[ Parte 1 | Parte 2 | Parte 3 ]
En la parte 1, mostré cómo la compresión de la página y del almacén de columnas podría reducir el tamaño de una tabla de 1 TB en un 80 % o más. Si bien me impresionó poder reducir una tabla de 1 TB a 50 GB, no estaba muy contento con la cantidad de tiempo que tomó (entre 2 y 14 horas). Con algunos consejos gentilmente tomados de personas como Joe Obbish, Lonny Niederstadt, Niko Neugebauer y otros, en esta publicación intentaré hacer algunos cambios en mi intento original de obtener un mejor rendimiento de carga. Dado que el índice de almacén de columnas normal no se comprimió mejor que la compresión de página en este conjunto de datos , y tardó 13 horas más en llegar, me centraré únicamente en la solución más avanzada usando COLUMNSTORE_ARCHIVE compresión.
Algunos de los problemas que creo que afectaron el rendimiento incluyen los siguientes:
- Opciones de diseño de archivo incorrectas – Puse 8 archivos en un grupo de archivos, con paralelismo pero sin particiones (o subóptimas), rociando E/S en múltiples archivos con abandono imprudente. Para abordar esto, haré lo siguiente:
- particione la tabla en 8 particiones (una por núcleo)
- poner el archivo de datos de cada partición en su propio grupo de archivos
- use 8 procesos separados para afinizar a cada partición
- usar la compresión de archivos en todas las particiones excepto en la "activa"
- demasiados lotes pequeños y población de grupos de filas subóptima – al procesar 10 millones de filas a la vez, estaba completando nueve grupos de filas con 1 048 576 filas, y luego las 562 816 filas restantes terminarían en otro grupo de filas más pequeño. Y cualquier distribución desigual que dejara un resto <102 400 filas filtraría las inserciones en la estructura de almacenamiento delta menos eficiente. Para distribuir las filas de manera más uniforme y evitar el almacenamiento delta, haré lo siguiente:
- procesar la mayor cantidad de datos posible en múltiplos exactos de 1 048 576 filas
- distribúyalos en 8 particiones de la manera más uniforme posible
- use un tamaño de lote más cercano a 10x -> 100 millones de filas
- apilamiento del programador – Si bien no revisé esto, es posible que parte de la ralentización se deba a que un programador asumió demasiado trabajo y otro no lo suficiente, debido a la rotación del programador. Ahora que cargaré intencionalmente los datos con 8 procesos maxdop 1 en lugar de un proceso maxdop 8, para mantener a todos los programadores igualmente ocupados, haré lo siguiente:
- utilice un procedimiento almacenado que intente equilibrarse uniformemente entre programadores (consulte las páginas 189-191 en la Guía de SQLCAT para:motor relacional para obtener la inspiración detrás de esta idea)
- habilitar el indicador de seguimiento global 2467 y 2469, como se advierte en la documentación
- tarea de compresión de almacén de columnas en segundo plano – Fue un desperdicio permitir que esto funcionara durante la población, ya que planeé reconstruir al final de todos modos. Esta vez lo haré:
- deshabilitar esta tarea usando el indicador de seguimiento global 634
Deseché la función y el esquema de partición inicial, y construí uno nuevo basado en una distribución más uniforme de los datos. Quiero 8 particiones para que coincidan con la cantidad de núcleos y la cantidad de archivos de datos, para maximizar el "paralelismo del hombre pobre" que planeo usar.
Primero, necesitamos crear un nuevo conjunto de grupos de archivos, cada uno con su propio archivo:
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part1; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_1', size = 250000, filename = 'K:\Data\o_cci_p_1.mdf') TO FILEGROUP FG_CCI_Part1; -- ... 6 more ... ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_Part8; ALTER DATABASE OCopy ADD FILE (name = N'CCI_Part_8', size = 250000, filename = 'K:\Data\o_cci_p_8.mdf') TO FILEGROUP FG_CCI_Part8;
Luego, miré el número de filas en la tabla:3,754,965,954. Para distribuir esos exactamente uniformemente en 8 particiones, serían 469.370.744,25 filas por partición. Para que funcione bien, hagamos que los límites de la partición acomoden el siguiente múltiplo de 1.048.576 filas. Esto es 1,048,576 x 448 = 469,762,048 – que sería el número de filas que buscamos en las primeras 7 particiones, dejando 466.631.618 filas en la última partición. Para ver el OID real valores que servirían como límites para contener el número óptimo de filas en cada partición, ejecuté esta consulta en la tabla original (dado que tomó 25 minutos ejecutarla, aprendí rápidamente a volcar estos resultados en una tabla separada):
;WITH x AS
(
SELECT OID, rn = ROW_NUMBER() OVER (ORDER BY OID)
FROM dbo.tblOriginal WITH (NOLOCK)
)
SELECT OID, PartitionID = 1+(rn/((1048576*448)+1))
INTO dbo.stage
FROM x
WHERE rn % (1048576*112) = 0;
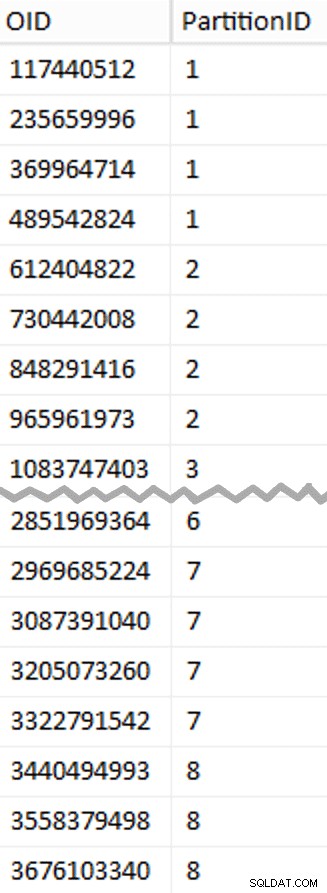 Más para desempaquetar aquí de lo que podría esperar. El CTE hace todo el trabajo pesado, ya que tiene que escanear toda la tabla de 1,14 TB y asignar un número de fila a cada fila . Solo quiero devolver cada
Más para desempaquetar aquí de lo que podría esperar. El CTE hace todo el trabajo pesado, ya que tiene que escanear toda la tabla de 1,14 TB y asignar un número de fila a cada fila . Solo quiero devolver cada (1048576*112)th fila, sin embargo, ya que estas son mis filas de límite de lote, así que esto es lo que WHERE la cláusula lo hace. Recuerde que quiero dividir el trabajo en lotes más cercanos a los 100 millones de filas a la vez, pero tampoco quiero procesar 469 millones de filas de una sola vez. Entonces, además de dividir los datos en 8 particiones, quiero dividir cada una de esas particiones en cuatro lotes de 117 440 512 (1,048,576*112) filas Cada conjunto adyacente de cuatro lotes pertenece a una partición, por lo que el PartitionID Derivo simplemente agrega uno al resultado del número de fila actual integer dividido por (1,048,576*448) , lo que garantiza que el límite esté siempre en el conjunto "izquierdo". Luego agregamos uno al resultado porque, de lo contrario, nos estaríamos refiriendo a una colección de particiones basada en 0, y nadie quiere eso.
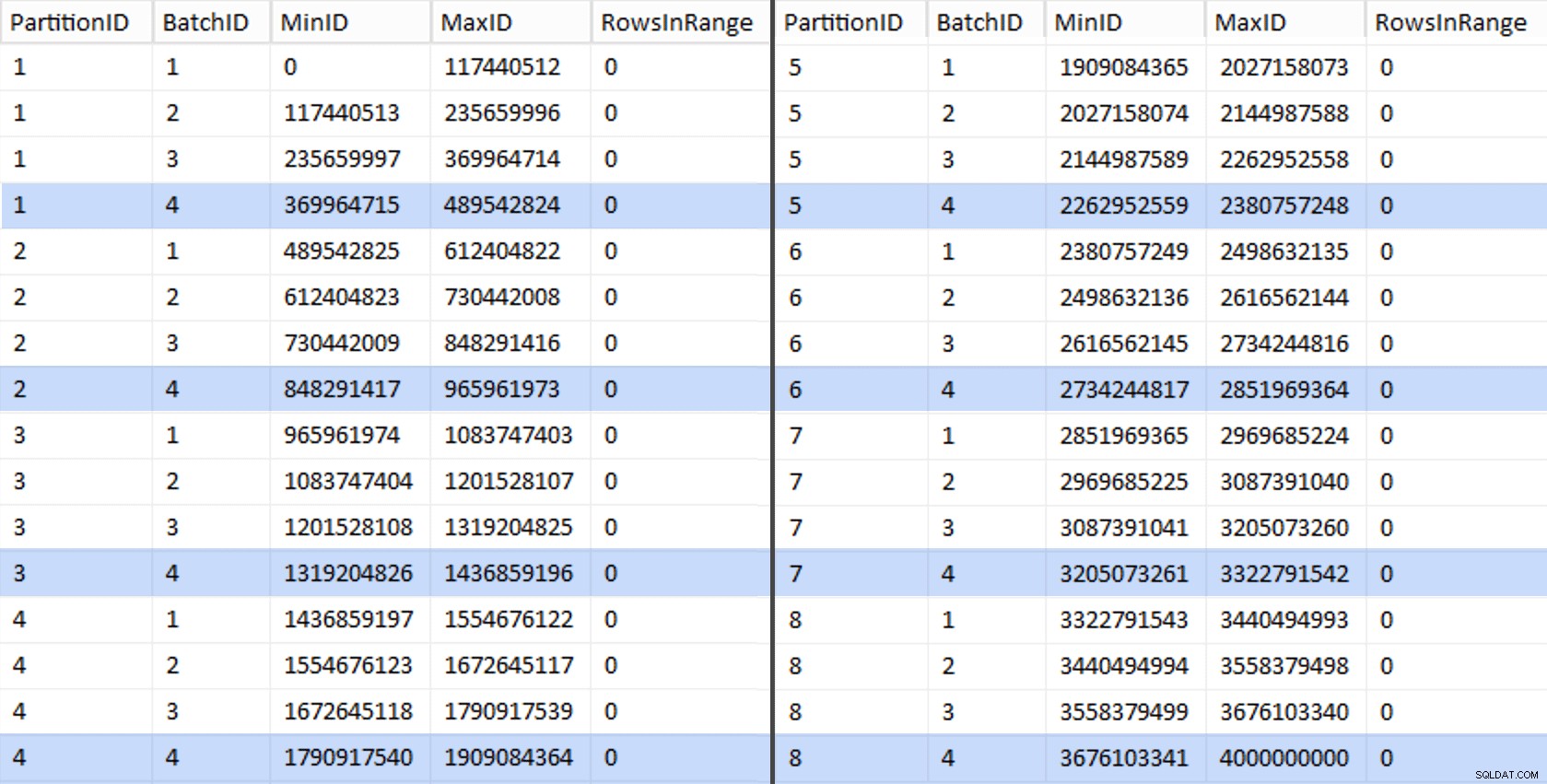
Ok, eso fue un montón de palabras. A la derecha hay una imagen que muestra el contenido (abreviado) del stage tabla (haga clic para mostrar el resultado completo, resaltando los valores de límite de partición).
Luego podemos derivar otra consulta de esa tabla de etapas que nos muestra los valores mínimo y máximo para cada lote dentro de cada partición, así como el lote adicional que no se tiene en cuenta (las filas en la tabla original con OID mayor que el valor límite más alto):
;WITH x AS
(
SELECT OID, PartitionID FROM dbo.stage
),
y AS
(
SELECT PartitionID,
MinID = COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1,
MaxID = OID
FROM x
UNION ALL
SELECT PartitionID = 8,
MinID = MAX(OID)+1,
MaxID = 4000000000 -- easier than remembering the real max
FROM x
)
SELECT PartitionID,
BatchID = ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID),
MinID,
MaxID,
RowsInRange = CONVERT(int, NULL)
INTO dbo.BatchQueue
FROM y;
-- let's not leave this as a heap:
CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID); Esos valores se ven así:
Para probar nuestro trabajo, podemos derivar de allí un conjunto de consultas que actualizarán BatchQueue con recuentos de filas reales de la tabla.
DECLARE @sql nvarchar(max) = N'';
SELECT @sql += 'UPDATE dbo.BatchQueue SET RowsInRange = (
SELECT COUNT(*)
FROM dbo.tblOriginal WITH (NOLOCK)
WHERE CostID BETWEEN ' + RTRIM(MinID) + ' AND ' + RTRIM(MaxID) + '
) WHERE MinID = ' + RTRIM(MinID) + ' AND MaxID = ' + RTRIM(MaxID) + ';'
FROM dbo.BatchQueue;
EXEC sys.sp_executesql @sql; Esto tomó alrededor de 6 minutos en mi sistema. Luego, puede ejecutar la siguiente consulta para mostrar que cada lote, excepto el último, es capaz de llenar completamente los grupos de filas y no dejar ningún resto para el uso potencial de la tienda delta:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Ahora la tabla se ve así:
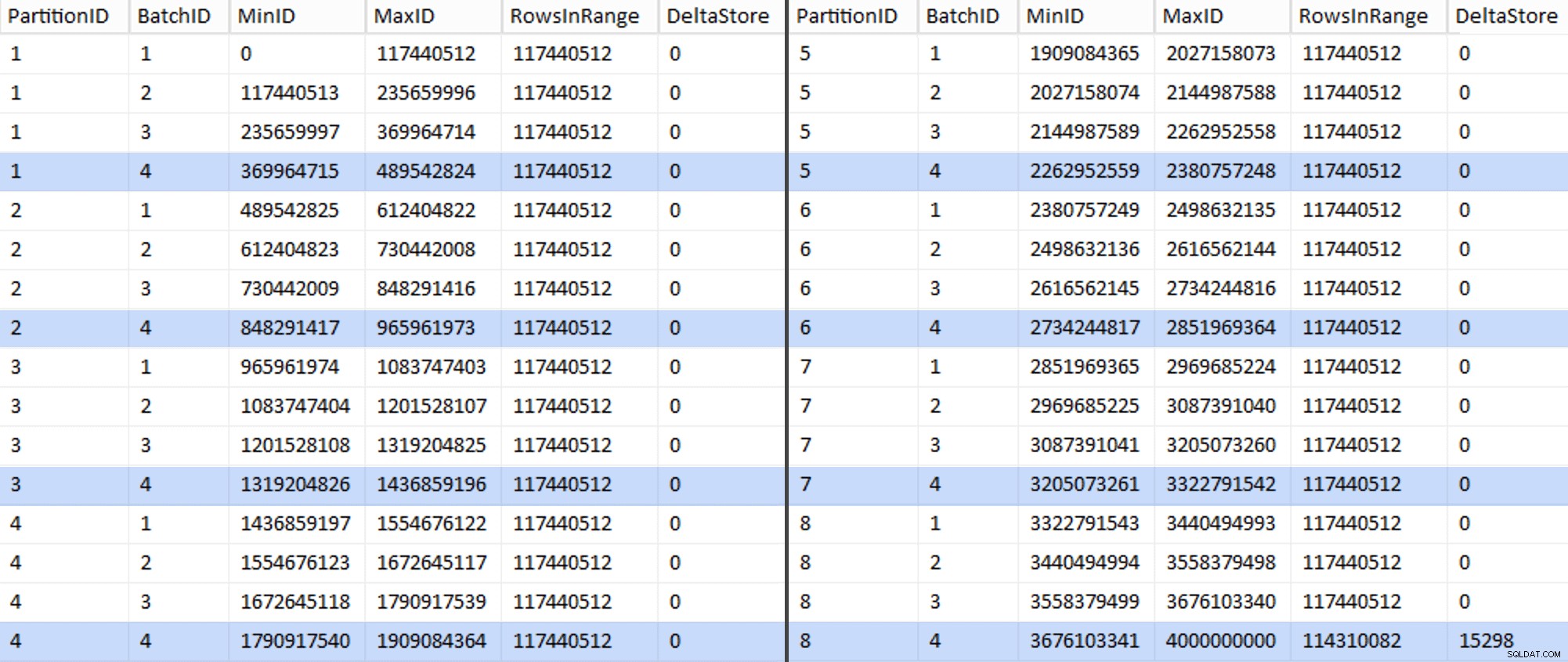
Efectivamente, cada lote tiene los 117 440 512 millones de filas calculados, excepto el último que, al menos idealmente, contendrá nuestro único almacén delta sin comprimir. Probablemente podamos evitar esto también cambiando el tamaño del lote ligeramente para esta partición para que los cuatro lotes se ejecuten con el mismo tamaño, o cambiando el número de lotes para acomodar algún otro múltiplo de 102 400 o 1 048 576. Dado que eso requeriría obtener un nuevo OID valores de la tabla base, agregando otros 25 minutos más a nuestro esfuerzo de migración, voy a dejar que esta partición imperfecta se deslice, especialmente porque de todos modos no estamos obteniendo el beneficio completo de compresión de archivo.
La BatchQueue table está comenzando a mostrar signos de ser útil para procesar nuestros lotes para migrar datos a nuestra nueva tabla de almacén de columnas agrupada y particionada. Que necesitamos crear, ahora que conocemos los límites. Solo hay 7 límites, por lo que ciertamente podría hacer esto manualmente, pero me gusta hacer que SQL dinámico haga mi trabajo por mí:
DECLARE @sql nvarchar(max) = N'';
SELECT @sql = N'CREATE PARTITION FUNCTION PF_OID([bigint])
AS RANGE LEFT FOR VALUES
(
' + STRING_AGG(MaxID, ',
') + '
);' FROM dbo.BatchQueue
WHERE PartitionID < 8
AND BatchID = 4;
PRINT @sql;
-- EXEC sys.sp_executesql @sql; Resultados:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES ( 489542824, 965961973, 1436859196, 1909084364, 2380757248, 2851969364, 3322791542 );
Una vez creado, podemos crear nuestro esquema de partición y asignar cada partición sucesiva a su archivo dedicado:
CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID TO ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8 );
Ahora podemos crear la tabla y prepararla para la migración:
CREATE TABLE dbo.tblPartitionedCCI ( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar(128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BI3 bigint NULL, NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BT1 bit NOT NULL, NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- need to create a PK constraint on the partition scheme... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID(OID) ); -- ... only to drop it immediately... ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part; GO -- ... so we can replace it with the CCI: CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblPartitionedCCI ON PS_OID(OID); GO -- now rebuild with the compression we want: ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION = ALL WITH ( DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 7), DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (8) );
En la Parte 3, seguiré configurando BatchQueue construya un procedimiento para que los procesos envíen los datos a la nueva estructura y analice los resultados.
[ Parte 1 | Parte 2 | Parte 3 ]