[ Parte 1 | Parte 2 | Parte 3 ]
Recientemente, alguien en el trabajo solicitó más espacio para acomodar una mesa que crece rápidamente. En ese momento tenía 3750 millones de filas, se presentaba en 143 millones de páginas y ocupaba ~1,14 TB. Por supuesto, siempre podemos lanzar más discos en una mesa, pero quería ver si podíamos escalar esto de manera más eficiente que la tendencia lineal actual. Suena como un gran trabajo para la compresión, ¿verdad? Pero también quería probar otras soluciones, incluido el almacén de columnas, que la gente es sorprendentemente reacia a probar. No soy Niko, pero quería hacer un esfuerzo para ver qué podía hacer por nosotros aquí.
Tenga en cuenta que no me estoy centrando en informar sobre la carga de trabajo u otro rendimiento de consultas de lectura en este momento; solo quiero ver qué impacto puedo tener en el espacio de almacenamiento (y memoria) de estos datos.
Aquí está la tabla original. Cambié los nombres de las tablas y las columnas para proteger a los inocentes, pero todo lo demás es relativamente preciso.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Hay algunas otras pequeñas cosas allí que son más anchas de lo que deberían ser y/o que la compresión de filas podría limpiar, como esas numeric(24,12) y bigint columnas que pueden sobredimensionarse prematuramente, pero no voy a volver al equipo de aplicaciones y averiguar si hay poca eficiencia allí, y voy a omitir la compresión de filas para este ejercicio y centrarme en la compresión de página y almacén de columnas.
Esta es una copia de los datos, en un servidor inactivo (8 núcleos, 64 GB de RAM), con mucho espacio en disco (más de 6 TB). Entonces, primero, agreguemos un par de grupos de archivos, uno para el almacén de columnas agrupado estándar y otro para una versión particionada de la tabla (donde todas las particiones, excepto la más reciente, se comprimirán con COLUMNSTORE_ARCHIVE , ya que todos esos datos antiguos ahora son de "solo lectura y con poca frecuencia"):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
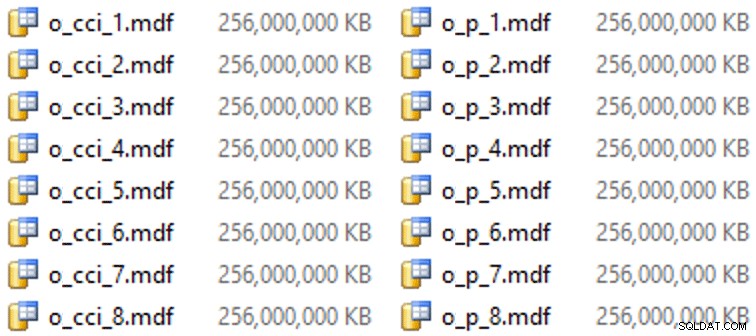
Y luego algunos archivos para estos grupos de archivos (un archivo por núcleo, agradable y con un tamaño uniforme de 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
En este hardware en particular (¡YMMV!), esto tomó alrededor de 10 segundos por archivo y arrojó lo siguiente:
Para generar las particiones, ingenuamente dividí los datos "por partes iguales", o eso pensé. Tomé las 3750 millones de filas y las dividí en algo que pensé que sería manejable:38 particiones con 100 millones de filas en las primeras 37 particiones y el resto en la última. (Recuerde, ¡esto es solo la parte 1! Hay una suposición inherente aquí sobre la distribución uniforme de los valores en la tabla de origen, y también sobre lo que es óptimo para la población del grupo de filas en la tabla de destino). Crear el esquema de partición y la función para esto es como sigue:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Uso RANGE LEFT porque, como sigue recordándome Cathrine Wilhelmsen, esto significa que el valor límite es una parte de la partición a su izquierda. En otras palabras, los valores que estoy especificando son los valores máximos en cada partición (con fechas, por lo general desea RANGE RIGHT ).
Luego creé dos copias de la tabla, una en cada grupo de archivos. El primero tenía un índice de almacén de columnas agrupado estándar, las únicas diferencias eran el OID la columna no es una IDENTITY y la columna calculada es solo un varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
El segundo se creó en el esquema de partición, por lo que primero necesitaba un PK con nombre, que luego tuvo que ser reemplazado por un índice de almacén de columnas agrupado (aunque Brent Ozar muestra en esta breve publicación que hay una sintaxis poco intuitiva que logrará esto en menos pasos ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Luego, para poder comprimir el archivo en todas las particiones excepto en la última, ejecuté lo siguiente:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Ahora, estaba listo para completar estas tablas con datos, medir el tiempo necesario y el tamaño resultante, y comparar. Modifiqué un útil script de procesamiento por lotes de Andy Mallon e inserté las filas en ambas tablas secuencialmente, con un tamaño de lote de 10 millones de filas. Hay mucho más que esto en el script real (incluida la actualización de una tabla de cola con el progreso), pero básicamente:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Después de llenar ambas tablas de almacén de columnas desde la fuente original (sin comprimir), reconstruí esas particiones nuevamente para limpiar cualquier desorden de grupos de filas y diccionarios. Finalmente, apliqué la compresión de página, en su lugar, a la tabla de origen. Estos fueron los tiempos y los resultados de compresión de cada tipo:
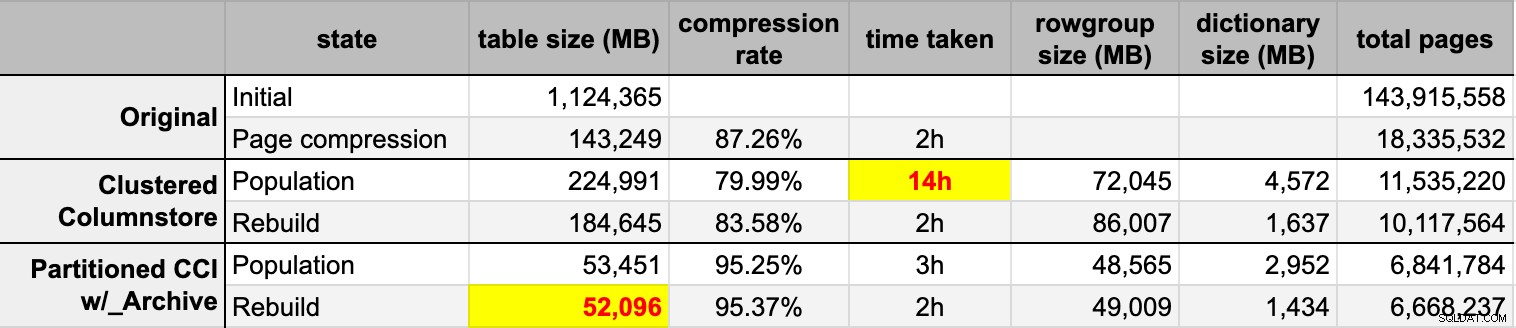
Estoy impresionado y decepcionado. Impresionado porque estos datos se comprimen muy bien – Reducir el espacio de almacenamiento hasta un 5 % del 1 TB original es asombroso. Decepcionado porque:
- No observé ningún recuerdo ni presión de registro.
- No hubo eventos de crecimiento de archivos.
- Desafortunadamente, no pensé en hacer un seguimiento de las esperas. No, no voy a intentarlo de nuevo. :-)
En próximas publicaciones, y después de revisar mis notas de una increíble presentación de Joe Obbish en la tienda de columnas en PASS Summit (a la que me vincularía directamente, si PASS supiera cómo IU), hablaré un poco sobre los cambios que realice en la configuración del servidor y mi secuencia de comandos de población para ver si puedo obtener un mejor rendimiento de la población del almacén de columnas.
[ Parte 1 | Parte 2 | Parte 3 ]