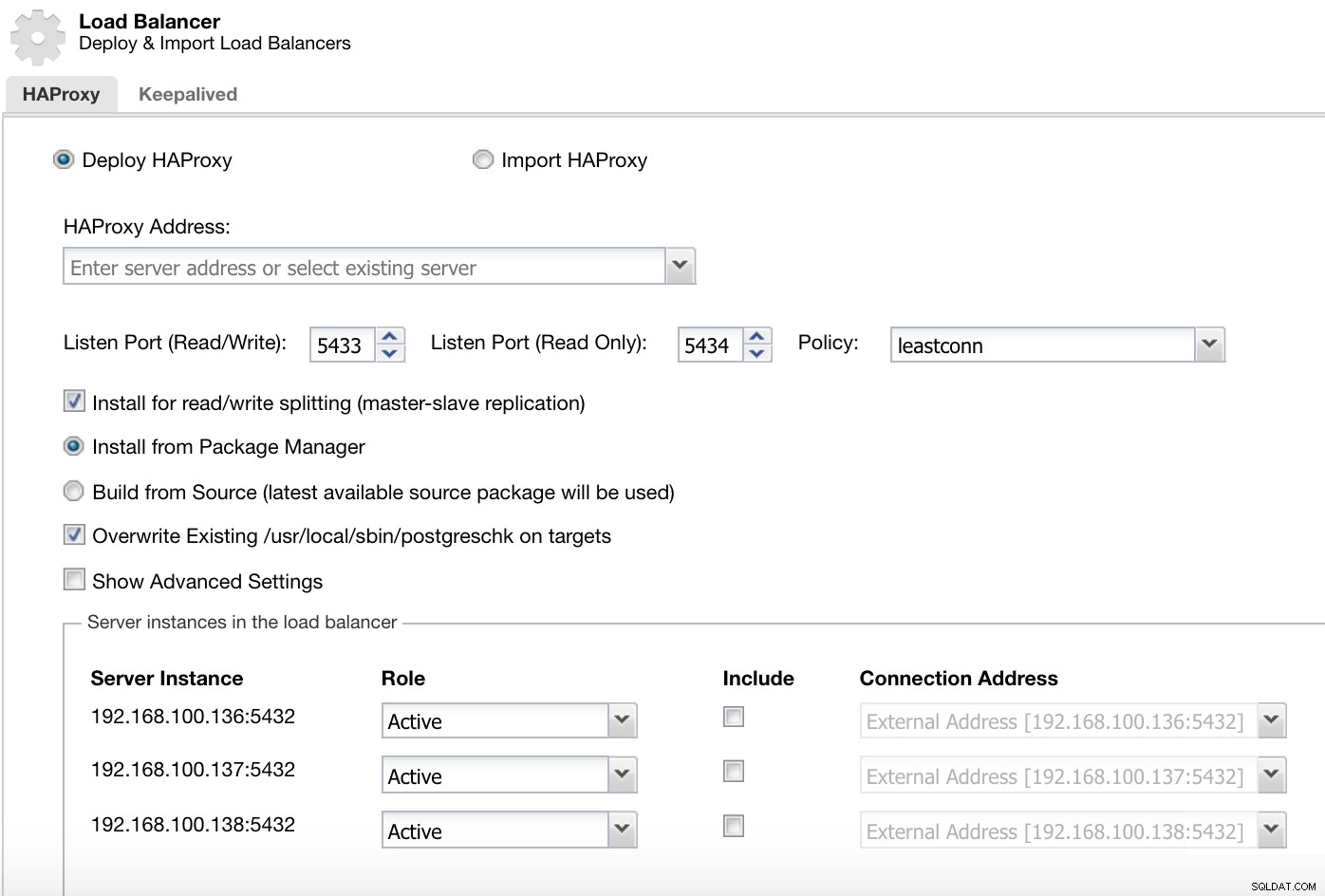 Información de implementación del equilibrador de carga de ClusterControl 1
Información de implementación del equilibrador de carga de ClusterControl 1 En nuestro puerto de lectura y escritura, tenemos nuestro servidor maestro en línea y el resto de nuestros nodos en línea, y en el puerto de solo lectura, tenemos tanto el maestro como los esclavos en línea.
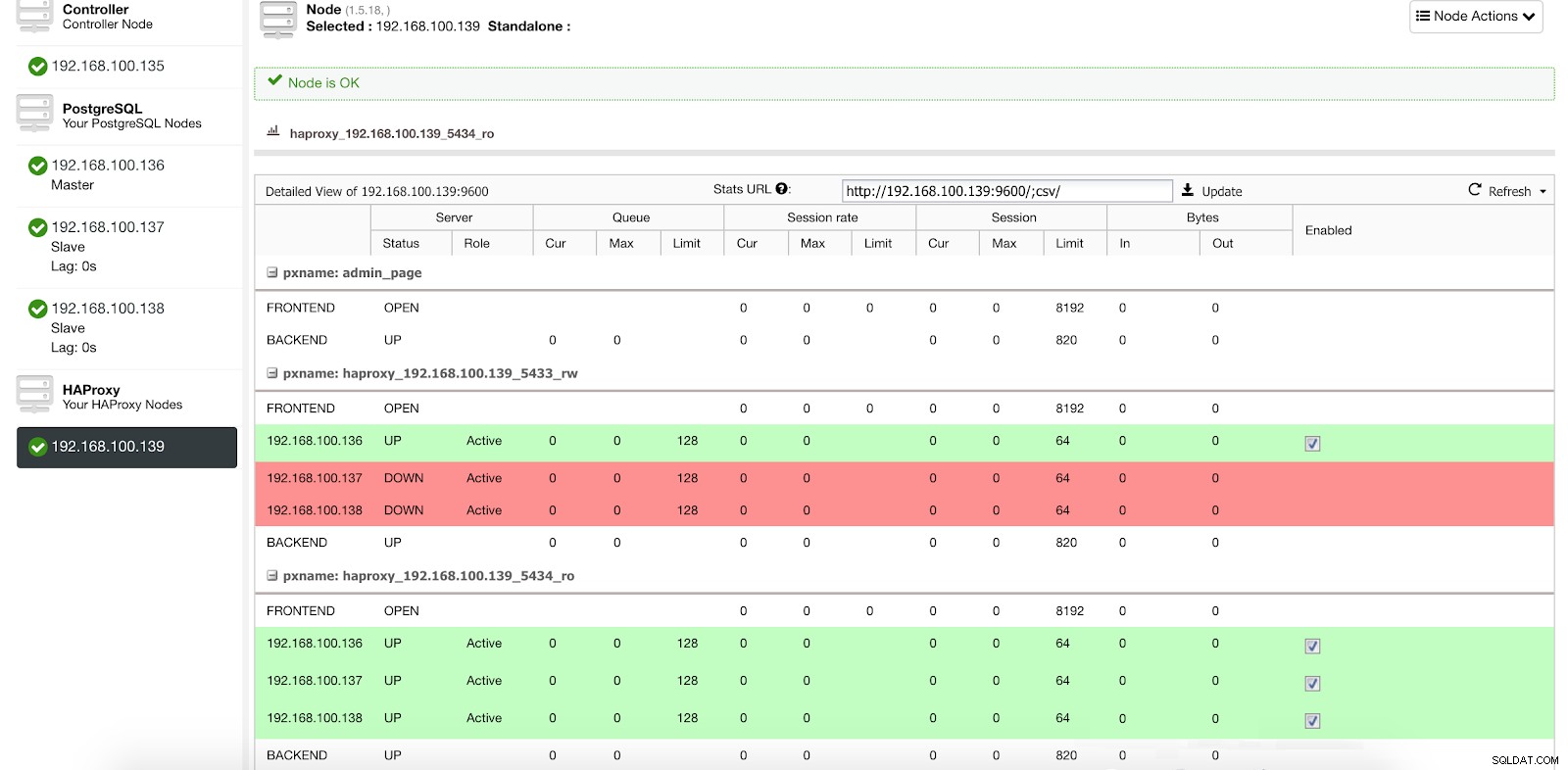 Estadísticas 1 del balanceador de carga de ClusterControl
Estadísticas 1 del balanceador de carga de ClusterControl Cuando HAProxy detecta que uno de nuestros nodos, ya sea maestro o esclavo, no está accesible, automáticamente lo marca como fuera de línea y no lo tiene en cuenta a la hora de enviar tráfico. La detección se realiza mediante secuencias de comandos de comprobación de estado configuradas por ClusterControl en el momento de la implementación. Estos comprueban si las instancias están activas, si se están recuperando o si son de solo lectura.
Cuando ClusterControl promueve un esclavo a maestro, nuestro HAProxy marca al antiguo maestro como fuera de línea (para ambos puertos) y pone el nodo promovido en línea (en el puerto de lectura y escritura).
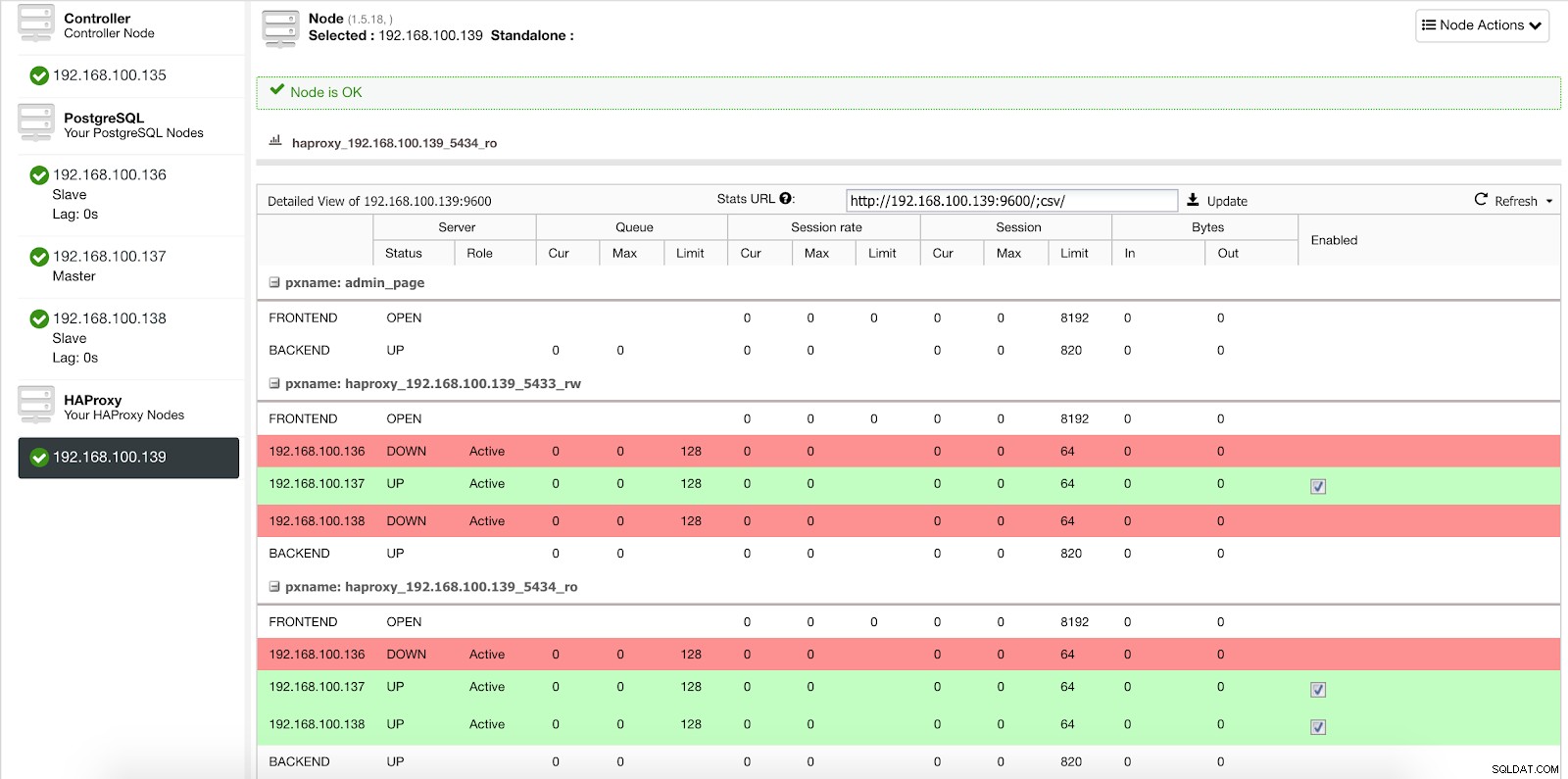 Estadísticas 2 del balanceador de carga de ClusterControl
Estadísticas 2 del balanceador de carga de ClusterControl De esta forma, nuestros sistemas continúan funcionando con normalidad y sin nuestra intervención.
Cómo implementar HAProxy con ClusterControl
En nuestro ejemplo, creamos un entorno con 1 maestro y 2 esclavos; vea una captura de pantalla de la Vista de topología en ClusterControl. Ahora agregaremos nuestro balanceador de carga HAProxy.
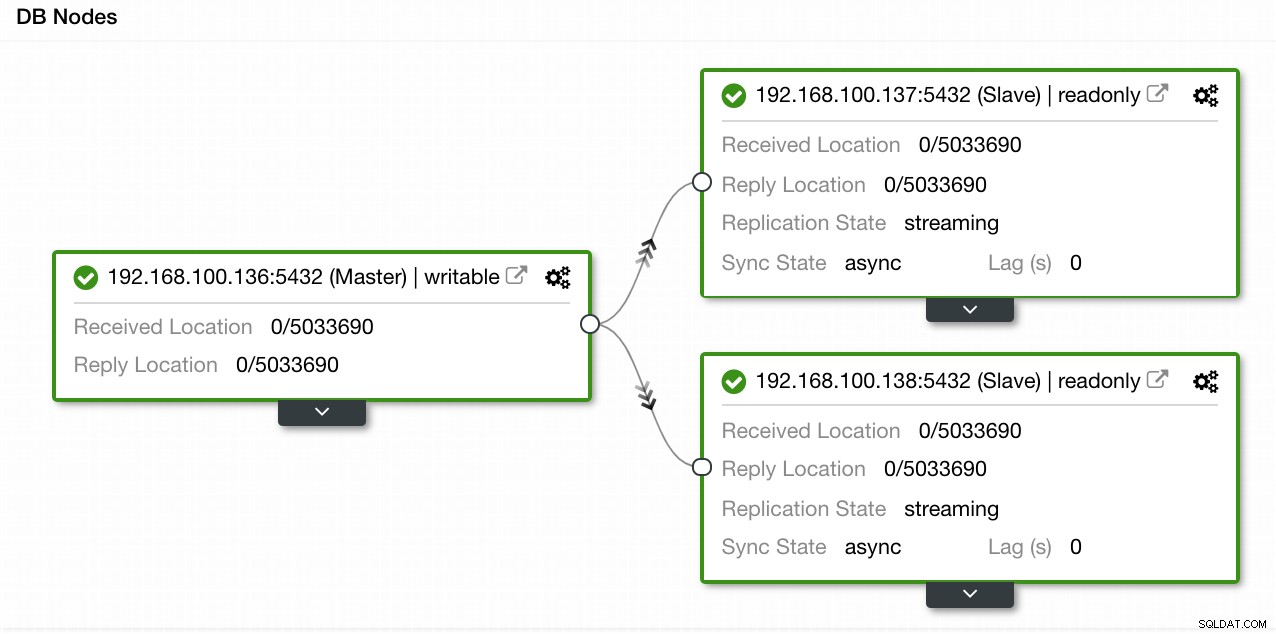 Vista de topología de control de clúster 1
Vista de topología de control de clúster 1 Para esta tarea necesitamos ir a ClusterControl -> PostgreSQL Cluster Actions -> Add Load Balancer
 Menú de acciones de clúster de ClusterControl
Menú de acciones de clúster de ClusterControl Aquí debemos agregar la información que utilizará ClusterControl para instalar y configurar nuestro balanceador de carga HAProxy.
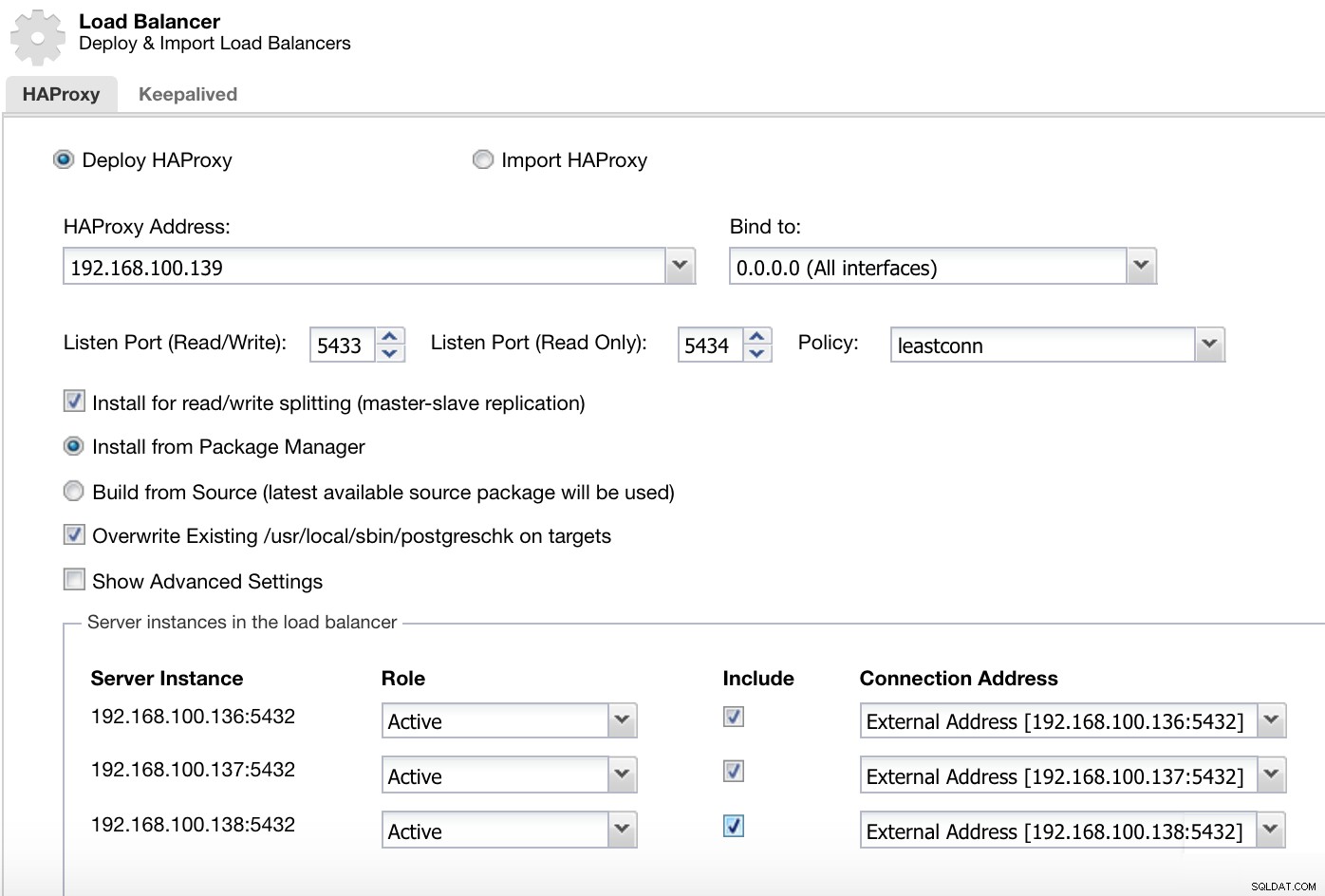 Información de implementación del equilibrador de carga de ClusterControl 2
Información de implementación del equilibrador de carga de ClusterControl 2 La información que necesitamos introducir es:
Acción:Implementar o Importar.
Dirección HAProxy:Dirección IP para nuestro servidor HAProxy.
Vincular a:Interfaz o dirección IP donde escuchará HAProxy.
Puerto de escucha (lectura/escritura):puerto para el modo de lectura/escritura.
Puerto de escucha (solo lectura):puerto para el modo de solo lectura.
Política:Puede ser:
- leastconn:el servidor con el menor número de conexiones recibe la conexión.
- roundrobin:Cada servidor se utiliza por turnos, según sus pesos.
- origen:la dirección IP de origen se codifica y se divide por el peso total de los servidores en ejecución para designar qué servidor recibirá la solicitud.
Instalar para división de lectura/escritura:para replicación maestro-esclavo.
Fuente:podemos elegir Instalar desde un administrador de paquetes o compilar desde la fuente.
Sobrescriba el postgreschk existente en los destinos.
Y debemos seleccionar qué servidores desea agregar a la configuración de HAProxy y alguna información adicional como:
Rol:Puede ser Activo o Backup.
Incluir:Sí o No.
Información de dirección de conexión.
Además, podemos configurar ajustes avanzados como usuario administrador, nombre de servidor, tiempos de espera y más.
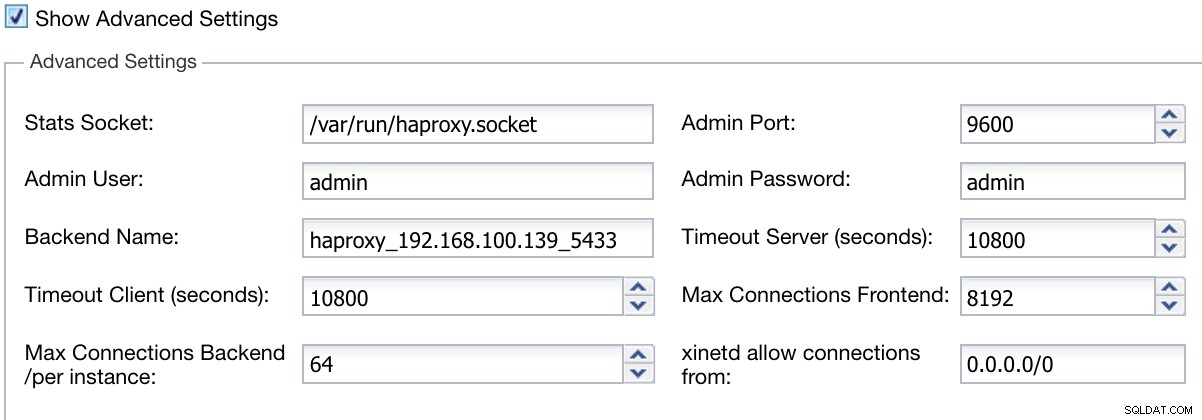 ClusterControl Load Balancer Información de implementación avanzada
ClusterControl Load Balancer Información de implementación avanzada Cuando termine la configuración y confirme la implementación, podemos seguir el progreso en la sección Actividad en la interfaz de usuario de ClusterControl.
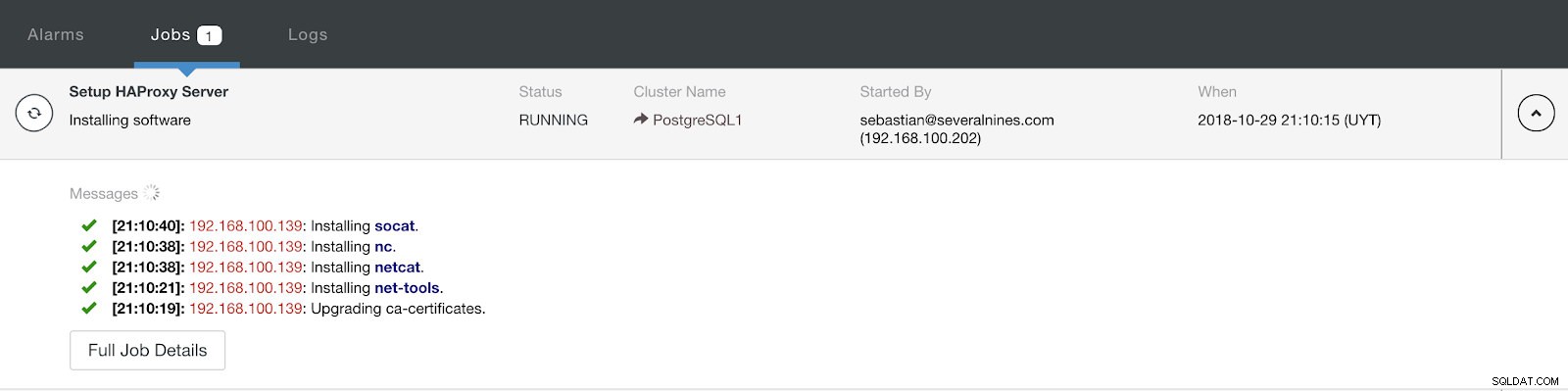 Sección de actividad de ClusterControl
Sección de actividad de ClusterControl Cuando haya terminado, deberíamos tener la siguiente topología:
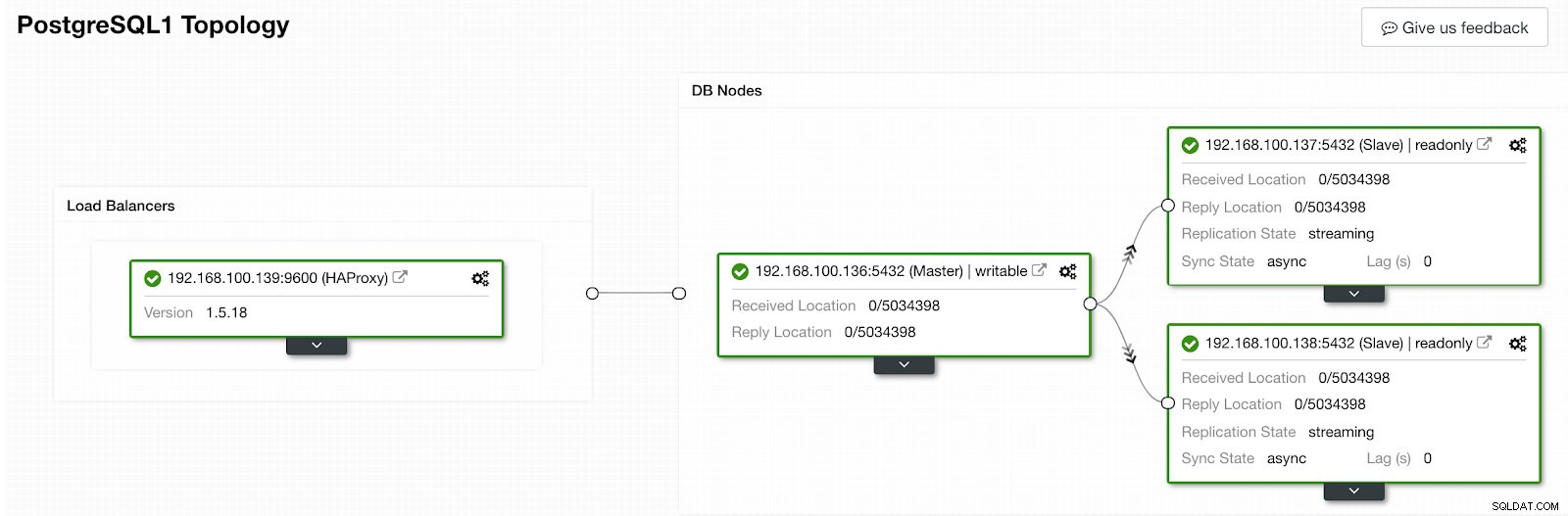 Vista de topología de control de clúster 2
Vista de topología de control de clúster 2 Podemos mejorar nuestro diseño HA agregando un nuevo nodo HAProxy y configurando el servicio Keepalived entre ellos. Todo esto puede ser realizado por ClusterControl. Para obtener más información, puede consultar nuestro blog anterior sobre PostgreSQL y HA.
Uso de la CLI de ClusterControl para agregar un balanceador de carga HAProxy
También conocido como s9s-tools, este paquete opcional se introdujo en la versión 1.4.1 de ClusterControl, que contiene un binario llamado s9s. Es una herramienta de línea de comandos para interactuar, controlar y administrar su infraestructura de base de datos usando ClusterControl. El proyecto de línea de comandos s9s es de código abierto y se puede encontrar en GitHub.
A partir de la versión 1.4.1, la secuencia de comandos del instalador instalará automáticamente el paquete (s9s-tools) en el nodo ClusterControl.
ClusterControl CLI abre una nueva puerta para la automatización de clústeres donde puede integrarla fácilmente con las herramientas de automatización de implementación existentes como Ansible, Puppet, Chef o Salt.
Veamos un ejemplo de cómo crear un balanceador de carga HAProxy con la dirección IP 192.168.100.142 en el ID de clúster 1:
[example@sqldat.com ~]# s9s cluster --add-node --cluster-id=1 --nodes="haproxy://192.168.100.142" --wait
Add HaProxy to Cluster
/ Job 7 FINISHED [██████████] 100% Job finished.Y luego podemos verificar todos nuestros nodos desde la línea de comando:
[example@sqldat.com ~]# s9s node --cluster-id=1 --list --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PostgreSQL1 192.168.100.135 9500 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.136 5432 Up and running.
poM- 10.5 1 PostgreSQL1 192.168.100.137 5432 Up and running.
poS- 10.5 1 PostgreSQL1 192.168.100.138 5432 Up and running.
ho-- 1.5.18 1 PostgreSQL1 192.168.100.142 9600 Process 'haproxy' is running.
Total: 5Para obtener más información sobre el s9s y cómo usarlo, puede consultar la documentación oficial o este blog sobre este tema.
Conclusión
En este blog, hemos revisado cómo HAProxy puede ayudarnos a administrar el tráfico proveniente de la aplicación en nuestra base de datos PostgreSQL. Verificamos cómo se puede implementar y configurar manualmente, y luego vimos cómo se puede automatizar con ClusterControl. Para evitar que HAProxy se convierta en un punto único de falla (SPOF), asegúrese de implementar al menos dos instancias de HAProxy e implemente algo como Keepalived y Virtual IP encima de ellas.